
[TOC]
## CSP 模型?
CSP 模型是“以通信的方式来共享内存”,不同于传统的多线程通过共享内存来通信。用于描述两个独立的并发实体通过共享的通讯 channel (管道)进行通信的并发模型。
## GMP
### GMP解释
G:Goroutine,实际上我们每次调用`go func`就是生成了一个 G。
P:Processor,处理器,一般 P 的数量就是处理器的核数,可以通过`GOMAXPROCS`进行修改。
M:Machine,系统线程。
在 GPM 模型,有一个全局队列(Global Queue):存放等待运行的 G,还有一个 P 的本地队列:也是存放等待运行的 G,但数量有限,不超过 256 个。
### GMP模型
在Go中,**线程是运行goroutine的实体,调度器的功能是把可运行的goroutine分配到工作线程上**
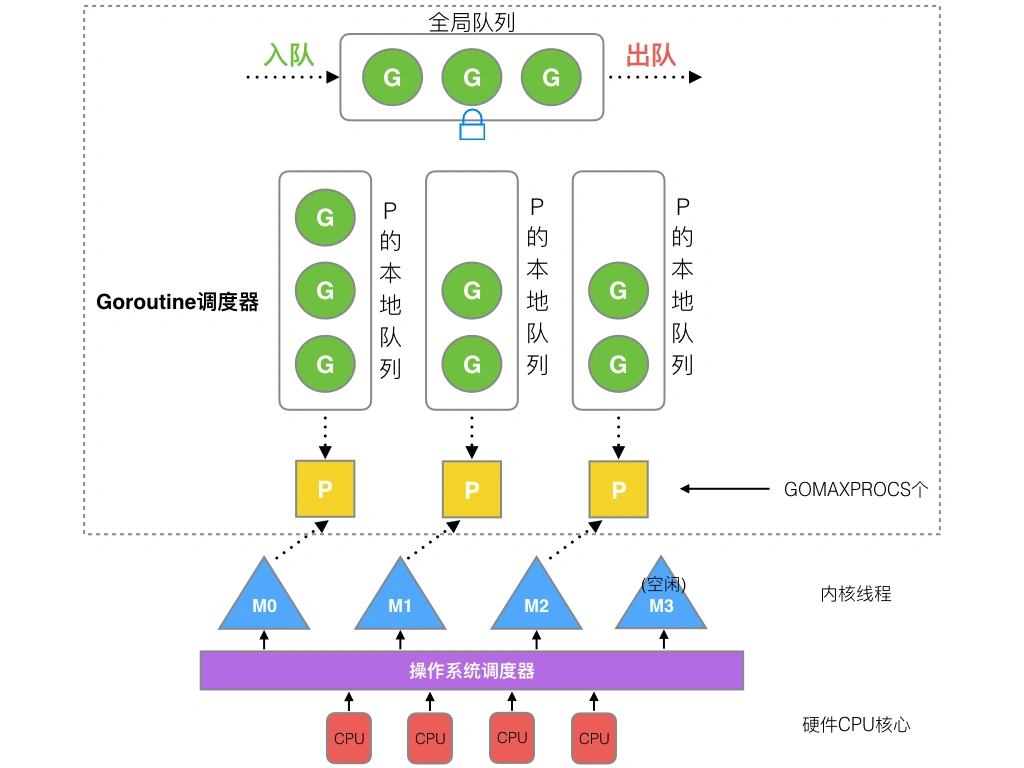
1. **全局队列**(Global Queue):存放等待运行的G。
2. **P的本地队列**:同全局队列类似,存放的也是等待运行的G,存的数量有限,不超过256个。新建G'时,G'优先加入到P的本地队列,如果队列满了,则会把本地队列中一半的G移动到全局队列。
3. **P列表**:所有的P都在程序启动时创建,并保存在数组中,最多有`GOMAXPROCS`(可配置)个。
4. **M**:线程想运行任务就得获取P,从P的本地队列获取G,P队列为空时,M也会尝试从全局队列**拿**一批G放到P的本地队列,或从其他P的本地队列**偷**一半放到自己P的本地队列。M运行G,G执行之后,M会从P获取下一个G,不断重复下去。
**Goroutine调度器和OS调度器是通过M结合起来的,每个M都代表了1个内核线程,OS调度器负责把内核线程分配到CPU的核上执行**。
> #### 有关P和M的个数问题
1、P的数量:
* 由启动时环境变量`$GOMAXPROCS`或者是由`runtime`的方法`GOMAXPROCS()`决定。这意味着在程序执行的任意时刻都只有`$GOMAXPROCS`个goroutine在同时运行。
2、M的数量:
* go语言本身的限制:go程序启动时,会设置M的最大数量,默认10000.但是内核很难支持这么多的线程数,所以这个限制可以忽略。
* runtime/debug中的SetMaxThreads函数,设置M的最大数量
* 一个M阻塞了,会创建新的M。
M与P的数量没有绝对关系,一个M阻塞,P就会去创建或者切换另一个M,所以,即使P的默认数量是1,也有可能会创建很多个M出来。
> #### P和M何时会被创建
1、P何时创建:在确定了P的最大数量n后,运行时系统会根据这个数量创建n个P。
2、M何时创建:没有足够的M来关联P并运行其中的可运行的G。比如所有的M此时都阻塞住了,而P中还有很多就绪任务,就会去寻找空闲的M,而没有空闲的,就会去创建新的M。
### 调度器的设计策略
**复用线程**:避免频繁的创建、销毁线程,而是对线程的复用。
1)work stealing机制
当本线程无可运行的G时,尝试从其他线程绑定的P偷取G,而不是销毁线程。
2)hand off机制
当本线程因为G进行系统调用阻塞时,线程释放绑定的P,把P转移给其他空闲的线程执行。
**利用并行**:`GOMAXPROCS`设置P的数量,最多有`GOMAXPROCS`个线程分布在多个CPU上同时运行。`GOMAXPROCS`也限制了并发的程度,比如`GOMAXPROCS = 核数/2`,则最多利用了一半的CPU核进行并行。
**抢占**:在coroutine中要等待一个协程主动让出CPU才执行下一个协程,在Go中,一个goroutine最多占用CPU 10ms,防止其他goroutine被饿死,这就是goroutine不同于coroutine的一个地方。
**全局G队列**:在新的调度器中依然有全局G队列,但功能已经被弱化了,当M执行work stealing从其他P偷不到G时,它可以从全局G队列获取G。
### GMP调度流程
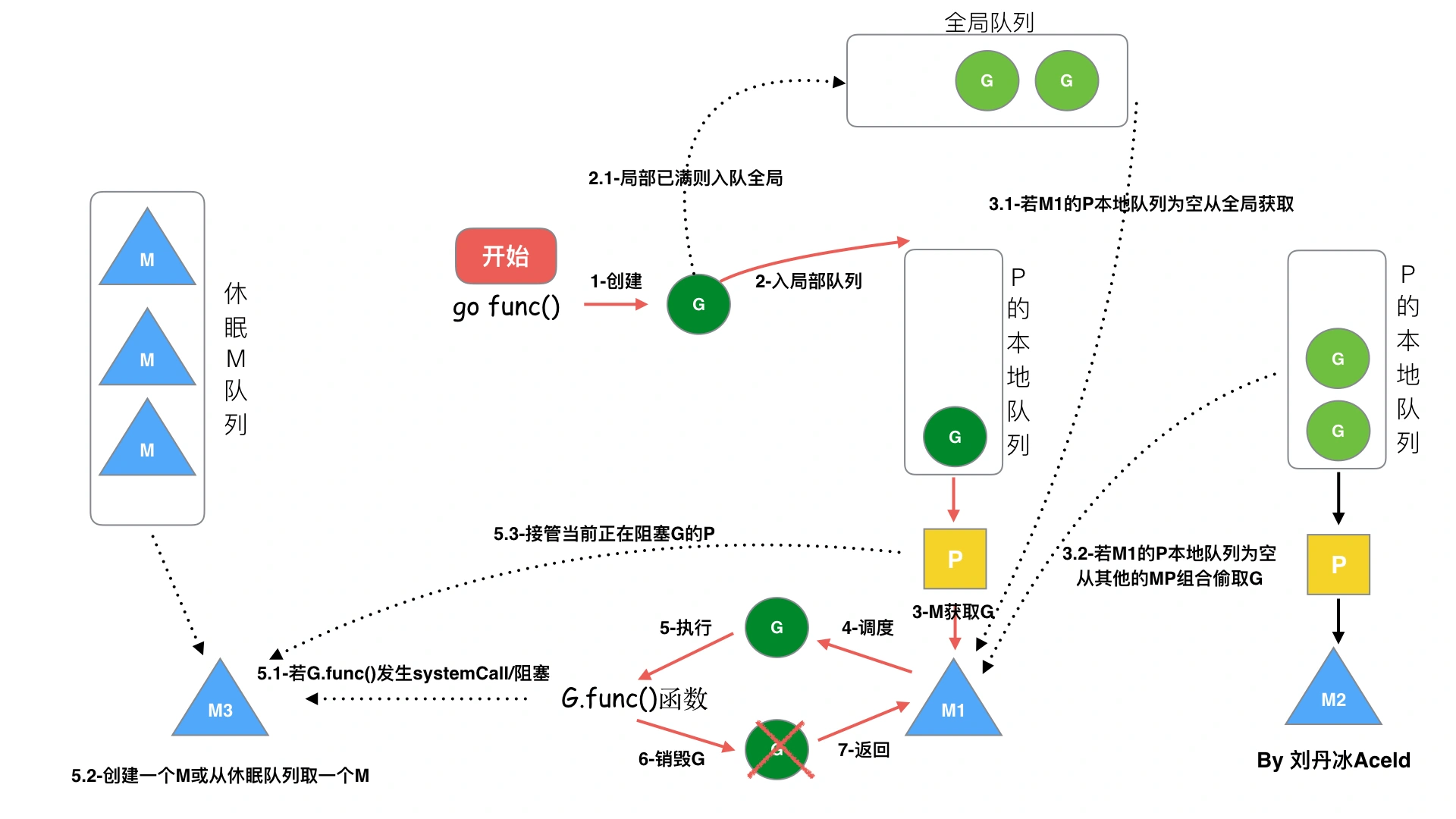
1、 GPM 的调度流程从 go func()开始创建一个 goroutine,新建的G优先放入P的本地队列保存待执行的 goroutine(流程 2),当 M 绑定的 P 的的局部队列已经满了之后就会把 goroutine 放到全局队列(流 程 2-1)
2、每个 P 和一个 M 绑定,M 是真正的执行 P 中 goroutine 的实体(流程 3), M 从绑定的 P 中的局部队列获取 G 来执行
3、当 M 绑定的 P 的局部队列为空时,M 会从全局队列获取到本地队列来执行 G (流程 3.1),当从全局队列中没有获取到可执行的 G 时候,M 会从其他 P 的局部队列中偷取 G 来执行(流程 3.2),这种从其他 P 偷的方式称为 work stealing
4、一个M调度G执行的过程是一个循环机制
5、 当 G 因系统调用(syscall)阻塞时会阻塞 M,此时 P 会和 M 解绑即 hand off,并寻找新的空闲的 M,若没有空闲的 M 就会新建一个 M(流程 5.1)
6、当 G 因 channel 或者 network I/O 阻塞时,不会阻塞 M,M 会寻找其他的 G;当阻塞的 G 恢复后会重新进入 runnable 进入 P 队列等待执 行(流程 5.3)
7、 当M系统调用结束时候,这个G会尝试获取一个空闲的P执行,并放入到这个P的本地队列。如果获取不到P,则将G放入全局队列,等待被其他的P调度。然后M将进入缓存池睡眠。
### GMP 中 work stealing 机制
获取 P 本地队列,当从绑定 P 本地 runq 上找不到可执行的 g,尝试从全局链 表中拿,再拿不到从 netpoll 和事件池里拿,最后会从别的 P 里偷任务。P 此时去唤醒一个 M。P 继续执行其它的程序。M 寻找是否有空闲的 P,如果有则 将该 G 对象移动到它本身。接下来 M 执行一个调度循环(调用 G 对象->执行-> 清理线程→继续找新的 Goroutine 执行)
### hand off 机制
当本线程 M 因为 G 进行的系统调用阻塞时,线程释放绑定的 P,把 P 转移给其 他空闲的 M 执行。
细节:当发生上线文切换时,需要对执行现场进行保护,以便下次被调度执行 时进行现场恢复。Go 调度器 M 的栈保存在 G 对象上,只需要将 M 所需要的寄存 器(SP、PC 等)保存到 G 对象上就可以实现现场保护。当这些寄存器数据被保 护起来,就随时可以做上下文切换了,在中断之前把现场保存起来。如果此时 G 任务还没有执行完,M 可以将任务重新丢到 P 的任务队列,等待下一次被调度 执行。当再次被调度执行时,M 通过访问 G 的 vdsoSP、vdsoPC 寄存器进行现场 恢复(从上次中断位置继续执行)。
### **抢占式调度是如何抢占的**
#### 协作式的抢占式调度
1. 如果 sysmon 监控线程发现有个协程 A 执行之间太长了(或者 gc 场景,或者 stw 场景),那么会友好的在这个 A 协程的某个字段设置一个抢占标记 ;
2. 协程 A 在 call 一个函数的时候,会复用到扩容栈(morestack)的部分逻辑,检查到抢占标记之后,让出 cpu,切到调度主协程里;
之所以说 v1.2 的抢占式调用是临时的优化方案,是因为这种抢占式调度是基于协作的。在一些的边缘场景下,协程还是在会独自占用整个线程无法让出。
从上面的流程中,你应该可以注意到,A 调度权被抢占有个前提:A 必须主动 call 函数,这样才能有走到 morestack 的机会。
等着主动让出,会出现
#### 基于信号的抢占式调度
不管是否愿意让出cpu只要运行超过20ms,就会发现号强行抢占cpu
>极客时间的解释
在任何情况下,Go 运行时并行执行(注意,不是并发)的 goroutines 数量是 小于等于 P 的数量的。为了提高系统的性能,P 的数量肯定不是越小越好,所 以官方默认值就是 CPU 的核心数,设置的过小的话,如果一个持有 P 的 M, 由于 P 当前执行的 G 调用了 syscall 而导致 M 被阻塞,那么此时关键点: GO 的调度器是迟钝的,它很可能什么都没做,直到 M 阻塞了相当长时间以 后,才会发现有一个 P/M 被 syscall 阻塞了。然后,才会用空闲的 M 来强这 个 P。通过 sysmon 监控实现的抢占式调度,最快在 20us,最慢在 10-20ms 才 会发现有一个 M 持有 P 并阻塞了。操作系统在 1ms 内可以完成很多次线程调 度(一般情况 1ms 可以完成几十次线程调度),Go 发起 IO/syscall 的时候执 行该 G 的 M 会阻塞然后被 OS 调度走,P 什么也不干,sysmon 最慢要 10-20ms 才能发现这个阻塞,说不定那时候阻塞已经结束了,这样宝贵的 P 资源就这么 被阻塞的 M 浪费了。
```
runtime.GOMAXPROCS(1)
fmt.Println("The program starts ...")
go func() {
for {
}
}()
time.Sleep(time.Second)
fmt.Println("I got scheduled!")
```
这段代码在1.14之前就会死循环,在之后就会直接跳出
**基于信号的抢占式调度,抢占也只会在垃圾回收扫描任务时触发**
### GMP 调度过程中存在哪些阻塞
1. I/O,select
2. block on syscall
3. channel
4. 等待锁
5. runtime.Gosched()
### Sysmon 有什么作用
Sysmon 也叫监控线程,变动的周期性检查,好处
* 释放闲置超过 5 分钟的 span 物理内存;
* 如果超过 2 分钟没有垃圾回收,强制执行;
* 将长时间未处理的 netpoll 添加到全局队列;
* 向长时间运行的 G 任务发出抢占调度(超过 10ms 的 g,会进行 retake);
* 收回因 syscall 长时间阻塞的 P;
### G-M-P的数量关系
* M:有限制,默认数量限制是 10000,可调整。(debug.SetMaxThreads 设置)
* G:没限制,但受内存影响。
~~~
假设一个 Goroutine 创建需要 4k:
4k * 80,000 = 320,000k ≈ 0.3G内存
4k * 1,000,000 = 4,000,000k ≈ 4G内存
以此就可以相对计算出来一台单机在通俗情况下,所能够创建 Goroutine 的大概数量级别。
注:Goroutine 创建所需申请的 2-4k 是需要连续的内存块。
~~~
* P:受本机的核数影响,可大可小,不影响 G 的数量创建。(**`GOMAXPROCS`**)
### 调度器的生命周期
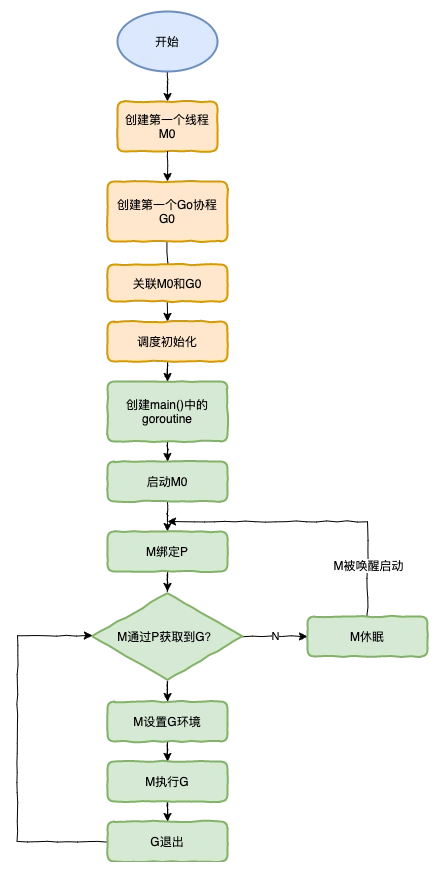
特殊的M0和G0
**M0**
`M0`是启动程序后的编号为0的主线程,这个M对应的实例会在全局变量runtime.m0中,不需要在heap上分配,M0负责执行初始化操作和启动第一个G, 在之后M0就和其他的M一样了。
**G0**
`G0`是每次启动一个M都会第一个创建的gourtine,G0仅用于负责调度的G,G0不指向任何可执行的函数, 每个M都会有一个自己的G0。在调度或系统调用时会使用G0的栈空间, 全局变量的G0是M0的G0。
- Go准备工作
- 依赖管理
- Go基础
- 1、变量和常量
- 2、基本数据类型
- 3、运算符
- 4、流程控制
- 5、数组
- 数组声明和初始化
- 遍历
- 数组是值类型
- 6、切片
- 定义
- slice其他内容
- 7、map
- 8、函数
- 函数基础
- 函数进阶
- 9、指针
- 10、结构体
- 类型别名和自定义类型
- 结构体
- 11、接口
- 12、反射
- 13、并发
- 14、网络编程
- 15、单元测试
- Go常用库/包
- Context
- time
- strings/strconv
- file
- http
- Go常用第三方包
- Go优化
- Go问题排查
- Go框架
- 基础知识点的思考
- 面试题
- 八股文
- 操作系统
- 整理一份资料
- interface
- array
- slice
- map
- MUTEX
- RWMUTEX
- Channel
- waitGroup
- context
- reflect
- gc
- GMP和CSP
- Select
- Docker
- 基本命令
- dockerfile
- docker-compose
- rpc和grpc
- consul和etcd
- ETCD
- consul
- gin
- 一些小点
- 树
- K8s
- ES
- pprof
- mycat
- nginx
- 整理后的面试题
- 基础
- Map
- Chan
- GC
- GMP
- 并发
- 内存
- 算法
- docker