
[toc]
### 1-缓存穿透
缓存穿透说简单点就是大量请求的 key 根本不存在于缓存中,导致请求直接到了数据库上,根本没有经过缓存这一层。举个例子:某个黑客故意制造我们缓存中不存在的 key 发起大量请求,导致大量请求落到数据库。
#### 如何避免缓存穿透?
1. 最基本的就是首先做好参数校验,一些不合法的参数请求直接抛出异常信息返回给客户端。比如查询的数据库 id 不能小于 0、传入的邮箱格式不对的时候直接返回错误消息给客户端等等。
2. 缓存无效 key。
3. 布隆过滤器。把所有可能存在的请求的值都存放在布隆过滤器中,当用户请求过来,先判断用户发来的请求的值是否存在于布隆过滤器中。不存在的话,直接返回请求参数错误信息给客户端,存在的话才会走下面的流程。
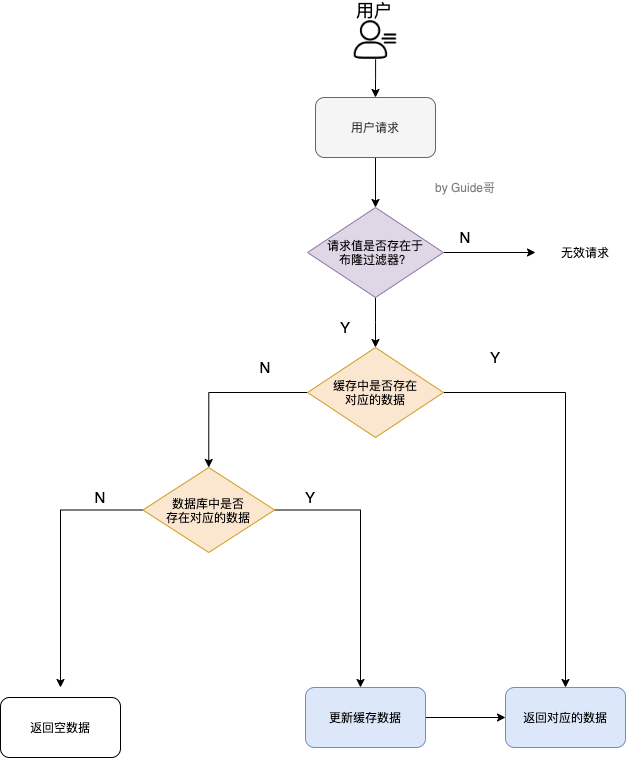
### 2-缓存雪崩
#### **1-什么是缓存雪崩?**
简介:缓存同一时间大面积的失效,所以,后面的请求都会落到数据库上,造成数据库短时间内承受大量请求而崩掉。
#### **2-有哪些解决办法?**
**针对 Redis 服务不可用的情况:**
1. 采用 Redis 集群,避免单机出现问题整个缓存服务都没办法使用。
2. 限流,避免同时处理大量的请求。
**针对热点缓存失效的情况:**
1. 设置不同的失效时间比如随机设置缓存的失效时间。
2. 缓存永不失效。
### 3-如何保证缓存和数据库数据的一致性?
缓存与数据库一致性问题Cache Aside Pattern 中遇到写请求是这样的:更新 DB,然后直接删除 cache 。
如果更新数据库成功,而删除缓存这一步失败的情况的话,简单说两个解决方案:
1. **缓存失效时间变短(不推荐,治标不治本)**:我们让缓存数据的过期时间变短,这样的话缓存就会从数据库中加载数据。另外,这种解决办法对于先操作缓存后操作数据库的场景不适用。
2. **增加 cache 更新重试机制(常用)**: 如果 cache 服务当前不可用导致缓存删除失败的话,我们就隔一段时间进行重试,重试次数可以自己定。如果多次重试还是失败的话,我们可以把当前更新失败的 key 存入队列中,等缓存服务可用之后,再将 缓存中对应的 key 删除即可。
### 4-Redis 内存淘汰机制了解么?
> 相关问题:MySQL 里有 2000w 数据,Redis 中只存 20w 的数据,如何保证 Redis 中的数据都是热点数据?
Redis 提供 6 种数据淘汰策略:
1. **volatile-lru(least recently used)**:从已设置过期时间的数据集(server.db\[i\].expires)中挑选最近最少使用的数据淘汰
2. **volatile-ttl**:从已设置过期时间的数据集(server.db\[i\].expires)中挑选将要过期的数据淘汰
3. **volatile-random**:从已设置过期时间的数据集(server.db\[i\].expires)中任意选择数据淘汰
4. **allkeys-lru(least recently used)**:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的 key(这个是最常用的)
5. **allkeys-random**:从数据集(server.db\[i\].dict)中任意选择数据淘汰
6. **no-eviction**:禁止驱逐数据,也就是说当内存不足以容纳新写入数据时,新写入操作会报错。这个应该没人使用吧!
4.0 版本后增加以下两种:
7. **volatile-lfu(least frequently used)**:从已设置过期时间的数据集(server.db\[i\].expires)中挑选最不经常使用的数据淘汰
8. **allkeys-lfu(least frequently used)**:当内存不足以容纳新写入数据时,在键空间中,移除最不经常使用的 key
- 前言
- 第一部分 计算机网络与操作系统
- 大量的 TIME_WAIT 状态 TCP 连接,对业务有什么影响?怎么处理?
- 性能占用
- 第二部分 Java基础
- 2-1 JVM
- JVM整体结构
- 方法区
- JVM的生命周期
- 堆对象结构
- 垃圾回收
- 调优案例
- 类加载机制
- 执行引擎
- 类文件结构
- 2-2 多线程
- 线程状态
- 锁与阻塞
- 悲观锁与乐观锁
- 阻塞队列
- ConcurrentHashMap
- 线程池
- 线程框架
- 彻底搞懂AQS
- 2-3 Spring框架基础
- Spring注解
- Spring IoC 和 AOP 的理解
- Spring工作原理
- 2-4 集合框架
- 死磕HashMap
- 第三部分 高级编程
- Socket与NIO
- 缓冲区
- Bybuffer
- BIO、NIO、AIO
- Netty的工作原理
- Netty高性能原因
- Rabbitmq
- mq消息可靠性是怎么保障的?
- 认证授权
- 第四部分 数据存储
- 第1章 mysql篇
- MySQL主从一致性
- Mysql的数据组织方式
- Mysql性能优化
- 数据库中的乐观锁与悲观锁
- 深度分页
- 从一条SQL语句看Mysql的工作流程
- 第2章 Redis
- Redis缓存
- redis key过期策略
- 数据持久化
- 基于Redis分布式锁的实现
- Redis高可用
- 第3章 Elasticsearch
- 全文查询为什么快
- battle with mysql
- 第五部分 数据结构与算法
- 常见算法题
- 基于数组实现的一个队列
- 第六部分 真实面试案例
- 初级开发面试材料
- 答案部分
- 现场编码
- 第七部分 面试官角度
- 第八部分 计算机基础
- 第九部分 微服务
- OpenFeign工作原理