
## **简单的留出验证、*K*折验证,以及带有打乱数据的重复*K*折验证**:
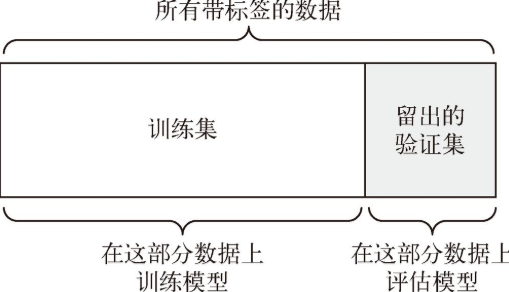
### **简单的留出验证**:
* 留出一定比例的数据作为测试集
* 在剩余的数据上训练模型
* 在测试集上评估模型
* 保留一个验证集
#### **缺点**:
可用的数据很少,那么可能验证集和测试集包含的样本就太少,从而无法在统计学上代表数据
*****
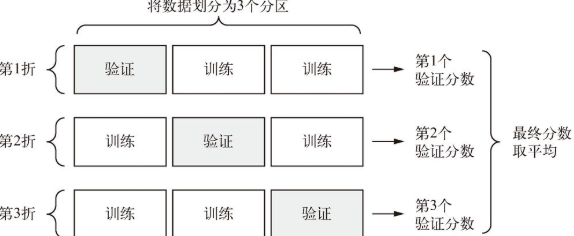
### ***K*折验证**:
如果模型性能的变化很大,那么这种方法很有用
* 将数据划分为**大小相同**的*K*个分区
* 对于每个分区`i`,在剩余的*K*\- 1 个分区上训练模型
* 在分区`i`上评估模型
* 最终分数等于*K*个分数的**平均值**
* 需要**独立的验证集**进行模型校正
*****
### **带有打乱数据的重复*K*折验证**(iterated*K*\-fold validation with shuffling):
* 可用的数据相对较**少**,需要**尽可能精确**地评估模型
* 具体做法是多次使用*K*折验证,在每次将数据划分为*K*个分区之前都先将数据打乱。最终分数是每次*K*折验证分数的平均值
* 这种方法一共要训练和评估*P*×*K*个模型(*P*是重复次数),**计算代价很大**
*****
- 基础
- 张量tensor
- 整数序列(列表)=>张量
- 张量运算
- 张量运算的几何解释
- 层:深度学习的基础组件
- 模型:层构成的网络
- 训练循环 (training loop)
- 数据类型与层类型、keras
- Keras
- Keras 开发
- Keras使用本地数据
- fit、predict、evaluate
- K 折 交叉验证
- 二分类问题-基于梯度的优化-训练
- relu运算
- Dens
- 损失函数与优化器:配置学习过程的关键
- 损失-二分类问题
- 优化器
- 过拟合 (overfit)
- 改进
- 小结
- 多分类问题
- 回归问题
- 章节小结
- 机械学习
- 训练集、验证集和测试集
- 三种经典的评估方法
- 模型评估
- 如何准备输入数据和目标?
- 过拟合与欠拟合
- 减小网络大小
- 添加权重正则化
- 添加 dropout 正则化
- 通用工作流程
- 计算机视觉
- 卷积神经网络
- 卷积运算
- 卷积的工作原理
- 训练一个卷积神经网络
- 使用预训练的卷积神经网络
- VGG16
- VGG16详细结构
- 为什么不微调整个卷积基?
- 卷积神经网络的可视化
- 中间输出(中间激活)
- 过滤器
- 热力图
- 文本和序列
- 处理文本数据
- n-gram
- one-hot 编码 (one-hot encoding)
- 标记嵌入 (token embedding)
- 利用 Embedding 层学习词嵌入
- 使用预训练的词嵌入
- 循环神经网络
- 循环神经网络的高级用法
- 温度预测问题
- code
- 用卷积神经网络处理序列
- GRU 层
- LSTM层
- 多输入模型
- 回调函数
- ModelCheckpoint 与 EarlyStopping
- ReduceLROnPlateau
- 自定义回调函数
- TensorBoard_TensorFlow 的可视化框架
- 高级架构模式
- 残差连接
- 批标准化
- 批再标准化
- 深度可分离卷积
- 超参数优化
- 模型集成
- LSTM
- DeepDream
- 神经风格迁移
- 变分自编码器
- 生成式对抗网络
- 术语表