
:-: 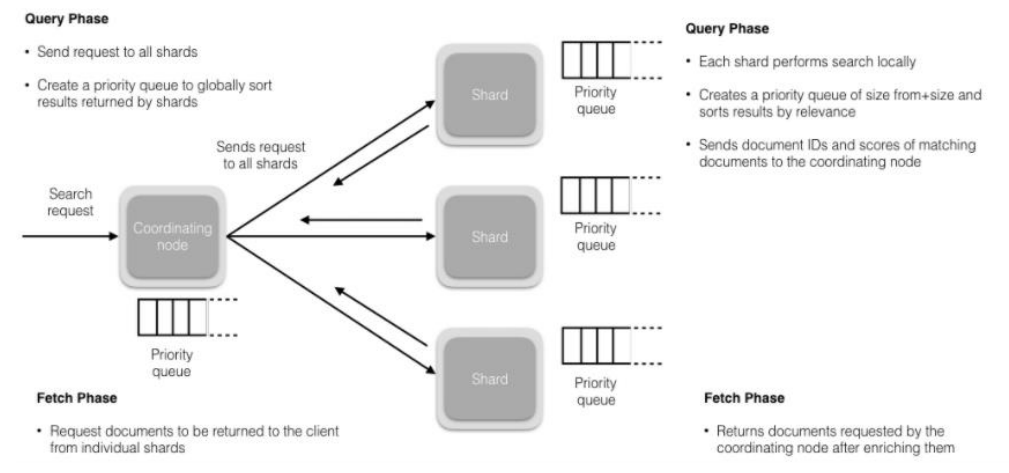
1. 搜索被执行成一个两阶段过程,我们称之为 Query Then Fetch。
2. 在初始查询阶段时,查询会广播到索引中每一个分片拷贝(主分片或者副本分片)。 每个分片在本地执行搜索并构建一个匹配文档的大小为 from + size 的优先队列。PS:在搜索的时候是会查询Filesystem Cache 的,但是有部分数据还在 Memory Buffer,所以搜索是近实时的。
3. 每个分片返回各自优先队列中 所有文档的 ID 和排序值 给协调节点,它合并这些值到自己的优先队列中来产生一个全局排序后的结果列表。
4. 接下来就是取回阶段,协调节点辨别出哪些文档需要被取回并向相关的分片提交多个 GET 请求。每个分片加载并丰富文档,如果有需要的话,接着返回文档给协调节点。一旦所有的文档都被取回了,协调节点返回结果给客户端。
5. Query Then Fetch 的搜索类型在文档相关性打分的时候参考的是本分片的数据,这样在文档数量较少的时候可能不够准确,DFS Query Then Fetch 增加了一个预查询的处理,询问 Term 和 Document frequency,这个评分更准确,但是性能会变差。
- Elasticsearch是什么
- 全文搜索引擎
- Elasticsearch与Solr
- 数据结构
- 安装Elasticsearch
- Linux单机安装
- Windows单机安装
- 安装Kibana
- Linux安装
- Windows安装
- es基本语句
- 索引操作
- 文档操作
- 映射操作
- 高级查询
- es-JavaAPI
- maven依赖
- 索引操作
- 文档操作
- 高级查询
- es集群搭建
- Linux集群搭建
- Windows集群搭建
- 核心概念
- 索引(Index)
- 类型(Type)
- 文档(Document)
- 字段(Field)
- 映射(Mapping)
- 分片(Shards)
- 副本(Replicas)
- 分配(Allocation)
- 系统架构
- 分布式集群
- 单节点集群
- 故障转移
- 水平扩容
- 应对故障
- 路由计算
- 分片控制
- 写流程
- 读流程
- 更新流程
- 多文档操作流程
- 分片原理
- 倒排索引
- 文档搜索
- 动态更新索引
- 近实时搜索
- 持久化变更
- 段合并
- 文档分析
- 内置分析器
- 分析器使用场景
- 测试分析器
- 指定分析器
- 自定义分析器
- 文档处理
- 文档冲突
- 乐观并发控制
- 外部系统版本控制
- es优化
- 硬件选择
- 分片策略
- 合理设置分片数
- 推迟分片分配
- 路由选择
- 写入速度优化
- 批量数据提交
- 优化存储设备
- 合理使用合并
- 减少Refresh的次数
- 加大Flush设置
- 减少副本的数量
- 内存设置
- 重要配置
- es常见问题
- 为什么要使用Elasticsearch
- master选举流程
- 集群脑裂问题
- 索引文档流程
- 更新和删除文档流程
- 搜索流程
- ES部署在Linux时的优化方法
- GC方面ES需要注意的点
- ES对大数据量的聚合实现
- 并发时保证读写一致性
- 字典树
- ES的倒排索引
- Spring Data Elasticsearch
- 环境搭建
- 索引操作
- 文档操作