
# 字符串常见操作
如有字符串`mystr = 'hello world itcast and itcastcpp'`,以下是常见的操作
#### 1\. find
检测 str 是否包含在 mystr中,如果是返回开始的索引值,否则返回-1
~~~
mystr.find(str, start=0, end=len(mystr))
~~~


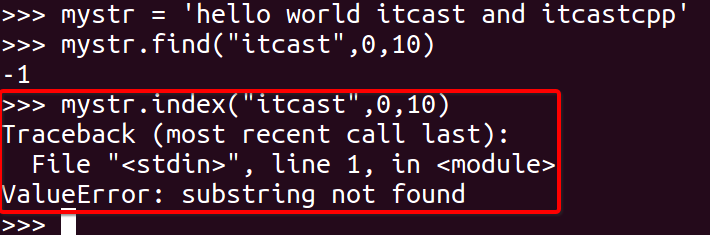
#### 2\. index
跟find()方法一样,只不过如果str不在 mystr中会报一个异常.
~~~
mystr.index(str, start=0, end=len(mystr))
~~~
#### 3\. count
返回 str在start和end之间 在 mystr里面出现的次数
~~~
mystr.count(str, start=0, end=len(mystr))
~~~

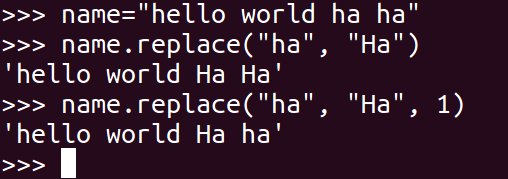
#### 4\. replace
把 mystr 中的 str1 替换成 str2,如果 count 指定,则替换不超过 count 次.
~~~
mystr.replace(str1, str2, mystr.count(str1))
~~~
#### 5\. split
以 str 为分隔符切片 mystr,如果 maxsplit有指定值,则仅分隔 maxsplit 个子字符串
~~~
mystr.split(str=" ", 2)
~~~

#### 6\. capitalize
把字符串的第一个字符大写
~~~
mystr.capitalize()
~~~

#### 7\. title
把字符串的每个单词首字母大写
~~~
>>> a = "hello itcast"
>>> a.title()
'Hello Itcast'
~~~
#### 8\. startswith
检查字符串是否是以 hello 开头, 是则返回 True,否则返回 False
~~~
mystr.startswith(hello)
~~~

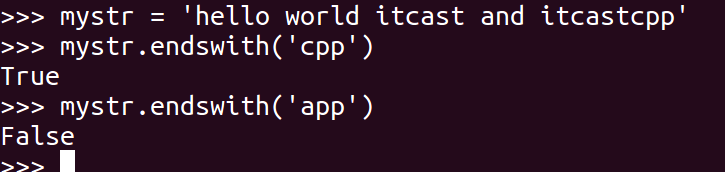
#### 9\. endswith
检查字符串是否以obj结束,如果是返回True,否则返回 False.
~~~
mystr.endswith(obj)
~~~
#### 10\. lower
转换 mystr 中所有大写字符为小写
~~~
mystr.lower()
~~~

#### 11\. upper
转换 mystr 中的小写字母为大写
~~~
mystr.upper()
~~~

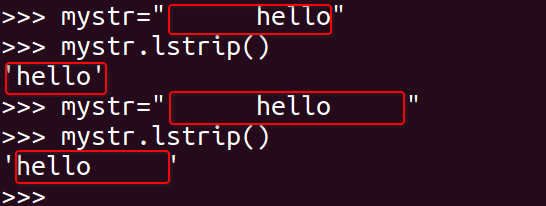
#### 12\. lstrip
删除 mystr 左边的空白字符
~~~
mystr.lstrip()
~~~
#### 13\. rstrip
删除 mystr 字符串末尾的空白字符
~~~
mystr.rstrip()
~~~

#### 14\. strip
删除mystr字符串两端的空白字符
~~~
>>> a = "\n\t itcast \t\n"
>>> a.strip()
'itcast'
~~~
### 15\. rfind
类似于 find()函数,不过是从右边开始查找.
~~~
mystr.rfind(str, start=0,end=len(mystr) )
~~~

### 16\. rindex
类似于 index(),不过是从右边开始.
~~~
mystr.rindex( str, start=0,end=len(mystr))
~~~
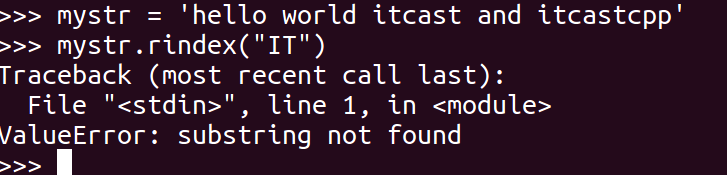
### 17\. partition
把mystr以str分割成三部分,str前,str和str后
~~~
mystr.partition(str)
~~~

### 18\. rpartition
类似于 partition()函数,不过是从右边开始.
~~~
mystr.rpartition(str)
~~~
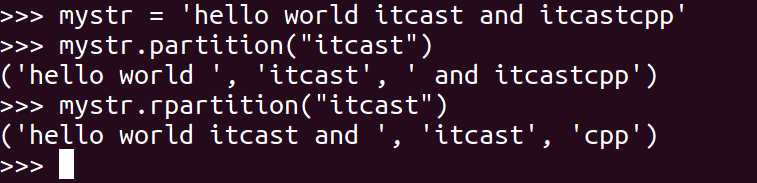
### 19\. splitlines
按照行分隔,返回一个包含各行作为元素的列表
~~~
mystr.splitlines()
~~~
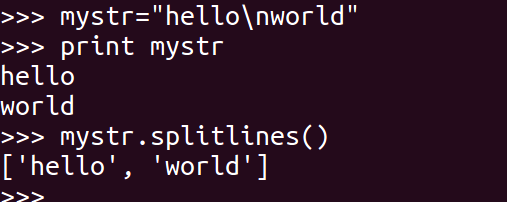
### 20\. isalpha
如果 mystr 所有字符都是字母 则返回 True,否则返回 False
~~~
mystr.isalpha()
~~~
### 21\. isdigit
如果 mystr 只包含数字则返回 True 否则返回 False.
~~~
mystr.isdigit()
~~~

### 22\. isalnum
如果 mystr 所有字符都是字母或数字则返回 True,否则返回 False
~~~
mystr.isalnum()
~~~

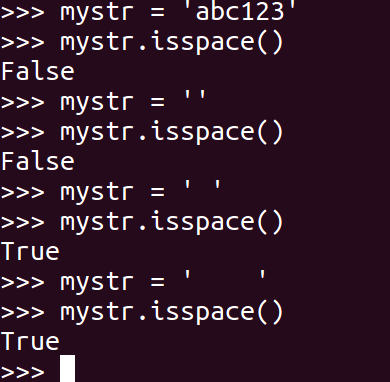
### 23\. isspace
如果 mystr 中只包含空格,则返回 True,否则返回 False.
~~~
mystr.isspace()
~~~
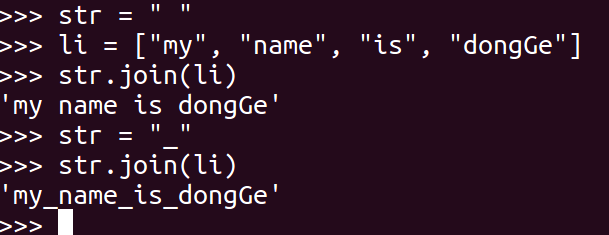
### 24\. join
mystr 中每个元素后面插入str,构造出一个新的字符串
~~~
mystr.join(str)
~~~
# 想一想
* (面试题)给定一个字符串aStr,返回使用空格或者'\\t'分割后的倒数第二个子串
](images/screenshot_1593859329967.png)
- 计算机组成原理和Python基础知识
- 计算机组成原理
- 编程语言和Python
- 开发第一个Python程序
- 注释
- 变量以及类型
- 标识符和关键字
- 输出
- 输入
- 运算符
- 数据类型转换
- 判断语句和循环语句
- 判断语句介绍
- if语句
- 比较、关系运算符
- if...else...语句格式
- if...elif...else语句格式
- if语句的嵌套
- if应用:猜拳游戏
- 循环语句介绍
- while循环
- while循环应用
- while循环的嵌套以及应用
- for循环
- break和continue
- 字符串、列表、元组、字典
- 字符串介绍
- 字符串输出
- 字符串输入
- 下标和切片
- 字符串常见操作
- 列表介绍
- 列表的循环遍历
- 列表的常见操作
- 列表的嵌套
- 元组
- 字典介绍
- 字典的常见操作1
- 字典的常见操作2
- 字典的遍历
- 集合(扩展)
- 公共方法
- 4.函数(一)
- 4.1.函数介绍
- 4.2.函数定义和调用
- 4.3.函数的文档说明
- 4.4.函数参数(一)
- 4.5.函数返回值(一)
- 4.6.函数的嵌套调用
- 4.7.函数应用:打印图形和数学计算
- 5.函数(二)
- 5.1.局部变量
- 5.2.全局变量
- 5.3.多函数程序的基本使用流程
- 5.4.函数返回值(二)
- 5.5.函数参数(二)
- 5.6.拆包、交换变量的值
- 5.7.引用(一)
- 5.8.可变、不可变类型
- 5.9.引用(二)
- 5.10.函数使用注意事项
- 6.强化练习
- 6.1.函数应用:学生管理系统
- 6.2.递归函数
- 6.3. 匿名函数
- 6.4.列表推导式
- 6.5.set、list、tuple
- 6.6.高阶函数: map reduce filter
- 7.文件操作,综合应用
- 7.1.文件操作介绍
- 7.2.文件的读写
- 7.3.应用1:制作文件的备份
- 7.4.文件的相关操作
- 7.5.应用:批量修改文件名
- 7.6.综合应用:学生管理系统(文件版)
- 8.面向对象(上)
- 8.1.认识面向对象编程
- 8.2.类和对象
- 8.3.定义类
- 8.4.创建对象
- 8.5.添加和获取对象的属性
- 8.6.在方法内通过self获取对象属性
- 8.7.魔法方法 - init()
- 8.8.魔法方法 - 有参数的__init__()方法
- 8.9.魔法方法 - str()方法
- 8.10.魔法方法 - del()方法
- 8.11.实操案例 - 烤土豆
- 9.面向对象(中)
- 9.1.实操案例 - 放家具
- 9.2.继承的概念
- 9.3.单继承
- 9.4.多继承
- 9.5.子类重写父类的同名属性和方法
- 9.6.子类调用父类同名属性和方法
- 9.7.多层继承
- 9.8.通过super()来调用父类的方法
- 10.面向对象(下)
- 10.1.私有属性和私有方法
- 10.2.修改私有属性的值
- 10.3.多态
- 10.4.类属性和实例属性
- 10.5.静态方法和类方法
- 11.异常处理与模块初识
- 11.1.异常
- 11.2.捕获异常
- 11.3.异常的传递
- 11.4.抛出自定义的异常
- 11.5.获取异常完整信息的正确姿势
- 11.6.认识模块
- 11.7.开发模块
- 11.8.模块中的__all__(未完成)
- 11.9.python中的包(未完成)
- 12.课后加餐
- 12.1.基础应用 - 进销存管理系统(未完成)
- 12.2.基础应用 - 员工信息管理系统(未完成)
- 12.1.编码规范 - PEP8编码规范(未完成)