
你好,我是你的数据结构课老师蔡元楠,欢迎进入第 04 课时的内容“链表在 Apache Kafka 中的应用”。
经过了前三讲的学习之后,我相信你已经对数组和链表有了比较好的了解了。那在这一讲中,我想和你分享一下,数组和链表结合起来的数据结构是如何被大量应用在操作系统、计算机网络,甚至是在 Apache 开源项目中的。
#### 如何重新设计定时器算法
说到定时器(Timer),你应该不会特别陌生。像我们写程序时使用到的 Java Timer 类,或者是在 Linux 中制定定时任务时所使用的 cron 命令,亦或是在 BSD TCP 网络协议中检测网络数据包是否需要重新发送的算法里,其实都使用了定时器这个概念。那在课程的开头,我想先问问你,如果让你来重新设计定时器算法的话,会如何设计呢?
本质上,定时器的实现是依靠着计算机里的时钟来完成的。举个例子,假设时钟是每秒跳一次,那我们可以根据时钟的精度构建出 10 秒或者 1 分钟的定时器,但是如果想要构建 0.5 秒的定时器是无法做到的,因为计算机时钟最快也只能每一秒跳一次,所以即便当我们设置了 0.5 秒的定时器之后,本质上这个定时器也是只有 1 秒。当然了,在现实中,计算机里时钟的精度都是毫微秒(Nanosecond)级别的,也就是十亿分之一秒。
那回到设计定时器这个算法中,一般我们可以把定时器的概念抽象成 4 个部分,它们分别是:
1. 初始化定时器,规定定时器经过了多少单位时间之后超时,并且在超时之后执行特定的程序;
2. 删除定时器,终止一个特定的定时器;
3.
定时器超时进程,定时器在超时之后所执行的特定程序;
4. 定时器检测进程,假设定时器里的时间最小颗粒度为 T 时间,则每经过 T 时间之后都会执行这个进程来查看是否定时器超时,并将其移除。
你可能会问,我们现在只学习了数组和链表这两种数据结构,难道就可以设计一个被如此广泛应用的定时器算法了吗?完全没问题的,那我们就由浅入深,一起来看看各种实现方法优缺点吧。下面的所有算法我们都假设定时器超时时间的最小颗粒度为 T。
* [ ] 维护无序定时器列表
最简单粗暴的方法,当然就是直接用数组或者链表来维护所有的定时器了。从前面的学习中我们可以知道,在数组中插入一个新的元素所需要的时间复杂度是 O(N),而在链表的结尾插入一个新的节点所需要的时间复杂度是 O(1),所以在这里可以选择用链表来维护定时器列表。假设我们要维护的定时器列表如下图所示:

它表示现在系统维护了 3 个定时器,分别会在 3T、T 和 2T 时间之后超时。如果现在用户又插入了一个新定时器,将会在 T 时间后超时,我们会将新的定时器数据结构插入到链表结尾,如下图所示:

每次经过 T 时间之后,定时器检测进程都会从头到尾扫描一遍这个链表,每扫描到一个节点的时候都会将里面的时间减去 T,然后判断这个节点的值是否等于 0 了,如果等于 0 了,则表示这个定时器超时,执行定时器超时进程并删除定时器,如果不等于,则继续扫描下一个节点。
这种方法的好处是定时器的插入和删除操作都只需要 O(1) 的时间。但是每次执行定时器检测进程的时间复杂度为 O(N)。如果定时器的数量还很小时还好,如果当定时器有成百上千个的时候,定时器检测进程就会成为一个瓶颈了。
* [ ] 维护有序定时器列表
这种方法是上述方法的改良版本。我们可以还是继续维护一个定时器列表,与第一种方法不一样的是,每次插入一个新的定时器时,并不是将它插入到链表的结尾,而是从头遍历一遍链表,将定时器的超时时间按从小到大的顺序插入到定时器列表中。还有一点不同的是,每次插入新定时器时,并不是保存超时时间,而是根据当前系统时间和超时时间算出一个绝对时间出来。例如,当前的系统时间为 NowTime,超时时间为 2T,那这个绝对时间就为 NowTime + 2T。
假设原来的有序定时器列表如下图所示:
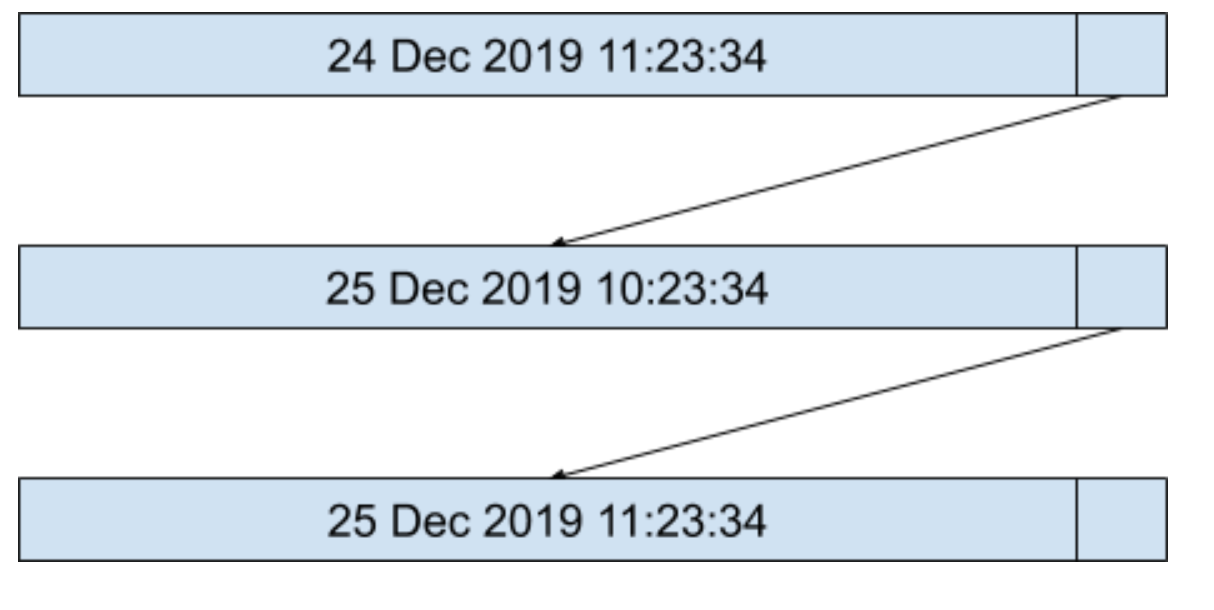
当我们要插入一个新的定时器,超时的绝对时间算出为 25 Dec 2019 9:23:34,这时候我们会按照超时时间从小到大的顺序,将定时器插入到定时器列表的开头,如下图所示:
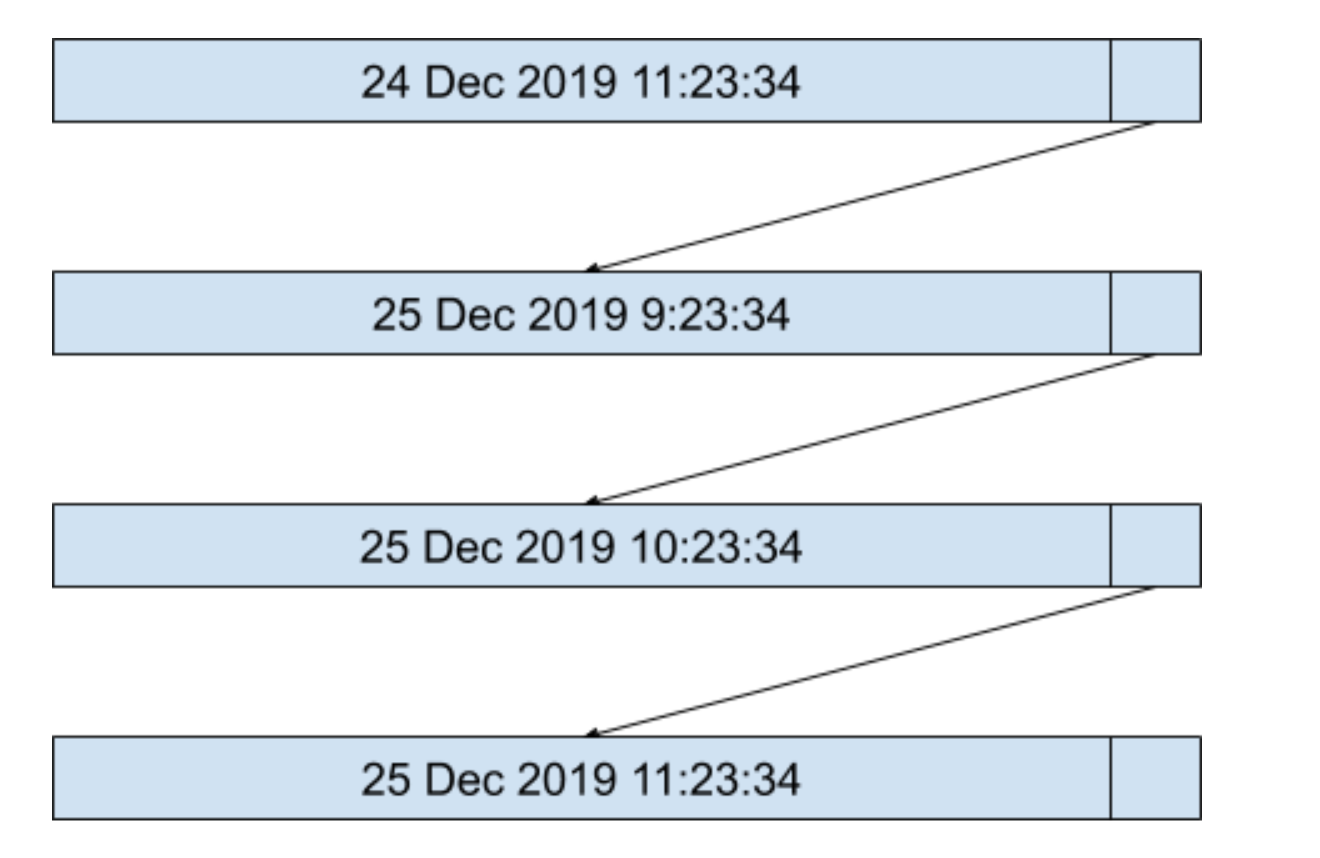
维护一个有序的定时器列表的好处是,每次执行定时器检测进程的时间复杂度为 O(1),因为每次定时器检测进程只需要判断当前系统时间是否是在链表第一个节点时间之后了,如果是则执行定时器超时进程并删除定时器,如果不是则结束定时器检测进程。
这种方法的好处是执行定时器检测进程和删除定时器的时间复杂度为 O(1),但因为要按照时间从小到大排列定时器,每次插入的时候都需要遍历一次定时器列表,所以插入定时器的时间复杂度为 O(N)。
* [ ] 维护定时器“时间轮”
“时间轮”(Timing-wheel )在概念上是一个用数组并且数组元素为链表的数据结构来维护的定时器列表,常常伴随着溢出列表(Overflow List)来维护那些无法在数组范围内表达的定时器。“时间轮”有非常多的变种,今天我来解释一下最基本的“时间轮”实现方式。
首先基本的“时间轮”会将定时器的超时时间划分到不同的周期(Cycle)中去,数组的大小决定了一个周期的大小。例如,一个“时间轮”数组的大小为 8,那这个“时间轮”周期的大小就为 8T。同时,我们维护一个最基本的“时间轮”还需要维护以下几个变量:
* “时间轮”的周期数,用 S 来表示;
*
“时间轮”的周期大小,用 N 来表示;
*
“时间轮”数组现在所指向的索引,用 i 来表示。
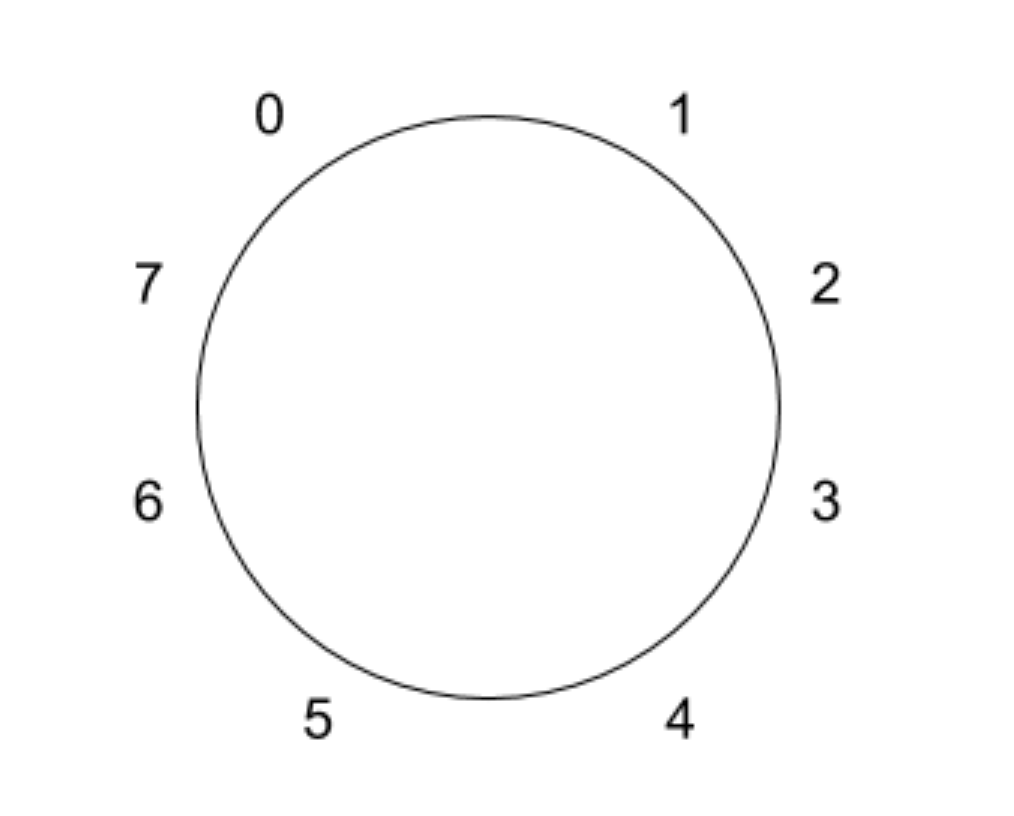
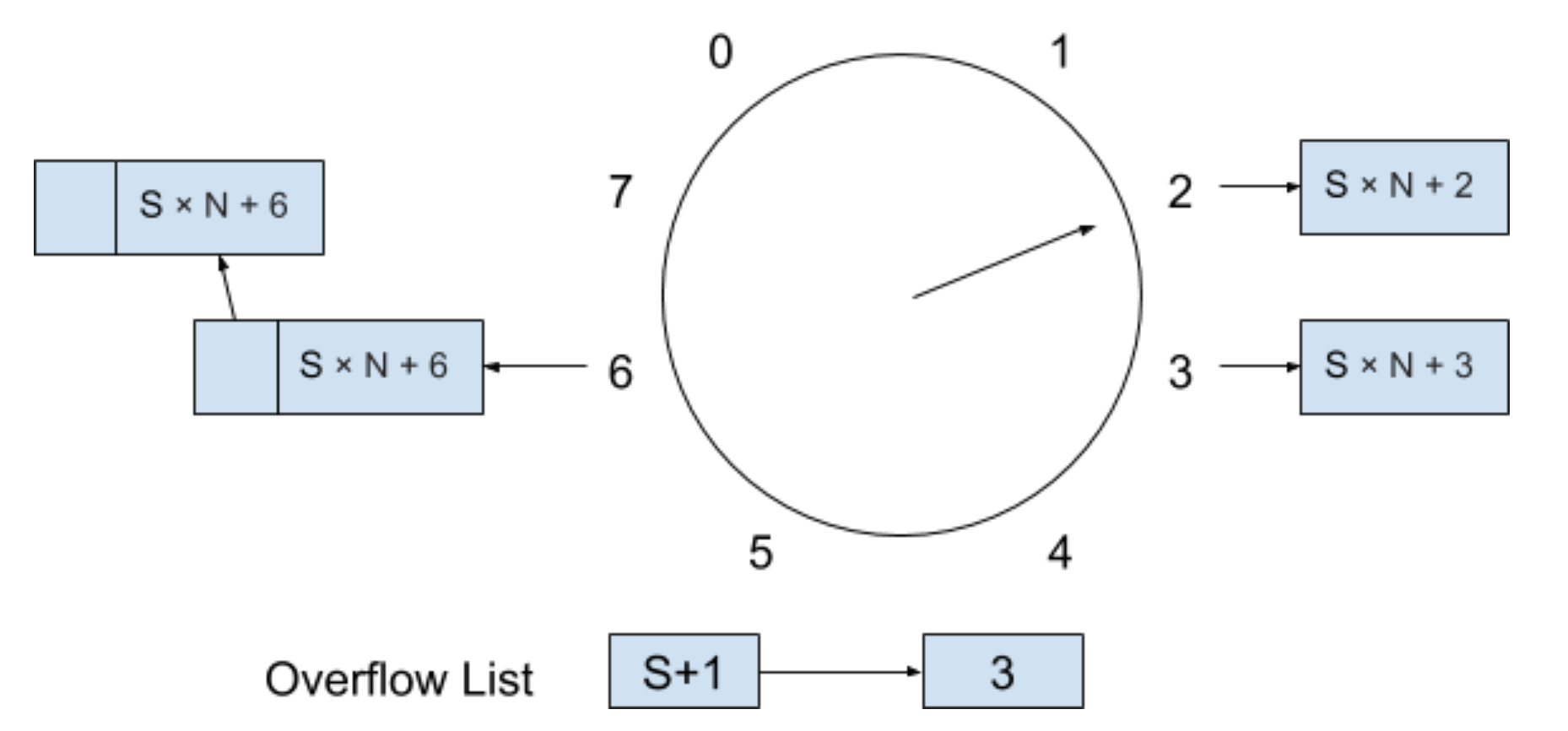
现在的时间我们可以用 S×N + i 来表示,每次我们执行完一次定时器检测进程之后,都会将 i 加 1。当 i 等于 N 的时候,我们将 S 加 1,并且将 i 归零。因为“时间轮”里面的数组索引会一直在 0 到 N-1 中循环,所以我们可以将数组想象成是一个环,例如一个“时间轮”的周期大小为 8 的数组,可以想象成如下图所示的环:
那么我们假设现在的时间是 S×N + 2,表示这个“时间轮”的当前周期为 S,数组索引为 2,同时假设这个“时间轮”已经维护了一部分定时器链表,如下图所示:

如果我们想新插入一个超时时间为 T 的新定时器进这个时间轮,因为 T 小于这个“时间轮”周期的大小 8T,所以表示这个定时器可以被插入到当前的“时间轮”中,插入的位置为当前索引为 1 + 2 % 8 = 3 ,插入新定时器后的“时间轮”如下图所示:
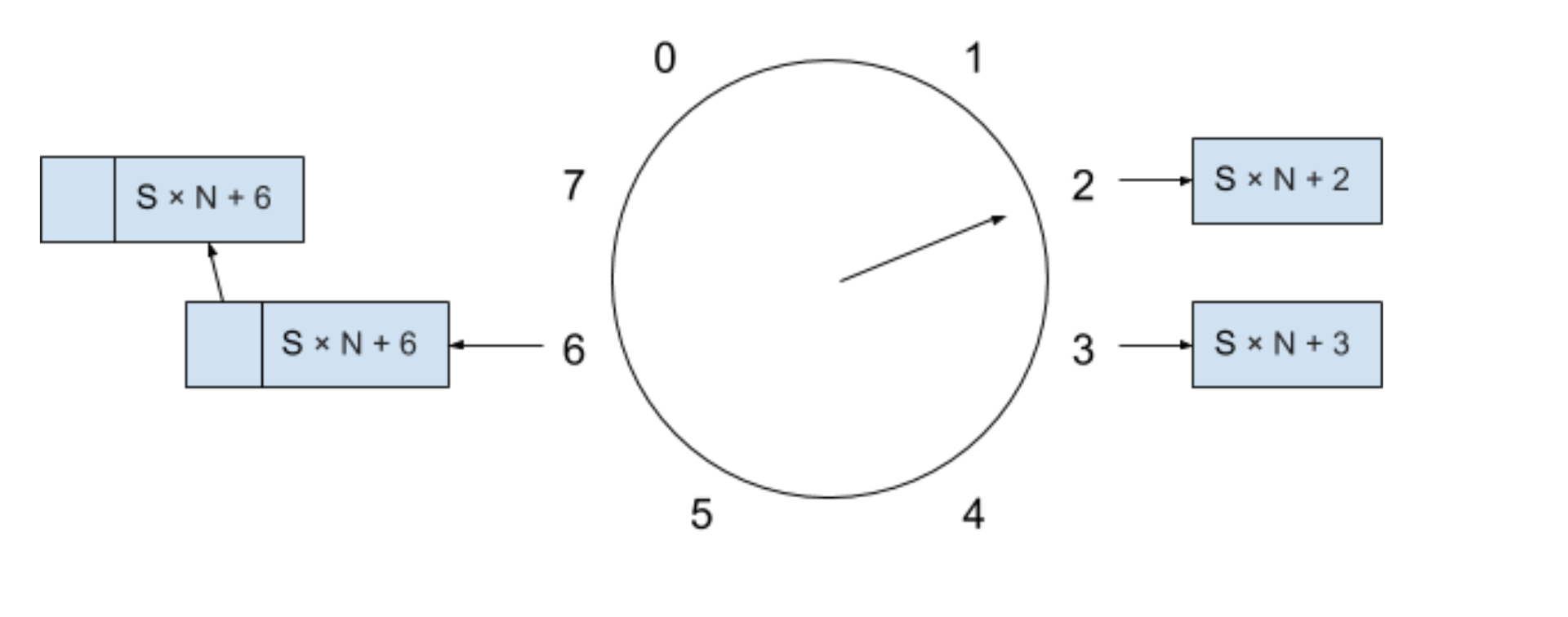
如果我们现在又想新插入一个超时时间为 9T 的新定时器进这个“时间轮”,因为 9T 大于或等于这个“时间轮”周期的大小 8T,所以表示这个定时器暂时无法被插入到当前的周期中,我们必须将这个新的定时器放进溢出列表里。溢出列表存放着新定时器还需要等待多少周期才能进入到当前“时间轮”中,我们按照下面公式来计算还需等待的周期和插入的位置:
* 还需等待的周期:9T / 8T = 1
* 新定时器插入时的索引位置:(9T + 2T) % 8T = 3
我们算出了等待周期和新插入数组的索引位置之后,就可以更新溢出列表,如下图所示:
在“时间轮”的算法中,定时器检测进程只需要判断“时间轮”数组现在所指向的索引里的链表为不为空,如果为空则不执行任何操作,如果不为空则对于这个数组元素链表里的所有定时器执行定时器超时进程。而每当“时间轮”的周期数加 1 的时候,系统都会遍历一遍溢出列表里的定时器是否满足当前周期数,如果满足的话,则将这个位置的溢出列表全部移到“时间轮”相对应的索引位置中。
在这种基本“时间轮”的算法里,定时器检测进程的时间复杂度为 O(1),而插入新定时器的时间复杂度取决于超时时间,因为插入的新定时器有可能会被放入溢出列表中从而需要遍历一遍溢出列表以便将新定时器放入到相对应周期的位置。
* [ ] “时间轮”变种算法
基本的“时间轮”插入操作因为维护了一个溢出列表导致定时器的插入操作无法做到 O(1) 的时间复杂度,所以为了 O(1) 时间复杂度的插入操作,一种变种的“时间轮”算法就被提出了。
在这个变种的“时间轮”算法里,我们加了一个 MaxInterval 的限制,这个 MaxInterval 其实也就是我们定义出的“时间轮”数组的大小。假设“时间轮”数组的大小为 N,对于任何需要新加入的定时器,如果超时时间小于 N 的话,则被允许加入到“时间轮”中,否则将不被允许加入。
这种“时间轮”变种算法,执行定时器检测进程还有插入和删除定时器的操作时间复杂度都只有 O(1)。
* [ ] 分层“时间轮”
上面所描述到的“时间轮”变种算法,当我们要表达的 MaxInterval 很大而且超时时间颗粒度比较小的时候,会占用比较大的空间。例如,如果时间颗粒度是 1 秒,而 MaxInterval 是 1 天的话,就表示我们需要维护一个大小为 24 × 60 × 60 = 86400 的数组。
那有没有方法可以将空间利用率提高,而同时保持着执行定时器检测进程还有插入和删除定时器的操作时间复杂度都只有 O(1) 呢?答案是使用分层“时间轮”(Hierarchical Timing Wheel)。下面还是以时间颗粒度是 1 秒,而 MaxInterval 是 1 天的例子来说明分层“时间轮”算法。
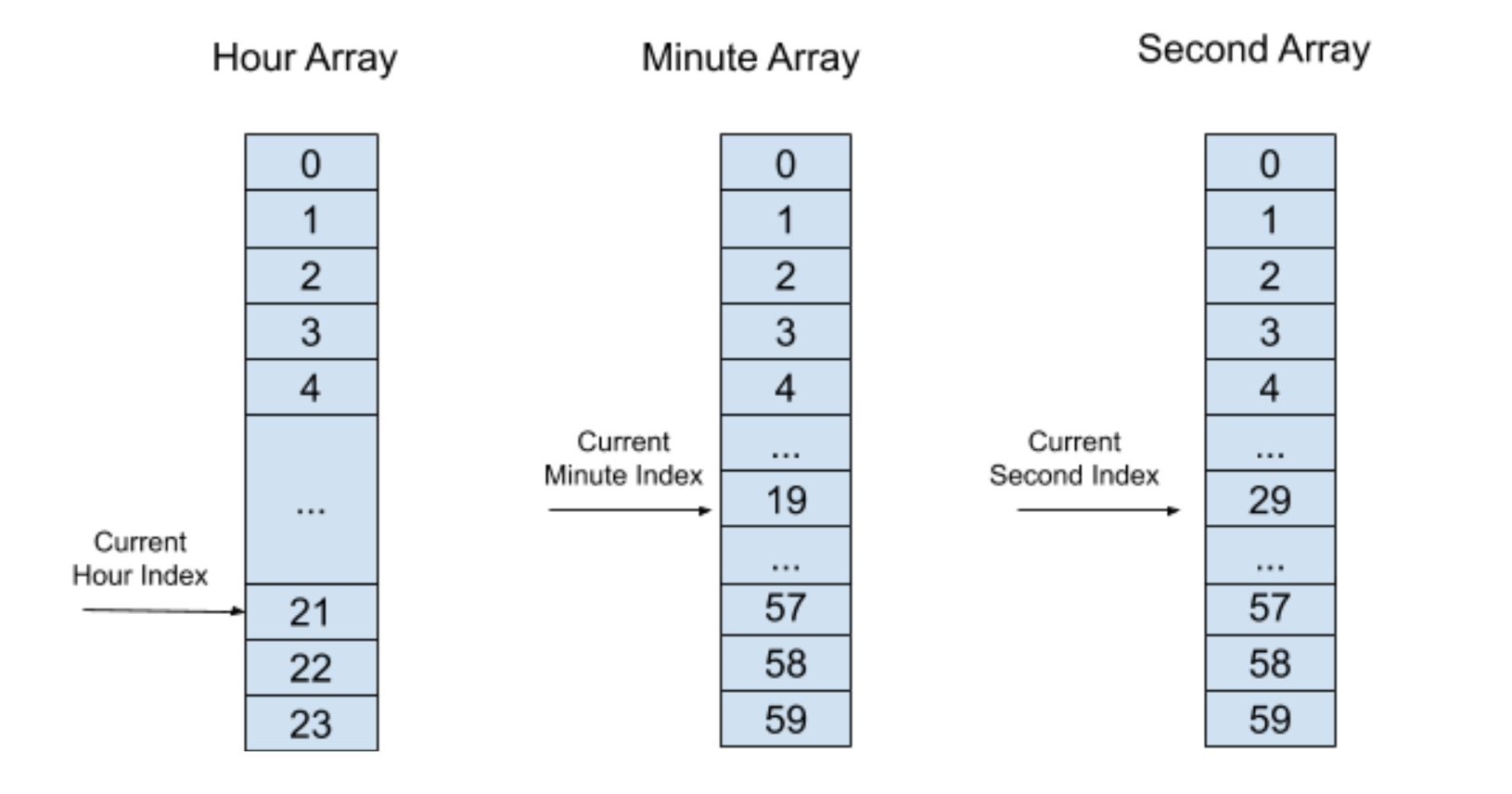
我们可以使用三个“时间轮”来表示不同颗粒度的时间,分别是小时“时间轮”、分钟“时间轮”和秒“时间轮”,可以称小时“时间轮”为分钟“时间轮”的上一层“时间轮”,秒“时间轮”为分钟“时间轮”的下一层“时间轮”。分层“时间轮”会维护一个“现在时间”,每层“时间轮”都需要各自维护一个当前索引来表示“现在时间”。例如,分层“时间轮”的“现在时间”是22h:20min:30s,它的结构图如下图所示:
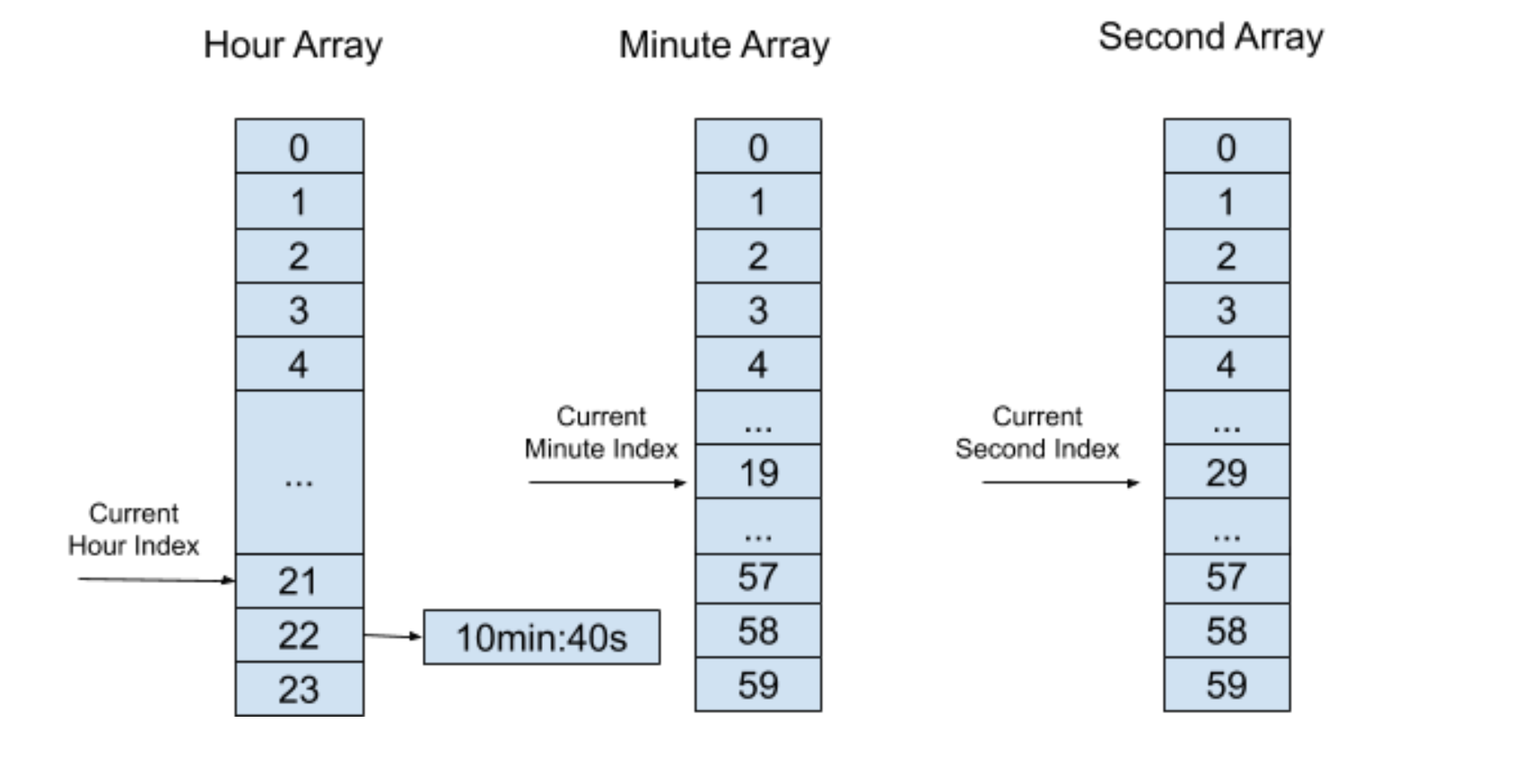
当每次有新的定时器需要插入进分层“时间轮”的时候,将根据分层“时间轮”的“现在时间”算出一个超时的绝对时间。例如,分层“时间轮”的“现在时间”是 22h:20min:30s,而当我们要插入的新定时器超时时间为 50 分钟 10 秒时,这个超时的绝对时间则为 23h:10min:40s。
我们需要先判断最高层的时间是否一致,如果不一致的话则算出时间差,然后插入定时器到对应层的“时间轮”中,如果一致,则到下一层中的时间中计算,如此类推。在上面的例子中,最高层的时间小时相差了 23-22 = 1 小时,所以需要将定时器插入到小时“时间轮”中的 (1 + 21) % 24 = 22这个索引中,定时器列表里还需要保存下层“时间轮”所剩余的时间 10min:40s,如下图所示:
每经过一秒钟,秒“时间轮”的索引都会加 1,并且执行定时器检测进程。定时器检测进程需要判断当前元素里的定时器列表是否为空,如果为空则不执行任何操作,如果不为空则对于这个数组元素列表里的所有定时器执行定时器超时进程。需要注意的是,定时器检测进程只会针对最下层的“时间轮”执行。
如果秒“时间轮”的索引到达 60 之后会将其归零,并将上一层的“时间轮”索引加 1,同时判断上一层的“时间轮”索引里的列表是否为空,如果不为空,则按照之前描述的算法将定时器加入到下一层“时间轮”中去,如此类推。
在经过一段时间之后,上面的分层“时间轮”会到达以下的一个状态:
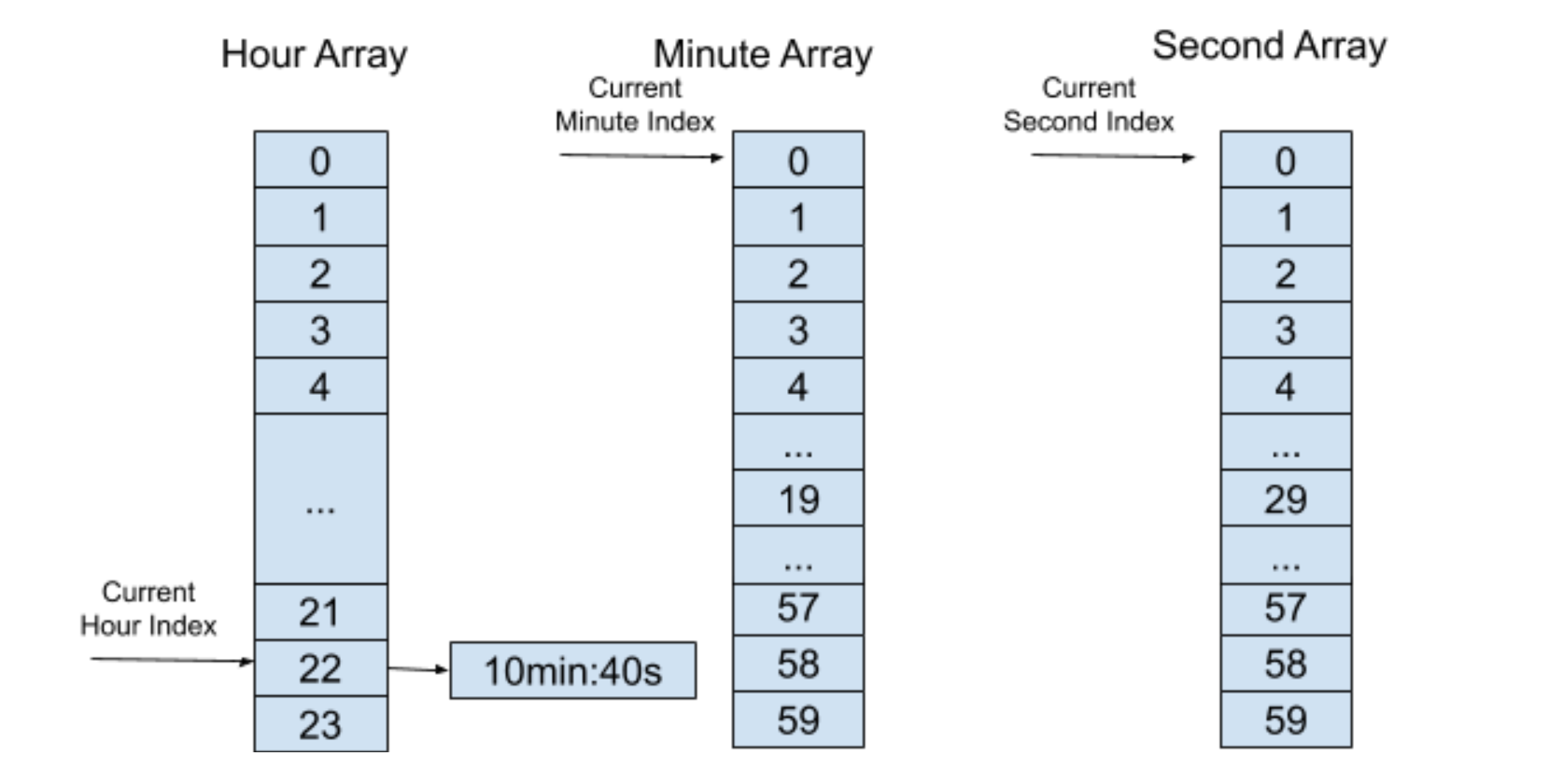
这时候上层“时间轮”索引里的列表不为空,将这个定时器加入的索引为 10 的分钟“时间轮”中,并且保存下层“时间轮”所剩余的时间 40s,如下图所示:
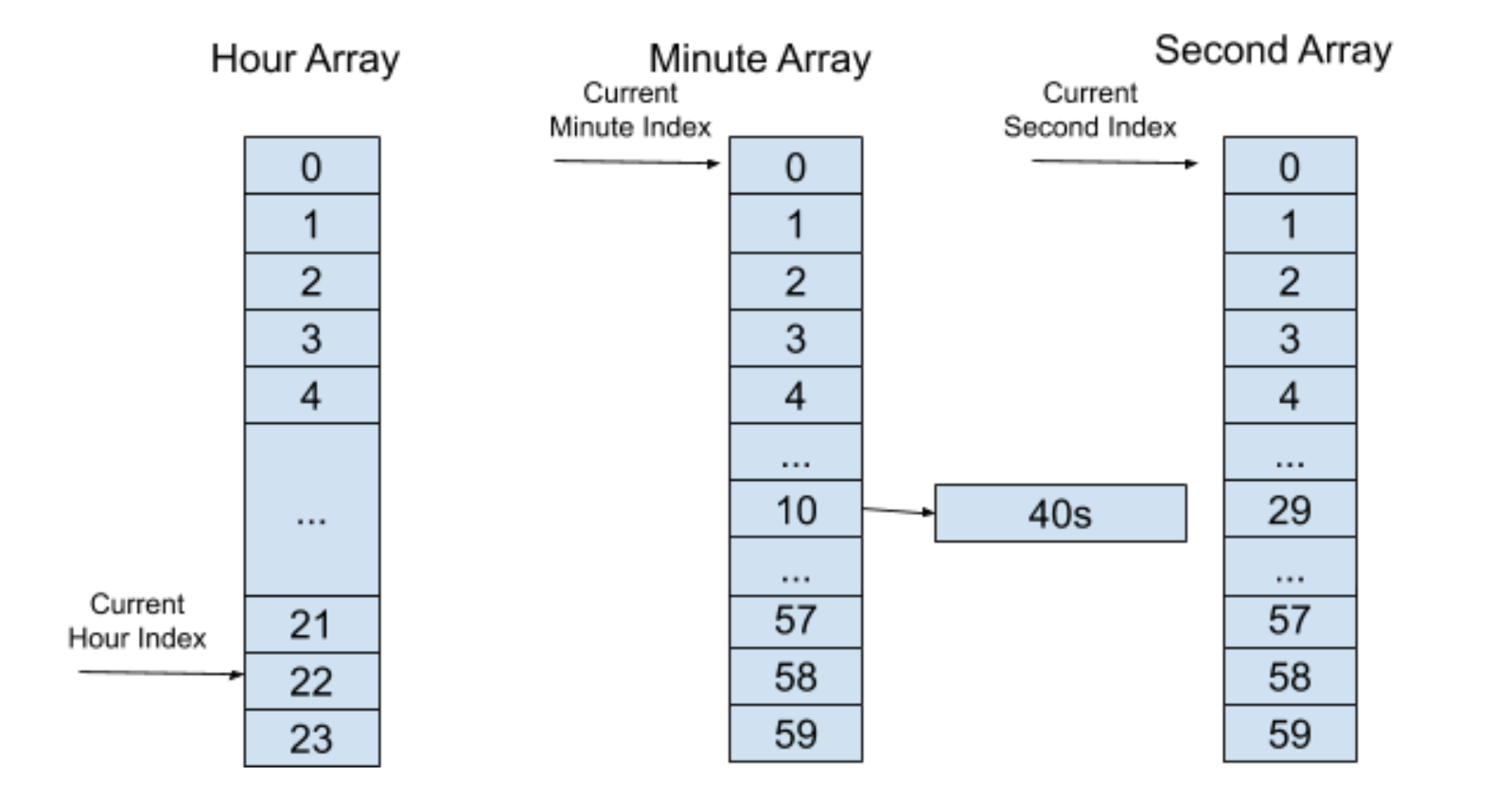
如此类推,在经过 10 分钟之后,分层“时间轮”会到达以下的一个状态:
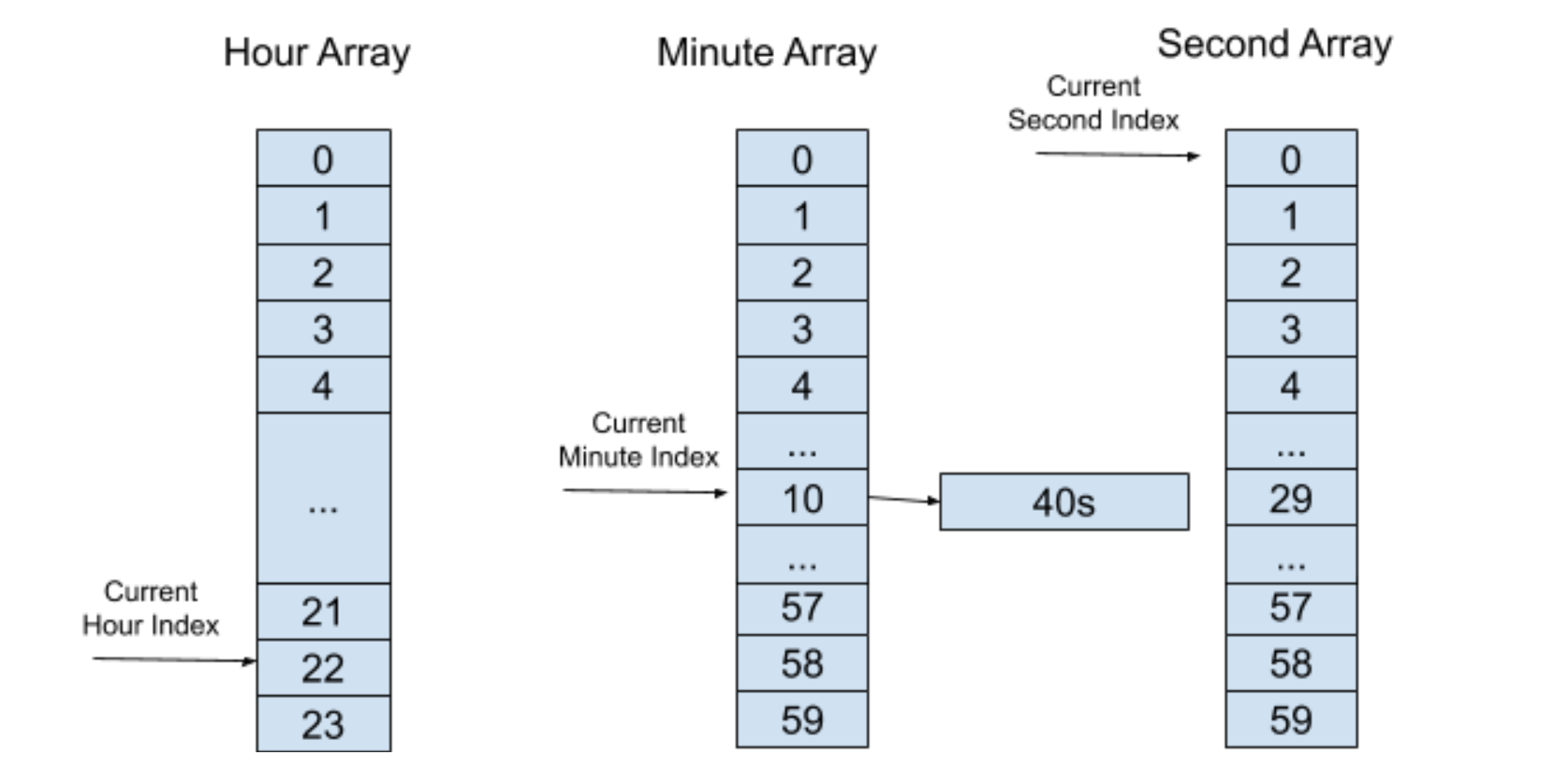
同样的,我们将这个定时器插入到秒“时间轮”中,如下图所示:
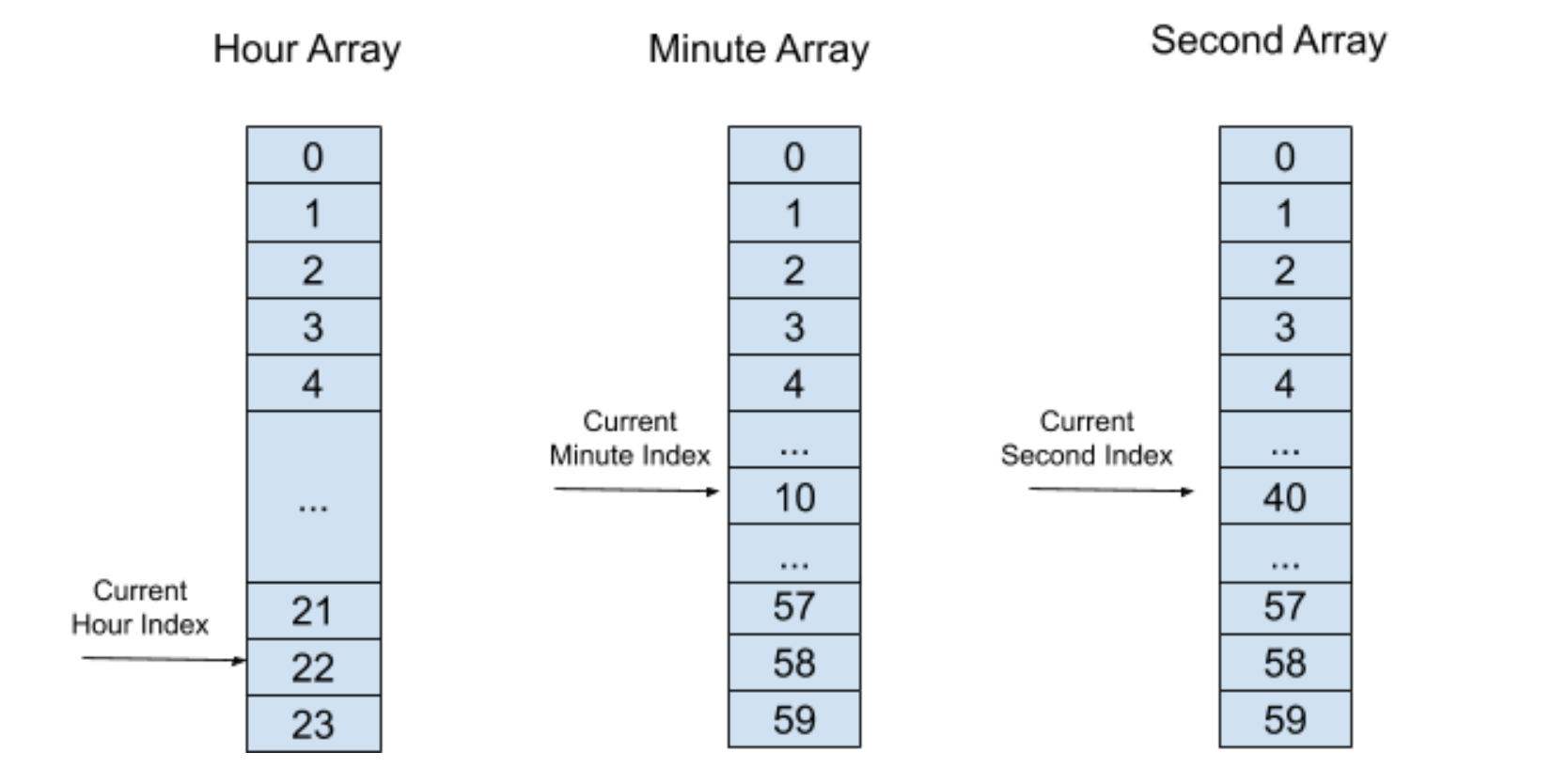
这个时候,再经过 40 秒,秒“时间轮”的索引将会指向一个元素,里面有着非空的定时器列表,然后执行定时器超时进程并将定时器列表里所有的定时器删除。
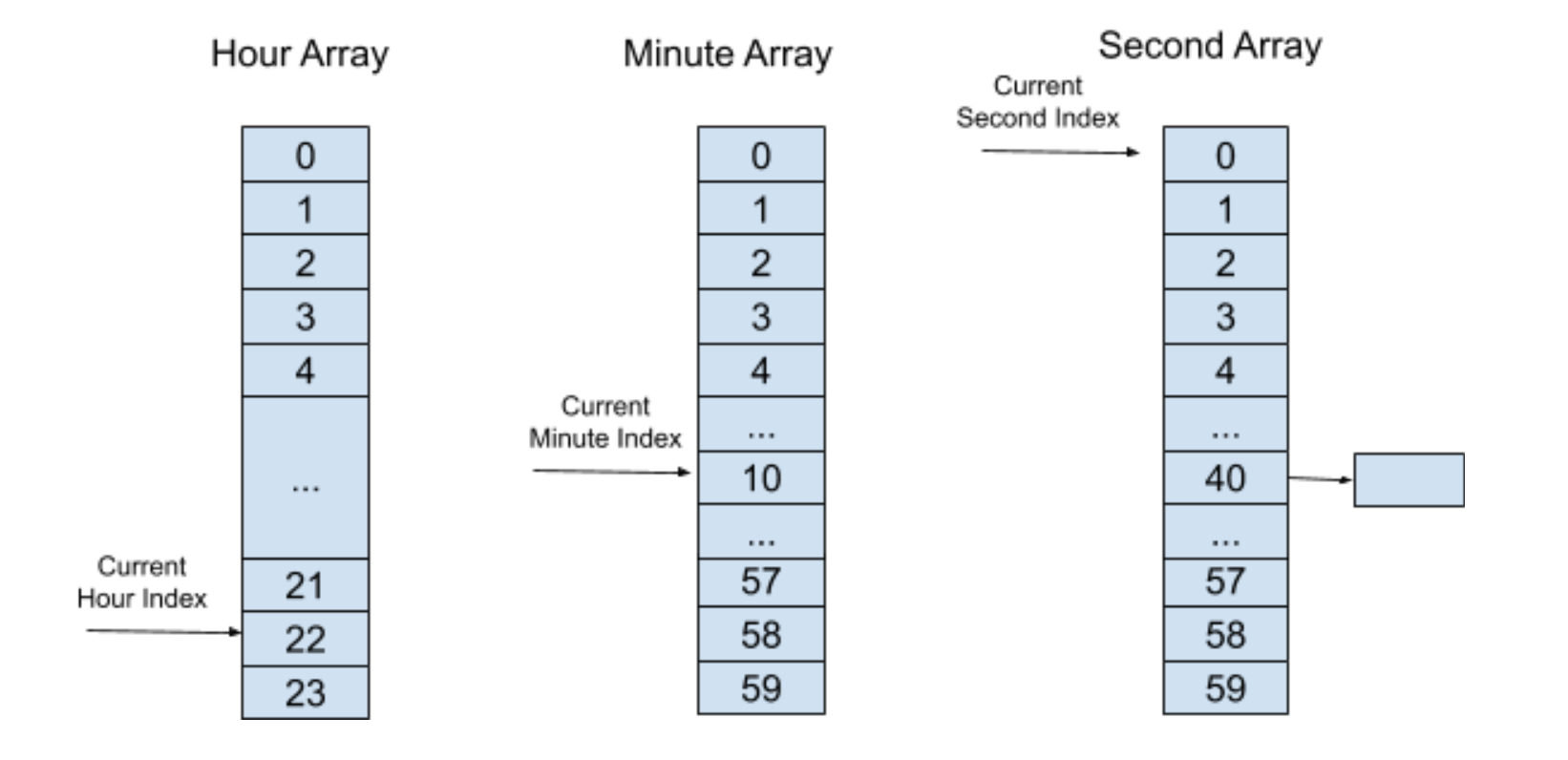
我们可以看到,采用了分层“时间轮”算法之后,我们只需要维护一个大小为 24 + 60 + 60 = 144 的数组,而同时保持着执行定时器检测进程还有插入和删除定时器的操作时间复杂度都只有 O(1)。
* [ ] Apache Kafka 的 Purgatory 组件
Apache Kafka 是一个开源的消息系统项目,主要用于提供一个实时处理消息事件的服务。与计算机网络里面的 TCP 协议需要用到大量定时器来判断是否需要重新发送丢失的网络包一样,在 Kafka 里面,因为它所提供的服务需要判断所发送出去的消息事件是否被订阅消息的用户接收到,Kafka 也需要用到大量的定时器来判断发出的消息是否超时然后重发消息。
而这个任务就落在了 Purgatory 组件上。在旧版本的 Purgatory 组件里,维护定时器的任务采用的是 Java 的 DelayQueue 类来实现的。DelayQueue 本质上是一个堆(Heap)数据结构,这个概念将会在第 09 讲中详细介绍。现在我们可以把这种实现方式看作是维护有序定时器列表的一种变种。这种操作的一个缺点是当有大量频繁的插入操作时,系统的性能将会降低。
因为 Kafka 中所有的最大消息超时时间都已经被写在了配置文件里,也就是说我们可以提前知道一个定时器的 MaxInterval,所以新版本的 Purgatory 组件则采用的了我们上面所提到的变种“时间轮”算法,将插入定时器的操作性能大大提升。根据 Kafka 所提供的检测结果,采用 DelayQueue 时所能处理的最大吞吐率为 25000 RPS,采用了变种“时间轮”算法之后,最大吞吐率则达到了 105000 RPS。
OK,这节课就讲到这里啦,下一课时我将分享“哈希函数的本质及生成方式”,记得按时来听课哈。
- 前言
- 开篇
- 开篇词:从此不再“面试造火箭、工作拧螺丝”
- 模块一:数组与链表的应用
- 第 01 讲:数组内存模型
- 第 02 讲:位图数组在 Redis 中的应用
- 第 03 讲:链表基础原理
- 第 04 讲:链表在 Apache Kafka 中的应用
- 模块二:哈希表的应用
- 第 05 讲:哈希函数的本质及生成方式
- 第 06 讲:哈希函数在 GitHub 和比特币中的应用
- 第 07 讲:哈希碰撞的本质及解决方式
- 第 08 讲:哈希表在 Facebook 和 Pinterest 中的应用
- 模块三:树的应用
- 第 09 讲:树的基本原理
- 第 10 讲:树在 Amazon 中的应用
- 第 11 讲:平衡树的性能优化
- 第 12 讲:LSM 树在 Apache HBase 等存储系统中的应用
- 模块四:图的应用
- 第 13 讲:用图来表达更为复杂的数据关系
- 第 14 讲:有向无环图在 Spark 中的应用
- 第 15 讲:图的实现方式与核心算法
- 第 16 讲:图在 Uber 拼车业务中的应用
- 模块五:数据结构组合拳
- 第 17 讲:缓存数据结构在 Nginx 中的应用
- 第 18讲:高并发数据结构在 Instagram 与 Twitter 中的应用