
# Netty入门
## 一、Netty概述
> Netty 是一个异步的、基于事件驱动的网络应用框架,用于快速开发可维护、高性能的网络服务器和客户端。《官网》
使用Netty的框架有:
* RocketMQ - 阿里巴巴开源的消息队列。
* gRPC - rpc 框架。
* Dubbo - rpc 框架。
* Zookeeper - 分布式协调框架。
* Spring 5.x - flux api 完全抛弃了 tomcat ,使用 netty 作为服务器端。
Netty框架与Java的nio相比:
* NIO工作量大,bug多。
* NIO需要自己构建协议。
* NIO需要自己解决TCP的传输问题。
* NIO的epoll空轮询可能会导致CPU100%的问题。
* Netty对NIO的API进行了增强,例如将ThreadLocal增强成FastThreadLocal,将ByteBuffer增强成ByteBuf。
## 二、使用
1. 引入依赖
~~~
<dependency>
<groupId>io.netty</groupId>
<artifactId>netty-all</artifactId>
<version>4.1.39.Final</version>
</dependency>
~~~
2. 服务端代码
~~~
new ServerBootstrap()
.group(new NioEventLoopGroup())
.channel(NioServerSocketChannel.class)
.childHandler(new ChannelInitializer<NioSocketChannel>() {
protected void initChannel(NioSocketChannel ch) {
ch.pipeline().addLast(new StringDecoder());
ch.pipeline().addLast(new SimpleChannelInboundHandler<String>() {
@Override
protected void channelRead0(ChannelHandlerContext ctx, String msg) {
System.out.println(msg);
}
});
}
})
.bind(8080);
~~~
- ServerBootstrap 服务端的启动类。
- NioEventLoopGroup 类似于线程池+Selector。
- childHandler 用于处理SocketChannel的内容,可以理解成Server和Client是父子关系。
- pipeline 管道,可以理解成每个Handler都是一个工序,管道由这些工序组成。
3. 客户端代码
~~~
new Bootstrap()
.group(new NioEventLoopGroup())
.channel(NioSocketChannel.class)
.handler(new ChannelInitializer<Channel>() {
@Override
protected void initChannel(Channel ch) {
ch.pipeline().addLast(new StringEncoder());
}
})
.connect("127.0.0.1", 8080)
.sync()
.channel()
.writeAndFlush(new Date() + ": hello world!");
~~~
- Bootstrap 客户端启动类。
- sync 表示同步连接建立后才能调用writeAndFlush往服务端输出内容。
**注意:**
在客户端和服务端中接受数据和发送数据都会去调用Handler处理器的方法进行处理。可以将channel理解为数据的通道,pipeline理解为处理数据的流水线,而Handler就是该流水线中的每道工序。
而eventLoop可以理解为处理数据的工人,由单线程的线程池组成。
## 三、组件
### 3.1 EventLoop
EventLoop表示事件循环对象,对应着一个线程,其本质是一个单线程的线程池,同时里面维护了一个Selector。通过里面的run方法源源不断的处理Channel上的IO事件。
EventLoop继承自OrderedEventExecutor和EventLoopGroup,里面有个parent方法用来判断属于哪个EventLoopGroup。
### 3.2 EventLoopGroup
EventLoopGroup 是一组 EventLoop,Channel 一般会调用 EventLoopGroup 的 register 方法来绑定其中一个 EventLoop,后续这个 Channel 上的 io 事件都由此 EventLoop 来处理(**这样做可以保证该channel上 io 事件处理时的线程安全**)。
:-: 
EventLoopGroup有多个实现类,常用的有:
~~~
MultithreadEventLoopGroup
NioEventLoopGroup
DefaultEventLoopGroup 只能执行普通任务和定时任务不能执行IO任务
~~~
实现类需要实现如下方法:
* 实现了 Iterable 接口提供遍历 EventLoop。
* 实现 next 方法获取集合中下一个 EventLoop。
NioEventLoopGroup的默认线程数由*DEFAULT\_EVENT\_LOOP\_THREADS*这个参数配置:
:-: 
默认为CPU核心数的两倍。
NioEventLoopGroup可以设置一个Boss EventLoop用于处理accept事件,多个Worker EventLoop用于处理SocketChannel IO 读写事件。两个Worker会轮流处理事件,同时是绑定channel进行处理。
channel交由特点的channel处理的关键代码如下:
~~~
static void invokeChannelRead(final AbstractChannelHandlerContext next, Object msg) {
final Object m = next.pipeline.touch(ObjectUtil.checkNotNull(msg, "msg"), next);
// 下一个 handler 的事件循环是否与当前的事件循环是同一个线程
EventExecutor executor = next.executor();
// 是,直接调用
if (executor.inEventLoop()) { // 判断当前handler中的线程是否和executor是同一个线程
next.invokeChannelRead(m);
}
// 不是,将要执行的代码作为任务提交给下一个事件循环处理(换人)
else {
executor.execute(new Runnable() { // 下一个handler的线程
@Override
public void run() {
next.invokeChannelRead(m);
}
});
}
}
~~~
如果两个Handler绑定的是同个线程,则直接执行,否则的话交由下一个eventLoop判断执行。
NioEventLoop也可以用于执行普通任务和定时任务:
~~~
NioEventLoopGroup nioWorkers = new NioEventLoopGroup(2);
log.debug("server start...");
// 让线程启动起来
Thread.sleep(2000);
nioWorkers.execute(()->{
log.debug("normal task...");
});
nioWorkers.scheduleAtFixedRate(() -> {
log.debug("running...");
}, 0, 1, TimeUnit.SECONDS);
~~~
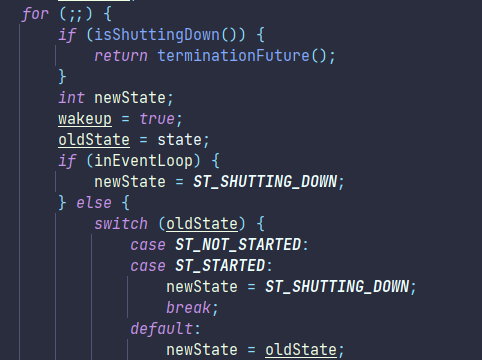
**关闭EventLoopGroup**
优雅关闭 `shutdownGracefully` 方法。该方法会首先切换 `EventLoopGroup` 到关闭状态从而拒绝新的任务的加入,然后在任务队列的任务都处理完成后,停止线程的运行。从而确保整体应用是在正常有序的状态下退出的。
默认是2秒后关闭,15秒后超时关闭,由如下两个参数限定:
:-: 
shutdownGracefully方法在关闭的时候会进行空循环关闭
:-: 
### 3.3 Channel
可以理解为数据流通道,其主要的API有:
1. close():关闭Channel。
2. closeFuture():处理Channel的关闭。
3. pipeline():往流水线中添加处理器。
4. write():将输入写入缓冲区中,不一定会立刻刷出。
5. writeAndFlush():写入并立刻将数据刷出。
**ChannelFuture**
注意带有**Future、promise**名称的都是和异步方法一起使用的。
~~~
ChannelFuture channelFuture = new Bootstrap()
.group(new NioEventLoopGroup())
.channel(NioSocketChannel.class)
.handler(new ChannelInitializer<Channel>() {
@Override
protected void initChannel(Channel ch) {
ch.pipeline().addLast(new StringEncoder());
}
})
// 异步非阻塞,由main线程发起调用,真正执行 connect 的是nio线程
.connect("127.0.0.1", 8080); // 1
channelFuture.sync().channel().writeAndFlush(new Date() + ": hello world!");
~~~
由于ChannelFuture本身是异步非阻塞的,所以才需要调用sync方法等待连接后获取channel对象。也可以使用回调的方法获取连接:
~~~
// addListener(回调对象)也可以异步处理结果,nio线程连接建立之后,就会调用operationComplete方法,处理channel的是nio线程
channelFuture.addListener((ChannelFutureListener) future -> {
System.out.println(future.channel()); // 2
});
~~~
**CloseFuture**
调用closeFuture方法可以获取CloseFuture对象,可用于同步或者异步处理关闭。
~~~
// 获取 CloseFuture 对象, 1) 同步处理关闭, 2) 异步处理关闭,回调函出,nio线程处理
ChannelFuture closeFuture = channel.closeFuture();
/*log.debug("waiting close...");
closeFuture.sync();
log.debug("处理关闭之后的操作");*/
closeFuture.addListener(new ChannelFutureListener() {
@Override
public void operationComplete(ChannelFuture future) throws Exception {
log.debug("处理关闭之后的操作");
// gracefully 优雅的
group.shutdownGracefully();
}
});
~~~
总的来说,Netty使用异步操作,用不同的线程来发起连接建立,另外一个线程来真正的建立连接,这样可以提高效率。原因如下:
* 单线程没法异步提高效率,必须配合多线程、多核 cpu 才能发挥异步的优势,类似于cpu的**流水线指令**。
* 异步**并没有缩短响应时间**,反而有所增加,提高的是吞吐量,即单位时间的处理量。
* 合理进行任务拆分,也是利用异步的关键。
### 3.4 Future & Promise
Netty的Future继承自JDK的Future,而Promise又继承自Netty的Future,三者有如下的区别:
* jdk Future **只能**同步等待任务结束(或成功、或失败)才能得到结果,通过get方法来进行同步的阻塞。
* netty Future 可以同步等待任务结束得到结果(get方法同步阻塞),也可以异步方式(addListener)得到结果,但都是要等任务结束才能得到结果。
* netty Promise 不仅有 netty Future 的功能,而且脱离了任务独立存在,只作为两个线程间传递结果的容器。
三者的使用方式如下:
~~~
public class TestFuture {
// 测试JDK Future
public void testJKDFuture() {
ExecutorService service = Executors.newFixedThreadPool(2);
Future<Integer> future = service.submit(new Callable<Integer>() {
@Override
public Integer call() throws Exception {
log.debug("执行计算");
Thread.sleep(1000);
return 50;
}
});
// 主线程通过future来获取结果
log.debug("等待结果");
// get方法会阻塞获取
log.debug("结果是 {}", future.get());
}
// 测试 netty Future
public void testNettyFuture() {
NioEventLoopGroup group = new NioEventLoopGroup();
EventLoop eventLoop = group.next();
eventLoop.submit(new Callable<Integer>() {
@Override
public Integer call() throws Exception {
log.debug("执行计算");
Thread.sleep(1000);
return 70;
}
});
// 同步等待
log.debug("等待结果...");
log.debug("结果是{}", future.get());
// 异步等待
future.addListener(new GenericFutureListener<Future<? super Integer>>() {
@Override
public void operationComplete(Future<? super Integer> future) throws Exception {
log.debug("接收结果{}", future.getNow());
}
})
}
// promise
public void testNettyPromise() {
DefaultEventLoop eventExecutors = new DefaultEventLoop();
DefaultPromise<Integer> promise = new DefaultPromise<>(eventExecutors);
eventExecutors.execute(()->{
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
log.debug("set success, {}",10);
// 手动装入结果
promise.setSuccess(10);
});
log.debug("start...");
log.debug("{}",promise.getNow()); // 还没有结果
// get方法是同步阻塞的
log.debug("{}",promise.get());
}
}
~~~
Future和Promise都可以看成一个容器,用于不同线程之间交互数据,例如在线程池中执行完后的结果在主线程中被获取。而使用Promise则可以更加灵活的处理数据,不仅仅是通过返回值来获取。
### 3.5 Pipeline & Handler
ChannelHandler 用来处理 Channel 上的各种事件,分为入站、出站两种。所有 ChannelHandler 被连成一串,就是 Pipeline、
* 入站处理器通常是 ChannelInboundHandlerAdapter 的子类,主要**用来读取客户端数据,写回结果**。
* 出站处理器通常是 ChannelOutboundHandlerAdapter 的子类,主要对**写回结果进行加工**。
打个比喻,每个 Channel 是一个产品的加工车间,Pipeline 是车间中的流水线,ChannelHandler 就是流水线上的各道工序,而 ByteBuf 是原材料,经过很多工序的加工:先经过一道道入站工序,再经过一道道出站工序最终变成产品。
Netty会对每个pipeline添加上header handler和tail handler,形成一个双向链表。出入站工序处理顺序的举例:
~~~java
new ServerBootstrap()
.group(new NioEventLoopGroup())
.channel(NioServerSocketChannel.class)
.childHandler(new ChannelInitializer<NioSocketChannel>() {
protected void initChannel(NioSocketChannel ch) {
ch.pipeline().addLast(new ChannelInboundHandlerAdapter(){
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) {
System.out.println(1);
ctx.fireChannelRead(msg); // 1
}
});
ch.pipeline().addLast(new ChannelInboundHandlerAdapter(){
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) {
System.out.println(2);
ctx.fireChannelRead(msg); // 2
}
});
ch.pipeline().addLast(new ChannelInboundHandlerAdapter(){
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) {
System.out.println(3);
ctx.channel().write(msg); // 3
}
});
// 出站处理器需要有写入操作才会触发,出站是按照加入pipeline的顺序相反。
ch.pipeline().addLast(new ChannelOutboundHandlerAdapter(){
@Override
public void write(ChannelHandlerContext ctx, Object msg,
ChannelPromise promise) {
System.out.println(4);
ctx.write(msg, promise); // 4
}
});
ch.pipeline().addLast(new ChannelOutboundHandlerAdapter(){
@Override
public void write(ChannelHandlerContext ctx, Object msg,
ChannelPromise promise) {
System.out.println(5);
ctx.write(msg, promise); // 5
}
});
ch.pipeline().addLast(new ChannelOutboundHandlerAdapter(){
@Override
public void write(ChannelHandlerContext ctx, Object msg,
ChannelPromise promise) {
System.out.println(6);
ctx.write(msg, promise); // 6
}
});
}
})
.bind(8080);
~~~
总共添加了三道入站处理器和三道出站处理器工序,对于每个入站处理器,需要在处理完数据最后调用**ChannelHandlerContext::fireChannelRead(msg)**,来将msg交由给下一道入站处理器处理。对于出站处理器,需要由写出数据的时候才会执行,同时是按照添加的顺序逆序执行的,调用ChannelHandlerContext::channel()::write(msg)会将处理工序指向到pipeline的tail节点,之后向前处理出站处理器。调用ChannelHandlerContext::write()会将工序指向当前节点的上一个节点。完整的结构如图所示:
:-: 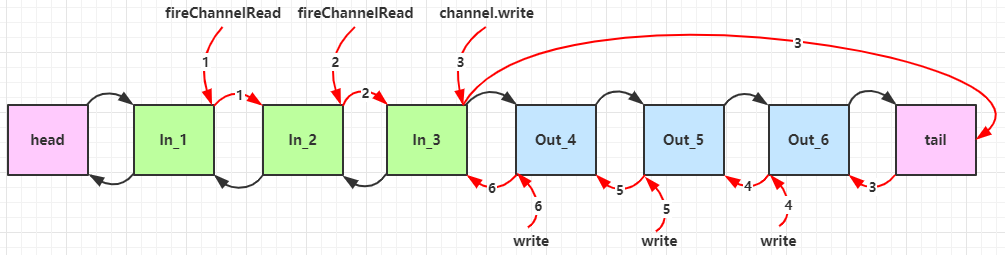
因此输出结果为:
~~~
1
2
3
6
5
4
~~~
可以在pipeline工序中通过msg传递上一个工序处理的msg结果, 跟生活中的流水线一样。为了让数据能够传递,在每个handler中必须调用super.channelRead(ctx, msg)或者是ctx.fireChannelRead(msg);
对于写出数据的方法有如下两个类似的方式
~~~
ctx.writeAndFlush(ctx.alloc().bytebuff()); // 从当前handler往前找出站处理器
ch.writeAndFlush(ctx.alloc().bytebuff()); // 从tail往前找出站处理器
~~~
**备注:使用了责任链模式。**
### 3.6 ByteBuf
与nio包的ByteBuffer类似,都是对字节数据的封装,可以看成是ByteBuffer的增强。
#### 3.6.1. 创建方式
~~~
ByteBuf buffer = ByteBufAllocator.DEFAULT.buffer(10);
~~~
从直接内存中一个大小为10字节的ByteBuf,可以自动扩容(ByteBuffer是不能自动扩容的),默认为256字节。
展示ByteBuf的内容,使用自定义的log方法:
~~~
private static void log(ByteBuf buffer) {
int length = buffer.readableBytes();
int rows = length / 16 + (length % 15 == 0 ? 0 : 1) + 4;
StringBuilder buf = new StringBuilder(rows * 80 * 2)
.append("read index:").append(buffer.readerIndex())
.append(" write index:").append(buffer.writerIndex())
.append(" capacity:").append(buffer.capacity())
.append(NEWLINE);
appendPrettyHexDump(buf, buffer);
System.out.println(buf.toString());
}
~~~
输出如下:
~~~
read index:0 write index:0 capacity:10
~~~
这种创建方式在windows系统会默认开启池化和分配直接内存。
**池化技术**:类似于线程池可以重用线程,Netty开启池化技术也能重用ByteBuf。其优点有:
* 没有池化,则每次都得创建新的 ByteBuf 实例,这个操作对直接内存代价昂贵,就算是堆内存,也会增加 GC 压力。
* 有了池化,则可以重用池中 ByteBuf 实例,并且采用了与 jemalloc 类似的内存分配算法提升分配效率。
* 高并发时,池化功能更节约内存,减少内存溢出的可能。
池化可以通过如下参数开启:
~~~
-Dio.netty.allocator.type={unpooled|pooled} # unpooled没有开启,pooled表示开启
~~~
4.1 以后,非 Android 平台**默认启用池化实现**,Android 平台启用非池化实现。
**其他分配方式**
~~~
ByteBuf buffer = ByteBufAllocator.DEFAULT.heapBuffer(10); // 分配JVM堆内存
ByteBuf buffer = ByteBufAllocator.DEFAULT.directBuffer(10); // 分配直接内存
~~~
* 直接内存创建和销毁的代价昂贵,但读写性能高(少一次内存复制,系统内存和JDK的内存会进行映射),适合配合池化功能一起用。
* 直接内存对 GC 压力小,因为这部分内存不受 JVM 垃圾回收的管理,但也要注意及时主动释放。
:-: 
#### 3.6.2.组成与API
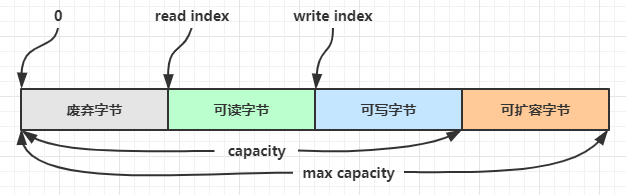
ByteBuf包含四个部分,由读写指针来维护读写操作。
:-: 
**写入操作**
ByteBuf的写入操作的API有write和set开头的组成,其中write开头的会修改写指针,set开头的不会改变写指针的位置。
**扩容规则**
当容量不够用的时候ByteBuf会自动扩容,扩容规则如下:
* 如何写入后数据大小未超过 512字节,则选择下一个 16 的整数倍,例如写入后大小为 12 ,则扩容后 capacity 是 16。
* 如果写入后数据大小超过 512字节,则选择下一个 2^n,例如写入后大小为 513,则扩容后 capacity 是 2^10=1024(2^9=512 已经不够了)。
* 扩容不能超过 max capacity (整数的最大值)会报错。
**读取**
read开头的方法,指针会往前移动,可以通过mark或者reset设置重复读取。另外一系列get开头的方法不会移动读指针。
**释放内存**
ByteBuf尽量自己手动释放,ByteBuf采用的是“引用计数”(继承ReferencedCounted接口)的方式,当计数为0的时候就会被清理掉。其中调用**release**方法可以让引用计数+1,调用retain可以让引用计数-1。不同的ByteBuf的释放机制不尽相同,在使用的过程中需要让最后处理的Handler进行手动释放ByteBuf。
同时head handler和tail handler也会保证流到这里的ByteBuf会被释放掉。
**复制**
调用copy会进行深度复制操作,对新ByteBuf的操作不会影响原来的ByteBuf。
ByteBuf和ByteBuffer相比的优点:
1. 使用池化技术,重用ByteBuf,提高内存的使用。
2. ByteBuf使用读写指针,ByteBuffer只使用一个指针,需要通过filp,clear,compact不断调整指针的状态。
3. 会自动扩容。
4. 支持链式调用,使用更流畅。
5. 很多地方体现零拷贝,例如 slice、duplicate、CompositeByteBuf,减少内存复制,提高性能。
- 第一章 Java基础
- ThreadLocal
- Java异常体系
- Java集合框架
- List接口及其实现类
- Queue接口及其实现类
- Set接口及其实现类
- Map接口及其实现类
- JDK1.8新特性
- Lambda表达式
- 常用函数式接口
- stream流
- 面试
- 第二章 Java虚拟机
- 第一节、运行时数据区
- 第二节、垃圾回收
- 第三节、类加载机制
- 第四节、类文件与字节码指令
- 第五节、语法糖
- 第六节、运行期优化
- 面试常见问题
- 第三章 并发编程
- 第一节、Java中的线程
- 第二节、Java中的锁
- 第三节、线程池
- 第四节、并发工具类
- AQS
- 第四章 网络编程
- WebSocket协议
- Netty
- Netty入门
- Netty-自定义协议
- 面试题
- IO
- 网络IO模型
- 第五章 操作系统
- IO
- 文件系统的相关概念
- Java几种文件读写方式性能对比
- Socket
- 内存管理
- 进程、线程、协程
- IO模型的演化过程
- 第六章 计算机网络
- 第七章 消息队列
- RabbitMQ
- 第八章 开发框架
- Spring
- Spring事务
- Spring MVC
- Spring Boot
- Mybatis
- Mybatis-Plus
- Shiro
- 第九章 数据库
- Mysql
- Mysql中的索引
- Mysql中的锁
- 面试常见问题
- Mysql中的日志
- InnoDB存储引擎
- 事务
- Redis
- redis的数据类型
- redis数据结构
- Redis主从复制
- 哨兵模式
- 面试题
- Spring Boot整合Lettuce+Redisson实现布隆过滤器
- 集群
- Redis网络IO模型
- 第十章 设计模式
- 设计模式-七大原则
- 设计模式-单例模式
- 设计模式-备忘录模式
- 设计模式-原型模式
- 设计模式-责任链模式
- 设计模式-过滤模式
- 设计模式-观察者模式
- 设计模式-工厂方法模式
- 设计模式-抽象工厂模式
- 设计模式-代理模式
- 第十一章 后端开发常用工具、库
- Docker
- Docker安装Mysql
- 第十二章 中间件
- ZooKeeper