
[toc]
## 1、线程池的工作原理;
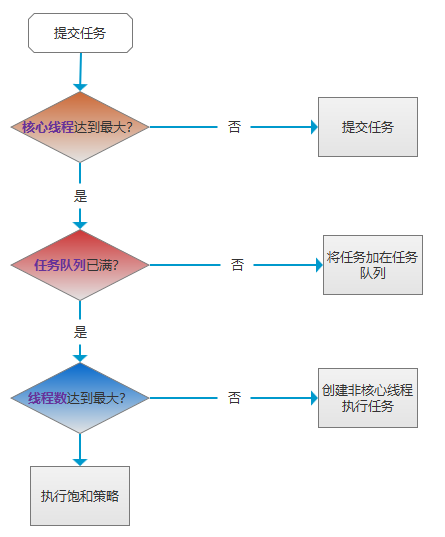
1、提交任务后,线程池先判断线程数是否达到了核心线程数(corePoolSize)。如果未达到线程数,则创建核心线程处理任务;否则,就执行下一步;
2、接着线程池判断任务队列是否满了。如果没满,则将任务添加到任务队列中;否则,执行下一步;
3、接着因为任务队列满了,线程池就判断线程数是否达到了最大线程数。如果未达到,则创建非核心线程处理任务;否则,就执行饱和策略,默认会抛出RejectedExecutionException异常。
> 创建非核心线程的优先级是最低的,因为其代价比较大。
## 2、CPU密集型和IO密集型的配置
### 非核心线程的消亡时间的设置,是怎么实现的?
1. 所有的线程都是一样的,并没有区分是核心线程还是非核心线程,只是在没有任务的时候,过了超时时间会有一些线程结束执行退出,剩下的就是核心线程了。
2. runworker()方法里会通过while死循环获取任务,当线程数量大于核心线程数量时,获取任务为null时,会执行线程销毁操作——线程是作为存放在HashSet<Worker>中的,执行remove()操作即可。`java/util/concurrent/ThreadPoolExecutor.java:1134`
```
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
while (task != null || (task = getTask()) != null) {
w.lock();
// 省略一部分代码
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}
```
### 线程的复用机制是怎么实现的?
- 前言
- 第一部分 计算机网络与操作系统
- 大量的 TIME_WAIT 状态 TCP 连接,对业务有什么影响?怎么处理?
- 性能占用
- 第二部分 Java基础
- 2-1 JVM
- JVM整体结构
- 方法区
- JVM的生命周期
- 堆对象结构
- 垃圾回收
- 调优案例
- 类加载机制
- 执行引擎
- 类文件结构
- 2-2 多线程
- 线程状态
- 锁与阻塞
- 悲观锁与乐观锁
- 阻塞队列
- ConcurrentHashMap
- 线程池
- 线程框架
- 彻底搞懂AQS
- 2-3 Spring框架基础
- Spring注解
- Spring IoC 和 AOP 的理解
- Spring工作原理
- 2-4 集合框架
- 死磕HashMap
- 第三部分 高级编程
- Socket与NIO
- 缓冲区
- Bybuffer
- BIO、NIO、AIO
- Netty的工作原理
- Netty高性能原因
- Rabbitmq
- mq消息可靠性是怎么保障的?
- 认证授权
- 第四部分 数据存储
- 第1章 mysql篇
- MySQL主从一致性
- Mysql的数据组织方式
- Mysql性能优化
- 数据库中的乐观锁与悲观锁
- 深度分页
- 从一条SQL语句看Mysql的工作流程
- 第2章 Redis
- Redis缓存
- redis key过期策略
- 数据持久化
- 基于Redis分布式锁的实现
- Redis高可用
- 第3章 Elasticsearch
- 全文查询为什么快
- battle with mysql
- 第五部分 数据结构与算法
- 常见算法题
- 基于数组实现的一个队列
- 第六部分 真实面试案例
- 初级开发面试材料
- 答案部分
- 现场编码
- 第七部分 面试官角度
- 第八部分 计算机基础
- 第九部分 微服务
- OpenFeign工作原理