
[TOC]
## etcd
* 端口:2379
https://zhuanlan.zhihu.com/p/405811320
https://developer.aliyun.com/article/11035?spm=a2c6h.12873639.article-detail.61.630bc264HCgp1g
https://www.cnblogs.com/aganippe/p/16009137.html
### etcd的数据构成
raft_term:leader的任期,递增的,没进行一次选举,这个值就会+1
revision:全局版本号,只要etcd发生改变就会+1
create_revision:创建key的版本号,即当时的revision数据
mod_revision:修改key的版本号
## ETCD工作原理
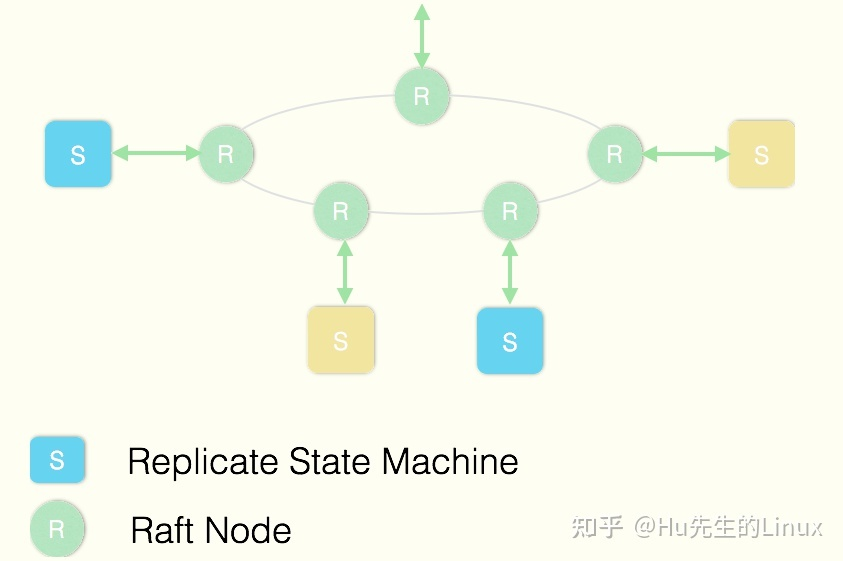
ETCD使用Raft协议来维护集群内各个节点状态的一致性。简单说,ETCD集群是一个分布式系统,由多个节点相互通信构成整体对外服务,每个节点都存储了完整的数据,并且通过Raft协议保证每个节点维护的数据是一致的。
## V3版本架构图
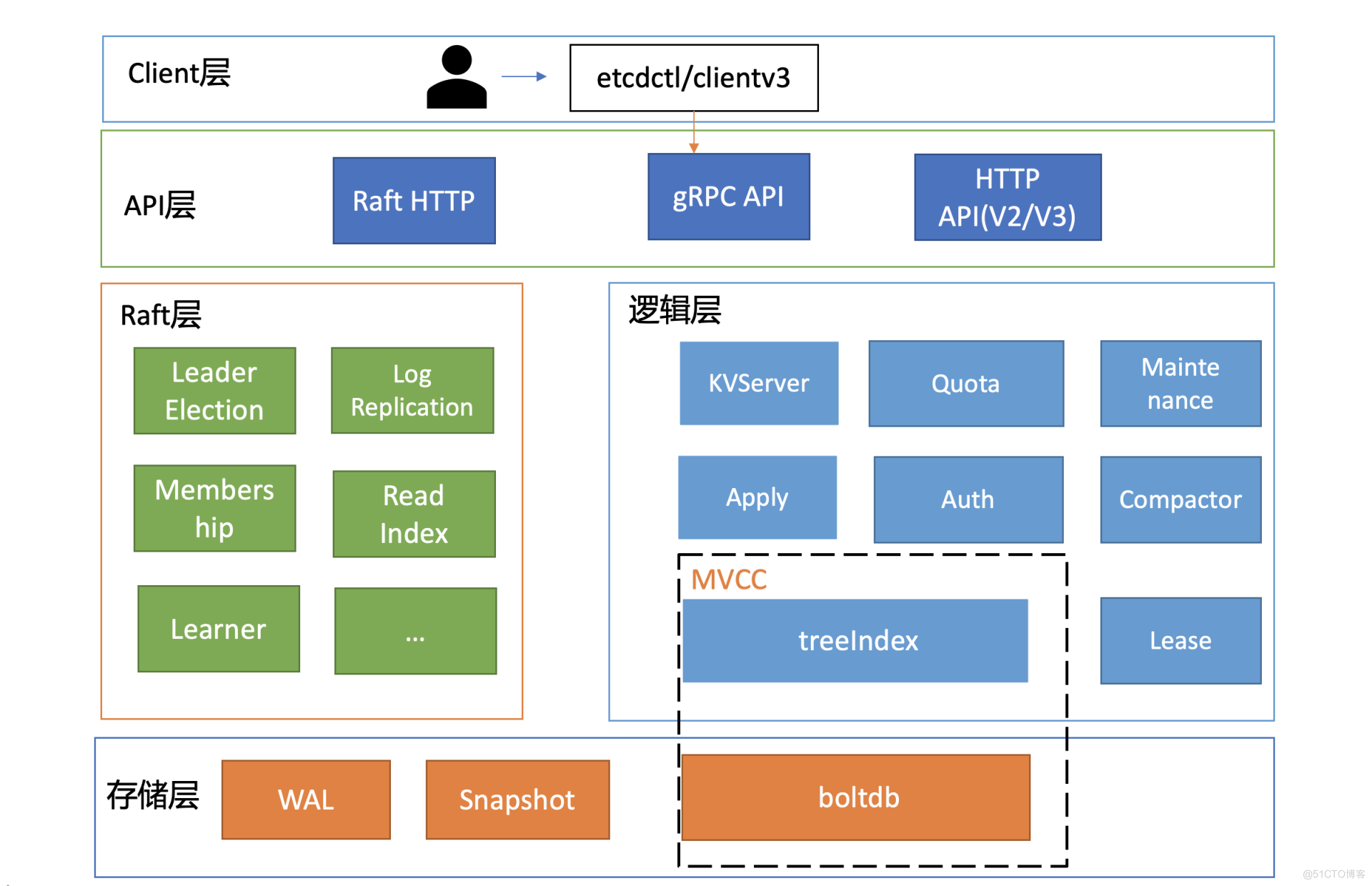
* Client 层:Client 层包括 client v2 和v3 两个大版本 API 客户端库,提供了简洁易用的
API,同时支持负载均衡、节点间故障自动转移,可极大降低业务使用etcd 复杂度,提
升开发效率、服务可用性。
* API 网络层:API 网络层主要包括 dlient 访问 server 和 server 节点之间的通信协议。
一方面,client 访问 etcd server 的API 分为v2和v3 两个大版本。V2 API 使用
HTTP/1.x 协议,V3 API 使用 gRPC 协议。同时v3通过etcd grpc-gateway 组件也支
持 HTTP/1.x 协议,便于各种语言的服务调用。另一方面,server 之间通信协议,是指
节点间通过 Raft 算法实现数据复制和 Leader 选举等功能时使用的 HTTP 协议。
* Raft 算法层:Raft 算法层实现了 Leader 选举、日志复制、Readlndex 等核心算法特
性,用于保障 etcd 多个节点间的数据一致性、提升服务可用性等,是etcd 的基石和亮
点。
* 功能逻辑层:etcd 核心特性实现层,如典型的 KVServer 模块、MVCC 模块、Auth 鉴
权模块、Lease 租约模块、Compactor 压缩模块等,其中 MVCC 模块主要由
treelndex 模块和 boltdb 模块组成。
•存储层:存储层包含预写日志 (WAL) 模块、快照(Snapshot)模块、boltdb模块。其中
WAL 可保障 etcd crash 后数据不丢失,boltdb 则保存了集群元数据和用户写入的数
据.
## Raft协议
>主要分为三个部分:选主,日志复制,安全性
### **raft一致性算法**
在raft体系中,有一个强leader,由它全权负责接收客户端的请求命令,并将命令作为日志条目复制给其他服务器,在确认安全的时候,将日志命令提交执行。
当leader故障时,会选举产生一个新的leader。在强leader的帮助下,raft将一致性问题分解为了三个子问题:
* leader选举:当已有的leader故障时必须选出一个新的leader
* 日志同步:leader接受来自客户端的命令,记录为日志,并复制给集群中的其他服务器,并强制其他节点的日志与leader保持一致
* 安全措施:通过一些措施确保系统的安全性,如确保所有状态机按照相同顺序执行相同命令的措施
可视化网站:http://thesecretlivesofdata.com/raft/
### 结构概念
leader:负责和客户端进行交互,并且负责向其他节点同步日志的,一个集群只有一个leader
candidate:当leader宕机后,部分follower将转为candidate,并为自己拉票,获得半数以上票数的candidate成为新的leader
follower:一般情况下,除了leader,其他节点都是follower
term:term使用连续递增的编号的进行识别,每一个term都从新的选举开始。同时term也有指示逻辑时钟的作用,最新日志的term越大证明越有资格成为leader
RequestVote RPC:它由选举过程中的candidate发起,用于拉取选票
AppendEntries RPC:它由leader发起,用于复制日志或者发送心跳信号
>内部两个超时机制:重置超时、心跳超时,每次follower接收到数据同步包,都会重置这两个时间
>什么时候开始选举?
当心跳超时之后,等选举超时,就开始选举,最先选举超时的follower就会成为candidate,并进行选举,只有当超过半数才能成为leader
### leader选举
raft通过心跳机制发起leader选举。节点都是从follower状态开始的,如果收到了来自leader或candidate的RPC,那它就保持follower状态,避免争抢成为candidate
leader会发送空的AppendEntries RPC作为心跳信号来确立自己的地位,如果follower一段时间(election timeout)没有收到心跳,它就会认为leader已经挂了,发起新的一轮选举
选举发起后,一个follower会增加自己的当前term编号并转变为candidate
它会首先投自己一票,然后向其他所有节点并行发起RequestVote RPC,之后candidate状态将可能发生如下三种变化:
* 赢得选举,成为leader:如果它在一个term内收到了大多数的选票,将会在接下的剩余term时间内称为leader,然后就可以通过发送心跳确立自己的地位。每一个server在一个term内只能投一张选票,并且按照先到先得的原则投出
* 其他server成为leader:在等待投票时,可能会收到其他server发出AppendEntries RPC心跳信号,说明其他leader已经产生了。这时通过比较自己的term编号和RPC过来的term编号,如果比对方大,说明leader的term过期了,就会拒绝该RPC,并继续保持候选人身份; 如果对方编号不比自己小,则承认对方的地位,转为follower
* 选票被瓜分,选举失败:如果没有candidate获取大多数选票,则没有leader产生, candidate们等待超时后发起另一轮选举。为了防止下一次选票还被瓜分,必须采取一些额外的措施,raft采用随机election timeout的机制防止选票被持续瓜分。通过将timeout随机设为一段区间上的某个值,因此很大概率会有某个candidate率先超时然后赢得大部分选票
### 日志同步
一旦leader被选举成功,就可以对客户端提供服务了
客户端提交每一条命令都会被按顺序记录到leader的日志中,每一条命令都包含term编号和顺序索引,然后向其他节点并行发送AppendEntries RPC用以复制命令(如果命令丢失会不断重发)
当复制成功也就是大多数节点成功复制后,leader就会提交命令,即执行该命令并且将执行结果返回客户端,raft保证已经提交的命令最终也会被其他节点成功执行。
leader会保存有当前已经提交的最高日志编号。顺序性确保了相同日志索引处的命令是相同的,而且之前的命令也是相同的。当发送AppendEntries RPC时,会包含leader上一条刚处理过的命令,接收节点如果发现上一条命令不匹配,就会拒绝执行
在这个过程中可能会出现一种特殊故障。如果leader崩溃了,它所记录的日志没有完全被复制,会造成日志不一致的情况,follower相比于当前的leader可能会丢失几条日志,也可能会额外多出几条日志,这种情况可能会持续几个term。
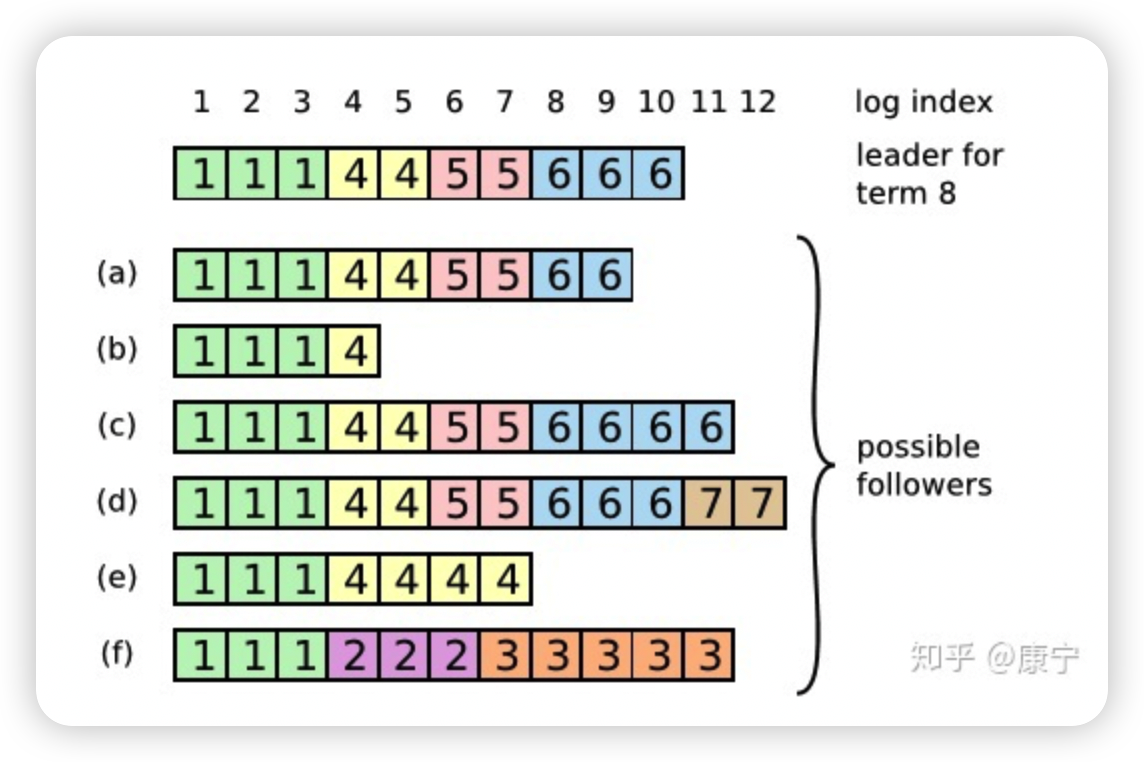
在上图中,框内的数字是term编号,a、b丢失了一些命令,c、d多出来了一些命令,e、f既有丢失也有增多,这些情况都有可能发生。
比如f可能发生在这样的情况下:f节点在term2时是leader,在此期间写入了几条命令,然后在提交之前崩溃了,在之后的term3中它很快重启并再次成为leader,又写入了几条日志,在提交之前又崩溃了,等他苏醒过来时新的leader来了,就形成了上图情形。
在Raft中,leader通过强制follower复制自己的日志来解决上述日志不一致的情形,那么冲突的日志将会被重写。为了让日志一致,先找到最新的一致的那条日志(如f中索引为3的日志条目),然后把follower之后的日志全部删除,leader再把自己在那之后的日志一股脑推送给follower,这样就实现了一致。
而寻找该条日志,可以通过AppendEntries RPC,该RPC中包含着下一次要执行的命令索引,如果能和follower的当前索引对上,那就执行,否则拒绝,然后leader将会逐次递减索引,直到找到相同的那条日志。
然而这样也还是会有问题,比如某个follower在leader提交时宕机了,也就是少了几条命令,然后它又经过选举成了新的leader,这样它就会强制其他follower跟自己一样,使得其他节点上刚刚提交的命令被删除,导致客户端提交的一些命令被丢失了,下面一节内容将会解决这个问题。
Raft通过为选举过程添加一个限制条件,解决了上面提出的问题,该限制确保leader包含之前term已经提交过的所有命令。Raft通过投票过程确保只有拥有全部已提交日志的candidate能成为leader。由于candidate为了拉选票需要通过RequestVote RPC联系其他节点,而之前提交的命令至少会存在于其中某一个节点上,因此只要candidate的日志至少和其他大部分节点的一样新就可以了,follower如果收到了不如自己新的candidate的RPC,就会将其丢弃。
还可能会出现另外一个问题,如果命令已经被复制到了大部分节点上,但是还没来的及提交就崩溃了,这样后来的leader应该完成之前term未完成的提交。
Raft通过让leader统计当前term内还未提交的命令已经被复制的数量是否半数以上,然后进行提交。
### 日志压缩
随着日志大小的增长,会占用更多的内存空间,处理起来也会耗费更多的时间,对系统的可用性造成影响,因此必须想办法压缩日志大小。
Snapshotting是最简单的压缩方法,系统的全部状态会写入一个snapshot保存起来,然后丢弃截止到snapshot时间点之前的所有日志。Raft中的snapshot内容如下图所示:
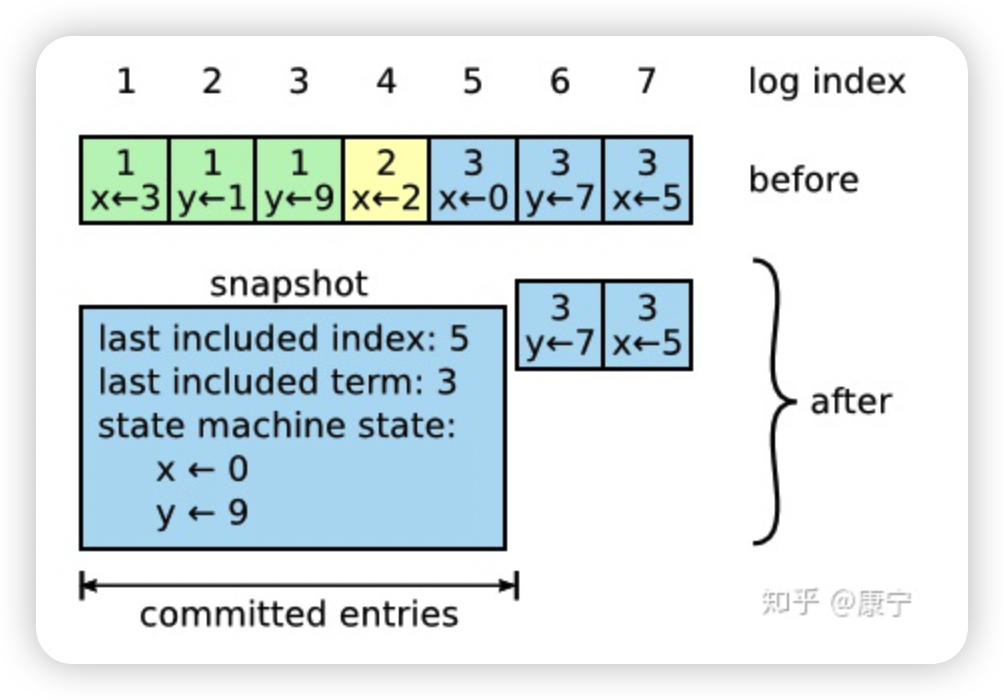
每一个server都有自己的snapshot,它只保存当前状态,如上图中的当前状态为x=0,y=9,而last included index和last included term代表snapshot之前最新的命令,用于AppendEntries的状态检查。
虽然每一个server都保存有自己的snapshot,但是当follower严重落后于leader时,leader需要把自己的snapshot发送给follower加快同步,此时用到了一个新的RPC:InstallSnapshot RPC。follower收到snapshot时,需要决定如何处理自己的日志,如果收到的snapshot包含有更新的信息,它将丢弃自己已有的日志,按snapshot更新自己的状态,如果snapshot包含的信息更少,那么它会丢弃snapshot中的内容,但是自己之后的内容会保存下来。
- Go准备工作
- 依赖管理
- Go基础
- 1、变量和常量
- 2、基本数据类型
- 3、运算符
- 4、流程控制
- 5、数组
- 数组声明和初始化
- 遍历
- 数组是值类型
- 6、切片
- 定义
- slice其他内容
- 7、map
- 8、函数
- 函数基础
- 函数进阶
- 9、指针
- 10、结构体
- 类型别名和自定义类型
- 结构体
- 11、接口
- 12、反射
- 13、并发
- 14、网络编程
- 15、单元测试
- Go常用库/包
- Context
- time
- strings/strconv
- file
- http
- Go常用第三方包
- Go优化
- Go问题排查
- Go框架
- 基础知识点的思考
- 面试题
- 八股文
- 操作系统
- 整理一份资料
- interface
- array
- slice
- map
- MUTEX
- RWMUTEX
- Channel
- waitGroup
- context
- reflect
- gc
- GMP和CSP
- Select
- Docker
- 基本命令
- dockerfile
- docker-compose
- rpc和grpc
- consul和etcd
- ETCD
- consul
- gin
- 一些小点
- 树
- K8s
- ES
- pprof
- mycat
- nginx
- 整理后的面试题
- 基础
- Map
- Chan
- GC
- GMP
- 并发
- 内存
- 算法
- docker