
[toc]
## 网络IO的模型分类
此IO模型出至Richard Stevens的<<UNIX® Network Programming Volume 1>>
Stevens在文章中一共比较了五种IO Model:
* blocking IO 阻塞IO
* nonblocking IO 非阻塞IO
* IO multiplexing IO多路复用
* signal driven IO 型号驱动IO
* asynchronous IO 异步IO
>由signal driven IO(信号驱动IO)在实际中并不常用,所以主要介绍其余四种IO Model。
对于一个network IO (以read举例),它会涉及到两个系统对象,一个是调用这个IO的process (or thread),另一个就是系统内核(kernel)。当一个read操作发生时,该操作会经历两个阶段:
~~~
1)等待数据准备 (Waiting for the data to be ready)
2)将数据从内核拷贝到进程中(Copying the data from the kernel to the process)
~~~
这两点很重要,因为这些IO模型的区别就是在两个阶段上各有不同的情况。
## **阻塞IO(blocking IO)**
在linux中,默认情况下所有的socket都是blocking,一个典型的读操作流程大概是这样:
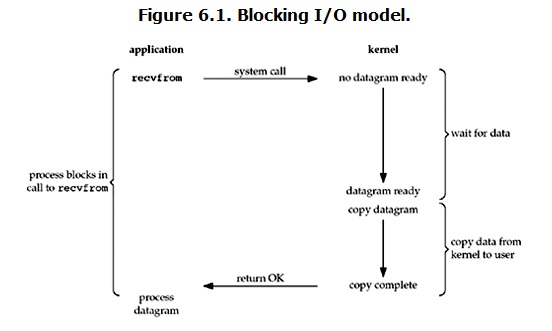
* 准备数据阶段
当用户进程调用了recvfrom这个系统调用,kernel就开始了IO的第一个阶段:准备数据。对于network io来说,很多时候数据在一开始还没有到达,这个时候kernel就要等待足够的数据到来。
而在用户进程这边,整个进程会被阻塞。
* 拷贝数据阶段
当kernel一直等到数据准备好了,它就会将数据从kernel中拷贝到用户内存,然后kernel返回结果,用户进程才解除block的状态,重新运行起来。
* 总结
**blocking IO的特点就是在IO执行的两个阶段(等待数据和拷贝数据两个阶段)都被block了。**
* 多线程能否解决
**对应所面临的可能同时出现的上千甚至上万次的客户端请求,“线程池”或“连接池”或许可以缓解部分压力,但是不能解决所有问题。总之,多线程模型可以方便高效的解决小规模的服务请求,但面对大规模的服务请求,多线程模型也会遇到瓶颈**
可以用非阻塞接口来尝试解决这个问题。
## **非阻塞IO(non-blocking IO)**
Linux下,可以通过设置socket使其变为non-blocking。当对一个non-blocking socket执行读操作时,流程是这个样子:

* 数据准备阶段
当用户进程发出read操作时,如果kernel中的数据还没有准备好,那么它并不会block用户进程,而是立刻返回一个error。
从用户进程角度讲 ,它发起一个read操作后,并不需要等待,而是马上就得到了一个结果。用户进程判断结果是一个error时,它就知道数据还没有准备好,于是用户就可以在本次到下次再发起read询问的时间间隔内做其他事情,或者直接再次发送read操作。
* 拷贝数据阶段
一旦kernel中的数据准备好了,并且又再次收到了用户进程的system call,那么它马上就将数据拷贝到了用户内存(这一阶段仍然是阻塞的),然后返回。
~~~
也就是说非阻塞的recvform系统调用调用之后,进程并没有被阻塞,
内核马上返回给进程,如果数据还没准备好,此时会返回一个error。
进程在返回之后,可以干点别的事情,然后再发起recvform系统调用。
重复上面的过程,循环往复的进行recvform系统调用,这个过程通常被称之为轮询。
轮询检查内核数据,直到数据准备好,再拷贝数据到进程,进行数据处理。
需要注意,拷贝数据整个过程,进程仍然是属于阻塞的状态。
~~~
* 总结
**在非阻塞式IO中,用户进程其实是需要不断的主动询问kernel数据准备好了没有。**
**但是非阻塞IO模型绝不被推荐。**
* 优点
能够在等待任务完成的时间里干其他活了(包括提交其他任务,也就是 “后台” 可以有多个任务在“”同时“”执行)。
* 缺点:
循环调用recv()将大幅度推高CPU占用率;
任务完成的响应延迟增大了,这会导致整体数据吞吐量的降低。
因为每过一段时间才去轮询一次read操作,而任务可能在两次轮询之间的任意时间完成。
## **多路复用IO(IO multiplexing)**
IO multiplexing也可以说是select/epoll,也称这种IO方式为**事件驱动IO**(event driven IO)。
select/epoll的好处就在于单个process就可以同时处理多个网络连接的IO。它的基本原理就是select/epoll这个function会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程。它的流程如图:
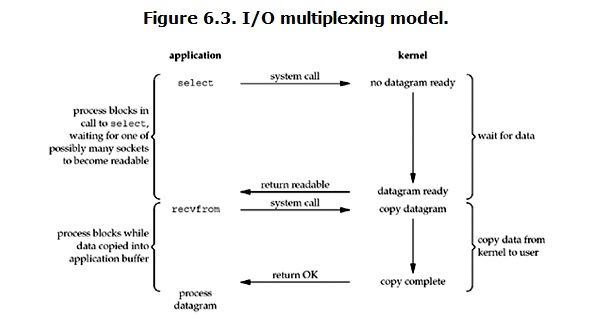
* 数据准备阶段:
当用户进程调用了select,那么整个进程会被block,而同时,kernel会“监视”所有select负责的socket
* 拷贝数据阶段
当任何一个socket中的数据准备好了,select就会返回。这个时候用户进程再调用read操作,将数据从kernel拷贝到用户进程。
* 结论
**结论: select的优势在于可以处理多个连接,不适用于单个连接**
用select的优势在于它可以同时处理多个connection。
**可以使用selectors模块,帮我们默认选择当前平台下最合适的IO多路复用模型**
* **该模型的优点:**
相比其他模型,使用select() 的事件驱动模型只用单线程(进程)执行,占用资源少,不消耗太多 CPU,同时能够为多客户端提供服务。
如果试图建立一个简单的事件驱动的服务器程序,这个模型有一定的参考价值。*
* **该模型的缺点:**
首先select()接口并不是实现“事件驱动”的最好选择。因为当需要探测的句柄值较大时,select()接口本身需要消耗大量时间去轮询各个句柄。
* **几种多路复用IO的实现**
select 轮询方式,windows只支持这种方式 ,linux也支持
poll 轮询方式,linux支持,poll能够监听的对象比select要多
**epoll 回调函数的方式,只有linux ,是一种很高效的方式**
## 异步IO(Asynchronous I/O)
Linux下的asynchronous IO其实用得不多,从内核2.6版本才开始引入,。先看一下它的流程:
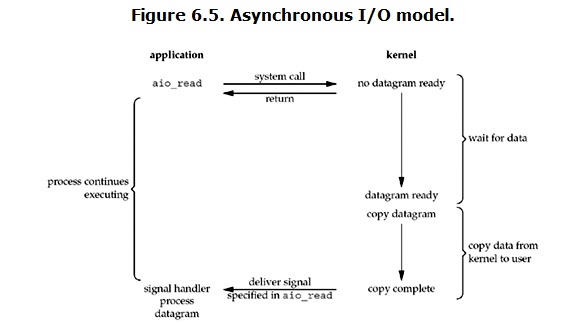
* 数据准备阶段
用户进程发起read操作之后,立刻就可以开始去做其它的事。而另一方面,从kernel的角度,当它受到一个asynchronous read之后,首先它会立刻返回,所以不会对用户进程产生任何block。
* 数据准备阶段
然后,kernel会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都完成之后,kernel会给用户进程发送一个signal,告诉它read操作完成了。
* 优缺点
异步IO应该是最好的IO模型,因为它在两个阶段都没有阻塞,但是python没有办法直接实现异步IO,但是可以使用开源的如`Tornado框架`等
- 基础部分
- 基础知识
- 变量
- 数据类型
- 数字与布尔详解
- 列表详解list
- 字符串详解str
- 元组详解tup
- 字典详解dict
- 集合详解set
- 运算符
- 流程控制与循环
- 字符编码
- 编的小程序
- 三级菜单
- 斐波那契数列
- 汉诺塔
- 文件操作
- 函数相关
- 函数基础知识
- 函数进阶知识
- lambda与map-filter-reduce
- 装饰器知识
- 生成器和迭代器
- 琢磨的小技巧
- 通过operator函数将字符串转换回运算符
- 目录规范
- 异常处理
- 常用模块
- 模块和包相关概念
- 绝对导入&相对导入
- pip使用第三方源
- time&datetime模块
- random随机数模块
- os 系统交互模块
- sys系统模块
- shutil复制&打包模块
- json&pickle&shelve模块
- xml序列化模块
- configparser配置模块
- hashlib哈希模块
- subprocess命令模块
- 日志logging模块基础
- 日志logging模块进阶
- 日志重复输出问题
- re正则表达式模块
- struct字节处理模块
- abc抽象类与多态模块
- requests与urllib网络访问模块
- 参数控制模块1-optparse-过时
- 参数控制模块2-argparse
- pymysql数据库模块
- requests网络请求模块
- 面向对象
- 面向对象相关概念
- 类与对象基础操作
- 继承-派生和组合
- 抽象类与接口
- 多态与鸭子类型
- 封装-隐藏与扩展性
- 绑定方法与非绑定方法
- 反射-字符串映射属性
- 类相关内置方法
- 元类自定义及单例模式
- 面向对象的软件开发
- 网络-并发编程
- 网络编程SOCKET
- socket简介和入门
- socket代码实例
- 粘包及粘包解决办法
- 基于UDP协议的socket
- 文件传输程序实战
- socketserver并发模块
- 多进程multiprocessing模块
- 进程理论知识
- 多进程与守护进程
- 锁-信号量-事件
- 队列与生产消费模型
- 进程池Pool
- 多线程threading模块
- 进程理论和GIL锁
- 死锁与递归锁
- 多线程与守护线程
- 定时器-条件-队列
- 线程池与进程池(新方法)
- 协程与IO模型
- 协程理论知识
- gevent与greenlet模块
- 5种网络IO模型
- 非阻塞与多路复用IO实现
- 带着目标学python
- Pycharm基本使用
- 爬虫
- 案例-爬mzitu美女
- 案例-爬小说
- beautifulsoup解析模块
- etree中的xpath解析模块
- 反爬对抗-普通验证码
- 反爬对抗-session登录
- 反爬对抗-代理池
- 爬虫技巧-线程池
- 爬虫对抗-图片懒加载
- selenium浏览器模拟