
进程、线程、协程的概念并不是按照时间顺序出现的,早在计算机刚发展的阶段就有协程(协同式调度)的概念了。如果强制的为进程、线程、协程的出现理清一条“时间线”的话,大致可能是如下:
操作系统早期只使用进程来管理不同应用程序之间的有序执行,对于一个应用程序的运行,有主要的两部分内容需要管理:程序运行所需的资源、程序的执行流程。为了更加细分这两部分内容的管理,引入了线程的概念,用于表征程序的执行流程。因此也就可以说“进程是资源管理的最小单位,线程是程序运行的最小单位”,进程与线程都是需要通过操作系统来管理的。
但是在现代的网络服务中,大多都是IO密集型系统,也就是说系统花费大量的时间在IO操作上,而应用程序执行IO操作是需要发生用户态到内核态的**模式切换**,这个过程需要保存上下文的信息,虽然这个切换的过程很短,可能只有几十毫秒,但是仍然有可能称为高并发系统中的一个瓶颈。那么有没有办法在应用程序模拟操作系统上下文切换时的过程呢?而不用每次都发生系统调用来进行上下文切换。因此就引入了协程的概念,用于在应用程序层面做调用栈的保护和恢复工作。
> 内存占用大小:进程 - 》线程 -》协程
## 进程
进程是操作系统为了管理不同应用程序之间有些运行而抽象出来的一个映射,操作系统通过一个进程控制块来控制进程的行为,同时一个进程还包括`程序`、`数据`、`栈`、`共享内存`等。基于虚拟内存管理的32位Linux操作系统的进程结构如下:
:-: 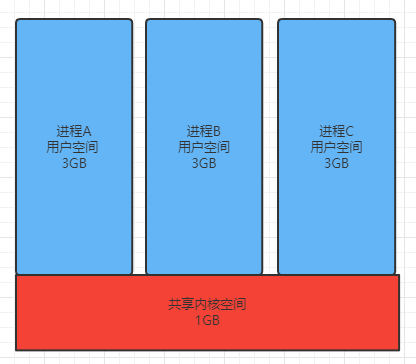
3GB用户空间、1GB内核空间
其中3GB的用户空间又包括了如下的内容:
:-: 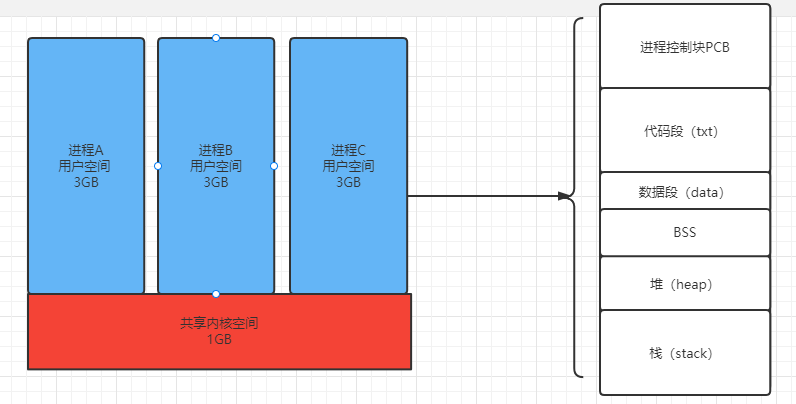
1. 进程控制块:用于操作系统控制进程的数据结构,当发生进程切换时需要在进程控制块中保护进程的上下文信息。其包括的内容有:
- 进程标识信息:**进程ID**、父进程ID、用户ID。
- 处理状态信息:通用寄存器、程序计数器、程序状态字寄存器、**栈指针**。
- 进程信息:**进程状态**、优先级、等待的事件集合、调度信息。
2. 代码段
代码段是用来存放执行程序的指令。需要防止在运行时被非法修改,只允许读,不允许写。
3. 数据段:用于存放静态分配的变量和已经初始化的全局变量。
4. BSS段:存放程序未初始化的全局变量。
5. 堆:存放程序运行过程中使用malloc动态分配的变量。
6. 栈:存放函数内的局部变量。
### 进程状态
当一个应用程序刚被加载进内存的时候操作系统会创建该应用程序对应的进程,一个进程从创建到销毁经历的状态如下:
:-: 
五状态模型
当内存不够用的时候,又引入了进程挂起的状态,其模型如下:
:-: 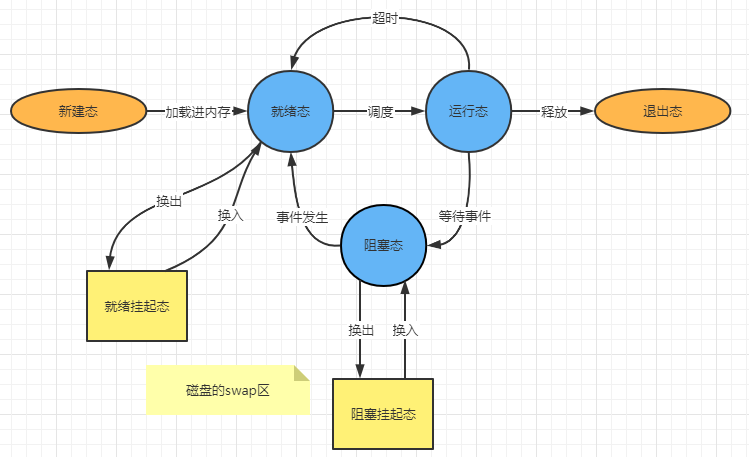
> 问:进程的状态保存在哪?
> 答:进程控制块中有一部分是保留进程信息,其中就有每个进程的状态信息。
那么进程之间的调度又是如何进程的呢?主要是由操作系统的调度器通过进程调度算法来进程的调度与超时。
### 进程调度算法
进程的调度算法从大体上可以分为“非抢占式调度”和“抢占式调度”,“非抢占式调度”会一直运行某个进程,知道阻塞事件获取进程运行结束,才会将CPU让给其他进程。“抢占式调度”的意思是程序正在运行时可能会被中途打断,将CPU的运行权交给其他进程。
**调度算法影响的是等待时间,而不会影响进程真正使用CPU的时间和IO时间。**
1. 先来先服务调度算法
“非抢占式”的一个调度算法,会一直运行直到进程结束或者需要等待事件,不利于短作业进程,适用于CPU密集型任务,不适用于IO密集型任务。
2. 最短作业优先调度算法
“非抢占式”的一个调度算法,会优先调用作业时间最短的进程,有利于提高系统的吞吐量,不利于长作业。**在现代的操作系统根本不可能使用,因为无从得知一个进程的运行时间的长短。**
3. 高响应比优先调度算法
"非抢占式"的一个调度算法,权衡短作业和长作业,每次进行进程调度的时候计算**响应比优先级**,响应比高的先运行。
:-: 
4. 时间片轮询调度算法
简单、公平且使用广泛的一个“抢占式”的调度算法,会为每个运行的进程分配一定的时间长度,当时间长度到了的时候就会切换到就绪态,调度另外一个进程运行。
缺点:可能会导致过多的上下文切换。
通常时间片会设置为20ms~50ms。
5. 最高优先级队列调度算法
“抢占式”和“非抢占式”都有,优先调度优先级高的进程,同时进程的优先级又可以分为静态的和动态的两种区别。
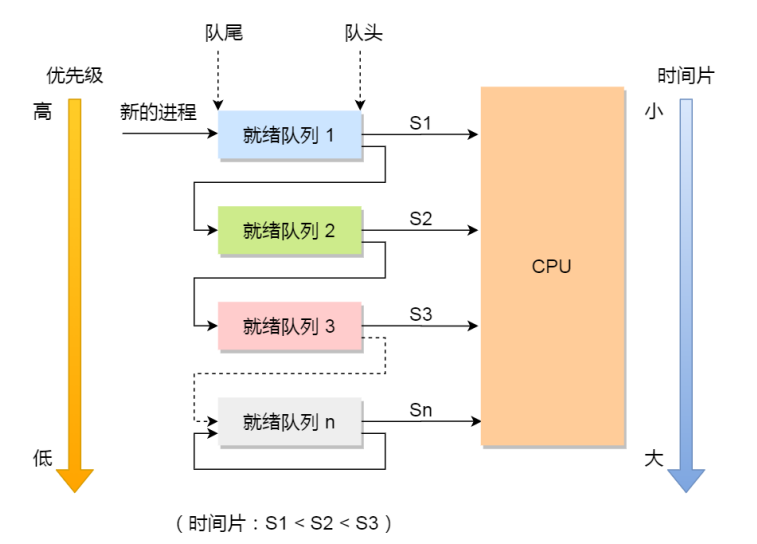
6. 多级反馈队列调度算法
时间片和优先级的综合使用,也是现代大多数操作系统的进程调度的解决方案。优先级高的进程分配的时间片短一些,但是优先调度;优先级低的进程分配的时间片多一些,但是不会优先调度。
:-: 
### 进程间的通信方式
多个进程之间彼此之间如何进行通信呢?在Linux系统主要有如下的几个方式:
1. 管道
2. 消息
3. 共享内存
4. 信号量
5. 信号
6. Socket
#### 管道
管道又可以具体分为*匿名管道*和*具名管道*,匿名管道就是命令行中的“|”,将一个命令的输出作为另外一个命令的输入,单向通信。具名管道可以通过`mkfifo`创建,当一个进程向具名管道中写入数据的时候如果没有进程从管道中读取数据,就会阻塞住,直到数据被另外的进程读取。
缺点:通信方式效率低,不适合进程间频繁的交换数据。
好处:容易知道管道中的数据被另外一个进程读取了。
原理:
创建管道时对调用`pipe()`这个系统调用,并返回两个文件描述符,一个是管道写入端的文件描述符,另外一个是管道输出端的文件描述符。在shell中使用匿名管道时候创建了两个子进程,共享父进程的文件描述符达到通信的效果。具名管道可以用于非父子进程之间的通信。
**存放进程的数据会阻塞到拿数据的进程拿走数据。**
#### 消息队列
为了解决管道通信效率低的问题,引入了消息队列,进程A向进程B通信时将消息体放入消息队列后直接返回 ,进程B再从消息队列中拿走数据,以此来实现异步通信的过程。**消息队列是保存在内核中的消息列表。**
缺点:不适合与大数据的输出,内核中每个消息体的大小有限制。同时进程之间在通信的过程中存在用户态到内核态之间的切换,以及用户态到内核态之间数据拷贝的开销。
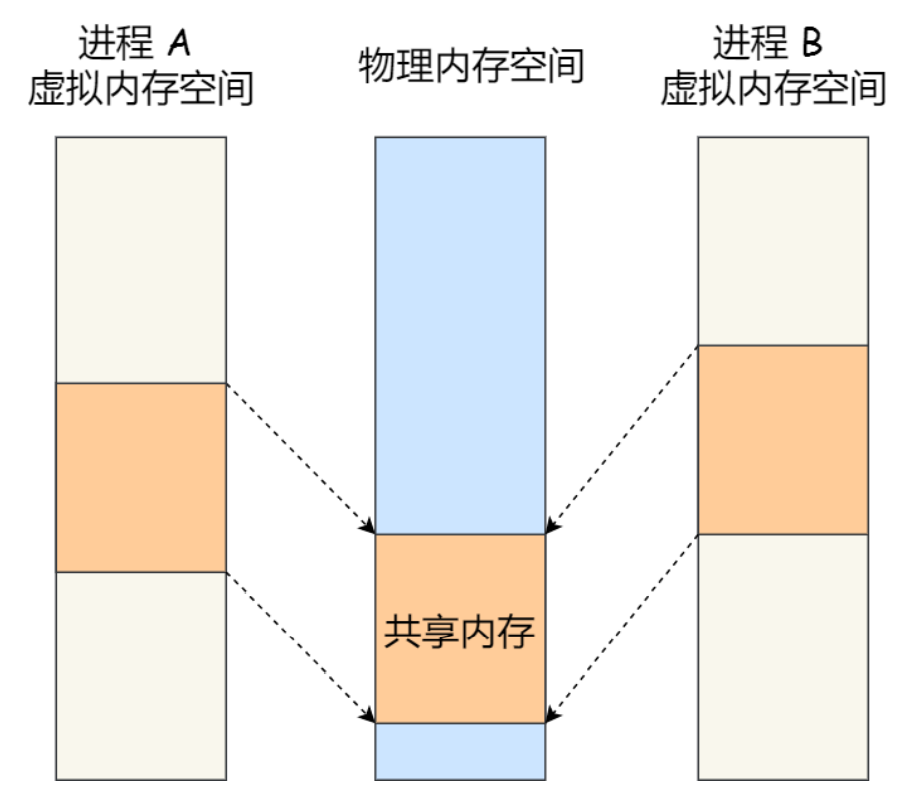
#### 共享内存
由于消息队列在通信的过程中存在内核态到用户态的数据拷贝的过程,使用共享内存就可以避免这个问题了。所谓共享内存就是在进程的虚拟地址空间中拿出一块地址空间,要通信的进程都映射到相同的物理内存中,这样两个进程之间的通信就可以基于这块物理内存中进行了。
:-: 
#### 信号量
当有多个进程对共享内存进行读写操作,就有可以导致数据错乱的问题,信号量就提供了一种同步的控制方式。
信号量本事是一个数据结构,并不会携带消息数据,而是用于控制共享内存的同步访问。其主要包括一个同步状态属性和两个同步操作。
等待操作:当进程访A访问共享内存的时候会递减同步状态的值,当同步状态小于0的时候就会阻塞进程,将进程放入等待队列中。
唤醒操作:当进程A结束访问共享内存的时候会递增同步状态的值,同时唤醒等待队列中的进程继续运行。
#### 信号
上面几种进程间的通信方式都是用于正常的工作模式下,而信号则是用于异常情况下的工作模式,用于响应各种各样的事件。Linux提供了几十种信号用于响应各种各样的事件。
使用命令`kill -l`可以查看,总共有64种。
组合键发送信号:
1. Ctrl + C,产生SIGINT信号,2号。
2. Ctrl + Z,产生SIGTSTP信号。
或者是使用信号标识号,例如杀死一个进程
```
kill -9 pid
```
信号是`唯一的异步通信机制`,可以在任何时候给某一进程发送信号。
#### Socket
Socket是基于TCP/IP协议进行通信的,上面几种都只能用于同一台主机之间的通信,而Socket可以用于不同主机之间的通信,是基于网络服务的不同主机进程之间的通信(当然也可以用于同一台主机)。
## 线程
线程是比进程更轻量级的调度单位,线程的引入可以把一个进程的分配和执行调度分开,各个线程可以共享进程资源,又可以独立调度。
线程的实现方式有如下三种:
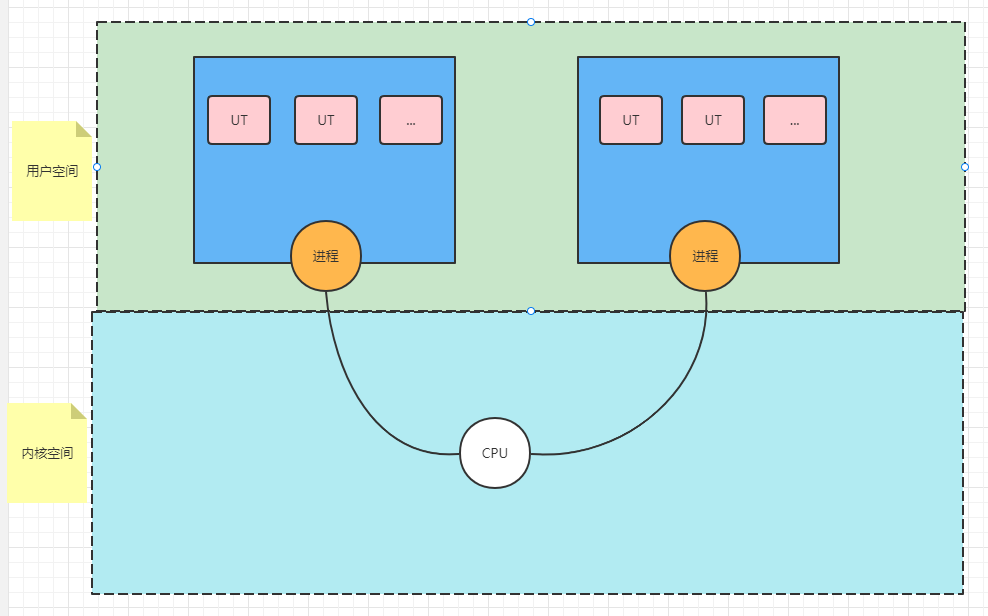
1. 1:1模式
用户程序中一个轻量级进程(LWP)与内核的一个线程一一对应,线程的创建、调度、阻塞与销毁需要系统调用的参数。
:-: 
LWP:Light Weight Process,轻量级进程。
KLT:Kernel-level Thread,内核线程。
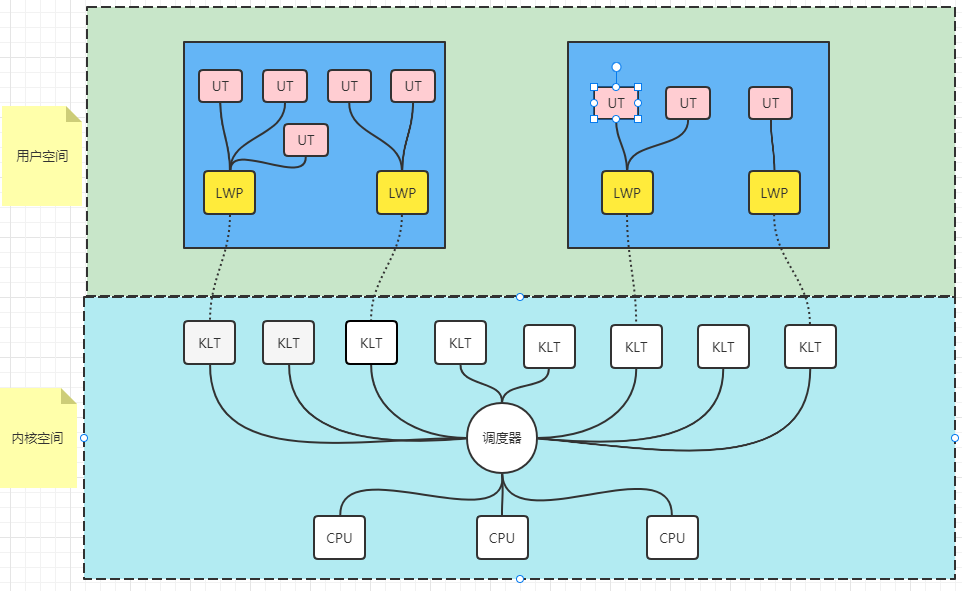
2. 1:N模式
使用用户线程实现,即完全建立在用户空间的线程库,系统内核不能感知用户线程,只能感知进程。用户线程的优势在于不需要系统内核的支援,但是劣势在于实现起来很复杂。
:-: 
UT:user Thread
3. N:M实现
一个轻量级进程对应多个用户线程,每个轻量级进程再和一个内核线程对应。
:-: 
> Java线程
在Java主流的虚拟机使用的是1:1的实现方式,也就是Java的线程的调度是需要陷入内核态由操作系统管理的;同时也由于这样,在Java中设置线程的优先级不一定会生效,而仅仅只是建议操作系统的行为,因为不同的操作系统是否是基于优先级的抢占式调度还未知,同时支持的线程的优先级的数量也未知。
## 协程
Coroutine
对于进程和线程,在IO密集型、高并发的系统中最主要的问题在于系统调用时需要耗费时间在上下文切换上,调度成本比较高。因此有些编程语言(python、golang)引入了协程的概念。
协程是比线程更加轻量级的微线程,可以看成是线程里面的函数一样;其调度时上下文状态的保存和恢复是由应用程序自己实现的,不需要陷入的内核态。
:-: 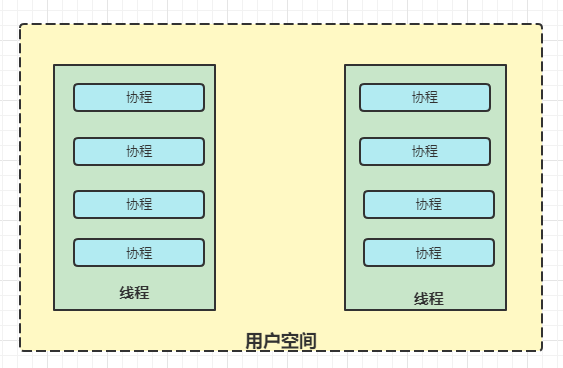
协程要比线程要轻量级很多,例如在Java中一个线程默认分配的空间是1MB,但是协程分配的空间一般几KB就足够了。
**不同语言的协程的实现**
1. Java语言采用的1:1方式的线程方案,并没有在一开始就支持协程。在2018年的时候官方创建了Loom项目来引入“纤程”(也就是协程),在未来Java语言开发中可能两种方式并存。
> 什么是纤程(Fiber)?
> 一个轻量级的用户态的线程,不是通过操作系统,而是通过Java虚拟机本身自己来调度。纤程占用空间小,任务切换开销小。可以创建大量的纤程。
2. golang在语言层面支持了对协程的实现,叫做Goroutine。其协程栈的最小大小为2KB,线程栈的最小大小为2MB。
Go的协程调度器有如下几个重要的数据结构:
* G 表示 Goroutine ,它是一个待执行的任务;
* M 表示操作系统的线程,它由操作系统的调度器调度和管理;
* P 表示处理器 Processor,它可以被看做运行在线程上的本地调度器;
:-: 
【参考】
1. 《小林Coding 图解系统》
2. 《操作系统精髓与设计原理》
3. https://zhuanlan.zhihu.com/p/337978321
4. 《深入理解Java虚拟机》
- 第一章 Java基础
- ThreadLocal
- Java异常体系
- Java集合框架
- List接口及其实现类
- Queue接口及其实现类
- Set接口及其实现类
- Map接口及其实现类
- JDK1.8新特性
- Lambda表达式
- 常用函数式接口
- stream流
- 面试
- 第二章 Java虚拟机
- 第一节、运行时数据区
- 第二节、垃圾回收
- 第三节、类加载机制
- 第四节、类文件与字节码指令
- 第五节、语法糖
- 第六节、运行期优化
- 面试常见问题
- 第三章 并发编程
- 第一节、Java中的线程
- 第二节、Java中的锁
- 第三节、线程池
- 第四节、并发工具类
- AQS
- 第四章 网络编程
- WebSocket协议
- Netty
- Netty入门
- Netty-自定义协议
- 面试题
- IO
- 网络IO模型
- 第五章 操作系统
- IO
- 文件系统的相关概念
- Java几种文件读写方式性能对比
- Socket
- 内存管理
- 进程、线程、协程
- IO模型的演化过程
- 第六章 计算机网络
- 第七章 消息队列
- RabbitMQ
- 第八章 开发框架
- Spring
- Spring事务
- Spring MVC
- Spring Boot
- Mybatis
- Mybatis-Plus
- Shiro
- 第九章 数据库
- Mysql
- Mysql中的索引
- Mysql中的锁
- 面试常见问题
- Mysql中的日志
- InnoDB存储引擎
- 事务
- Redis
- redis的数据类型
- redis数据结构
- Redis主从复制
- 哨兵模式
- 面试题
- Spring Boot整合Lettuce+Redisson实现布隆过滤器
- 集群
- Redis网络IO模型
- 第十章 设计模式
- 设计模式-七大原则
- 设计模式-单例模式
- 设计模式-备忘录模式
- 设计模式-原型模式
- 设计模式-责任链模式
- 设计模式-过滤模式
- 设计模式-观察者模式
- 设计模式-工厂方法模式
- 设计模式-抽象工厂模式
- 设计模式-代理模式
- 第十一章 后端开发常用工具、库
- Docker
- Docker安装Mysql
- 第十二章 中间件
- ZooKeeper