
[TOC]
## **粘包说明**
说明粘包问题,需要先看做一次下面的小实验,根据结果来看原理
### **基于TCP的简单ssh程序**
写一个远程执行命令的程序,写一个socket client端在windows端发送指令,一个socket server在Linux端执行命令并返回结果给客户端
执行命令的话,肯定是用我们学过的subprocess模块啦,但要**注意操作系统的编码问题**:
Windows用的GBK,linux用的utf-8
~~~
res = subprocess.Popen(cmd.decode('utf-8'),shell=True,stderr=subprocess.PIPE,stdout=subprocess.PIPE)
~~~
**ssh server代码**
仅在源代码上加入了命令执行部分,其他结构都没有变化
~~~
import socket,subprocess
phone=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
phone.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1)
phone.bind(('127.0.0.1',8800))
phone.listen(5)
print('starting...')
while True: # 链接循环
conn,client_addr=phone.accept()
print(client_addr)
while True: #通信循环
try:
#1、收命令
cmd=conn.recv(1024)
if not cmd:break
#2、执行命令,拿到结果
obj = subprocess.Popen(cmd.decode('utf-8'), shell=True,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE)
stdout=obj.stdout.read()
stderr=obj.stderr.read()
#3、把命令的结果返回给客户端
print(len(stdout)+len(stderr))
conn.send(stdout+stderr) #+是一个可以优化的点
except ConnectionResetError:
break
conn.close()
phone.close()
~~~
**ssh client代码**
client端代码无任何变化,仅添加部分注释
~~~
import socket
phone=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
phone.connect(('127.0.0.1',8800))
while True:
#1、发命令
cmd=input('>>: ').strip() #ls /etc
if not cmd:continue
phone.send(cmd.encode('utf-8'))
#2、拿命令的结果,并打印
data=phone.recv(1024)
print(data.decode('utf-8'))
phone.close()
~~~
### **粘包说明**
在上面的程序中,尝试执行ls、pwd等结果长度较少的命令时,拿到了正确的结果!
但执行一个结果比较长的命令,比如top -bn 1, 你发现依然可以拿到结果,再执行一条df -h的话,就发现拿到并不是df命令的结果,而是上一条top命令的部分结果。
这个现象叫做粘包,就是指两次结果粘到一起了
* 起因
op命令的结果比较长,但客户端只recv(1024), 可结果比1024长呀,那只好在服务器端的IO缓冲区里把客户端还没收走的暂时存下来,等客户端下次再来收,所以当客户端第2次调用recv(1024)就会首先把上次没收完的数据先收下来,再收df命令的结果。
而且有关部门建议recv不要超过8192,再大反而会出现影响收发速度和不稳定的情况,所以不能通过该带reve来解决
* 原因
所谓粘包问题主要还是因为接收方不知道消息之间的界限,不知道一次性提取多少字节的数据所造成的。
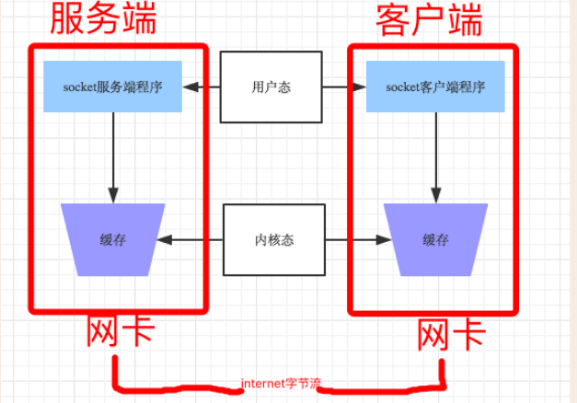
我们的应用程序实际上无权直接操作网卡的,操作网卡都是通过操作系统给用户程序暴露出来的接口,每次程序要给远程发数据时,其实是先把数据从用户态copy到内核态后由操作系统完成后续工作,而Nagle算法会将多次间隔较小且数据量小的数据,合并成一个大的数据块,然后进行封包,这样接收方就收到了粘包数据。
### **粘包总结**
1. TCP(transport control protocol,传输控制协议)
是面向连接的,面向流的,提供高可靠性服务。收发两端(客户端和服务器端)都要有一一成对的socket,因此,发送端为了将多个发往接收端的包,更有效的发到对方,使用了优化方法(Nagle算法),将多次间隔较小且数据量小的数据,合并成一个大的数据块,然后进行封包。这样,接收端,就难于分辨出来了,必须提供科学的拆包机制。 **即面向流的通信是无消息保护边界的。**
2. UDP(user datagram protocol,用户数据报协议)
是无连接的,面向消息的,提供高效率服务。不会使用块的合并优化算法,, 由于UDP支持的是一对多的模式,所以接收端的skbuff(套接字缓冲区)采用了链式结构来记录每一个到达的UDP包,在每个UDP包中就有了消息头(消息来源地址,端口等信息),这样,对于接收端来说,就容易进行区分处理了。**即面向消息的通信是有消息保护边界的。**
3. 空消息的处理
tcp是基于数据流的,于是收发的消息不能为空,这就需要在客户端和服务端都添加空消息的处理机制,防止程序卡住
而udp是基于数据报的,即便输入的是空内容,那也不是空消息,udp协议会帮你封装上消息头
## **粘包问题解决**
解决粘包问题的问题的思路,就是先发送数据前,先统计一下当前需要发送的数据有多长,然后将数据长度告诉对端,让对端只接收指定长度的数据即可
### **两种做法说明:**
1. low逼做法
手动统计数据长度,然后先发送数据长度给对端,待对端回复消息后再发送真实数据
2. 大牛做法
将数据长度作为数据报头封装到真实数据前面,只要能指定报头长度(如4bytes),即可让对端先接收指定长度的报头,在根据报头中写入的数据长度大小,通过for循环接收真实数据
### **struct模块解决粘包**
python中的struct模块正好可以解决报头定长的问题,通过len方法计算数据长度后,通过struct模块转换为定长数据,然后就可以用来做报头数据了
**server端代码**
```
import socket,subprocess,struct
phone=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
phone.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1)
phone.bind(('127.0.0.1',8800))
phone.listen(5)
print('starting...')
while True: # 链接循环
conn,client_addr=phone.accept()
print(client_addr)
while True: #通信循环
try:
cmd=conn.recv(8096)
if not cmd:break
obj = subprocess.Popen(cmd.decode('utf-8'), shell=True,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE)
stdout=obj.stdout.read()
stderr=obj.stderr.read()
#第一步:制作固定长度的报头
total_size = len(stdout) + len(stderr)
header=struct.pack('i',total_size)
#第二步:把报头发送给客户端
conn.send(header)
#第三步:再发送真实的数据
conn.send(stdout)
conn.send(stderr)
except ConnectionResetError:
break
conn.close()
phone.close()
```
**client端代码**
```
import socket,struct
phone=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
phone.connect(('127.0.0.1',9909))
while True:
cmd=input('>>: ').strip() #ls /etc
if not cmd:continue
phone.send(cmd.encode('utf-8'))
#第一步:先收报头
header=phone.recv(4) #报头长度是自己计划好的
#第二步:从报头中解析出对真实数据的描述信息(数据的长度)
total_size=struct.unpack('i',header)[0]
#第三步:接收真实的数据
recv_size=0
recv_data=b''
while recv_size < total_size:
res=phone.recv(1024)
recv_data+=res
recv_size+=len(res)
print(recv_data.decode('utf-8'))
phone.close()
```
### **struct+json终极解决粘包**
既然可以用struct来做定长报头,那就可以更进一步,使用json序列化模块,在报头中写入更多信息
**server代码**
```
import socket,subprocess,struct,json
phone=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
phone.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1)
phone.bind(('127.0.0.1',9909))
phone.listen(5)
print('starting...')
while True: # 链接循环
conn,client_addr=phone.accept()
print(client_addr)
while True: #通信循环
try:
cmd=conn.recv(8096)
if not cmd:break
obj = subprocess.Popen(cmd.decode('utf-8'), shell=True,
stdout=subprocess.PIPE,stderr=subprocess.PIPE)
stdout=obj.stdout.read()
stderr=obj.stderr.read()
#第一步:制作固定长度的报头
header_dic={
'filename':'a.txt',
'md5':'xxdxxx',
'total_size': len(stdout) + len(stderr)
}
header_json=json.dumps(header_dic)
header_bytes=header_json.encode('utf-8')
#第二步:先发送报头的长度
conn.send(struct.pack('i',len(header_bytes)))
#第三步:再发报头
conn.send(header_bytes)
#第四步:再发送真实的数据
conn.send(stdout)
conn.send(stderr)
except ConnectionResetError:
break
conn.close()
phone.close()
```
**client端代码**
```
import socket,struct,json
phone=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
phone.connect(('127.0.0.1',9909))
while True:
cmd=input('>>: ').strip() #ls /etc
if not cmd:continue
phone.send(cmd.encode('utf-8'))
#第一步:先收报头的长度
obj=phone.recv(4)
header_size=struct.unpack('i',obj)[0]
#第二步:再收报头
header_bytes=phone.recv(header_size)
#第三步:从报头中解析出对真实数据的描述信息
header_json=header_bytes.decode('utf-8')
header_dic=json.loads(header_json)
print(header_dic)
total_size=header_dic['total_size']
#第四步:接收真实的数据
recv_size=0
recv_data=b''
while recv_size < total_size:
res=phone.recv(1024) #按1024循环收取
recv_data+=res
recv_size+=len(res)
print(recv_data.decode('utf-8'))
phone.close()
```
- 基础部分
- 基础知识
- 变量
- 数据类型
- 数字与布尔详解
- 列表详解list
- 字符串详解str
- 元组详解tup
- 字典详解dict
- 集合详解set
- 运算符
- 流程控制与循环
- 字符编码
- 编的小程序
- 三级菜单
- 斐波那契数列
- 汉诺塔
- 文件操作
- 函数相关
- 函数基础知识
- 函数进阶知识
- lambda与map-filter-reduce
- 装饰器知识
- 生成器和迭代器
- 琢磨的小技巧
- 通过operator函数将字符串转换回运算符
- 目录规范
- 异常处理
- 常用模块
- 模块和包相关概念
- 绝对导入&相对导入
- pip使用第三方源
- time&datetime模块
- random随机数模块
- os 系统交互模块
- sys系统模块
- shutil复制&打包模块
- json&pickle&shelve模块
- xml序列化模块
- configparser配置模块
- hashlib哈希模块
- subprocess命令模块
- 日志logging模块基础
- 日志logging模块进阶
- 日志重复输出问题
- re正则表达式模块
- struct字节处理模块
- abc抽象类与多态模块
- requests与urllib网络访问模块
- 参数控制模块1-optparse-过时
- 参数控制模块2-argparse
- pymysql数据库模块
- requests网络请求模块
- 面向对象
- 面向对象相关概念
- 类与对象基础操作
- 继承-派生和组合
- 抽象类与接口
- 多态与鸭子类型
- 封装-隐藏与扩展性
- 绑定方法与非绑定方法
- 反射-字符串映射属性
- 类相关内置方法
- 元类自定义及单例模式
- 面向对象的软件开发
- 网络-并发编程
- 网络编程SOCKET
- socket简介和入门
- socket代码实例
- 粘包及粘包解决办法
- 基于UDP协议的socket
- 文件传输程序实战
- socketserver并发模块
- 多进程multiprocessing模块
- 进程理论知识
- 多进程与守护进程
- 锁-信号量-事件
- 队列与生产消费模型
- 进程池Pool
- 多线程threading模块
- 进程理论和GIL锁
- 死锁与递归锁
- 多线程与守护线程
- 定时器-条件-队列
- 线程池与进程池(新方法)
- 协程与IO模型
- 协程理论知识
- gevent与greenlet模块
- 5种网络IO模型
- 非阻塞与多路复用IO实现
- 带着目标学python
- Pycharm基本使用
- 爬虫
- 案例-爬mzitu美女
- 案例-爬小说
- beautifulsoup解析模块
- etree中的xpath解析模块
- 反爬对抗-普通验证码
- 反爬对抗-session登录
- 反爬对抗-代理池
- 爬虫技巧-线程池
- 爬虫对抗-图片懒加载
- selenium浏览器模拟