
### 栈上分配
故名思议就是在栈上分配对象,栈上分配主要是指在Java程序的执行过程中,在方法体中声明的变量以及创建的对象,将直接从该线程所使用的栈中分配空间。 一般而言,创建对象都是从堆中来分配的,这里是指在栈上来分配空间给新创建的对象;其实目前Hotspot并没有实现真正意义上的栈上分配,实际上是标量替换。
栈上分配的好处一方面更加快速,另一方面是方法结束时对象也被回收了
```
private static int fn(int age) {
User user = new User(age);
int i = user.getAge();
return i;
}
```
User对象的作用域局限在方法fn中,可以使用标量替换的优化手段在栈上分配对象的成员变量,这样就不会生成User对象,大大减轻GC的压力,下面通过例子看看逃逸分析的影响。
```
public class JVM {
public static void main(String[] args) throws Exception {
int sum = 0;
int count = 1000000;
//warm up
for (int i = 0; i < count ; i++) {
sum += fn(i);
}
Thread.sleep(500);
for (int i = 0; i < count ; i++) {
sum += fn(i);
}
System.out.println(sum);
System.in.read();
}
private static int fn(int age) {
User user = new User(age);
int i = user.getAge();
return i;
}
}
class User {
private final int age;
public User(int age) {
this.age = age;
}
public int getAge() {
return age;
}
}
```
分层编译和逃逸分析在1.8中是默认是开启的,例子中fn方法被执行了200w次,按理说应该在Java堆生成200w个User对象
1、通过java -cp . -Xmx3G -Xmn2G -server -XX:-DoEscapeAnalysis JVM运行代码,-XX:-DoEscapeAnalysis关闭逃逸分析,通过jps查看java进程的PID,接着通过jmap -histo \[pid\]查看java堆上的对象分布情况,结果如下:
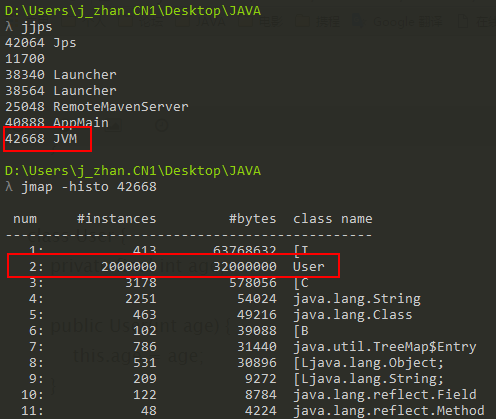
可以发现:关闭逃逸分析之后,User对象一个不少的都在堆上进行分配
2、通过
```
java -cp . -Xmx3G -Xmn2G -server JVM
```
运行代码,结果如下:
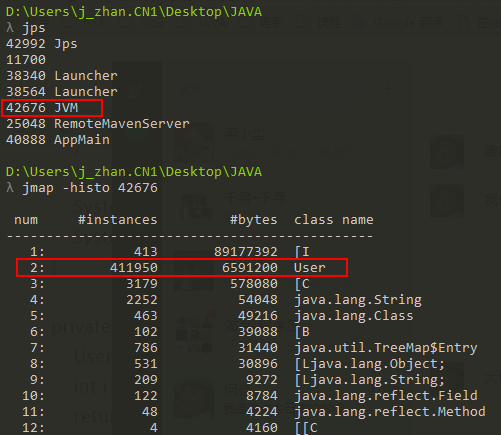
可以发现:开启逃逸分析之后,只有41w左右的User对象在Java堆上分配,其余的对象已经通过标量替换优化了。
3、通过
```
java -cp . -Xmx3G -Xmn2G -server -XX:-TieredCompilation
```
运行代码,关闭分层编译,结果如下
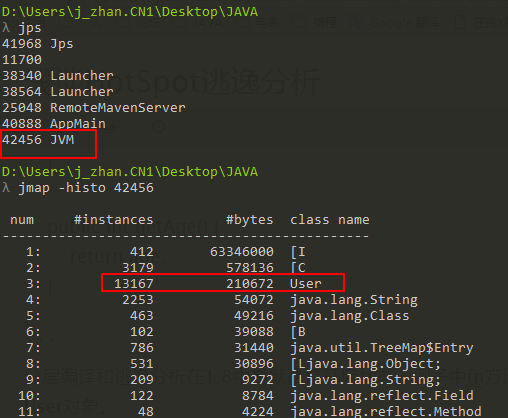
可以发现:关闭了分层编译之后,在Java堆上分配的User对象降低到1w多个,分层编译对逃逸分析还是有影响的
- 前言
- Write once, run anywhere
- 概述
- JAVA虚拟机
- JVM整体结构
- JVM架构模型
- JVM虚拟机分类
- HotSpot VM
- JRockit
- IBM-J9
- Azul/zing VM
- Taobao VM
- Dalvik VM
- Graal VM
- JAVA源码编译机制
- Javac编译器
- 分析和输入到符号表
- 注解处理
- 语义分析和生成class文件
- ECJ编译器
- 类执行机制
- 字节码解释执行
- 栈顶缓存
- 部分栈帧共享
- 编译执行
- 即时编译器
- C1 Compiler
- C2 Compiler
- Graal编译器
- C1与C2编译器
- AOT
- 编译优化
- 字符串优化
- 方法内联
- 逃逸分析
- 同步消除
- 标量替换
- 栈上分配
- 去虚拟化/逆优化
- 多层编译
- JVM编译策略
- OSR编译
- 冗余削除
- CodeCache
- 常量编译优化
- JVM运行时数据区
- 程序计数器
- JAVA虚拟机栈
- 栈帧
- 局部变量表
- 操作数栈
- 本地方法栈
- Java调用native方法
- JVM Stacks && Native Stacks
- 堆-Heap
- 方法区(Method Area)
- 运行时常量池
- 常量传播优化
- MetaSpace
- 直接内存
- StackOverflowError
- 递归方法
- OutOfMemoryError
- 本地内存溢出
- 执行引擎
- 运行时数据区关联关系
- jdk8内存结构
- JMM内存模型
- JAVA内存模型
- JMM八种操作指令
- 内存屏障
- 指令重排
- as-if-serial语义
- Happen-Before规则
- 数据依赖性
- 原子性、可见性与有序性
- 伪共享
- CPU三级缓存
- 缓存行
- MESI协议
- Java中的伪共享
- ConcurrentHashMap伪共享解决方案
- 虚拟机对象
- 对象创建原理
- 对象内存布局
- 对象头
- 实例数据
- 对象的访问定位
- 垃圾收集器与内存分配策略
- GC相关概念
- TLAB
- JVM GC工作原理
- 内存管理
- JAVA引用分类
- 死亡标记
- 回收方法区
- 三色标记算法
- 垃圾收集算法
- 标记-清除算法
- 标记-整理算法
- 复制算法
- 分代收集算法
- HotSpot算法实现
- STW
- 垃圾收集器
- 常见的垃圾收集器
- 垃圾收集器分类
- Serial收集器
- Serial Old收集器
- ParNew收集器
- Parallel Scavenge收集器
- Parallel Old收集器
- CMS收集器
- CMS完整收集过程
- Card Table
- G1收集器
- 分代收集
- 空间整合
- 可预测的停顿时间模型
- G1&CMS
- 主要参数说明
- G1适用场景
- Remembered Set
- G1垃圾回收的过程
- G1优化建议
- Shenandoah
- ZGC
- 垃圾收集器特点
- GC日志
- GC策略的评价指标
- jvm card table数据结构
- 对象生存轨迹
- 类文件结构
- 魔数
- 版本号
- 常量池
- 访问标志
- 父类索引
- 接口集合
- 字段集合
- 方法集合
- 属性集合
- 类加载机制与类的初始化
- Java代码执行流程
- 类加载过程
- 抽象类ClassLoader
- 常见类加载器
- BootstrapClassLoader
- 自定义类加载器
- 线程上下文类加载器
- 双亲委派模型
- Tomcat类加载机制
- ServiceLoader
- 类的初始化
- 常见的JVM类加载异常
- ClassNotFoundException
- NoClassDefFoundError
- LinkageError
- ClassCastException
- 虚拟机性能调优监控与故障处理工具
- CPU利用率高/飙升
- 排查及解决方案
- 上下文切换
- GC问题定位解决方案
- prommotion failed
- FullGC频繁
- youngGC
- 内存问题
- 内存溢出和内存泄漏
- 内存溢出
- 栈溢出
- 堆溢出
- 对外内存溢出
- 内存泄漏
- 磁盘问题
- 线上问题解决方案
- 不定期出现的接口耗时现象
- 线程池异常
- 死锁问题
- JVM调优
- jvm参考配置
- jvm-jstat
- jvm-jmap
- jvm-jstack
- jinfo
- jps
- 虚拟机的退出
- Shutdown Hook
- JVM指令
- 附录
- 常用JVM指令
- Class文件版本号
- Class文件格式
- 方法访问标识
- jvm常量池
- 类或接口的访问标识
- 描述符标识字符含义
- 字段访问标识
- Java程序与Docker容器环境
- 基准测试