
## 体系结构
InnoDB的体系结构:
:-: 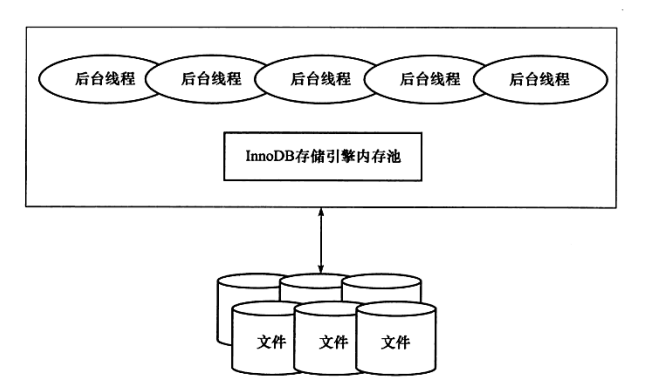
后台线程可以分为:
* Master Thread:负责将缓冲池的数据异步刷新到磁盘,保证数据一致性。
* IO Thread:使用AIO来处理IO请求,一般情况下有4个读线程和4个写线程。
:-: 
* Purge Thread:回收已经使用并分配的undo页。
* page Cleaner Thread:刷新之前版本中的脏页数据。
**缓冲区**
InnoDB的内存结构可以分为如下几个部分:
* 缓冲池:多存放表和索引数据。
* 更改缓冲区:保存insert、delete、update等更改操作的缓冲区。
* 自适应哈希索引:存放在程序运行中生成的自适应哈希索引结构。
* 日志缓冲区:日志缓冲区的内容会定期刷新到磁盘。
InnoDB存储引擎内存池的缓冲区可以起到和cache类似的作用。查看当前系统InnoDB缓冲区的大小:
:-: 
默认为128M
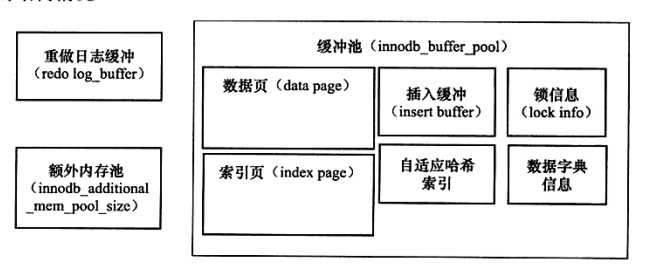
缓冲池中缓存的数据页类型有:索引页、数据页、undo页、插入缓冲(insert buffer)、自适应哈希索引(adaptive hash index)、InnoDB存储的锁信息(lock info)、数据字典信息(data dictionary)。其内部结构如下:
:-: 
查看缓冲池的数量(会将每个页根据哈希值平均分配到不同的缓冲池实例中)
:-: 
**如何管理内存**
InnoDB使用LRU算法来进行内存缓存页的管理。在InnoDB存储引擎中,缓冲池页的大小默认为16KB,与普通的LRU算法不同的是,LRU列表还加入Midpoint位置。对于读取到新的页,不再是直接放到最前面的位置,而是放在midpoint的位置,这个位置在LRU列表长度的5/8处。InnoDB将midpoint之前的列表称为new(活跃的)列表,将midpoint之后的列表称为old列表。
:-: 
\[old列表占尾端37%\]
LRU列表用来管理已经从磁盘读取到的页,但是数据库刚启动的时候,LRU列表是空的,没有任何的页。这时页都存放在Free列表中。
同时innodb可能会对每个页的内容进行压缩,对于非16KB大小的页,是通过unzip\_LRU列表进行管理的;每个页可能被压缩成2KB、4KB、8KB大小。unzip\_LRU是对不同的尺寸的页进行管理的,同时利用**伙伴系统**进行内存大小的分配。例如当需要对内存申请4KB大小的页时,会进行如下操作:
* 查看4KB列表是否有足够的空间,有直接分配。
* 否则查看8KB列表是否有足够的空间,有将8KB大小的空闲页划分为2个4KB大小的页,放入4KB大小的unzip\_LRU列表中。
* 如果8KB大小列表没有足够空间,则从16KB中的LRU申请空闲页,划分成一个8KB和2个4KB的页放入对应的unzip\_LRU列表中
脏页:在LRU列表中的页被修改之后,该页就会被称为脏页,这个时候缓冲池中的页和磁盘中的页数据不一致。数据库会通过checkpoint机制将脏页刷回到磁盘中,而Flush列表页即为脏页列表。`脏页会同时保留在LRU列表和Flush列表。`因此Flush列表用来负责将脏页刷回到磁盘中。
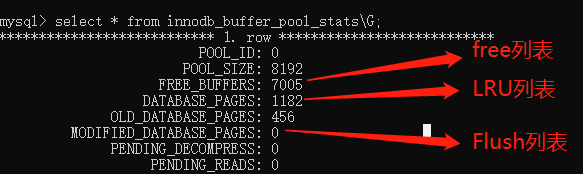
使用`show engine innodb status\G;`可以查看各个列表中的大小
:-: 
**redo log缓冲**
InnoDB会将重做日志信息放到redo log buffer中,并且按照一定的频率刷入磁盘中,刷入磁盘的时机为:
1. Master Thread每秒将redo log buffer刷新到redo log file中。
2. 每个事务提交时会将redo log buffer刷新到redo log file中。
3. 当redo log buffer缓冲区小于1/2的时候,会将redo log buffer刷新到redo log file中。
查看redo log buffer大小
~~~
show variables like 'innodb_log_buffer_size'\G;
~~~
## checkpoint
checkpoint(检查点)技术是为了解决如下几个问题:
1. 缩短数据库进行重做日志时的恢复时间。
2. 缓冲池不够用时,将脏页刷新到磁盘,一次刷新多少?
3. 重做日志不可用时,刷新脏页。
checkpoint技术要做的事情就是将缓冲池中的脏页刷回到磁盘,每次刷新多少页,每次从哪里取脏页(LRU列表、Flush列表),以及什么时间触发Checkpoint。
触发Checkpoint的时间点:
1、 Sharp Checkpoint:数据库关闭的时候将所有脏页刷新到磁盘中。
2、Fuzzy Checkpoint:一次刷新一部分的脏页,而不是将所有的脏页进行刷新。
* Master Thread Checkpoint:Master Thread线程每秒或者每十秒异步的刷新一定比例的脏页回盘。
* FLUSH\_LRU\_LIST Checkpoint: 当LRU中的可用页不够的时候,需要将LRU列表中尾端的一些脏页刷新回磁盘。在新的版本中使用Page Cleaner线程来检查LRU列表是否有足够的可用页。
* Async/Sync Flush Checkpoint:重做日志不可用的时候刷新。
* Dirty Page too much Checkpoint:当脏页数量超过一定比例的时候Innodb引擎就会强制进行Checkpoint,保证缓冲池中有足够的可用页。这个比例可以通过`show variables like 'innodb_max_dirty_pages_pct'\G`查看。
:-: 
【超过90%时候进行刷新】
- 第一章 Java基础
- ThreadLocal
- Java异常体系
- Java集合框架
- List接口及其实现类
- Queue接口及其实现类
- Set接口及其实现类
- Map接口及其实现类
- JDK1.8新特性
- Lambda表达式
- 常用函数式接口
- stream流
- 面试
- 第二章 Java虚拟机
- 第一节、运行时数据区
- 第二节、垃圾回收
- 第三节、类加载机制
- 第四节、类文件与字节码指令
- 第五节、语法糖
- 第六节、运行期优化
- 面试常见问题
- 第三章 并发编程
- 第一节、Java中的线程
- 第二节、Java中的锁
- 第三节、线程池
- 第四节、并发工具类
- AQS
- 第四章 网络编程
- WebSocket协议
- Netty
- Netty入门
- Netty-自定义协议
- 面试题
- IO
- 网络IO模型
- 第五章 操作系统
- IO
- 文件系统的相关概念
- Java几种文件读写方式性能对比
- Socket
- 内存管理
- 进程、线程、协程
- IO模型的演化过程
- 第六章 计算机网络
- 第七章 消息队列
- RabbitMQ
- 第八章 开发框架
- Spring
- Spring事务
- Spring MVC
- Spring Boot
- Mybatis
- Mybatis-Plus
- Shiro
- 第九章 数据库
- Mysql
- Mysql中的索引
- Mysql中的锁
- 面试常见问题
- Mysql中的日志
- InnoDB存储引擎
- 事务
- Redis
- redis的数据类型
- redis数据结构
- Redis主从复制
- 哨兵模式
- 面试题
- Spring Boot整合Lettuce+Redisson实现布隆过滤器
- 集群
- Redis网络IO模型
- 第十章 设计模式
- 设计模式-七大原则
- 设计模式-单例模式
- 设计模式-备忘录模式
- 设计模式-原型模式
- 设计模式-责任链模式
- 设计模式-过滤模式
- 设计模式-观察者模式
- 设计模式-工厂方法模式
- 设计模式-抽象工厂模式
- 设计模式-代理模式
- 第十一章 后端开发常用工具、库
- Docker
- Docker安装Mysql
- 第十二章 中间件
- ZooKeeper