
这一讲是哈希表模块的最后一讲,相信经过前三讲的学习之后,你已经对哈希函数、哈希碰撞以及哈希表这个数据结构有了深刻的了解。那今天我想和你分享一下哈希表这种数据结构是如何在硅谷的大厂中被应用到的。
#### 均摊时间复杂度
我们知道,哈希表是一个可以根据键来直接访问在内存中存储位置的值的数据结构。虽然哈希表无法对存储在自身的数据进行排序,但是它的插入和删除操作的均摊时间复杂度都属于均摊 O(1) (Amortized O(1))。均摊时间复杂度可以这样来理解:如果说一个数据结构的均摊时间复杂度是 X,那么这个数据结构的时间复杂度在大部分情况下都可以达到 X,只有当在极少数的情况下出现时间复杂度不是 X。
为什么在分析哈希表的时候我们会用到均摊时间复杂度呢?这主要是因为在处理哈希碰撞的时候,需要花费额外的时间去寻找下一个可用空间,这样造成的时间复杂度并不是 O(1)。极端情况下,所有插入的数据如果都产生了哈希碰撞,而我们采用的是分离链接法来解决哈希碰撞,那时间复杂度就变成了 O(N)。当然了,在现实中,其实哈希算法都已经设计得非常好了,造成哈希碰撞的情况是少数的,大部分时间,它的时间复杂度还是 O(1)。
所以若在面试中有面试官问你哈希表的时间复杂度,就可以好好的分析一下均摊时间复杂度了。
因为这种特性,使得哈希表的应用十分广泛,很常见的一种应用就是缓存(Cache),缓存这个概念其实不单单只是针对于内存来说的,可以抽象地把缓存看作是一种读取速度更快的媒介。比如说,对于同样的数据,因为读取内存上的数据会比硬盘上的数据更快一些,所以我们可以把内存看作是硬盘的缓存;当我们想要的数据结果需要通过数据库查询操作来完成的时候,把可以查询的结果存放在一台机器上,这样当下一次读取时就可以直接从这台机器上读取而不是通过耗时的数据库操作,此时就可以把这台机器看作是数据库的缓存了。
Memcached 和 Redis 这两个框架是现在应用得最广泛的两种缓存系统,它们的底层数据结构本质都是哈希表。那么下面我们就来一起看看它们是如何被应用在 Facebook 和 Pinterest 中的,进而了解哈希表这种数据结构的实战应用。
* [ ] Memcached 缓存
Memcache 是一种分布式的键值对存储系统,它的值可以存储多种文件格式,比如图片、视频等。Memcache 的一个很大特点就是数据完全保存在内存中,也就是说如果一台运行着 Memcache 的机器突然挂掉了,那保存在上面的数据就会全部丢失,所以我们可以把保存在 Memcache 中的数据看作是 Memcache 维护了一个超级大的哈希表数据结构,并没有任何内容保存在硬盘中。
同样的,因为每台机器的内存容量是有限的,如果存储的数据占满了一台机器的内存之后,再有新的数据想保存进 Memcache 的话,就必须把旧的数据删除掉。
* [ ] 哈希表在 Facebook 中的应用
Facebook 会把每个用户发布过的文字和视频、去过的地方、点过的赞、喜欢的东西等内容都保存下来,想要在一台机器上存储如此海量数据是完全不可能的,所以 Facebook 的做法是会维护为成千上万台机器运行 Memcache,不同的数据会保存在不同的 Memcache 中,这里我们可以看作是不同的数据都有不同的哈希表来维护它们。
对此,Facebook 自己做了一个名叫 mcrouter 的服务器集群出来,可以将不同的数据请求导向不同的 Memcache,而他们还开源了这个管理 mcrouter 的代码(开源代码)。
社交软件有一个很大的特点就是读操作会远远高于写操作,也就是说当用户打开 Facebook 之后,基本是在不断地刷新好友发布的内容,而 Facebook 在全球拥有着超过 24 亿的用户,如果每个用户的刷新都需要到数据库进行查询操作的话,那数据库肯定扛不住这么大的流量。
但是很多数据不从数据库读取的话是拿不到最新数据的,怎么办呢?解决的方案是在第一次读取数据之后,将这些通过数据库算出的结果存放在 Memcache 中并设定一个过期时间。只要数据没有超过设置的过期时间,后续的所有读取都不需要通过数据库计算,而是直接从 Memcache 中读取。下面就以几个 Facebook 的实际应用来说明一下。
* [ ] 好友生日提醒
最简单的应用就是 Facebook 里的好友生日提醒了,其做法是将用户 ID 和用户的生日日期作为键值对存放在 Memcache 中。每个用户在当天登录的时候,会先以所有的好友 ID 作为键,去 Memcache 中寻找是否有他们的数据存在,如果存在则判断当天的日期是否是好友生日的日期,然后决定是否发送生日提醒;如果不存在,则先去数据库中拿出所有好友的生日日期,然后存在 Memcache 中,最后返回给用户判断。
当然了,Facebook 的设定是允许用户修改生日日期的,这样就无法将用户的生日直接存放在 Memcache 之后就一劳永逸了,如果用户修改了自己的生日在更新数据库的同时也需要发送请求删除 Memcache 中的数据。
就是这样简单的一个功能,其实每天都会对 Memcache 这个哈希表产生数十亿次操作。
* [ ] 通过访问直播链接来看回放
而另外一个大量利用了哈希表这个数据结构的 Facebook 应用是 Facebook Live。Facebook Live 是一个直播应用,它的一个特点是即使用户错过了直播时间,后面也可以通过访问直播链接来观看回放。在这里,Facebook 把每一个直播的视频流数据按照每一秒钟的时间分割成一个块(Segment),每一个视频流块都会被存放在 Memcache 中。当用户读取直播视频流的时候,会以直播 ID 加上这个时间进度作为哈希表的键,来读取每一秒的直播视频。
2016 年 Facebook 技术讲座的整体架构如下图所示:
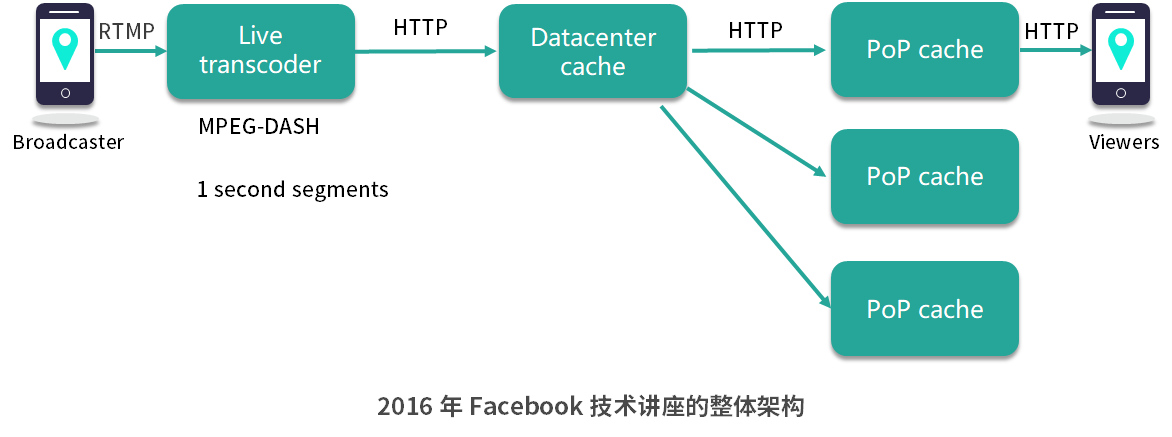
从上图中可以看到,直播视频其实在经过处理之后首先会被存入数据库,然后在往上一层再做了一个 Memcache 内容缓存。
* [ ] Redis 缓存
说到以哈希表作为底层数据结构的系统,除了 Memcache 之外,另外一个著名系统就是 Redis 了。Redis 与 Memcache 一样,同样是一个保存键值对的存储系统。它与 Memcache 的一个很大不同是,保存在 Redis 上的数据会每间隔一段时间写入到磁盘中,以防止当机器宕机后可以重新恢复数据。
Redis 所支持的数据类型也十分简单,包括 Strings、Lists、Sets、Sorted Sets、Hashes 和之前介绍的 Bitmaps 等。下面将介绍 Redis 是如何被利用在“美版小红书” Pinterest 中的。
* [ ] 哈希表在 Pinterest 中的应用
在 Pinterest 的应用里,每个用户都可以发布一个叫 Pin 的东西,Pin 可以是自己原创的一些想法,也可以是物品,还可以是图片视频等,不同的 Pin 可以被归类到一个 Board 里面。比如说在一个体育 Board 里面,可以有用户发布的球鞋的 Pin,体育视频的 Pin,或者对某个体育明星采访的 Pin。
我们可以通过关注 Board 和 Pin 来获取推荐系统给用户发布的内容。比方说,如果一个用户关注了 Board A,那每当 Board A 有新的 Pin 加进去的时候都会推送给这个用户。用户 A 也可以通过关注用户 B,那以后用户 B 所发布的每一个 Pin 和 Board 都会推送给用户 A。
Pinterest 在全球拥有着超过 3 亿的活跃用户,上面也提到过,社交软件的读操作会远远高于写操作,推荐系统的算法在很大程度上是通过读取每个用户的关系图来进行推荐的。如果每次用户的内容推荐都需要到数据库中去读取他所关注的用户,同时再读取关注的用户发布过的 Board 和 Pin,这样的话读取速度会非常慢。所以 Pinterest 将很多这些关系图都保存在了 Redis 里面,从而不必从数据库中读取内容。
从 Pinterest 公布的工程论文中可以知道,他们会将一个用户所关注的其他用户保存在 Sorted Sets 里。一个 Set 是一个集合,本质上也可以看作是一个哈希表,而我们所关心的只是这个哈希表中的键,而不是它的值。比如说我们所关心的是这个 Set 里某一个键是否已经被插入了,如果是,则表示这个键存在 Set 里。
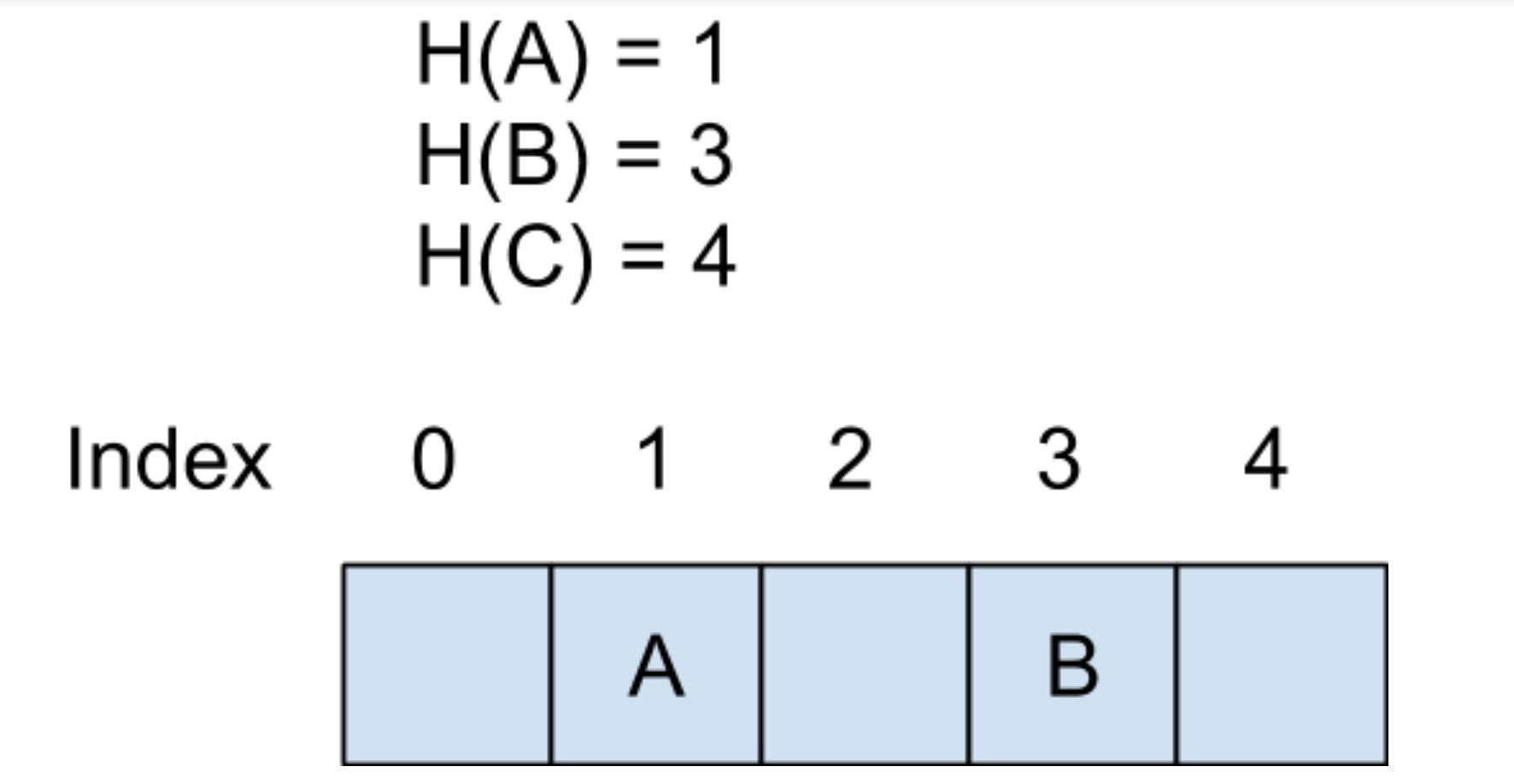
下面以一个例子来说明一下,假设这里的哈希函数是 H(X),键 A 和键 B 都已经插入到哈希表中了,而 C 并没有插入,所以我们判断出 A 和 B 是在这个集合里的,而 C 并不存在集合里。
Sorted Sets 这个类型其实就是在 Set 外的基础上加上了一个 Score 的概念,Redis 内部会根据 Score 的大小对插入的键进行排序。比如说,Pinterest 会把一个用户所关注的其他用户按照以关注时间戳为 Score,关注的用户 ID 作为键存放在 Sorted Sets 里。
这样做的好处就是当一个用户在查看自己所有关注过的用户时,可以读取所有存储在这个 Sorted Sets 里的数据,而因为 Score 的值是关注这个用户的时间戳,所以读取数据出来的时候,会按照自己关注他们的时间顺序读取出来,而不是乱序地读取关注过的用户。
Pinterest 也会将对于一个 Board 的所有关注用户存放在 Redis 的 Hash 里。这样,一个 Board 每次发布一个新的 Pin 之后,就无需到数据库中寻找应该推送这个 Pin 给哪些用户了,而是直接从 Redis 中读取所有关注了这个 Board 的用户。
- 前言
- 开篇
- 开篇词:从此不再“面试造火箭、工作拧螺丝”
- 模块一:数组与链表的应用
- 第 01 讲:数组内存模型
- 第 02 讲:位图数组在 Redis 中的应用
- 第 03 讲:链表基础原理
- 第 04 讲:链表在 Apache Kafka 中的应用
- 模块二:哈希表的应用
- 第 05 讲:哈希函数的本质及生成方式
- 第 06 讲:哈希函数在 GitHub 和比特币中的应用
- 第 07 讲:哈希碰撞的本质及解决方式
- 第 08 讲:哈希表在 Facebook 和 Pinterest 中的应用
- 模块三:树的应用
- 第 09 讲:树的基本原理
- 第 10 讲:树在 Amazon 中的应用
- 第 11 讲:平衡树的性能优化
- 第 12 讲:LSM 树在 Apache HBase 等存储系统中的应用
- 模块四:图的应用
- 第 13 讲:用图来表达更为复杂的数据关系
- 第 14 讲:有向无环图在 Spark 中的应用
- 第 15 讲:图的实现方式与核心算法
- 第 16 讲:图在 Uber 拼车业务中的应用
- 模块五:数据结构组合拳
- 第 17 讲:缓存数据结构在 Nginx 中的应用
- 第 18讲:高并发数据结构在 Instagram 与 Twitter 中的应用