
# Java中几种文件读写的性能对比
准备:
```
static byte[] data = "123456789\n".getBytes();
static String path = "/root/testfileio/out.txt";
```
查看系统脏页及文件被缓存大小:
```
ll -h out.txt && /home/golang/go/bin/pcstat out.txt && cat /proc/vmstat | egrep "dirty|writeback"
```
## 一、使用最传统的stream
~~~
public static void testBasicFileIO() throws Exception {
File file = new File(path);
FileOutputStream out = new FileOutputStream(file);
while (true) {
out.write(data);
}
}
~~~
其中data为10个字节大小的字节数组,在while循环中不断的将其写入文件中。查看输出文件的增长大小,会发现增长的还是比较缓慢的。同时所有的内容也会被pageCache所缓存(缓冲的限制可以查看dirty_ratio参数。)
:-: 
即是暂停了程序,会发现该文件仍然有缓存在pageCache中,如果这个时候突然断电,可能就会导致数据丢失,因为有可能没有被持久化到磁盘中。
## 二、使用buffer + stream
~~~
public static void testBufferedFileIO() throws Exception {
File file = new File(path);
BufferedOutputStream out = new BufferedOutputStream(new FileOutputStream(file));
while (true) {
out.write(data);
}
}
~~~
源码:
~~~
public synchronized void write(int b) throws IOException {
if (count >= buf.length) {
flushBuffer();
}
// 先放到本地的buffer中
buf[count++] = (byte)b;
}
~~~
可以发现使用buffer之后其写入的速度比没有使用buffer就会快很多。其原因是Buffer流会在用户空间中准备一个8KB大小的字节数组作为缓冲区,该数组满了之后才会发生一次调用系统,一次性的写入8KB的内容。这样就大大的减少了系统调用的次数,因此要比没有使用Buffer的快很多。
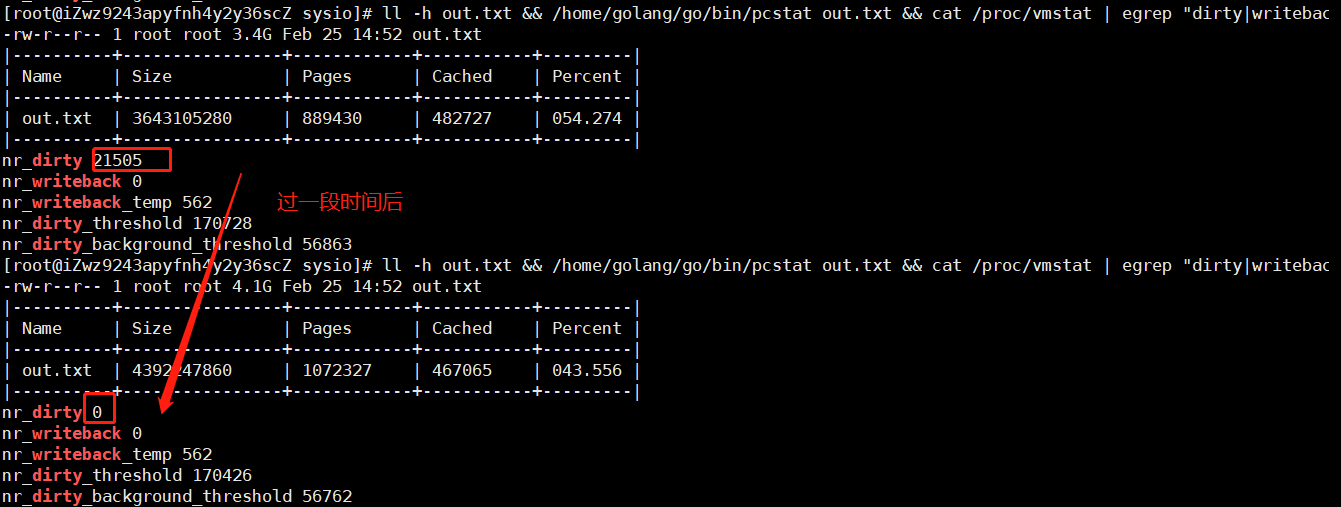
同时在查看文件的缓存大小的时候会发现系统有明显的卡顿现象,这是因为当在脏页的数据超过一定比例之后需要暂停进行脏页的落盘。
:-: 
## 三、使用mmap
~~~
public static void testRandomAccessFileWrite() throws Exception {
RandomAccessFile raf = new RandomAccessFile(path, "rw");
FileChannel rafchannel = raf.getChannel();
//mmap 使得jvm堆和pageCache有一块映射空间
MappedByteBuffer map = rafchannel.map(FileChannel.MapMode.READ_WRITE, 0, 4096 * 1024 * 250); // 1000M的pageCache大小
while (true) {
map.put(data); //不是系统调用 但是数据会到达 内核的pagecache
}
}
~~~
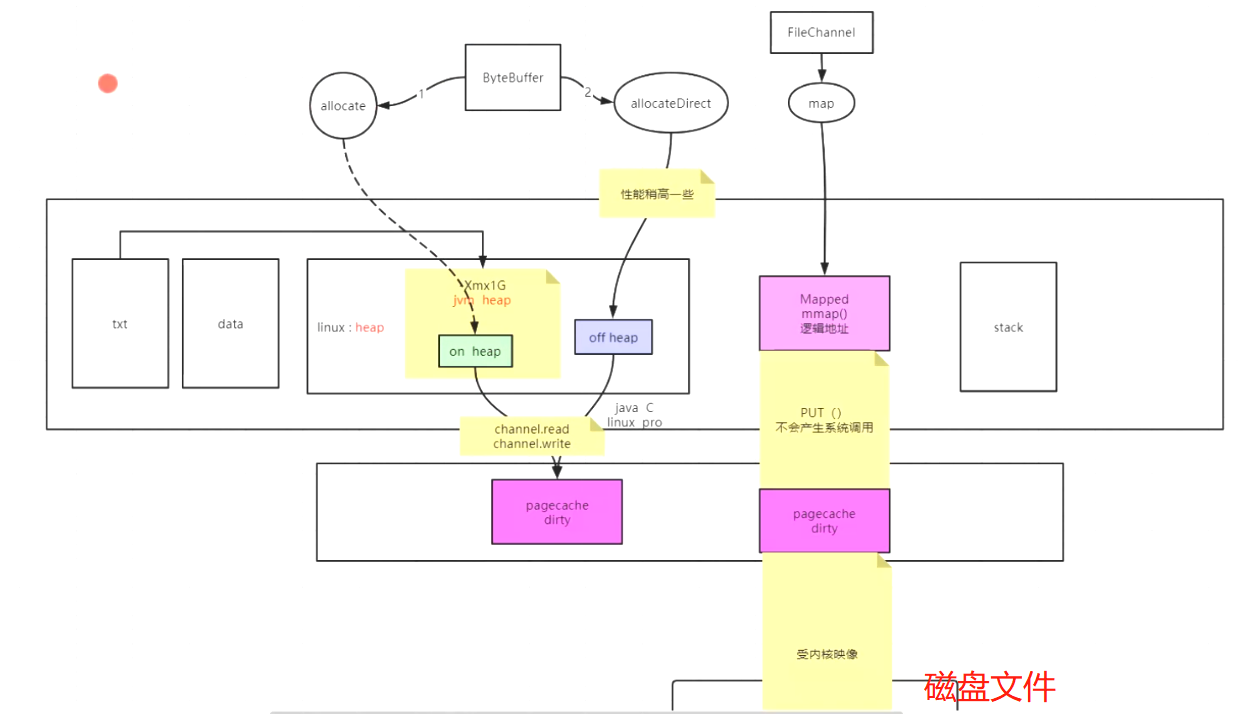
可以看到快1G的pageCache写入几乎是一瞬间的事情。使用mmap会直接在pageCache中开辟一块空间,作为映射(思考一些虚拟内存的地址转化),不会发生系统调用。
使用拓扑图总结:
:-: 
- 第一章 Java基础
- ThreadLocal
- Java异常体系
- Java集合框架
- List接口及其实现类
- Queue接口及其实现类
- Set接口及其实现类
- Map接口及其实现类
- JDK1.8新特性
- Lambda表达式
- 常用函数式接口
- stream流
- 面试
- 第二章 Java虚拟机
- 第一节、运行时数据区
- 第二节、垃圾回收
- 第三节、类加载机制
- 第四节、类文件与字节码指令
- 第五节、语法糖
- 第六节、运行期优化
- 面试常见问题
- 第三章 并发编程
- 第一节、Java中的线程
- 第二节、Java中的锁
- 第三节、线程池
- 第四节、并发工具类
- AQS
- 第四章 网络编程
- WebSocket协议
- Netty
- Netty入门
- Netty-自定义协议
- 面试题
- IO
- 网络IO模型
- 第五章 操作系统
- IO
- 文件系统的相关概念
- Java几种文件读写方式性能对比
- Socket
- 内存管理
- 进程、线程、协程
- IO模型的演化过程
- 第六章 计算机网络
- 第七章 消息队列
- RabbitMQ
- 第八章 开发框架
- Spring
- Spring事务
- Spring MVC
- Spring Boot
- Mybatis
- Mybatis-Plus
- Shiro
- 第九章 数据库
- Mysql
- Mysql中的索引
- Mysql中的锁
- 面试常见问题
- Mysql中的日志
- InnoDB存储引擎
- 事务
- Redis
- redis的数据类型
- redis数据结构
- Redis主从复制
- 哨兵模式
- 面试题
- Spring Boot整合Lettuce+Redisson实现布隆过滤器
- 集群
- Redis网络IO模型
- 第十章 设计模式
- 设计模式-七大原则
- 设计模式-单例模式
- 设计模式-备忘录模式
- 设计模式-原型模式
- 设计模式-责任链模式
- 设计模式-过滤模式
- 设计模式-观察者模式
- 设计模式-工厂方法模式
- 设计模式-抽象工厂模式
- 设计模式-代理模式
- 第十一章 后端开发常用工具、库
- Docker
- Docker安装Mysql
- 第十二章 中间件
- ZooKeeper