
### 前言
主从复制是哨兵`sentinel`和`cluster`的基础,知其然知其所以然,所以,了解了其中的细节原理和每一步都执行了什么操作,对以后的调试也是很有帮助的。
### 为什么要使用主从
在实际的场景当中单一节点的`redis`容易面临风险,比如只有一台`redis`,然后挂了,本来要经过`缓存层`的东西直接把压力转到`数据库`上了,即使数据库扛得住,响应速度可能也不是很快,这样业务受影响了,如果有主从复制,一台从机挂了还可以在其他从机获取数据,所以,主从复制可以很好的解决`单机器故障`的问题,也就是`高可用`问题,但是其实还存在`故障转移问题`,后面我会写文章解决这个。
### 主从复制的简单流程
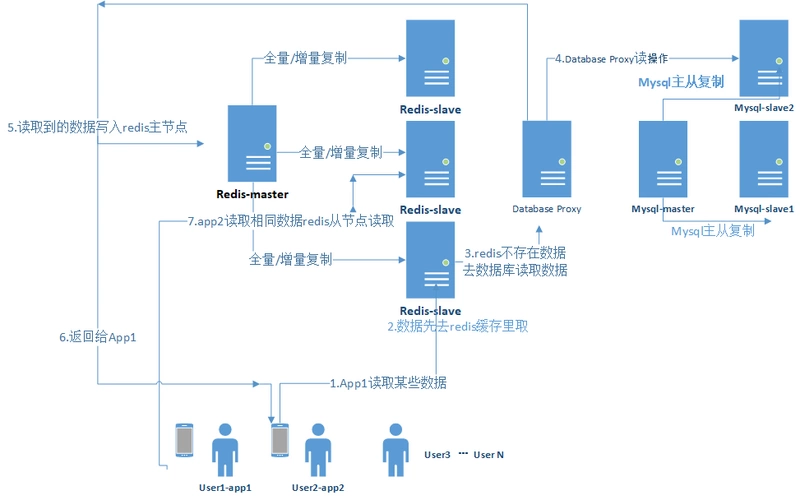
1.这里我把一系列操作举例放到实际业务流程中,比如有`N`多用户在频繁的读取数据。
2.如果用户1先去`redis-slave`缓存里取数据。
3.缓存中没有数据,去数据库里取。
4.`database proxy`分发读取数据操作,请求落在`mysql`从节点上。
5.`database proxy`将获取到的数据(这里假如获取到了,没有获取到直接返回给app)写入`redis-master` 主节点。
6.同时把获取到的数据返回给用户。
7.后面的`N`个用户获取相同的数据,压力被分散在不同的`redis-slave`上面,即使,某一个`redis-slave`宕机了,其他`redis-slave`还可以继续提供服务。
**注:**
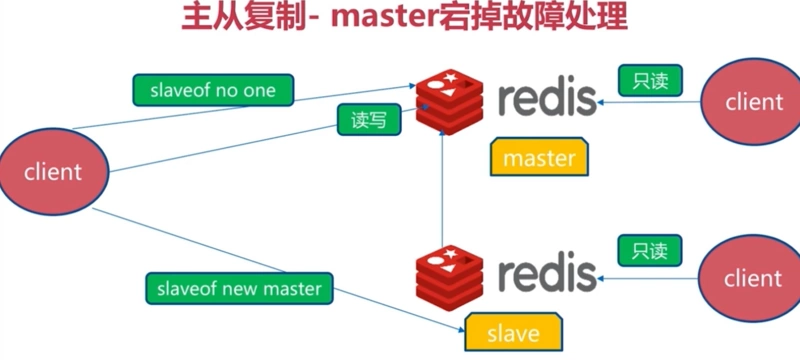
主从复制数据的复制是`单向的`,只能由主节点到从节点默认情况下,每台`redis`服务器都是主节点,也就是`主节点挂了其他从节点可以变成主节点`(这个切换过程我附在下面);且一个主节点可以有多个从节点(或没有从节点),但**一个从节点只能有一个主节点**。
### 主从复制搭建
**从节点开启主从复制,有3种方式:**
#### 1、配置文件启用
在从服务器的配置文件中加入:`slaveof masterip masterport`
#### 2、启动命令启用
redis-server启动命令后加入 `--slaveof masterip masterport`
#### 3、客户端命令启用
redis服务器启动后,直接通过客户端执行命令:`slaveof masterip masterport`,则该redis实例成为从节点。
**通过 `info replication` 命令可以看到复制的一些信息**
注 : `Log` 文件位置 `vi /var/log/redis/redis.log`
### 主从复制原理
主从复制过程大体可以分为3个阶段:**连接建立阶段(即准备阶段)、数据同步阶段、命令传播阶段。**
在从节点执行 `slaveof` 命令后,复制过程便开始运作,复制过程大致分为6个过程。

对照日志看一下日志如下
`1`保存主节点(master)信息。
`2`从节点(slave)内部通过每秒运行的定时任务维护复制相关逻辑,当定时任务发现存在新的主节点后,会尝试与该节点建立网络连接从节点会建立一个 `socket` 套接字,从节点建立了一个端口为`xxxxx`的套接字,专门用于接受主节点发送的复制命令。从节点连接成功后打印如下日志:

如果从节点无法建立连接,定时任务会无限重试直到连接成功或者执行 `slaveof no one` 取消复制
关于连接失败,可以在从节点执行 `info replication` 查看 `master_link_down_since_seconds` 指标,它会记录与主节点连接失败的系统时间。从节点连接主节点失败时也会每秒打印如下日志,方便发现问题:
Error condition on socket for SYNC: {socket_error_reason}
`3`发送 `ping` 命令
连接建立成功后从节点发送 ping 请求进行首次通信,ping 请求主要目的如下:
检测主从之间网络套接字是否可用。
检测主节点当前是否可接受处理命令。
如果发送 ping 命令后,从节点没有收到主节点的 pong 回复或者超时,比如网络超时或者主节点正在阻塞无法响应命令,从节点会断开复制连接,下次定时任务会发起重连。
我估计好多人的学软件的第一课 都`ping pong`过把,这里就不解释了。。
`4`权限验证。如果主节点设置了 `requirepass` 参数,则需要密码验证,从节点必须配置 `masterauth` 参数保证与主节点相同的密码才能通过验证;如果验证失败复制将终止,从节点重新发起复制流程。
先`ping`服务器和端口,通了肯定校验一下密码
`5`同步数据集。主从复制连接正常通信后,对于首次建立复制的场景,主节点会把持有的数据全部发送给从节点,这部分操作也是耗时最长的步骤。
`6`命令持续复制。当主节点把当前的数据同步给从节点后,便完成了复制的建立流程。接下来主节点会持续地把写命令发送给从节点,保证主从数据一致性。
### 全量复制和部分复制和复制偏移量
#### 全量复制
用于初次复制或其它无法进行部分复制的情况,将主节点中的所有数据都发送给从节点,是一个非常重型的操作,当数据量较大时,会对主从节点和网络造成很大的开销
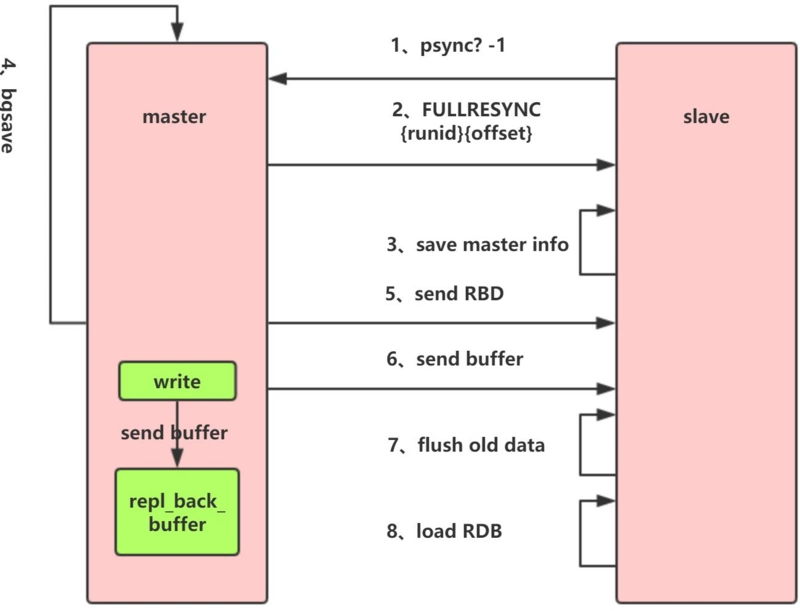
`1.Redis` 内部会发出一个同步命令,刚开始是 `Psync` 命令,Psync ? -1表示要求 `master` 主机同步数据
`2.`主机会向从机发送 `runid` 和 `offset`,因为 `slave` 并没有对应的 `offset`,所以是`全量复制`
`3.`从机 slave 会保存 主机master 的基本信息 `save masterInfo`
`4.`主节点收到全量复制的命令后,执行`bgsave`(异步执行),在后台生成`RDB`文件(快照),并使用一个缓冲区(称为`复制缓冲区`)记录从现在开始执行的所有写命令
`5.`主机`send RDB` 发送 `RDB` 文件给从机
`6.`发送缓冲区数据
`7.`刷新旧的数据,从节点在载入主节点的数据之前要先将老数据清除
`8.`加载 `RDB` 文件将数据库状态更新至主节点执行`bgsave`时的数据库状态和缓冲区数据的加载
##### 全量复制的开销主要如下
`1.`bgsave 时间
`2.`RDB 文件网络传输时间
`3.`从节点清空数据的时间
`4.`从节点加载 RDB 的时间
#### 部分复制
用于处理在主从复制中因网络闪断等原因造成的数据丢失场景,当从节点再次连上主节点后,如果条件允许,主节点会补发丢失数据给从节点。因为补发的数据远远小于全量数据,可以有效避免全量复制的过高开销,需要注意的是,如果网络中断时间过长,造成主节点没有能够完整地保存中断期间执行的写命令,则无法进行部分复制,仍使用全量复制
部分复制是 `redis 2.8` 以后出现的,之所以要加入部分复制,是因为全量复制会产生很多问题,比如像上面的时间开销大、无法隔离等问题, **`redis` 希望能够在 `master` 出现抖动(相当于断开连接)的时候,可以有一些机制将复制的损失降低到最低。**
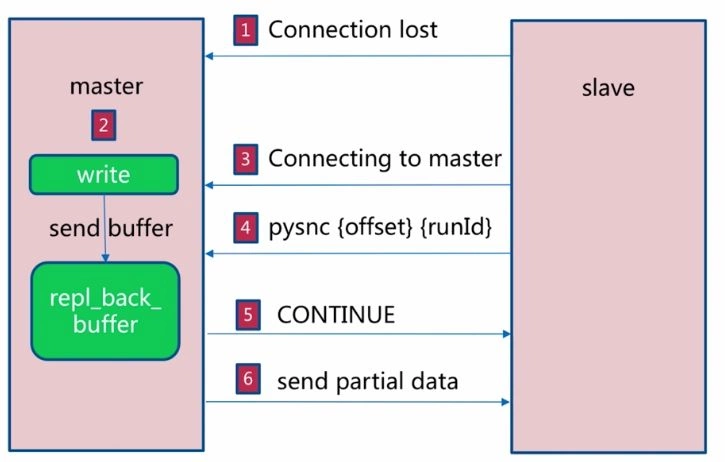
`1.`如果网络抖动(连接断开 `connection lost`)
`2.`主机`master` 还是会写 `replbackbuffer`(复制缓冲区)
`3.`从机`slave` 会继续尝试连接主机
`4.`从机`slave` 会把自己当前 `runid` 和偏移量传输给主机 `master`,并且执行 `pysnc` 命令同步
`5.`如果 `master` 发现你的偏移量是在缓冲区的范围内,就会返回 `continue` 命令
`6.`同步了 `offset` 的部分数据,所以部分复制的基础就是偏移量 `offset`。
#### 复制偏移量
参与复制的主从节点都会维护自身复制偏移量。主节点(`master`)在处理完写入命令后,会把命令的字节长度做累加记录,统计信息在 `info relication` 中的 `master_repl_offset` 指标中:
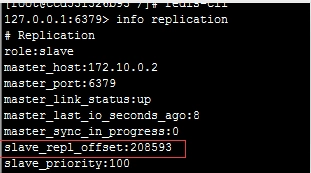
从节点(`slave`)每秒钟上报自身的复制偏移量给主节点,因此主节点也会保存从节点的复制偏移量,统计指标如下:

从节点在接收到主节点发送的命令后,也会累加记录自身的偏移量。统计信息在 `info relication` 中的 `slave_repl_offset` 中
### 复制积压缓冲区
复制积压缓冲区是保存在主节点上的一个固定长度的队列,默认大小为`1MB`,当主节点有连接的从节点(`slave`)时被创建,这时主节点(`master`)响应写命令时,不但会把命令发送给从节点,还会写入复制积压缓冲区。
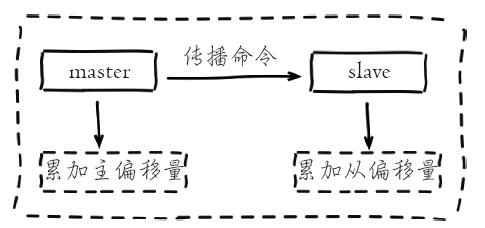
在`命令传播阶段`,主节点除了将写命令发送给从节点,还会发送一份给复制积压缓冲区,作为写命令的备份;除了存储写命令,复制积压缓冲区中还存储了其中的每个字节对应的复制偏移量(`offset`) 。由于复制积压缓冲区定长且先进先出,所以它保存的是主节点最近执行的写命令;时间较早的写命令会被挤出缓冲区。可以对照全量复制`redis-master`的图理解 复制挤压缓冲区。
### 正常情况下redis是如何决定是全量复制还是部分复制
1.从节点将`offset`发送给主节点后,主节点根据`offset`和缓冲区大小决定能否执行部分复制:
2.如果`offset`偏移量之后的数据,仍然都在复制积压缓冲区里,则执行部分复制;
3.如果`offset`偏移量之后的数据已不在复制积压缓冲区中(数据已被挤出),则执行全量复制。
#### 1、缓冲区大小调节:
由于缓冲区长度固定且有限,因此可以备份的写命令也有限,当主从节点`offset`的差距过大超过缓冲区长度时,将无法执行部分复制,只能执行全量复制。反过来说,为了提高网络中断时部分复制执行的概率,可以根据需要增大复制积压缓冲区的大小(通过配置`repl-backlog-size`)来设置;例如如果网络中断的平均时间是`60s`,而主节点平均每秒产生的写命令(特定协议格式)所占的字节数为`100KB`,则复制积压缓冲区的平均需求为`6MB`,保险起见,可以设置为`12MB`,来保证绝大多数断线情况都可以使用部分复制。
#### 2、服务器运行ID(`runid`)
每个`redis`节点(无论主从),在启动时都会自动生成一个随机ID(每次启动都不一样),由40个随机的十六进制字符组成;runid用来唯一识别一个`redis`节点。 通过`info server`命令,可以查看节点的`runid`:
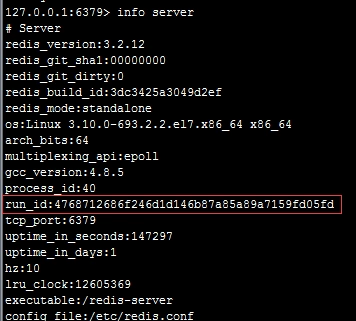
主从节点初次复制时,主节点将自己的`runid`发送给从节点,从节点将这个`runid`保存起来;当断线重连时,从节点会将这个`runid`发送给主节点;主节点根据`runid`判断能否进行部分复制:
如果从节点保存的`runid`与主节点现在的`runid`相同,说明主从节点之前同步过,主节点会继续尝试使用部分复制(到底能不能部分复制还要看`offset`和复制积压缓冲区的情况)
如果从节点保存的`runid`与主节点现在的`runid`不同,说明从节点在断线前同步的`Redis`节点并不是当前的主节点,只能进行全量复制。
### 主从复制进阶常见问题解决
#### 1、读写分离
读流量分摊到从节点。这是个非常好的特性,如果一个业务只需要读数据,那么我们只需要连一台 `slave` 从机读数据。

虽然读写有优势,能够让读这部分分配给各个 slave 从机,如果不够,直接加 `slave` 机器就好了。但是也会出现以下问题。
**1.复制数据延迟。**
可能会出现 `slave` 延迟导致读写不一致等问题,当然你也可以使用监控偏移量 offset,如果 offset 超出范围就切换到 `master` 上,逻辑切换,而具体延迟多少,可以通过 `info replication` 的 `offset` 指标进行排查。
对于无法容忍大量延迟场景,可以编写外部监控程序监听主从节点的复制偏移量,当延迟较大时触发报警或者通知客户端避免读取延迟过高的从节点
同时从节点的`slave-serve-stale-data`参数也与此有关,它控制这种情况下从节点的表现:如果为`yes`(默认值),则从节点仍能够响应客户端的命令;如果为`no`,则从节点只能响应`info`、`slaveof`等少数命令。该参数的设置与应用对数据一致性的要求有关;如果对数据一致性要求很高,则应设置为`no`。
**2.从节点故障问题**
对于从节点的故障问题,需要在客户端维护一个可用从节点可用列表,当从节点故障时,立刻切换到其他从节点或主节点。
#### 2、主从配置不一致
主机和从机不同,经常导致主机和从机的配置不同,并带来问题。
数据丢失:主机和从机有时候会发生配置不一致的情况,例如 `maxmemory` 不一致,如果主机配置 `maxmemory` 为`8G`,从机 `slave` 设置为`4G`,这个时候是可以用的,而且还不会报错。但是如果要做高可用,让从节点变成主节点的时候,就会发现数据已经丢失了,而且无法挽回。虽然错误很低级,但是有人会犯。。。
#### 3、规避全量复制
全量复制指的是当 `slave` 从机断掉并重启后,`runid` 产生变化而导致需要在 `master` 主机里拷贝全部数据。这种拷贝全部数据的过程非常耗资源。全量复制是不可避免的,例如第一次的全量复制是不可避免的,这时我们需要选择小主节点,且maxmemory 值不要过大,这样就会比较快。同时选择在低峰值的时候做全量复制。
##### 1.造成全量复制的原因
##### 1、是主从机的运行 `runid` 不匹配。
解释一下,主节点如果重启,`runid` 将会发生变化。如果从节点监控到 `runid` 不是同一个,它就会认为你的节点不安全。当发生故障转移的时候,如果主节点发生故障,那么从机就会变成主节点。我们会在后面讲解哨兵和集群。
##### 2、复制缓冲区空间不足
比如默认值`1M`,可以部分复制。但如果缓存区不够大的话,首先需要网络中断,部分复制就无法满足。其次需要增大复制缓冲区配置(`relbacklogsize`),对网络的缓冲增强。参考之前的说明。
**解决办法:**
在一些场景下,可能希望对主节点进行重启,例如主节点内存碎片率过高,或者希望调整一些只能在启动时调整的参数。如果使用普通的手段重启主节点,会使得runid发生变化,可能导致不必要的全量复制。
为了解决这个问题,rdis提供了debug reload的重启方式:重启后,主节点的`runid`和`offset`都不受影响,避免了全量复制。
##### 3、`master` 主机挂了重启
当一个主机下面挂了很多个 `slave` 从机的时候,主机 `master` 挂了,这时 `master` 主机重启后,因为 `runid` 发生了变化,所有的 `slave` 从机都要做一次全量复制。这将引起单节点和单机器的复制风暴,开销会非常大。
**解决办法:**
可以采用树状结构降低多个从节点对主节点的消耗
从节点采用树状树非常有用,网络开销交给位于中间层的从节点,而不必消耗顶层的主节点。但是这种树状结构也带来了运维的复杂性,增加了手动和自动处理故障转移的难度
#### 4、单机器的复制风暴
由于 `redis`的单线程架构,通常单台机器会部署多个 `redis` 实例。当一台机器(`machine`)上同时部署多个主节点(`master`)时,如果每个 `master` 主机只有一台 `slave` 从机,那么当机器宕机以后,会产生大量全量复制。这种情况是非常危险的情况,带宽马上会被占用,会导致不可用。
**解决办法:**
应该把主节点尽量分散在多台机器上,避免在单台机器上部署过多的主节点。
当主节点所在机器故障后提供故障转移机制,避免机器恢复后进行密集的全量复制。
- 微服务
- 服务器相关
- 操作系统
- 极客时间操作系统实战笔记
- 01 程序的运行过程:从代码到机器运行
- 02 几行汇编几行C:实现一个最简单的内核
- 03 黑盒之中有什么:内核结构与设计
- Rust
- 入门:Rust开发一个简单的web服务器
- Rust的引用和租借
- 函数与函数指针
- Rust中如何面向对象编程
- 构建单线程web服务器
- 在服务器中增加线程池提高吞吐
- Java
- 并发编程
- 并发基础
- 1.创建并启动线程
- 2.java线程生命周期以及start源码剖析
- 3.采用多线程模拟银行排队叫号
- 4.Runnable接口存在的必要性
- 5.策略模式在Thread和Runnable中的应用分析
- 6.Daemon线程的创建以及使用场景分析
- 7.线程ID,优先级
- 8.Thread的join方法
- 9.Thread中断Interrupt方法学习&采用优雅的方式结束线程生命周期
- 10.编写ThreadService实现暴力结束线程
- 11.线程同步问题以及synchronized的引入
- 12.同步代码块以及同步方法之间的区别和关系
- 13.通过实验分析This锁和Class锁的存在
- 14.多线程死锁分析以及案例介绍
- 15.线程间通信快速入门,使用wait和notify进行线程间的数据通信
- 16.多Product多Consumer之间的通讯导致出现程序假死的原因分析
- 17.使用notifyAll完善多线程下的生产者消费者模型
- 18.wait和sleep的本质区别
- 19.完善数据采集程序
- 20.如何实现一个自己的显式锁Lock
- 21.addShutdownHook给你的程序注入钩子
- 22.如何捕获线程运行期间的异常
- 23.ThreadGroup API介绍
- 24.线程池原理与自定义线程池一
- 25.给线程池增加拒绝策略以及停止方法
- 26.给线程池增加自动扩充,闲时自动回收线程的功能
- JVM
- C&C++
- GDB调试工具笔记
- C&C++基础
- 一个例子理解C语言数据类型的本质
- 字节顺序-大小端模式
- Php
- Php源码阅读笔记
- Swoole相关
- Swoole基础
- php的五种运行模式
- FPM模式的生命周期
- OSI网络七层图片速查
- IP/TCP/UPD/HTTP
- swoole源代码编译安装
- 安全相关
- MySql
- Mysql基础
- 1.事务与锁
- 2.事务隔离级别与IO的关系
- 3.mysql锁机制与结构
- 4.mysql结构与sql执行
- 5.mysql物理文件
- 6.mysql性能问题
- Docker&K8s
- Docker安装java8
- Redis
- 分布式部署相关
- Redis的主从复制
- Redis的哨兵
- redis-Cluster分区方案&应用场景
- redis-Cluster哈希虚拟槽&简单搭建
- redis-Cluster redis-trib.rb 搭建&原理
- redis-Cluster集群的伸缩调优
- 源码阅读笔记
- Mq
- ELK
- ElasticSearch
- Logstash
- Kibana
- 一些好玩的东西
- 一次折腾了几天的大华摄像头调试经历
- 搬砖实用代码
- python读取excel拼接sql
- mysql大批量插入数据四种方法
- composer好用的镜像源
- ab
- 环境搭建与配置
- face_recognition本地调试笔记
- 虚拟机配置静态ip
- Centos7 Init Shell
- 发布自己的Composer包
- git推送一直失败怎么办
- Beyond Compare过期解决办法
- 我的Navicat for Mysql
- 小错误解决办法
- CLoin报错CreateProcess error=216
- mysql error You must reset your password using ALTER USER statement before executing this statement.
- VM无法连接到虚拟机
- Jetbrains相关
- IntelliJ IDEA 笔记
- CLoin的配置与使用
- PhpStormDocker环境下配置Xdebug
- PhpStorm advanced metadata
- PhpStorm PHP_CodeSniffer