
### DNS域名解析负载均衡
DNS(Domain Name System)是因特网的一项服务,它作为域名和IP地址相互映射的一个分布式数据库,能够使人更方便的访问互联网。人们在通过浏览器访问网站时只需要记住网站的域名即可,而不需要记住那些不太容易理解的IP地址。
在DNS系统中有一个比较重要的的资源类型叫做主机记录也称为A记录,A记录是用于名称解析的重要记录,它将特定的主机名映射到对应主机的IP地址上。
如果你有一个自己的域名,那么要想别人能访问到你的网站,你需要到特定的DNS解析服务商的服务器上填写A记录,过一段时间后,别人就能通过你的域名访问你的网站了
## Domain Name System
一种能进行主机名到IP地址转换的目录服务,这就是域名系统(Domain Name System),DNS协议运行在UDP之上,使用端口53
DNS采用分布式设计方案,DNS服务器分为四类:
* 根DNS服务器。
* 顶级域DNS服务器。这些服务器负责顶级域名,如com,org,net,edu和gov以及国家的顶级域名,如uk,fr,ca,jp。
* 权威DNS服务器。这些服务器记录了主机名到IP地址的映射关系。
* 本地DNS服务器(local DNS server)
DNS查询有两种方式:
* 递归查询
* 迭代查询
从请求主机到本地DNS服务器的查询是递归的,其余的查询是迭代的
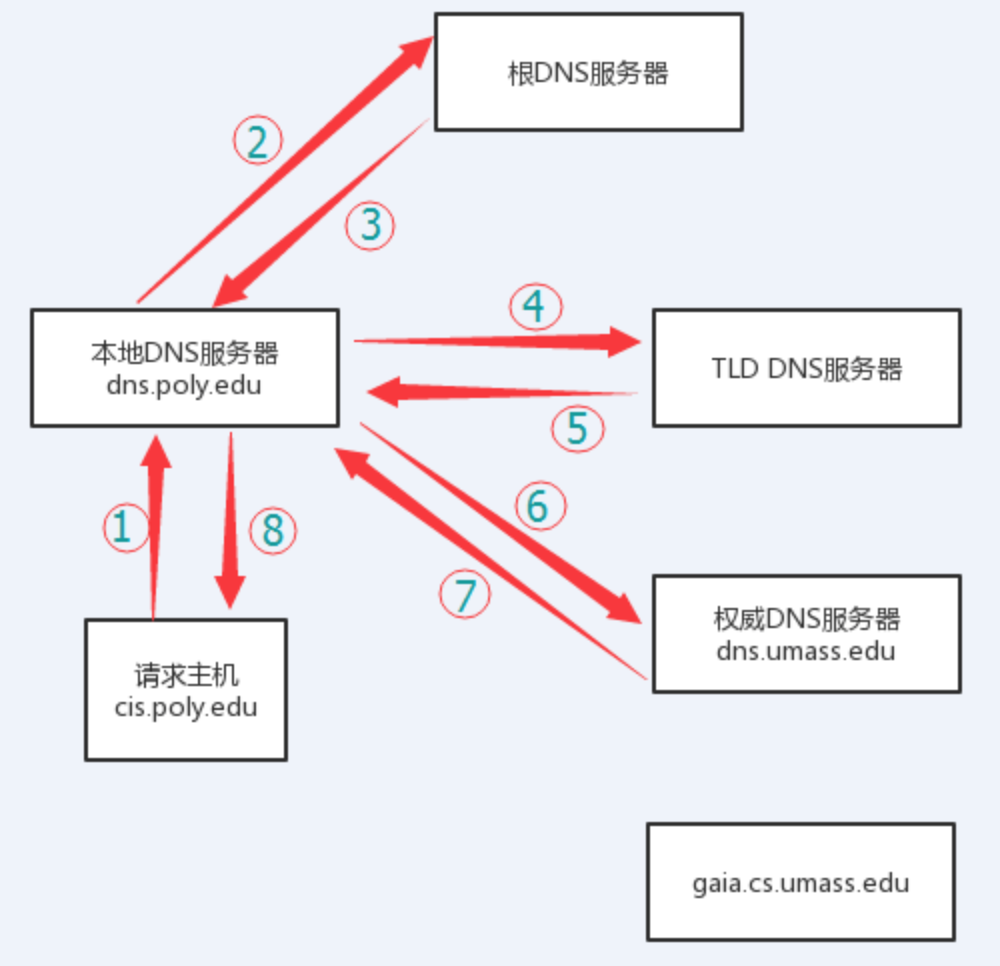
DNS解析过程:
### 神奇的解释权机制\(SOA\)
根服务器拥有一切域名的起始解释权,但是如果你去问根服务器它是不会直接告诉你最终答案的。因为如果它要存储所有的记录,那它也太累了,这个负载和开销是惊人的。那它会告诉你什么呢?它会告诉你应该去问谁,也就是它授权下一级服务器来解答你的问题。拟人化这个过程
> 1. 我: root, root 告诉我, segmentfault.com 怎么走?
> 2. root: 呵呵,你可以去问.com的dns服务器,地址是xxxxxx
> 3. 我: .com, .com 告诉我,segmentfault.com 怎么走?
> 4. .com: 呵呵,你可以去问segmentfault.com的dns服务器\(dnspod之类的\),地址是xxxxxx
> 5. 我: dnspod, dnspod 告诉我,segmentfault.com 怎么走?
> 6. dnspod: 拿着 xxxxxx,走你
###
### DNS负载均衡工作原理
利用DNS工作原理处理负载均衡的工作原理图:

由上图可以看出,在DNS服务器中应该配置了多个A记录,如:
```
www.apusapp.com IN A 114.100.20.201;
www.apusapp.com IN A 114.100.20.202;
www.apusapp.com IN A 114.100.20.203;
```
每次域名解析请求都会根据对应的负载均衡算法计算出一个不同的IP地址并返回,这样A记录中配置多个服务器就可以构成一个集群,并可以实现负载均衡。上图中,用户请求www.apusapp.com,DNS根据A记录和负载均衡算法计算得到一个IP地址114.100.20.203,并返回给浏览器,浏览器根据该IP地址,访问真实的物理服务器114.100.20.203。所有这些操作对用户来说都是透明的,用户可能只知道www.apusapp.com这个域名
### 优缺点
**DNS域名解析负载均衡有如下优点:**
> 1. 将负载均衡的工作交给DNS,省去了网站管理维护负载均衡服务器的麻烦。
> 2. 技术实现比较灵活、方便,简单易行,成本低,使用于大多数TCP/IP应用。
> 3. 对于部署在服务器上的应用来说不需要进行任何的代码修改即可实现不同机器上的应用访问。
> 4. 服务器可以位于互联网的任意位置。
> 5. 同时许多DNS还支持基于地理位置的域名解析,即会将域名解析成距离用户地理最近的一个服务器地址,这样就可以加速用户访问,改善性能。
**DNS域名解析也存在如下缺点:**
> 1. 目前的DNS是多级解析的,每一级DNS都可能缓存A记录,当某台服务器下线之后,即使修改了A记录,要使其生效也需要较长的时间,这段时间,DNS仍然会将域名解析到已下线的服务器上,最终导致用户访问失败。
> 2. 不能够按服务器的处理能力来分配负载。DNS负载均衡采用的是简单的轮询算法,不能区分服务器之间的差异,不能反映服务器当前运行状态,所以负载均衡效果并不是太好。
> 3. 可能会造成额外的网络问题。为了使本DNS服务器和其他DNS服务器及时交互,保证DNS数据及时更新,使地址能随机分配,一般都要将DNS的刷新时间设置的较小,但太小将会使DNS流量大增造成额外的网络问题。
## 有哪些DNS服务商支持负载均衡呢?
这是一种比较高级的服务,一般域名注册商的dns服务器不会支持,目前我已知支持它的服务商有
1. [AWS Route 53](http://aws.amazon.com/cn/route53/)
2. [NSONE](https://nsone.net/)
3. [Dyn](http://dyn.com/)
4. [dnspod](https://dnspod.cn/)
5. 万网——[https://wanwang.aliyun.com/](https://wanwang.aliyun.com/)
- 概述
- CAP理论
- BASE理论
- ACID
- 分布式系统相关技术
- 主流数据库连接池
- 基础
- 系统单点
- 负载均衡
- HTTP重定向负载均衡
- DNS域名解析负载均衡
- 反向代理负载均衡
- IP负载均衡
- 数据链路层负载均衡
- 负载均衡算法
- 轮询法(Round Robin)
- 加权轮询(Weight Round Robin)
- 随机算法(Random)
- 源地址Hash算法
- 加权随机法(Weight Random)
- 最小连接数法(Least Connections)
- 接入层负载均衡
- 软件架构
- 性能
- 性能测试指标
- 响应时间
- 并发数
- 吞吐量
- 性能计数器
- 性能测试方法
- 性能测试报告
- 性能优化
- Web前端性能优化
- 应用服务器性能优化
- 可用性
- 服务降级
- 伸缩性
- 扩展性
- 事件驱动架构
- 安全性
- 信息加密技术
- 分布式系统概述
- 自动化
- 分布式唯一ID
- 幂等设计
- 分布式锁
- 脑裂
- 一致性原理
- Paxos
- Zab
- Raft
- 分布式远程服务调用
- RMI
- Spring RMI
- WebService
- SOA服务架构
- 微服务架构
- 微服务的九大特性
- 服务注册和发现
- 解决方案及组件
- 分布式网关
- 注册中心
- Zookeeper
- ZNode
- Watch接口
- 持久节点-配置中心实现原理
- 临时节点-注册中心
- Zookeeper选举
- Zookeeper角色
- ZooKeeper工作原理
- 选主流程
- 同步流程
- Leader工作流程
- Follower工作流程
- 常见限流算法
- 计数器算法
- 漏桶算法
- 令牌桶算法
- 滑动窗口
- 计数器&滑动窗口
- 断路器
- 大流量高并发高可用
- 高可用
- 高并发/大流量
- 分布式缓存系统
- 基本概念
- 缓存命中率
- 缓存最大元素
- 缓存回收策略
- 回收算法
- 缓存穿透与缓存雪崩
- CDN缓存
- 缓存分类
- memcached
- 客户端路由原理
- 内存管理机制
- Redis
- Redis数据模型
- redisObject/Redis type/Redis encoding
- 命令的类型检查和多态
- skiplist跳跃表
- 为什么使用跳跃表
- redis-内存管理机制
- Redis淘汰策略
- Redis持久化策略
- Redis并发竞争
- redis主从复制
- Redis集群实现方案
- Redis Cluster
- redis事务
- Redis-Sentinel
- Redis适用场景
- Redis客户端
- redis rehash原理
- dict数据结构
- 触发rehash的条件
- 渐进式rehash
- 渐进式rehash过程
- Redis多线程版本
- 缓存实际应用
- 堆缓存-Guava Cache
- 主要参数
- Caffeine
- Spring注解缓存
- 分布式存储
- Database
- AUTOCOMMIT
- 脏读&幻读&不可重复读
- 子查询
- 连接
- 内连接
- 自连接
- 自然连接
- 外连接
- 组合查询
- 隔离级别
- 数据库范式
- 索引实现机制
- 数据库拆分
- 表分区
- 分库
- 分表
- MySQL
- MySQL基础架构
- 锁分类
- 排它锁&独占锁
- 共享锁
- 间隙锁
- 表级锁
- 存储引擎
- 磁盘IO
- 磁盘结构图
- 磁盘数据读写原理
- MySQL索引原理
- B+树索引
- 局部性原理
- 索引数据结构
- 联合索引
- 最左前缀匹配原则
- 建索引的几大原则
- 数据文件和索引文件
- 执行计划explain
- 常见问题
- 数据页
- MYSQL单表存储量计算
- 回表
- 索引覆盖
- 索引下推
- 页分裂和页合并
- InnoDB
- innodb索引
- Innodb引擎的底层实现
- MyISAM
- MyISAM引擎的底层实现
- MVCC
- Next-Key Locks
- MySQL索引类型
- MYSQL复制
- 主从复制
- 读写分离
- MySQL Dual-Master
- 分库分表实现方案
- MySQL事务实现原理
- MYSQL调优
- 性能优化
- HBase
- 不停机分库分表迁移
- RDBMS&NoSQL
- 分布式事务
- 协议或事务模型
- X/Open XA协议
- 分布式事务编程接口规范JTA
- TCC模型
- 解决方案
- 两阶段提交2PC
- 三阶段提交3PC
- Seata
- 分布式事务Seata产品模块
- AT模式
- TCC模式
- Saga模式
- XA模式
- 基于消息中间件的最终一致性事务方案
- 消息队列
- AMQP
- JMS
- ActiveMQ
- RabbitMQ
- RocketMQ
- RocketMQ基本概念
- 主要特性
- 分区顺序消息
- 全局顺序消息
- 消息可靠性
- 定时消息
- 消息重试
- 死信队列
- 分布式事务消息
- RocketMQ架构
- Producer
- Consumer
- NameServer
- Broker
- RocketMQ设计
- 消息存储
- 页缓存与内存映射
- 消息刷盘
- 通信机制
- console控制台
- RocketMQ部署架构
- Kafka
- Pulsar
- MQ消息重复消费与丢失
- 主流消息队列比较
- 分布式调度系统
- 分布式搜索
- 分布式计算
- 架构案例
- 秒杀业务
- 秒杀整体架构
- 常见的监控系统
- 小米手机抢购秒杀方案
- 架构师领导艺术
- 架构师箴言
- 技术leader核心职责
- WEB服务器
- Servlet
- Servlet实现
- Servlet生命周期
- Servlet容器工作模式
- Servlet工作原理
- servlet线程安全
- CGI&FastCGI
- CGI
- FastCGI
- FastCGI与CGI特点
- CGI与Servlet比较
- HTTP Server
- Nginx
- Apache
- Nginx与Apache比较
- Application Server
- Tomcat
- Tomcat总体架构
- Connector
- 连接器核心功能
- ProtocolHandler
- EndPoint
- Processor
- Adapter
- Container
- 请求定位Servlet的过程
- Lifecycle生命周期
- Tomcat模块设计
- Tomcat实例
- Tomcat运行原理
- spring & servlet
- Tomcat启动流程
- Tomcat支持的I/O模型
- Tomcat应用层协议
- Tomcat类加载机制
- Tomcat类加载器
- Tomcat类加载器层次
- Apache+Tomcat
- 序列化
- XML&JSON
- JSON
- JAVA原生序列化
- hessian
- 常见中间件
- Canal
- Databus
- ELK日志套件
- 数据库连接池
- spring状态机
- 常见解决方案
- 二维码扫码登录原理
- 前沿技术
- Saas服务
- 服务网格(Service Mesh)
- 云原生
- 常见面试问题
- Redis持久化的几种方式
- Redis的缓存失效策略
- 附录
- 二将军问题
- 常见问题定位步骤
- 如何快速熟悉新系统
- 制定技术方案套路
- NUMA陷阱