
由于自动刷新流程每秒会创建一个新的段 ,这样会导致短时间内的段数量暴增。而段数目太多会带来较大的麻烦。 每一个段都会消耗文件句柄、内存和 cpu 运行周期。更重要的是,每个搜索请求都必须轮流检查每个段;所以段越多,搜索也就越慢。
<br/>
Elasticsearch 通过在后台进行段合并来解决这个问题。小的段被合并到大的段,然后这些大的段再被合并到更大的段。
<br/>
段合并的时候会将那些旧的已删除文档从文件系统中清除。被删除的文档(或被更新文档的旧版本)不会被拷贝到新的大段中。
<br/>
启动段合并不需要你做任何事,进行索引和搜索时会自动进行:
1. 当索引的时候,刷新(refresh)操作会创建新的段并将段打开以供搜索使用。
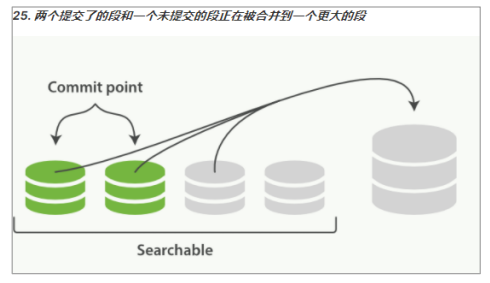
2. 合并进程选择一小部分大小相似的段,并且在后台将它们合并到更大的段中。这并不会中断索引和搜索。
:-: 
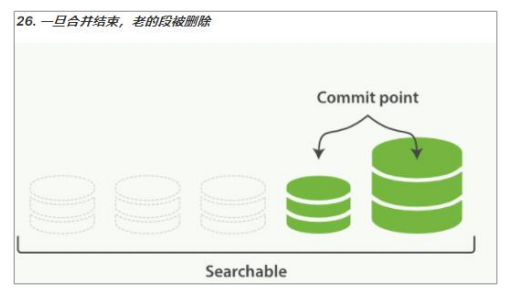
3. 一旦合并结束,老的段被删除。
* 新的段被刷新(flush)到了磁盘。 写入一个包含新段且排除旧的和较小的段的新提交点。
* 新的段被打开用来搜索。
* 老的段被删除。
:-: 
<br/>
合并大的段需要消耗大量的 I/O 和 CPU 资源,如果任其发展会影响搜索性能。Elasticsearch在默认情况下会对合并流程进行资源限制,所以搜索仍然 有足够的资源很好地执行。
- Elasticsearch是什么
- 全文搜索引擎
- Elasticsearch与Solr
- 数据结构
- 安装Elasticsearch
- Linux单机安装
- Windows单机安装
- 安装Kibana
- Linux安装
- Windows安装
- es基本语句
- 索引操作
- 文档操作
- 映射操作
- 高级查询
- es-JavaAPI
- maven依赖
- 索引操作
- 文档操作
- 高级查询
- es集群搭建
- Linux集群搭建
- Windows集群搭建
- 核心概念
- 索引(Index)
- 类型(Type)
- 文档(Document)
- 字段(Field)
- 映射(Mapping)
- 分片(Shards)
- 副本(Replicas)
- 分配(Allocation)
- 系统架构
- 分布式集群
- 单节点集群
- 故障转移
- 水平扩容
- 应对故障
- 路由计算
- 分片控制
- 写流程
- 读流程
- 更新流程
- 多文档操作流程
- 分片原理
- 倒排索引
- 文档搜索
- 动态更新索引
- 近实时搜索
- 持久化变更
- 段合并
- 文档分析
- 内置分析器
- 分析器使用场景
- 测试分析器
- 指定分析器
- 自定义分析器
- 文档处理
- 文档冲突
- 乐观并发控制
- 外部系统版本控制
- es优化
- 硬件选择
- 分片策略
- 合理设置分片数
- 推迟分片分配
- 路由选择
- 写入速度优化
- 批量数据提交
- 优化存储设备
- 合理使用合并
- 减少Refresh的次数
- 加大Flush设置
- 减少副本的数量
- 内存设置
- 重要配置
- es常见问题
- 为什么要使用Elasticsearch
- master选举流程
- 集群脑裂问题
- 索引文档流程
- 更新和删除文档流程
- 搜索流程
- ES部署在Linux时的优化方法
- GC方面ES需要注意的点
- ES对大数据量的聚合实现
- 并发时保证读写一致性
- 字典树
- ES的倒排索引
- Spring Data Elasticsearch
- 环境搭建
- 索引操作
- 文档操作