
# Linux虚拟文件系统
虚拟文件系统 VFS,使得Linux“一切皆文件”的哲学得以实现。虚拟文件系统位于顶层应用软件和底层具体IO设备的中间一层。
:-: 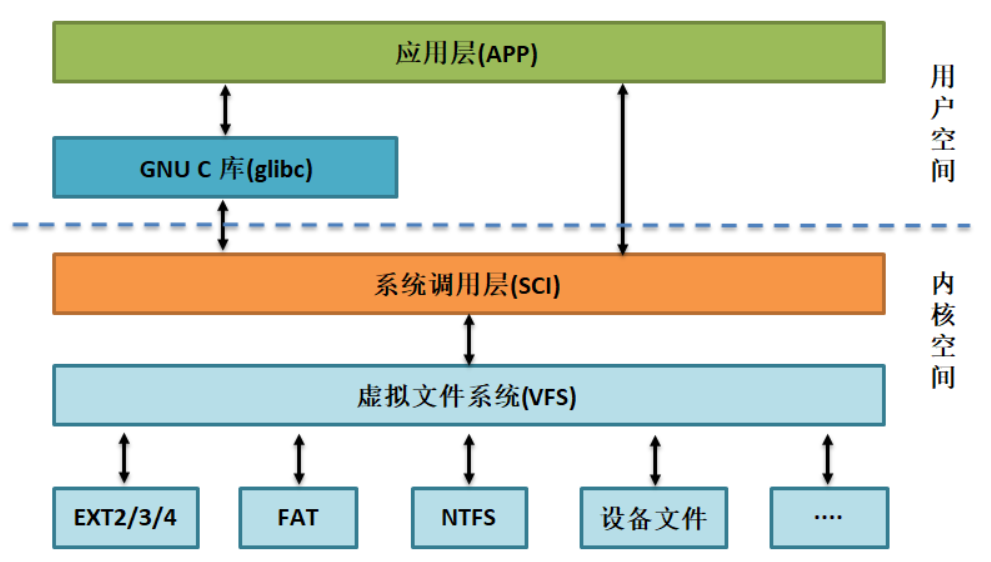
虚拟文件系统是抽象的一层,对用户提供了统一的访问不同文件系统的接口。其使用面向对象的方式抽象出了四种类型的数据结构:
* 超级块对象:代表一个已安装的文件系统,该文件系统才会真正的和IO设备交互。
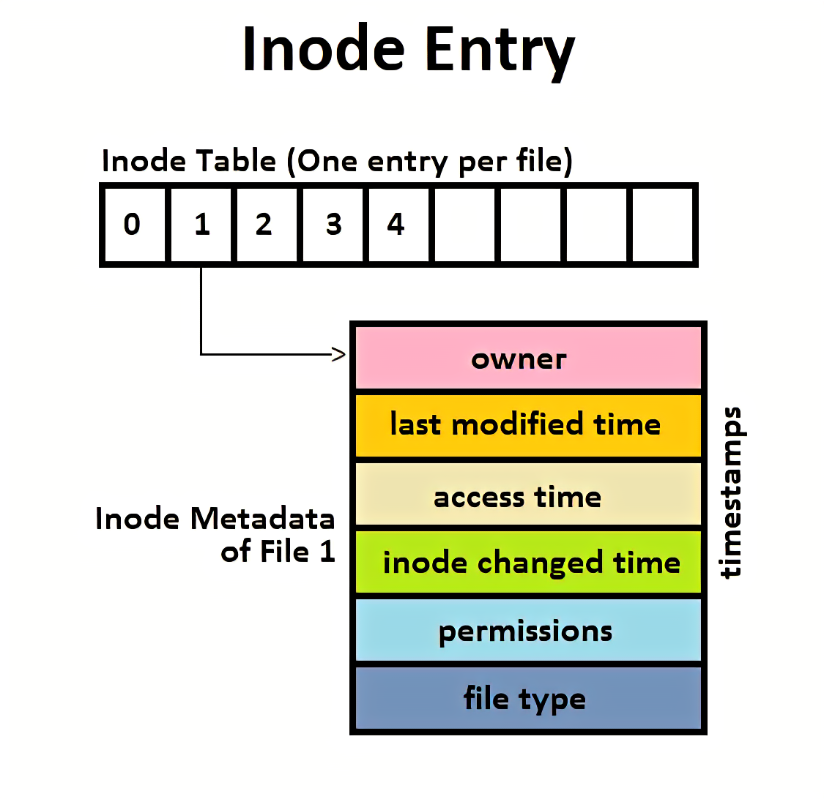
* 索引节点对象 inode:代表具体的文件。其结构可如下
:-: 
* 目录项对象 :代表一个目录项,是文件路径的一个组成部分。存在内存中。
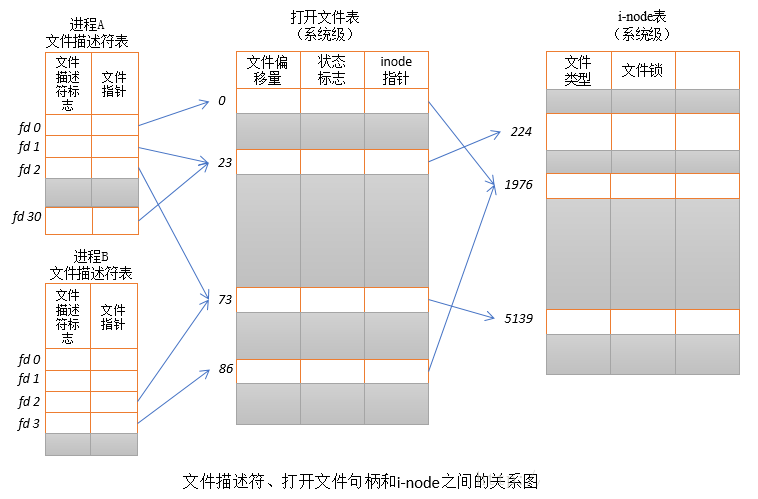
* 文件对象FD:表示进程打开的一个文件,**也称文件描述符**,每个进程的文件描述符相互独立。当两个进程打开同一个文件的时候,文件描述符会维护独立的指针(seek)。
其中文件描述符、文件句柄、inode之间的关系如下:
:-: 
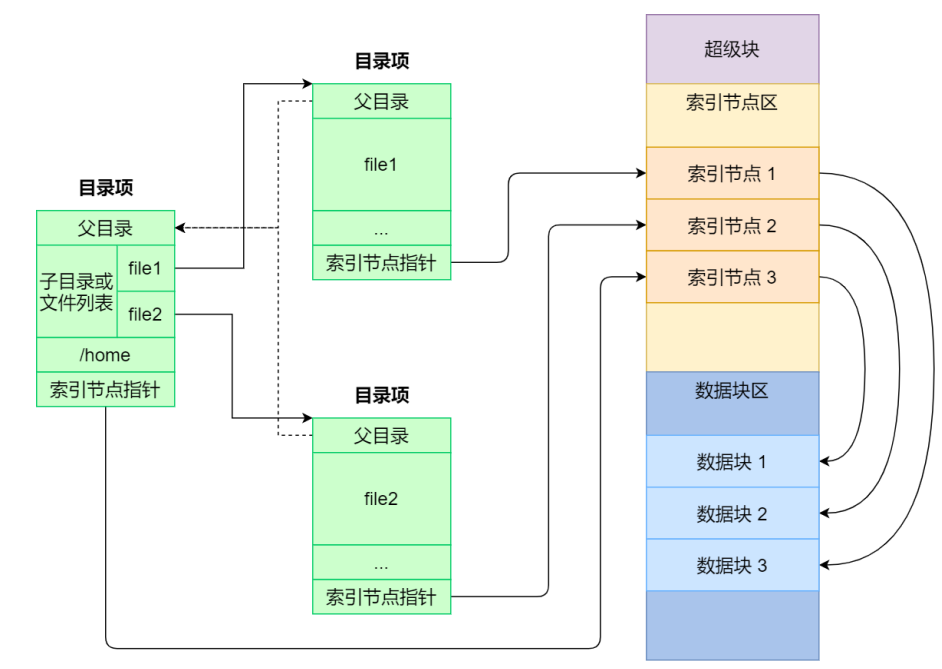
目录项、inode之间的关系(inode和超级快都在磁盘中 ):
:-: 
**Linux系统分区**
~~~bash
df -h
~~~
~~~
分区 大小 使用 可用 使用百分比 挂载目录
udev 1.9G 0 1.9G 0% /dev
tmpfs 376M 4.7M 372M 2% /run
/dev/vda1 79G 6.4G 69G 9% /
tmpfs 1.9G 7.7M 1.9G 1% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
tmpfs 1.9G 0 1.9G 0% /sys/fs/cgroup
tmpfs 376M 0 376M 0% /run/user/0
~~~
具体的IO设备在进行挂载的时候会先挂载root目录,接着才会挂载其他的目录。与挂载相关的操作如下:
~~~
umount 分区 # 取消该分区与该目录的挂载
mount 分区 目录 # 将该分区与该目录进行挂载
~~~
**文件类型**
Linux将系统中的一切都抽象成文件,可以具体区分出多种不同类型的文件。
:-: 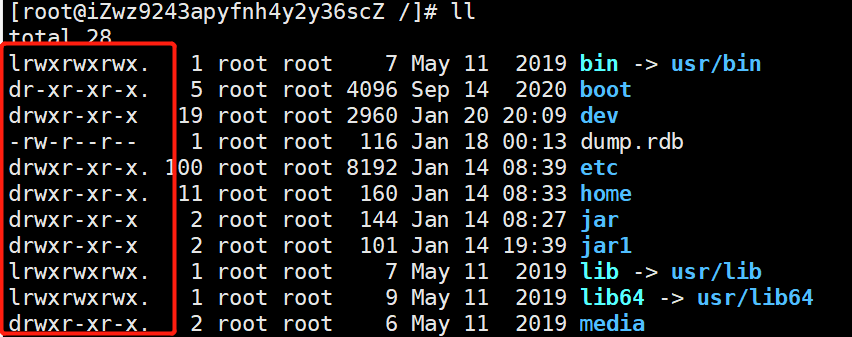
使用`ll`命令第一个字段的第一列可以查看文件的类型:
-:表示普通文件。
d:表示目录。
b:表示块设备,例如硬盘,可以移动字节位置。
c:表示字符设备,例如键盘。
s:表示socket。
p:表示pipeline,管道。
l:链接,可以分为软硬链接,上图的数字就表示被硬链接引用的次数。
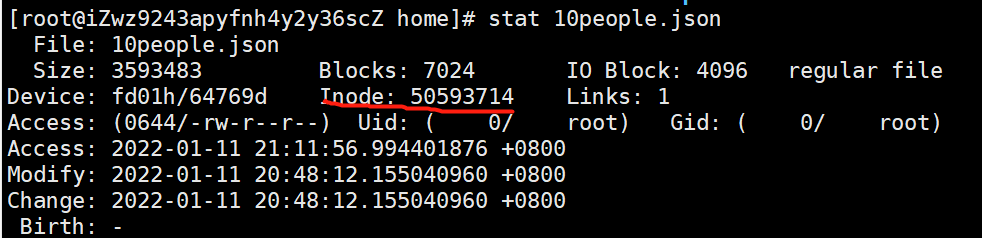
使用命令
~~~
stat 文件名
~~~
可以查看文件的元数据信息
:-: 
Linux系统有个/proc目录,里面存放着打开进程的信息,每个数字文件夹标识着一个进程pid号。Linux也将进程也映射成一个文件,同时在任何的进程中都有文件描述符为:
- 0:标准输入。
- 1:标准输出。
- 2:报错输出。
采用如下命令可以查看一个进程打开的文件
~~~
lsof -p pid
~~~
输出结果的一部分如下:
~~~
bash 162968 root 0u CHR 136,0 0t0 3 /dev/pts/0
bash 162968 root 1u CHR 136,0 0t0 3 /dev/pts/0
bash 162968 root 2u CHR 136,0 0t0 3 /dev/pts/0
~~~
例如使用如下命令可以用标准输入将内容输入到文件中
~~~
ls ./ 1> ls.out
~~~
可以将当前的ls命令的输出内容输出到ls.out文件中。
又例如在运行jar包的时候
~~~
nohup java -jar *.jar >server.log 2>&1
~~~
即表示将输出重定向到server.log文件中,同时将报错输出重定向到标准输出文件描述符1中。这样报错输出也会输出到server.log中。
**管道**
管道就是在命令行中用符号【|】表示,例如:
~~~
ps -ef | grep java
~~~
表示将左边的命令的输出作为右边命令的输入。
管道是进程间通信的一种方式,并且是单向通信的。可以分为**匿名管道**和**命名管道**,上面的 “|” 就是匿名管道,命令管道可以使用命令`mkfifo`创建。
~~~
[root@iZwz9243apyfnh4y2y36scZ test]# mkfifo mypipe
[root@iZwz9243apyfnh4y2y36scZ test]# ll
total 0
prw-r--r-- 1 root root 0 Feb 24 21:11 mypipe
~~~
p就是表示命名管道类型的文件。
往命令管道存入的数据之后被读出之后程序才会退出,不然会一直阻塞住。注意**管道就是内核中的一串缓存数据**。
原理:
当我们在shell使用匿名管道时,会fork两个子进程,其父进程是shell这个客户端,并复制命令的文件文件描述符,这样文件描述符就可以通过管道进行数据交互了。
其他:
【$$】和【$BASHPID】都能表示当前进程的PID号,但是$$的优先级要比管道符号的要高。
## pageCache
磁盘高速缓存,pageCache是内核的内存空间中对磁盘读写数据的一块缓存空间,系统内核对磁盘数据的读写会先经过pageCache,然后再从pageCache中复制到用户空间中(直接io的方式不用使用pageCache)。使用pageCache有如下的特点:
1. 跟计算机中大多数的缓存层的作用类似,符合“程序的局部性原理”,可以减少对磁盘的访问。
2. 当pageCache中的数据被修改过后,需要设置成脏页标志,操作系统会根据一定的策略将脏页的数据写回到磁盘中。但是并不一定会立刻写出,所以可能造成数据丢失不能持久化的问题。
3. 当pageCache满的时候会通过LRU算法将某些页写回磁盘。
4. 具备**预读**的功能,能够在一次磁盘读取数据的时候,额外的读取更多的数据(受局部性原理的指导)。
图示pageCache的位置:
:-: 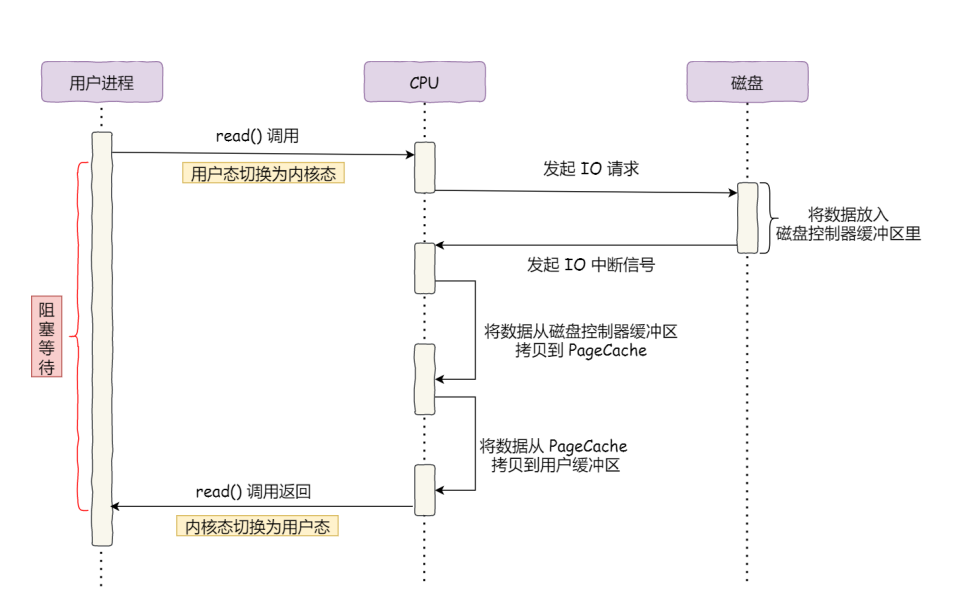
现在都是由DMA将磁盘中的数据放到pageCache中
:-: 
**查看系统脏页大小**
1. 查看系统配置
~~~
sysctl -a | grep dirty
~~~
:-: 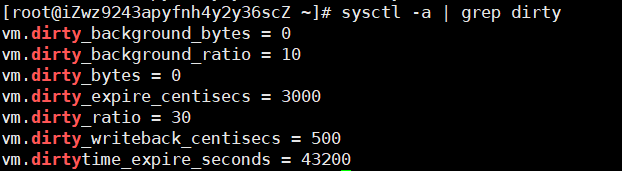
其中:
* vm.dirty_background_ratio:是内存可以填充脏数据的百分比。超过这个比例,这些脏数据稍后会写入磁盘,由后台进程执行,不会阻塞。比如,我有32G内存,那么有3.2G的脏数据可以待着内存里,超过3.2G的话就会有后台进程来清理。
* vm.dirty_ratio:是可以用脏数据填充的绝对最大系统内存量,当系统到达此点时,必须将所有脏数据提交到磁盘,同时所有新的`I/O`块都会被阻塞,直到脏数据被写入磁盘。这通常是长`I/O`卡顿的原因,但这也是保证内存中不会存在过量脏数据的保护机制。
* `vm.dirty_background_bytes`和`vm.dirty_bytes`是另一种指定这些参数的方法。如果设置`_bytes`版本,则`_ratio`版本将变为0,反之亦然。
* vm.dirty_expire_centisecs:指定脏数据能存活的时间。在这里它的值是30秒。当后台进程在运行的时候,他们会检查是否有数据超过这个时限,如果有则会把它异步地写到磁盘中。
* vm.dirty_writeback_centisecs:指定多长时间后台进程会唤醒一次,然后检查是否有缓存需要清理。
**修改系统配置**
~~~
vim /etc/sysctl.conf
~~~
重新生效
~~~
sysctl -p
~~~
2. 查看脏页数据:
~~~
cat /proc/vmstat | egrep "dirty|writeback"
~~~
或者使用`pcstat`查看,
### 安装pcstat
1. 如果没有go环境需要先安装golang环境
官网下载安装包:[Downloads - The Go Programming Language](https://go.dev/dl/),解压
~~~
tar -zxvf goxxx.tar.gz
~~~
2. 添加环境变量
~~~
vim /etc/profile
~~~
~~~
export GO_HOME=go的解压地址/go
export PATH=$PATH:$GO_HOME/bin
# 国内
export GOPROXY=https://goproxy.io
export GO111MODULE=on
~~~
~~~
source /etc/profile
~~~
3. 安装pcstat
官方地址:[tobert/pcsta(github.com)](https://github.com/tobert/pcstat),阅读一下Readmd.md安装即可。
4. 使用
注意`pcstat`命令需要放于环境变量中,这里我放到了go的bin目录下。
:-: 
- 第一章 Java基础
- ThreadLocal
- Java异常体系
- Java集合框架
- List接口及其实现类
- Queue接口及其实现类
- Set接口及其实现类
- Map接口及其实现类
- JDK1.8新特性
- Lambda表达式
- 常用函数式接口
- stream流
- 面试
- 第二章 Java虚拟机
- 第一节、运行时数据区
- 第二节、垃圾回收
- 第三节、类加载机制
- 第四节、类文件与字节码指令
- 第五节、语法糖
- 第六节、运行期优化
- 面试常见问题
- 第三章 并发编程
- 第一节、Java中的线程
- 第二节、Java中的锁
- 第三节、线程池
- 第四节、并发工具类
- AQS
- 第四章 网络编程
- WebSocket协议
- Netty
- Netty入门
- Netty-自定义协议
- 面试题
- IO
- 网络IO模型
- 第五章 操作系统
- IO
- 文件系统的相关概念
- Java几种文件读写方式性能对比
- Socket
- 内存管理
- 进程、线程、协程
- IO模型的演化过程
- 第六章 计算机网络
- 第七章 消息队列
- RabbitMQ
- 第八章 开发框架
- Spring
- Spring事务
- Spring MVC
- Spring Boot
- Mybatis
- Mybatis-Plus
- Shiro
- 第九章 数据库
- Mysql
- Mysql中的索引
- Mysql中的锁
- 面试常见问题
- Mysql中的日志
- InnoDB存储引擎
- 事务
- Redis
- redis的数据类型
- redis数据结构
- Redis主从复制
- 哨兵模式
- 面试题
- Spring Boot整合Lettuce+Redisson实现布隆过滤器
- 集群
- Redis网络IO模型
- 第十章 设计模式
- 设计模式-七大原则
- 设计模式-单例模式
- 设计模式-备忘录模式
- 设计模式-原型模式
- 设计模式-责任链模式
- 设计模式-过滤模式
- 设计模式-观察者模式
- 设计模式-工厂方法模式
- 设计模式-抽象工厂模式
- 设计模式-代理模式
- 第十一章 后端开发常用工具、库
- Docker
- Docker安装Mysql
- 第十二章 中间件
- ZooKeeper