
前面的章节我们学习了用树表达层级化的数据,尤其是应用在数据的检索方面,树可以大大的优化数据查询效率。
而图相比树的结构则更为详尽,图可以包含一组相互连接的点。在深入图的规范定义之前,我们先来看看图有哪些应用场景,为什么需要应用图这样的节点间相互连接的数据结构。
#### 图的应用举例
社交网络。社交网络是典型的网络结构,图可以用点来表达社交关系中的人,用点与点之间的连接来表达人与人的关系。比如我们想要去表示谁认识谁、谁和谁沟通、谁能够影响谁等人与人之间的关系。一个具体的例子是在小红书上,比如,A 关注了 B 的小红书,可以用 A 指向 B 的线来连接表示。这些人与人的社交信息,可以用来去解释社交网络的信息流动。人与人之间的联系也定义了我们是谁。
交通网络。交通网络也可以用图来表达。比如所有的城市可以用图的节点来表示,城市间的交通渠道可以用边来表示。像最近大家关注的疫情封城措施,也可以用数据结构来理解,就是把交通网络图的一些边进行了阻隔。
互联网网站连接。我们经常看到网站上会有指向其他网址的超链接。如果我们把互联网所有的网页定义成图的节点,那么网页与网页之间的边就是这些链接了。如果大家熟悉 Google 经典的网页排名算法 PageRank,就会知道,搜索引擎正是用指向一个网页的引用数量去判断一个网页的质量。
* [ ] 图的定义、图的方向和权重
从数学规范上来讲一个图可以被定义成一个集合 G, G = (V,A) ,其中:
* V 是图的节点集合
* A ⊆ V × V 是节点与节点之间的连接的边,边可以是有向或者是无向的
我们来看两个例子,下图是一个有向图的例子,可以看到节点 C 指向节点 A,而节点 A 又指向了节点 D。这个我们可以理解成生活中比如微博上的关注,你可能关注了一个大 V,但是大 V 并不一定关注了你,这就是一个单向的关系,可以用有向图来建模。
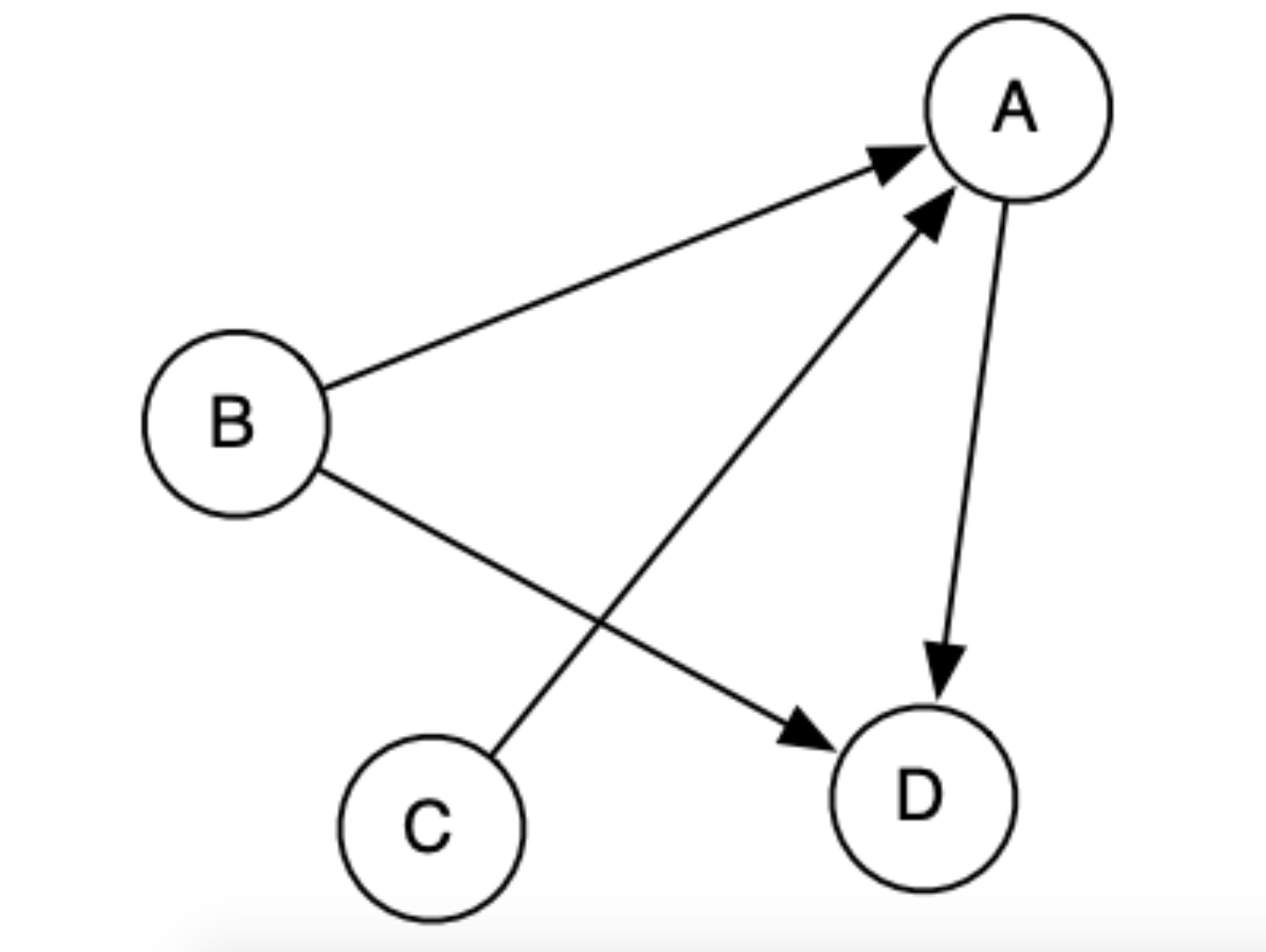
再看下面这个例子,其是一个无向图的例子。我们可以看到,所有的边都是没有方向的,也就是说点和点之间的关系是对称的。无向图在生活中也是非常常见的,比如在前面提到的交通网络,上海如果能通向北京的话,那北京也是能到达上海的。
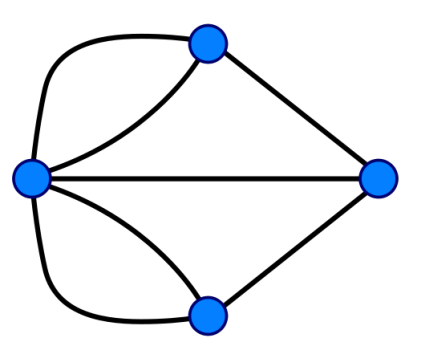
实际上有向图是比无向图更常用的图的类型。因为你可以把无向的边理解成同时由两个有向边组成。事实上我们在实现无向图的时候也经常用两条边来实现。比如说在微博上,如果你关注了 A,并且 A 也关注了你,我们就可以把你和 A 的关系看作是一条无向的边。
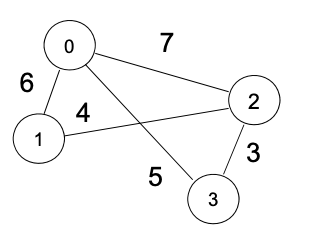
图的边也可以有权重。比如下图这个例子就是一个有权重的图,你可以看到 0 和 2 的边有权重 7,而 2 和 3 的边权重为 3。权重在网络关系中也很常见。比如在交通网络中,假设北京去上海的交通费用是 1000 元,而上海去武汉的交通费用是 2000 元;再比如在商品交易网络中,如果把世界上所有的商品做成一个图,商品与商品之间的交易价格定义成边,那么如果要用人民币购买口罩,则可能是 10 元人民币,但如果用人民币兑换成美元,则需要 7 元人民币。
#### 图和树的区别
学习到这里,你可能还会有疑问,树也是有节点和边,那么图和树究竟有啥区别呢?其实本质区别是,树和图所要抽象的数据关系不一样。树表达的是层级化的结构,图是用来表达网络化的结构。
例如,我们在树的章节中经常用公司的上下级关系来举例,因为树是有父节点和子节点这样的关系存在的。树有一个根节点,下面的每一棵子树都有唯一的根节点;而图则不一样,图的每一个节点都可以看作是平等的,并且节点与节点之间的连接也更为自由。在树中一个父节点只能与它的子节点相连,但不会看到父节点与孙子节点相连。但是在图中,任意节点都是可以相连的。
#### 图的实现和内存表达
相信你学到这里一定迫不及待地想要自己实现图了。图有两种常见的实现方式,一种是邻接矩阵法,另一种是邻接链表法。
* [ ] 1. 邻接矩阵法
使用邻接矩阵法的基本思想是开一个超大的数组,用数组中间元素的 true / false 来表达边。具体什么意思呢?比如你有 V 个节点的图,那么就需要一个 V×V 大小的数组。
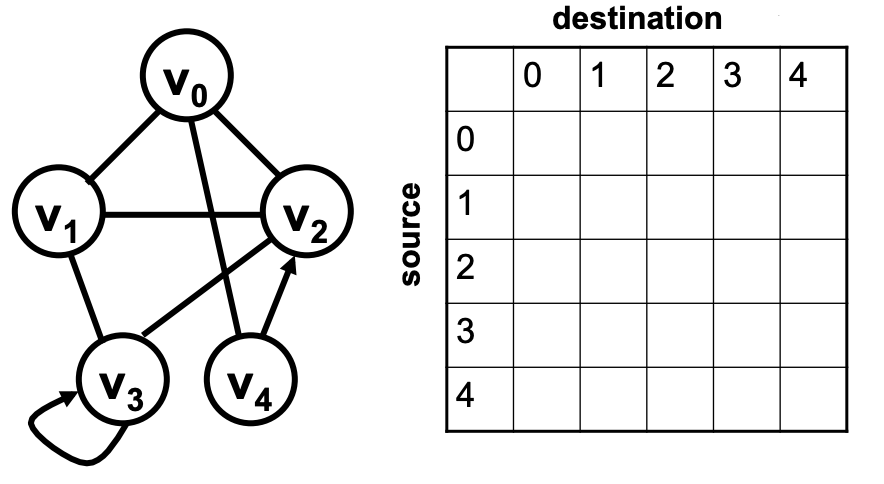
我们来看一个例子,下面这个例子中有 V0 - V4 总共 5 个节点,可以看到我们已经画出了一个 5 × 5 的二维数组 G。如果学习了之前数组章节中的二维数组,就知道可以用 G[i][j] 这样的寻址方式来找到第 i 行第 j 列的元素。在这个例子中规定,如果有从 Vi 指向 Vj 的边,那么 G[i][j] = true,反之如果没有边,则 G[i][j] = false。不如一起来看看在这个例子中有哪些数组元素会是 true。
我们首先看看 V4 指向 V2 的边,即 G[4][2] = true;接着再看看 V0 和 V2 之间的边是无向的,也就是说,我们需要 G[0][2] = true,同时 G[2][0] = true;最后看到 V3 有指向自己的边,所以 G[3][3] 也是 true,可以发现邻接矩阵法的实际上存储的是所有的边。
* [ ] 2. 邻接链表法
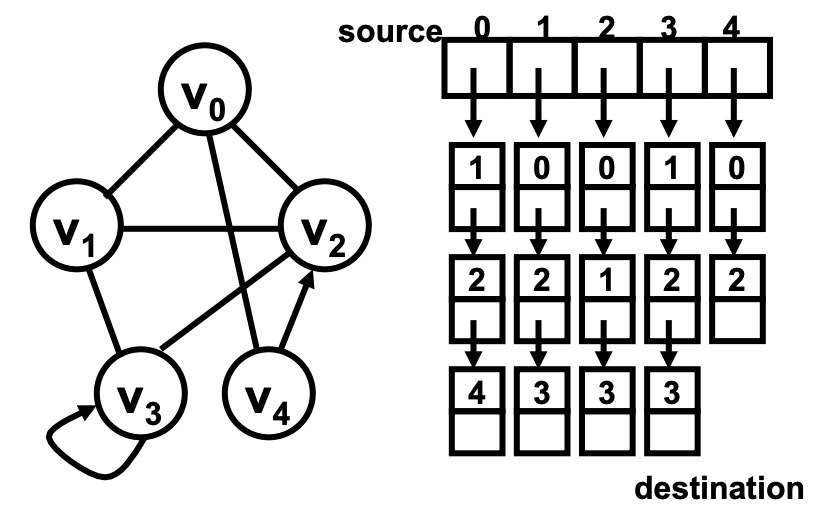
邻接链表法则是不一样的思路了,它的核心思想是把每一个节点所指向的点给存储起来。
比如还是同样一个图 V0 - V4,如果我们用邻接链表法表达的话,则需要一个含有 5 个元素的数组,用来存储这样 5 个节点;然后每个节点所指向的点都会维护在一个链表中。比如在这个例子中,V0 指向了 V1、V4、V2 三个节点,那么在内存中就会有从 0 指向 1 接着指向 2、4 类似这样的一个链表。同理我们看 V4 指向了 V0 和 V2,则在内存中就要维护一个 4→0→2 的单向链表。
这两种实现方式有什么区别呢?邻接矩阵法因为存储在二维数组中,我们在之前的章节中已经掌握了数组的特点,那就是随机访问快。在这里也一样,邻接矩阵法可以更快地添加和删除边,也可以更快地判断边是否存在,你只需要对 G[i][j] 这个元素操作就行了。
但是邻接矩阵法需要一个 O(V^2) 的内存空间,相对来说更适合边比较多的图,这样就可以更好的利用这些内存。因为邻接矩阵法存储的是边,不管有多少边,它都需要一样的内存。
邻接链表法可以更快地操作一个节点相邻的节点,在一个稀疏的图中也就是边比较少的图中,邻接链表法的效率其实是比较高的。因为每一个单链表都比较短,我们知道修改链表的时间复杂度是 O(n),同样也适用于邻接链表法。如果邻接链表法的边比较多,则链表就会比较长,进而影响我们的操作效率。邻接链表法的空间复杂度需要 O(|V| + |E|) 的内存空间。
#### 总结
这一讲我们学习了图的基本概念,搞清楚了图和树的区别,之后又仔细探究了图的两种实现方法。这些都为我们应用图这个数据结构打下了良好的基础,后面我们会马上学习图在现实工业界的应用。
- 前言
- 开篇
- 开篇词:从此不再“面试造火箭、工作拧螺丝”
- 模块一:数组与链表的应用
- 第 01 讲:数组内存模型
- 第 02 讲:位图数组在 Redis 中的应用
- 第 03 讲:链表基础原理
- 第 04 讲:链表在 Apache Kafka 中的应用
- 模块二:哈希表的应用
- 第 05 讲:哈希函数的本质及生成方式
- 第 06 讲:哈希函数在 GitHub 和比特币中的应用
- 第 07 讲:哈希碰撞的本质及解决方式
- 第 08 讲:哈希表在 Facebook 和 Pinterest 中的应用
- 模块三:树的应用
- 第 09 讲:树的基本原理
- 第 10 讲:树在 Amazon 中的应用
- 第 11 讲:平衡树的性能优化
- 第 12 讲:LSM 树在 Apache HBase 等存储系统中的应用
- 模块四:图的应用
- 第 13 讲:用图来表达更为复杂的数据关系
- 第 14 讲:有向无环图在 Spark 中的应用
- 第 15 讲:图的实现方式与核心算法
- 第 16 讲:图在 Uber 拼车业务中的应用
- 模块五:数据结构组合拳
- 第 17 讲:缓存数据结构在 Nginx 中的应用
- 第 18讲:高并发数据结构在 Instagram 与 Twitter 中的应用