
[TOC]
https://www.jianshu.com/p/59999ddc0a6a
https://mp.weixin.qq.com/s/hY2zBZqzMjVSIgnDK19EUQ
https://blog.csdn.net/ZHHX666/article/details/125978591
https://www.cnblogs.com/wscw/p/16389764.html
https://blog.csdn.net/Zach1Lavine/article/details/124958771
https://blog.csdn.net/qq_44954571/article/details/122835659
ES默认端口:9200;
kibana默认端口:5601
### ES和Mysql 对比
| 类型 | | | | |
| --- | --- | --- | --- | --- |
| ES | 索引(index) | 类型(type) | 文档(document) | field(每条数据里面的字段) |
| Mysql | 库 | 表 | 行记录 |列|
### 数据类型
> 仅对比,不是相等
| es | | mysql |
| --- | --- |--- |
|integer | | int |
| long | | bigint |
| date | 时间戳 | timestamp |
| byte | | tinyint |
。。。
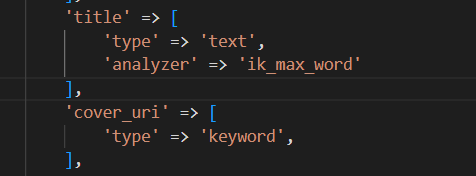
### keyword和text区别
* keyword不会进行分词,直接把字符串建立倒排索引
* text,先分词,再建立倒排索引
### 节点 node
#### 主节点 MasterNode
负责集群节点状态的维护,索引的创建,删除,数据的 rebalance,分片的分配等工作,不负责具体数据的索引和检索
#### 数据节点 DataNode
负责集群中数据的写入和检索,属于 IO,内存 和 CPU 密集型操作,需要的计算资源大
#### 提取节点 IngestNode
数据预处理通道,在数据被索引前预先处理文档。
#### 协调节点 CoordinatingNode
接受客户端请求,然后转发到数据节点,最后将各个节点返回来的数据进行整合。对应着**两个阶段**
1. **分散阶段,协调节点将请求转发到保存数据的数据节点**
2. **收集阶段,协调节点将每个数据节点的结果缩减为单个全局结果集**
### 分片 Shard 和 副本 Replica
Elasticsearch 的 索引是以分片的方式来组织的,每个分片就是 Lucene 中的索引。
分片分为**主分片**和**副本分片**,默认配置是 每个索引 5 个主分片,每个主分片都有一个副本分片,主分片和它的副本不在一个节点上,主要作用是**故障转移和负载均衡**

## 倒排索引的结构

其中主要有如下几个核心术语需要理解:
* **词条(Term):** 索引里面最小的存储和查询单元,对于英文来说是一个单词,对于中文来说一般指分词后的一个词。
* **词典(Term Dictionary):** 或字典,是词条 Term 的集合。搜索引擎的通常索引单位是单词,单词词典是由文档集合中出现过的所有单词构成的字符串集合,单词词典内每条索引项记载单词本身的一些信息以及指向“倒排列表”的指针。
* **倒排表(Post list):** 一个文档通常由多个词组成,倒排表记录的是某个词在哪些文档里出现过以及出现的位置。每条记录称为一个倒排项(Posting)。倒排表记录的不单是文档编号,还存储了词频等信息。
* **倒排文件(Inverted File):** 所有单词的倒排列表往往顺序地存储在磁盘的某个文件里,这个文件被称之为倒排文件,倒排文件是存储倒排索引的物理文件。
从上图我们可以了解到倒排索引主要由两个部分组成:
* 词典(存储在内存)
* 倒排文件(存储在磁盘)
词典和倒排表是 Lucene 中很重要的两种数据结构,是实现快速检索的重要基石。
## ES 机制原理
>master 只负责把集群状态信息的改变同步到其他节点,只有之间里索引和类型时才会需要master节点
### 写索引原理
写索引是只能写在主分片上,然后同步到副本分片
#### 文档怎么路由到对应的分片上
公式:
>shard = hash(routing) % number_of_primary_shards
`routing`是一个可变值,默认是文档的`_id`,也可以设置成一个自定义的值。`routing`通过 hash 函数生成一个数字,然后这个数字再除以`number_of_primary_shards`(主分片的数量)后得到**余数**。这个分布在`0`到`number_of_primary_shards-1`之间的余数,就是我们所寻求的文档所在分片的位置。
这就解释了为什么我们要在创建索引的时候就确定好主分片的数量 并且永远不会改变这个数量:因为如果数量变化了,那么所有之前路由的值都会无效,文档也再也找不到了。
由于在 ES 集群中每个节点通过上面的计算公式都知道集群中的文档的存放位置,所以每个节点都有处理读写请求的能力。
在一个写请求被发送到某个节点后,该节点即为前面说过的协调节点,协调节点会根据路由公式计算出需要写到哪个分片上,再将请求转发到该分片的主分片节点上
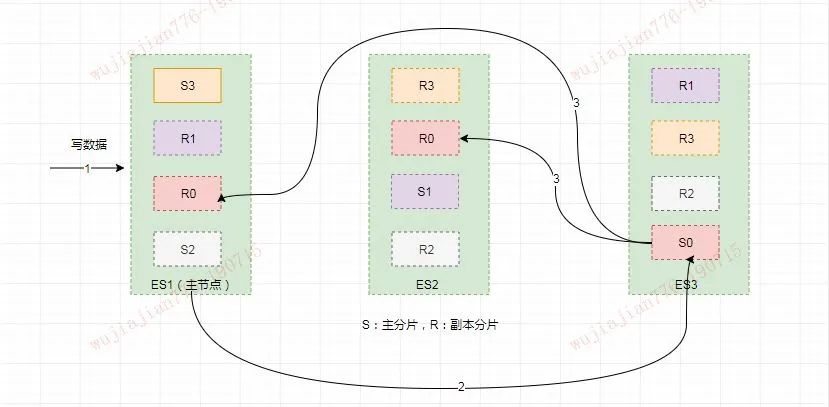
假如此时数据通过路由计算公式取余后得到的值是 `shard=hash(routing)%4=0`。
则具体流程如下:
* 客户端向 ES1 节点(协调节点)发送写请求,通过路由计算公式得到值为 0,则当前数据应被写到主分片 S0 上。
* ES1 节点将请求转发到 S0 主分片所在的节点 ES3,ES3 接受请求并写入到磁盘。
* 并发将数据复制到两个副本分片 R0 上,其中通过乐观并发控制数据的冲突。一旦所有的副本分片都报告成功,则节点 ES3 将向协调节点报告成功,协调节点向客户端报告成功。
## 查询
### 全文级别查询
match 是一个标准查询,可以查询文本、数字、日期格式的数据。match 查询的一个主要用途是全文检索
#### match
~~~
GET /_search
{
"query": {
"match" : {
"message" : "hello world"
}
}
}
~~~
#### match_phrase (match_phrase 与match查询不同,它是精确匹配)
~~~
GET /_search
{
"query": {
"match_phrase" : {
"message" : "this is a test"
}
}
}
~~~
#### multi_match(允许在做match 查询的基础上查询多个字段)
~~~
GET /_search
{
"query":{
"multi_match": {
"query": "full text search",
"fields": [ "title", "body" ]
}
}
}
~~~
### 词条级别查询
erm 用于精确值的查询。使用boost参数可以提高指定字段的分数。boost的默认值为1。
string类型的数据在ES中可以使用text或者keyword的类型来存储。ES存储text类型的数据时会自动分词,然后建立索引。keyword存储数据时,不会分词,直接建立索引。如果需要对string数据进行精确查询,应该使用keyword的类型来存储数据。
#### term
~~~
GET /_search
{
"query":{
"bool":{
"should":[
{
"term":{
"status":{
"value":"urgent",
"boost":2
}
}
},
{
"term":{
"status":"normal"
}
}
]
}
}
}
~~~
#### terms 可以指定一个字段的多个精确值。
~~~
GET /_search
{
"query": {
"constant_score" : {
"filter" : {
"terms" : { "user" : ["kimchy", "elasticsearch"]}
}
}
}
}
~~~
#### range
用于需要查询指定范围的内容。range 的常用参数有gte (greater-than or equal to), gt (greater-than) ,lte (less-than or equal to) 和 lt (less-than)。ES 的date类型的数值也可以使用range查询。
~~~ada
GET /_search
{
"query": {
"range" : {
"age" : {
"gte" : 10,
"lte" : 20,
"boost" : 2.0
}
}
}
}
~~~
#### exists 返回在原始字段汇中至少有一个非空值的文档
~~~routeros
GET /_search
{
"query": {
"exists" : { "field" : "user" }
}
}
~~~
#### 前缀
~~~routeros
GET /_search
{
"query": {
"prefix": {
"postcode": "W1"
}
}
}
~~~
### 复合查询
bool 查询可以合并多个过滤条件查询的结果。bool 查询可由 must, should, must not, filter 组合完成
* must 查询的内容必须出现在检索到的文档中,并且会计算文档匹配的相关度
* filter 查询的内容必须出现在检索到的文档中。与must不同,filter中的查询条件不会参与评分。filter对查询的数据有缓存功能。filter效率会比must高一些,一般,除了需要计算相关度的查询,一般使用filter
* should 至少有一个查询条件匹配,相当于 or
* must\_mot 多个查询条件的相反匹配,相当于 not
~~~routeros
GET /_search
{
"query":{
"bool":{
"must":{
"term":{
"user":"kimchy"
}
},
"filter":{
"term":{
"tag":"tech"
}
},
"must_not":{
"range":{
"age":{
"gte":10,
"lte":20
}
}
},
"should":[
{
"term":{
"tag":"wow"
}
},
{
"term":{
"tag":"elasticsearch"
}
}
]
}
}
}
~~~
## 聚合
`聚合(aggregations)`:可以实现对文档数据的统计、分析、运算。
聚合常见的有三类:
* 桶(Bucket)排序:用来对文档做分组。
* TermAggregation:按照文档字段值分组。
* Date Histogram:按照日期阶梯分组,例如一周为一组,或者一月为一组。
度量(Metric)聚合:用以计算一些值,比如:最大值、最小值、平均值等
* Avg:求平均值
* Max:求最大值
* Min:求最小值
* Stats:同时求max、min、avg、sum等
管道(pipeline)聚合:其它聚合的结果为基础做聚合。
参与聚合的字段类型必须是:
* keyword
* 数值
* 日期
* 布尔
### DSL实现Bucket聚合
>案例一:统计所有数据中的酒店品牌,此时可以根据酒店品牌名称做聚合。
```
GET /hotel1/_search
{
"size": 0, // 设置size为0,结果中不包含文档,只包含聚合结果
"aggs": { // 定义聚合
"brandAggs": {
"terms": { // 聚合类型,按照品牌值聚合
"field": "brand", // 参与聚合的字段
"size": 20 // 希望获取的聚合结果数量
}
}
}
}
```
>案例二:聚合结果排序
```
# 聚合功能,自定义排序规则
GET /hotel1/_search
{
"size": 0,
"aggs": {
"brandAggs": {
"terms": {
"order": {
"_count": "asc"
},
"field": "brand",
"size": 30
}
}
}
}
```
>限定聚合范围
```
# 聚合功能,自定义聚合范围
GET /hotel1/_search
{
"query": {
"range": {
"price": {
"lte": 200
}
}
},
"size": 0,
"aggs": {
"brandAggs": {
"terms": {
"field": "brand",
"size": 20
}
}
}
}
```
总结:
aggs代表聚合,与query同级,此时query的作用是限定聚合文档的范围。
聚合必须的三要素:
* 聚合名称
* 聚合类型
* 聚合字段
聚合可配置属性:
* size:指定聚合结果数量。
* order:指定聚合结果排序方式。
* field:指定聚合字段。
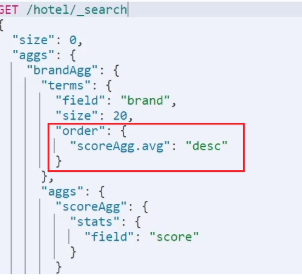
### Metric聚合语法
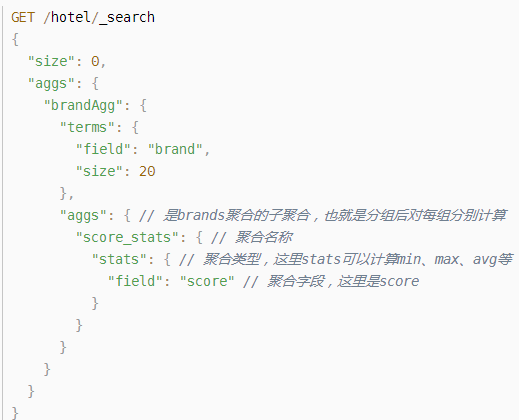
还可以给聚合结果做个排序

## ES 集群配置
### **集群搭建的实现步骤**
**eg:**
> 第一步:准备三台服务器
服务器名称 IP地址
node-1 192.168.86.130
node-2 192.168.86.131
node-3 192.168.86.132
>第二步:服务器集群配置
/opt/application/es6.7.0下执行cd config命令后,再执行vi elasticsearch.yml命令,然后修改:
1、cluster.name: myes 保证三台服务器节点集群名称相同
2、node.name: node-1 每个节点名称不一样,其他两台为node-2,node-3
3、network.host: 192.168.86.130 实际服务器的ip地址
4、discovery.zen.ping.unicast.hosts: ["192.168.86.130", "192.168.86.131","192.168.86.132"] 多个服务集群ip
5、discovery.zen.minimum_master_nodes:1
6、关闭防火墙 systemctl stop firewalld.service
三台服务器都做同样的配置步骤,只有2和3不一样,其他一模一样。
>第三步:验证集群效果
在浏览器中输入:http://192.168.86.130/_cat/nodes?pretty
### **如何处理高并发场景**
1、分布式ElasticSearch
ElasticSearch是一个分布式全文检索框架,隐藏了复杂的处理机制,内部使用分片机制、集群发现、分片负载均衡请求路由。
2、Shards分片
Shards分片:代表索引分片,ElasticSearch可以把一个完整的索引分成多个分片,这样的好处是可以把一个大的索引拆分成多个,分布到不同的节点上。构成分布式搜索。分片的数量只能在索引创建前指定,并且索引创建后不能更改。
3、Replicas分片
Replicas分片:代表索引副本,ElasticSearch可以设置多个索引的副本,副本的作用一是提高系统的容错性,当某个节点某个分片损坏或丢失时可以从副本中恢复。二是提高ElasticSearch的查询效率,ElasticSearch会自动对搜索请求进行负载均衡。
### **集群核心原理分析**
> 什么是primary shards
每个索引会被分成多个分片shards进行存储,默认创建索引是分配5个分片进行存储,每个分片都会分布式部署在多个不同的节点上,该分片成为primary shards主分片。查看索引分片信息http://192.168.86.130:9200/mytest/\_settings:索引的主分片数量定义好后,不能修改。
>主分片如何实现高可用
每一个主分片为了实现高可用,都会有自己对应的备份分片,主分片对应的备份分片不能存放同一台服务器上。就说明单台ElasticSearch服务器上是没有备份分片的。
### **大数量提高查询效率**
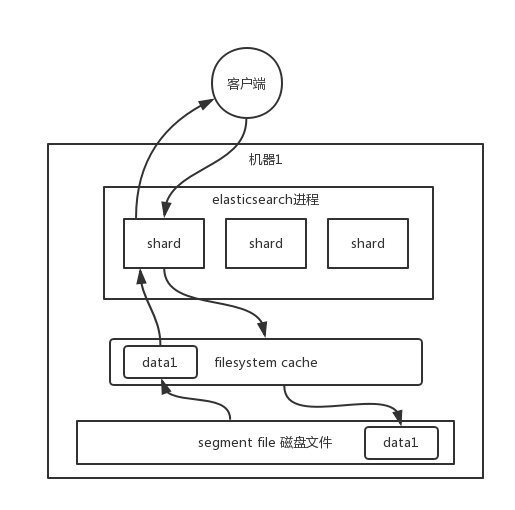
数据实际上都写到磁盘文件里去了,查询的时候,操作系统会将磁盘文件里的数据自动缓存到`filesystem cache`里面去,所以为了加快查询效率,就要尽量使得查询的数据在filesystem cache中,避免去磁盘文件查询数据
1、尽量使得es可以有一半的数据在filesystem cache中
2、尽量存储用于查询的数据,不要把无关数据都存进去,避免无关数据占用filesystem cache的空间
3、数据预热,对数据的搜索的做统计,把热数据通过脚本每隔一段时间访问一次,保证热数据在filesystem cache
4、不要深分页,因为效率会很低,例如:发送一条取前100条数据,实际上是把每个shard取100条,数据聚合后再进入排序返回,速度很慢
5、冷热索引,把冷热数据存在不能机器,避免冷数据占用cache
### **JVM 调优建议如下**:
* 确保堆内存最小值( Xms )与最大值( Xmx )的大小是相同的,防止程序在运行时改变堆内存大小。Elasticsearch 默认安装后设置的堆内存是 1GB。可通过` ../config/jvm.option` 文件进行配置,但是最好不要超过物理内存的50%和超过 32GB。
* GC 默认采用 CMS 的方式,并发但是有 STW 的问题,可以考虑使用 G1 收集器。
* ES 非常依赖文件系统缓存(Filesystem Cache),快速搜索。一般来说,应该至少确保物理上有一半的可用内存分配到文件系统缓存。
- Go准备工作
- 依赖管理
- Go基础
- 1、变量和常量
- 2、基本数据类型
- 3、运算符
- 4、流程控制
- 5、数组
- 数组声明和初始化
- 遍历
- 数组是值类型
- 6、切片
- 定义
- slice其他内容
- 7、map
- 8、函数
- 函数基础
- 函数进阶
- 9、指针
- 10、结构体
- 类型别名和自定义类型
- 结构体
- 11、接口
- 12、反射
- 13、并发
- 14、网络编程
- 15、单元测试
- Go常用库/包
- Context
- time
- strings/strconv
- file
- http
- Go常用第三方包
- Go优化
- Go问题排查
- Go框架
- 基础知识点的思考
- 面试题
- 八股文
- 操作系统
- 整理一份资料
- interface
- array
- slice
- map
- MUTEX
- RWMUTEX
- Channel
- waitGroup
- context
- reflect
- gc
- GMP和CSP
- Select
- Docker
- 基本命令
- dockerfile
- docker-compose
- rpc和grpc
- consul和etcd
- ETCD
- consul
- gin
- 一些小点
- 树
- K8s
- ES
- pprof
- mycat
- nginx
- 整理后的面试题
- 基础
- Map
- Chan
- GC
- GMP
- 并发
- 内存
- 算法
- docker