
**特征图:** 特征中往往编码了某种模式或概念在特征图的不同位置是否存在
**边界效应**:开始的输入尺寸为 28×28,经过第一个卷积层之后尺寸变为 26×26。
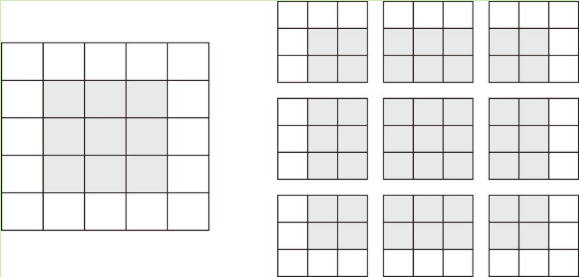
**填充**(padding):在输入特征图的每一边添加适当数目的行和列,使得每个输入方块都能作为卷积窗口的中心。
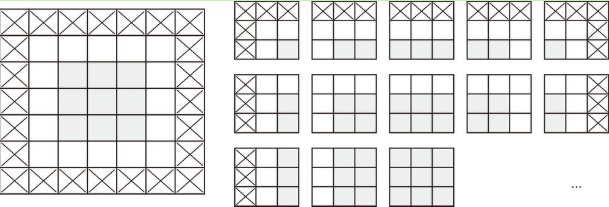
`Conv2D`层,通过`padding`参数来设置填充 :
* `"valid"`表示不使用填充(只使用有效的窗口位置)(默认)
* `"same"`表示填充后输出的宽度和高度与输入相同
**步幅**:两个连续窗口的距离是卷积的一个参数,叫作**步幅**,默认值为 1
**步进卷积**(strided convolution):步幅大于 1 的卷积。步幅为 2 意味着特征图的宽度和高度都被做了 2 倍下采样。
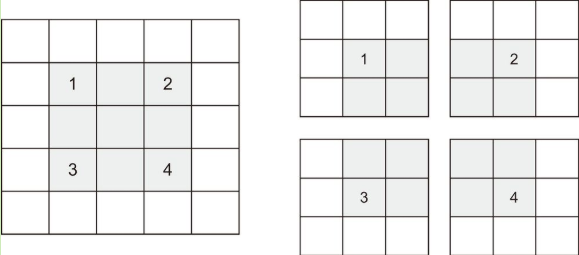
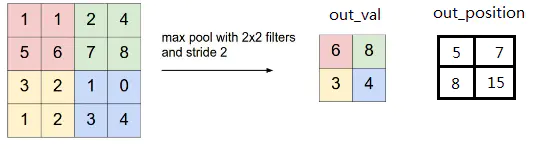
**最大池化运算:**
* 对特征图进行下采样,通常使用**最大池化**(max-pooling)运算。
* 最大池化是从输入特征图中提取窗口,并输出每个通道的**最大值**
* 最大池化使用硬编码的`max`张量运算对局部图块进行变换
* 最大池化通常使用 2×2 的窗口和步幅 2
**为什么要用这种方式对特征图下采样?:**
* 这种架构不利于学习特征的空间层级结构,卷积层的特征包含输入的整体信息太少。
* 最后一层的特征图的元素太多,参数太多,会导致严重的过拟合。
**使用下采样的原因:**
* 减少需要处理的特征图的元素个数
* 通过让**连续卷积层的观察窗口**越来越大(即**窗口覆盖原始输入的比例**越来越大),从而引入空间过滤器的**层级结构**
- 基础
- 张量tensor
- 整数序列(列表)=>张量
- 张量运算
- 张量运算的几何解释
- 层:深度学习的基础组件
- 模型:层构成的网络
- 训练循环 (training loop)
- 数据类型与层类型、keras
- Keras
- Keras 开发
- Keras使用本地数据
- fit、predict、evaluate
- K 折 交叉验证
- 二分类问题-基于梯度的优化-训练
- relu运算
- Dens
- 损失函数与优化器:配置学习过程的关键
- 损失-二分类问题
- 优化器
- 过拟合 (overfit)
- 改进
- 小结
- 多分类问题
- 回归问题
- 章节小结
- 机械学习
- 训练集、验证集和测试集
- 三种经典的评估方法
- 模型评估
- 如何准备输入数据和目标?
- 过拟合与欠拟合
- 减小网络大小
- 添加权重正则化
- 添加 dropout 正则化
- 通用工作流程
- 计算机视觉
- 卷积神经网络
- 卷积运算
- 卷积的工作原理
- 训练一个卷积神经网络
- 使用预训练的卷积神经网络
- VGG16
- VGG16详细结构
- 为什么不微调整个卷积基?
- 卷积神经网络的可视化
- 中间输出(中间激活)
- 过滤器
- 热力图
- 文本和序列
- 处理文本数据
- n-gram
- one-hot 编码 (one-hot encoding)
- 标记嵌入 (token embedding)
- 利用 Embedding 层学习词嵌入
- 使用预训练的词嵌入
- 循环神经网络
- 循环神经网络的高级用法
- 温度预测问题
- code
- 用卷积神经网络处理序列
- GRU 层
- LSTM层
- 多输入模型
- 回调函数
- ModelCheckpoint 与 EarlyStopping
- ReduceLROnPlateau
- 自定义回调函数
- TensorBoard_TensorFlow 的可视化框架
- 高级架构模式
- 残差连接
- 批标准化
- 批再标准化
- 深度可分离卷积
- 超参数优化
- 模型集成
- LSTM
- DeepDream
- 神经风格迁移
- 变分自编码器
- 生成式对抗网络
- 术语表