
第8篇笔记在引入join使用场景的时候,有个信息采集功能的案例:有若干台采集服务器,然后还有一台主机,这台主机需要等待这若干台服务器信息采集完之后再做进一步的处理,一台采集服务器就对应一个线程,如之前写的代码:
```java
public class ThreadJoin3 {
public static void main(String[] args) throws InterruptedException {
long startTimestamp = System.currentTimeMillis();
// 假设有三台机器,开启三个线程。
Thread m1 = new Thread(new CaptureRunnable("M1", 1_000L));
Thread m2 = new Thread(new CaptureRunnable("M2", 2_000L));
Thread m3 = new Thread(new CaptureRunnable("M3", 3_000L));
m1.start();
m2.start();
m3.start();
m1.join();
m2.join();
m3.join();
long endTimestamp = System.currentTimeMillis();
System.out.printf("Save data begin timestamp is %s, end timestamp is %s\n", startTimestamp, endTimestamp);
System.out.printf("Spend time is %s", endTimestamp - startTimestamp);
}
}
/**
* 采集服务器节点的任务。
*/
class CaptureRunnable implements Runnable {
// 机器节点的名称
private String machineName;
// 采集花费时间
private long spendTime;
public CaptureRunnable(String machineName, long spendTime) {
this.machineName = machineName;
this.spendTime = spendTime;
}
@Override
public void run() {
// do the really capture data.
try {
Thread.sleep(spendTime);
System.out.printf(machineName + " completed data capture at timestamp [%s] and successful.\n", System.currentTimeMillis());
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public String getResult() {
return machineName + " finish.";
}
}
```
为了获取三个线程统一的结束时间,使用了join,这是三个线程三个服务器的情况,如果有成千上万台那怎么办,不可能每台服务器对应一个线程,因为线程有一个stackSize的上限,此时就需要用到线程同步来避免这个问题了,我们一步一步完善这个功能:
首先创建十个线程,这里采用流的方式来创建,如下:
```java
public class CaptureService {
public static void main(String[] args) {
Stream.of("M1", "M2", "M3", "M4", "M5", "M6", "M7", "M8", "M9", "M10")
.map(CaptureService::createCaptureService)
.forEach(t -> {
t.start();
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
Optional.of("All of capture work finished.").ifPresent(System.out::println);
}
public static Thread createCaptureService(String name) {
return new Thread(() -> {
//TODO
System.out.println(Thread.currentThread().getName());
}, name);
}
}
```
运行效果如下:
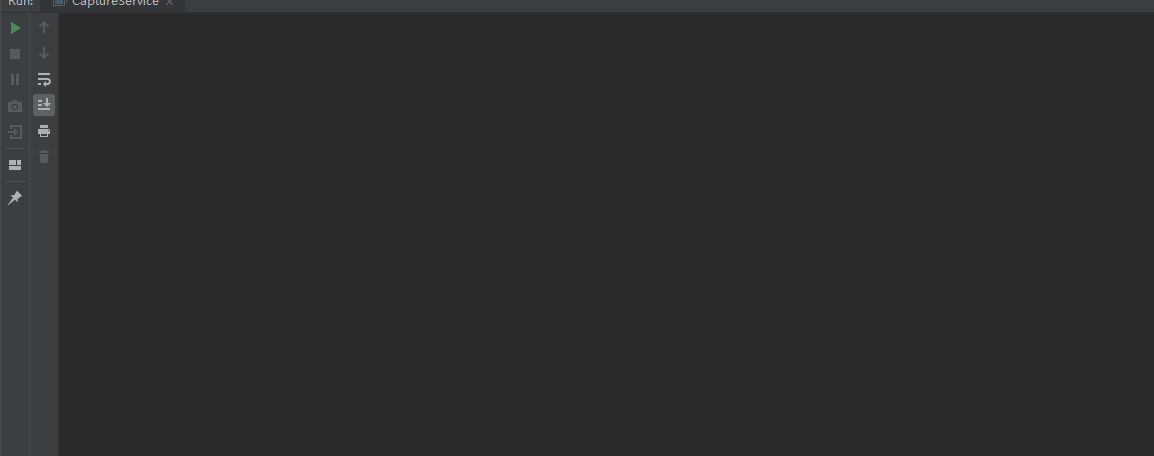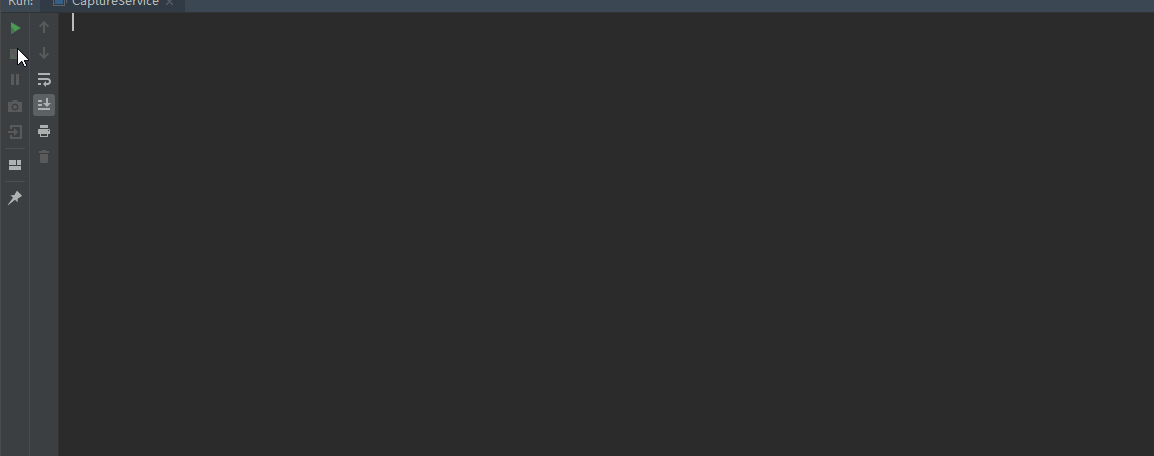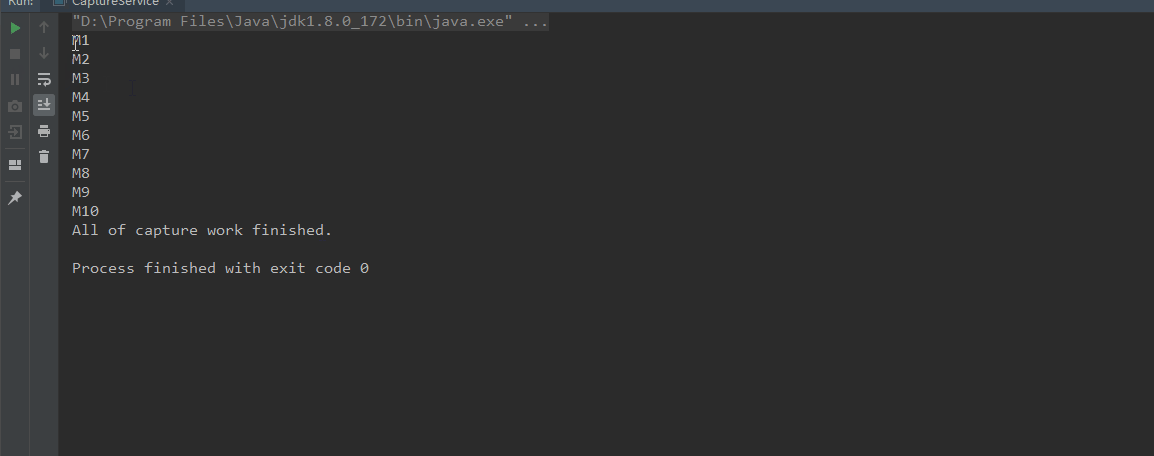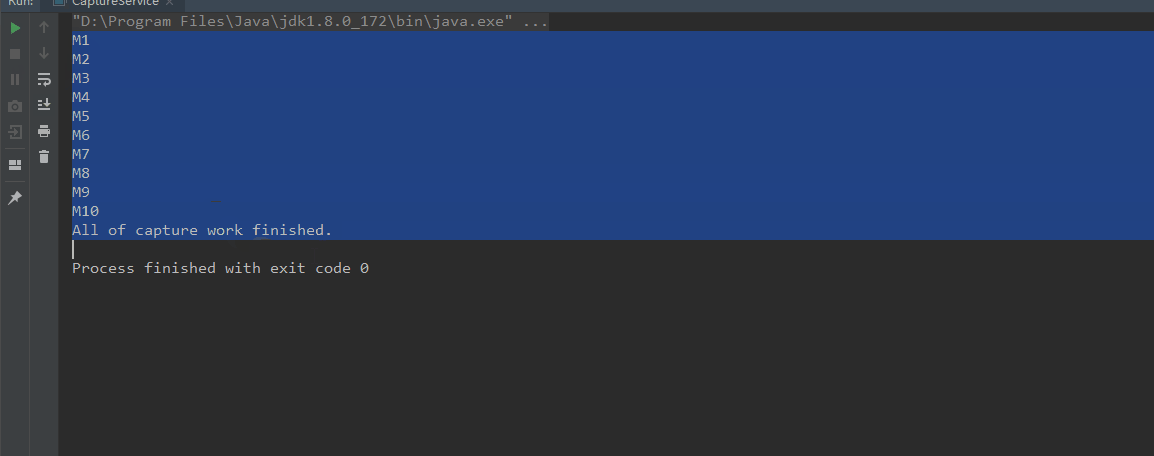
可以看到线程都跑起来了,但是这样实际是有问题的,因为写在foreach里是只等待当前线程执行完了而不是所有的线程执行完。
这里使用java8的Stream.forEach(),因为这个方法是一个teminal operation,这个后续再深入学习,先知道有这么个东西,运行效果如下:
接下来完善createCaptureService:
1. 我们在CaptureService增加一个MAX_WORKER来代表最大执行线程数。
```java
private static final int MAX_WORKER = 5;
```
2. 定义一个class,作为执行代码锁的控制器Control。然后放在一个链表里。
```java
private static final LinkedList<Control> CONTROLS = new LinkedList<>();
```
3. 如果链表的长度大于最大执行线程数,就wait();
```java
while (CONTROLS.size() > MAX_WORKER) {
try {
CONTROLS.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
```
4. 如果链表长度小于最大执行线程数,就代表链表里还有空间,那么就在链表里增加一个Control的对象。
```java
CONTROLS.addLast(new Control());
```
5. 然后写采集的业务,采集业务执行后,先把链表里的第一个移除。也就是先进先出。同时notifyAll()wait的线程,这时候一个线程抢导锁就会继续执行上面的4步的操作,依次类推下去:
```java
synchronized (CONTROLS) {
Optional.of("The worker [" + Thread.currentThread().getName() + "] END capture data.").ifPresent(System.out::println);
CONTROLS.removeFirst();
CONTROLS.notifyAll();
}
```
整体代码如下:
```java
/**
* @program: ThreadDemo
* @description: 数据采集功能:利用多个线程采集多台服务器运行状态信息。
* 当服务器数量较少时,可以采取一个线程采集一台服务器;
* 但是服务器数量非常大时,将不可能采取这种方式。
* 可以开启一定数量的线程采集完成后再采集其他服务器,即运行的线程始终保持着稳定数量。
* @author: hs96.cn@Gmail.com
* @create: 2020-09-08
*/
public class CaptureService {
private static final int MAX_WORKER = 5;
private static final LinkedList<Control> CONTROLS = new LinkedList<>();
public static void main(String[] args) {
List<Thread> worker = new ArrayList<>();
Stream.of("M1", "M2", "M3", "M4", "M5", "M6", "M7", "M8", "M9", "M10")
.map(CaptureService::createCaptureService)
.forEach(t -> {
t.start();
worker.add(t);
});
worker.stream().forEach(t -> {
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
Optional.of("All of capture work finished.").ifPresent(System.out::println);
}
public static Thread createCaptureService(String name) {
return new Thread(() -> {
// Optional可以防止NPE空指针异常
Optional.of("The worker [" + Thread.currentThread().getName() + "] BEGIN capture data.").ifPresent(System.out::println);
synchronized (CONTROLS) {
while (CONTROLS.size() > MAX_WORKER) {
try {
CONTROLS.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
CONTROLS.addLast(new Control());
}
Optional.of("The worker [" + Thread.currentThread().getName() + "] is WORKING...").ifPresent(System.out::println);
try {
Thread.sleep(10_000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (CONTROLS) {
Optional.of("The worker [" + Thread.currentThread().getName() + "] END capture data.").ifPresent(System.out::println);
CONTROLS.removeFirst();
CONTROLS.notifyAll();
}
}, name);
}
private static class Control{
}
}
```
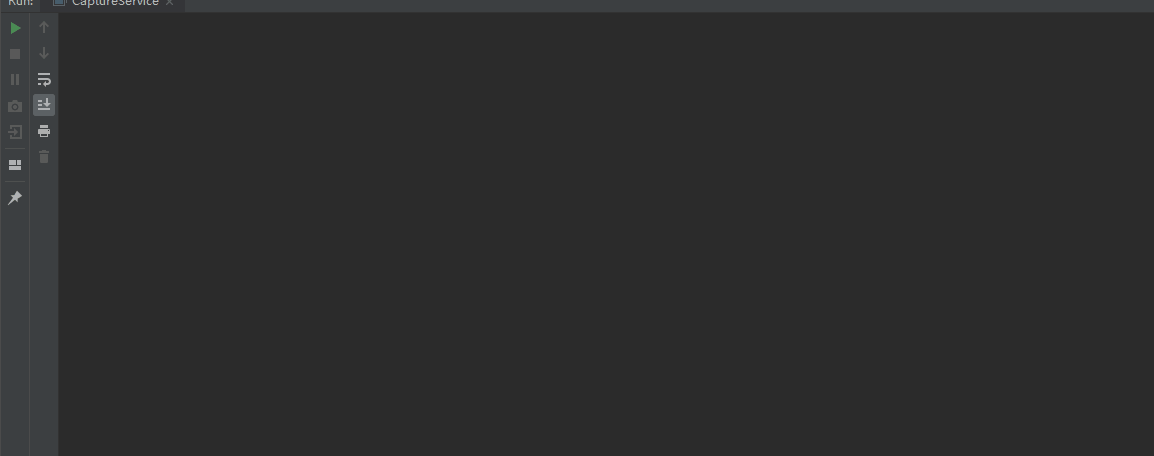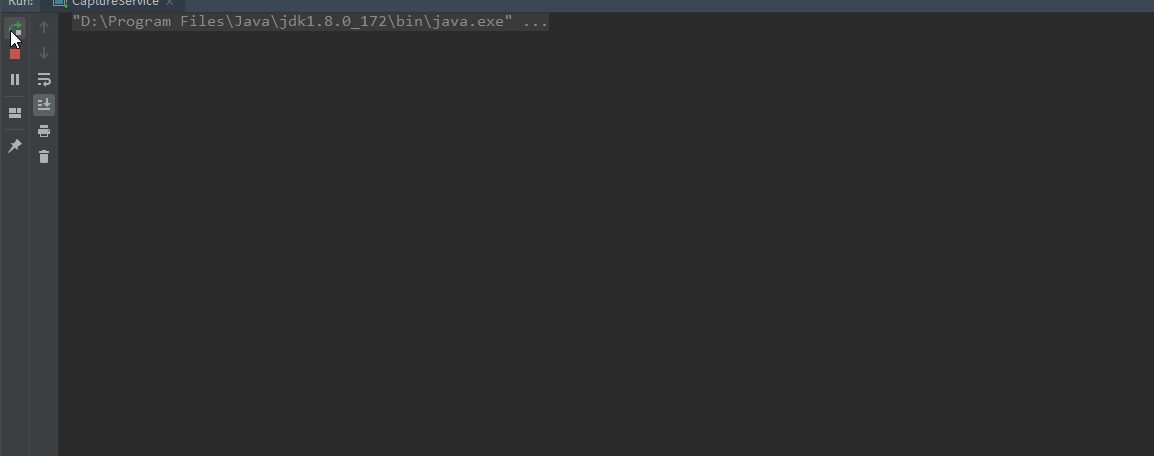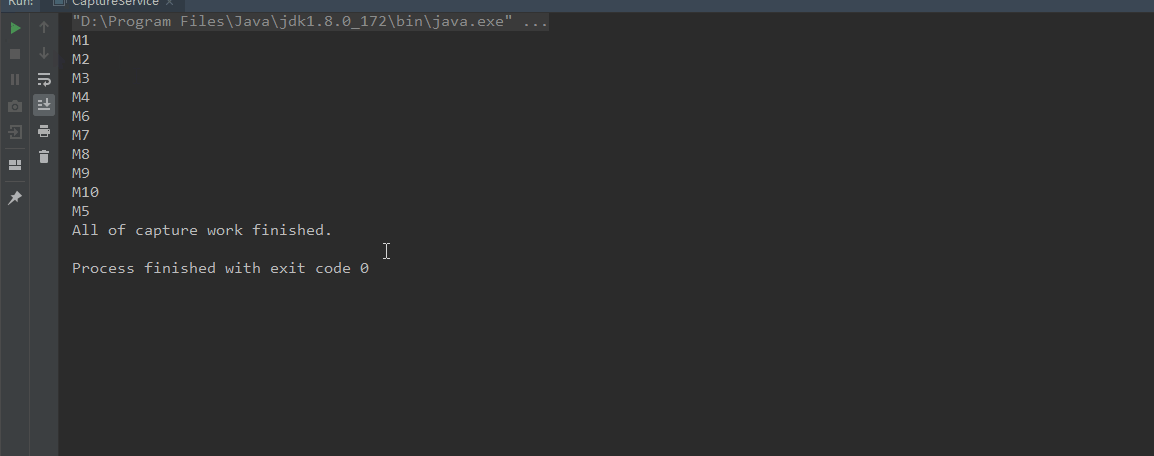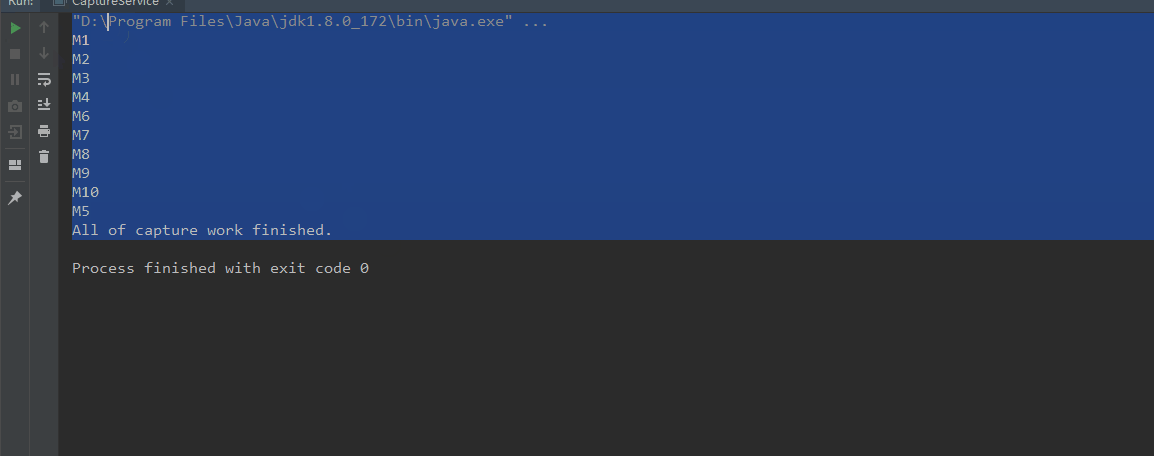
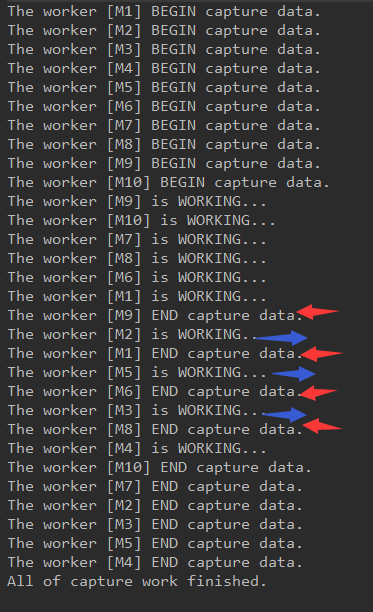
运行结果如下:
- 微服务
- 服务器相关
- 操作系统
- 极客时间操作系统实战笔记
- 01 程序的运行过程:从代码到机器运行
- 02 几行汇编几行C:实现一个最简单的内核
- 03 黑盒之中有什么:内核结构与设计
- Rust
- 入门:Rust开发一个简单的web服务器
- Rust的引用和租借
- 函数与函数指针
- Rust中如何面向对象编程
- 构建单线程web服务器
- 在服务器中增加线程池提高吞吐
- Java
- 并发编程
- 并发基础
- 1.创建并启动线程
- 2.java线程生命周期以及start源码剖析
- 3.采用多线程模拟银行排队叫号
- 4.Runnable接口存在的必要性
- 5.策略模式在Thread和Runnable中的应用分析
- 6.Daemon线程的创建以及使用场景分析
- 7.线程ID,优先级
- 8.Thread的join方法
- 9.Thread中断Interrupt方法学习&采用优雅的方式结束线程生命周期
- 10.编写ThreadService实现暴力结束线程
- 11.线程同步问题以及synchronized的引入
- 12.同步代码块以及同步方法之间的区别和关系
- 13.通过实验分析This锁和Class锁的存在
- 14.多线程死锁分析以及案例介绍
- 15.线程间通信快速入门,使用wait和notify进行线程间的数据通信
- 16.多Product多Consumer之间的通讯导致出现程序假死的原因分析
- 17.使用notifyAll完善多线程下的生产者消费者模型
- 18.wait和sleep的本质区别
- 19.完善数据采集程序
- 20.如何实现一个自己的显式锁Lock
- 21.addShutdownHook给你的程序注入钩子
- 22.如何捕获线程运行期间的异常
- 23.ThreadGroup API介绍
- 24.线程池原理与自定义线程池一
- 25.给线程池增加拒绝策略以及停止方法
- 26.给线程池增加自动扩充,闲时自动回收线程的功能
- JVM
- C&C++
- GDB调试工具笔记
- C&C++基础
- 一个例子理解C语言数据类型的本质
- 字节顺序-大小端模式
- Php
- Php源码阅读笔记
- Swoole相关
- Swoole基础
- php的五种运行模式
- FPM模式的生命周期
- OSI网络七层图片速查
- IP/TCP/UPD/HTTP
- swoole源代码编译安装
- 安全相关
- MySql
- Mysql基础
- 1.事务与锁
- 2.事务隔离级别与IO的关系
- 3.mysql锁机制与结构
- 4.mysql结构与sql执行
- 5.mysql物理文件
- 6.mysql性能问题
- Docker&K8s
- Docker安装java8
- Redis
- 分布式部署相关
- Redis的主从复制
- Redis的哨兵
- redis-Cluster分区方案&应用场景
- redis-Cluster哈希虚拟槽&简单搭建
- redis-Cluster redis-trib.rb 搭建&原理
- redis-Cluster集群的伸缩调优
- 源码阅读笔记
- Mq
- ELK
- ElasticSearch
- Logstash
- Kibana
- 一些好玩的东西
- 一次折腾了几天的大华摄像头调试经历
- 搬砖实用代码
- python读取excel拼接sql
- mysql大批量插入数据四种方法
- composer好用的镜像源
- ab
- 环境搭建与配置
- face_recognition本地调试笔记
- 虚拟机配置静态ip
- Centos7 Init Shell
- 发布自己的Composer包
- git推送一直失败怎么办
- Beyond Compare过期解决办法
- 我的Navicat for Mysql
- 小错误解决办法
- CLoin报错CreateProcess error=216
- mysql error You must reset your password using ALTER USER statement before executing this statement.
- VM无法连接到虚拟机
- Jetbrains相关
- IntelliJ IDEA 笔记
- CLoin的配置与使用
- PhpStormDocker环境下配置Xdebug
- PhpStorm advanced metadata
- PhpStorm PHP_CodeSniffer