
# 网络IO模型变化
涉及到网络模型有如下几个名称概念:
`同步、异步、阻塞、非阻塞`。
- 同步:应用程序自己完成读写操作。
- 异步:内核完成读写操作,就好像程序没有访问IO,而是直接访问了内核缓冲区。
- 阻塞:调用阻塞方法时一定会拿到返回值。
- 非阻塞:调用非阻塞方法时可能拿不到返回值。
由这些可以组成多种不同的网络模型:
- 同步阻塞:BIO
- 同步非阻塞:NIO、多路复用
- 异步非阻塞:AIO
- 异步阻塞:没有意义!
使用命令:
~~~
strace -off -o out cmd
~~~
可以用于最终每个线程的系统调用情况,输出为out文件。
C10K问题:
单机是否能够支持1万个链接?
下面对C10K问题进行性能压测:
## BIO
代码:
~~~
public static void main(String[] args) {
ServerSocket server = null;
try {
server = new ServerSocket();
server.bind(new InetSocketAddress( 9090), BACK_LOG);
server.setReceiveBufferSize(RECEIVE_BUFFER);
} catch (IOException e) {
e.printStackTrace();
}
System.out.println("server up use 9090!");
while (true) {
try {
System.in.read(); //分水岭:
Socket client = server.accept();
System.out.println("client port: " + client.getPort());
new Thread(
() -> {
while (true) {
try {
InputStream in = client.getInputStream();
BufferedReader reader = new BufferedReader(new InputStreamReader(in));
char[] data = new char[1024];
int num = reader.read(data);
if (num > 0) {
System.out.println("client read some data is :" + num + " val :" + new String(data, 0, num));
} else if (num == 0) {
System.out.println("client readed nothing!");
continue;
} else {
System.out.println("client readed -1...");
client.close();
break;
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
).start();
} catch (IOException e) {
e.printStackTrace();
}finally {
try {
server.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
~~~
在上面服务端的代码在运行过程中,while死循环一直在等待连接,当发生accept(系统调用)方法时,每次都新建了一个线程进行处理,同时操作内核会克隆一个内核级的线程。当然可以采用池化的技术增加线程的利用率。这也是BIO慢的原因。整个BIO的弊端就是因为accept、read、write阻塞,而且这个阻塞还是因为内核提供的API是阻塞的才会造成的。
## NIO
NIO有两个含义:一个是在java.nio包中表示new IO;一个是在操作系统中表示NONBlocking,非阻塞的意思。
~~~
List<SockerChannel> list = new ArrayList<>();
ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
// 设置为非阻塞
while (true) {
accept();
if == null
for (SocketChannel c : list) {
.. 处理读写
}
}
~~~
假设采用11万连接的客户端去进行压测,会=发现建立连接的速度为BIO快很多。但是发现到后面越来越慢了,因为每次List的遍历的次数会越来越多。最后可能出现如下问题`Too many open files`的问题。
NIO的优势:
1. 通过一个或者多个的线程,来解决N个客户端的连接处理。
NIO的问题:
1. 虽然是单线程的,但是每次循环都需要O(n)的系统调用的成本,询问是否有数据。但是实际场景中真的有数据的连接并不多,所以有很多系统调用是浪费的。系统调用accept、recv等都需要做保护现场等工作,比较费时。注意并不是服务端代码调用read系统调用的问题,而是很多read系统调用没有数据的问题。
## 多路复用器
多路复用器指的是多个客户端复用一次系统调用,只用一次系统调用就能知道各个连接的IO状态,进程由程序进一步控制对有状态的IO进行读写操作。
Linux中提供了三种多路复用器:**select、poll、epoll**。Java中的Selector.open会根据不同的操作系统选择不同的多路复用器,可以在虚拟机参数中进行配置,在Linux系统中默认是调用epoll。
其实无论是NIO还是多路复用,都是需要遍历所有的IO询问到状态的。只不过NIO的这个遍历**每次**都需要用户态到内核态的切换,而多路复用器的遍历过程只触发了**一次**用户态到内核态的系统调用,把很多的fd传递给内核,内核遍历这些fd,并修改状态,之后返回给用户态,用户态再根据这些问题具体处理。
**多路复用器也是运行在同步非阻塞模型!!!异步Linux还不完善。**
### select方法
Linux系统中最早的一个多路复用器、其能够接收的文件描述符有限制,受参数FD_SETSIZE的限制,为1024。
select方法每次在发生系统调用的时候,会复制一份所有的文件描述符fds,传递给内核,内核遍历fds后修改状态后返回给用户态。用户态再次遍历fds,然后处理有状态的fd。可以发现这个过程虽然只有一次系统调用,但是需要2次的全量遍历fds的过程。
### poll方法
poll方法是对select的优化,与select的主要区别是没有FD_SETSIZE的限制,两者的工作模式比较像。
### epoll方法
最新的一个多路复用器,也是使用得最多的一个多路复用器。
包括三个过程:
1. epoll\_create:创建一个新的epoll实例,并返回一个文件描述符指向这个epoll实例。即在内核中开辟一块空间,并返回一个fd指向该内核空间。这块空间里存放了一颗红黑树,也称为epoll\_fd。
2. epoll\_ctl:可以看成是控制epoll\_fd这块区域的操作,例如往里面添加fd或者删除fd。
3. epoll\_wait:epoll\_wait在等待一个链表,这个链表中的是由红黑树中发生事件的节点迁移过去的,由中断进行处理。如果没有事件的会阻塞线程进行等待。
因此每次在系统调用的时候拿到链表即可,链表中的节点都表示有状态的节点,因此不用全量的遍历整个fds。
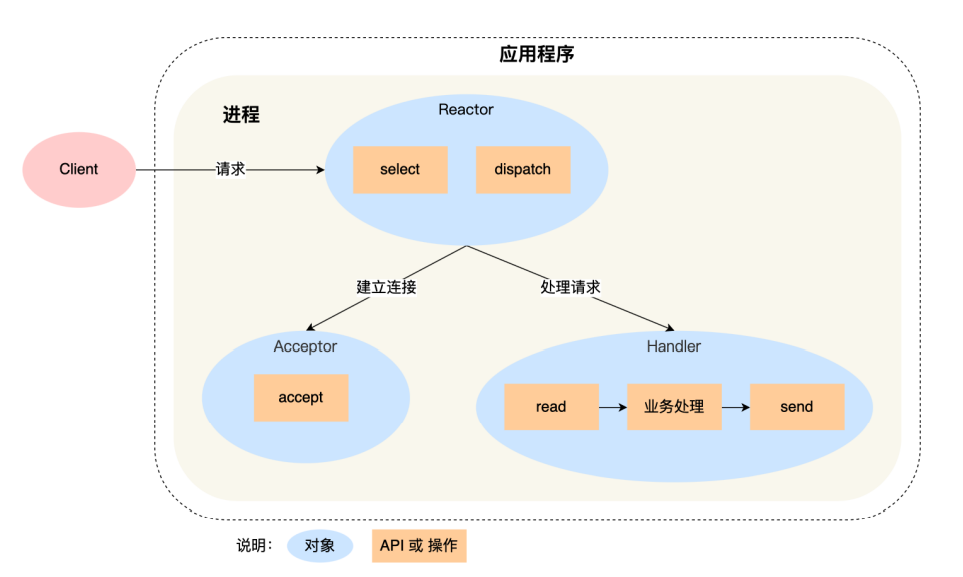
## Reactor模式
对多路复用的一层封装,表示对应事件的意思,当有一个事件来的时候,Reactor就会对其作出反应。Reactor模式也叫作**Disapatcher**分发模式,I/O 多路复⽤监 听事件,收到事件后,根据事件类型分配(Dispatch)给某个进程 / 线程进行处理。例如Netty中的EventLoopGroup。其中:
- Reactor 负责监听和分发事件,事件类型包含连接事件、读写事件;
- 处理资源池负责处理事件,如 read -> 业务逻辑 -> send。
**可能理解成Boss和Worker会比较好理解一点。**
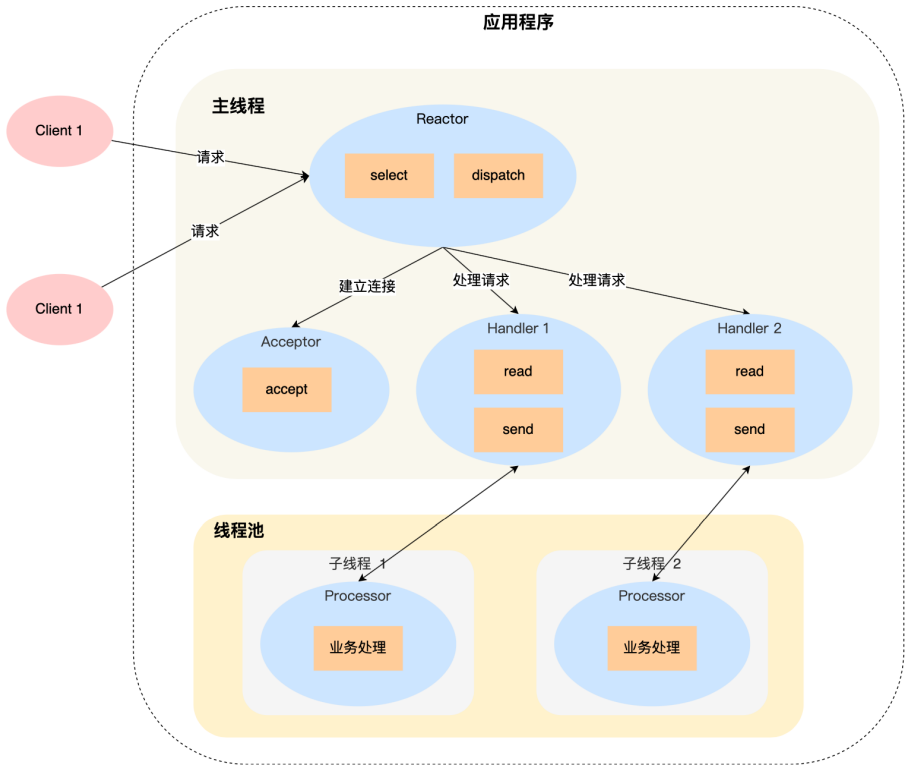
Reactor一般可以分为如下几种:
- 单个Reactor,单工作线程:
:-: 
- 单个Reactor,多个工作线程:
:-: 
- 多个Reactor,多个工作线程:
:-: 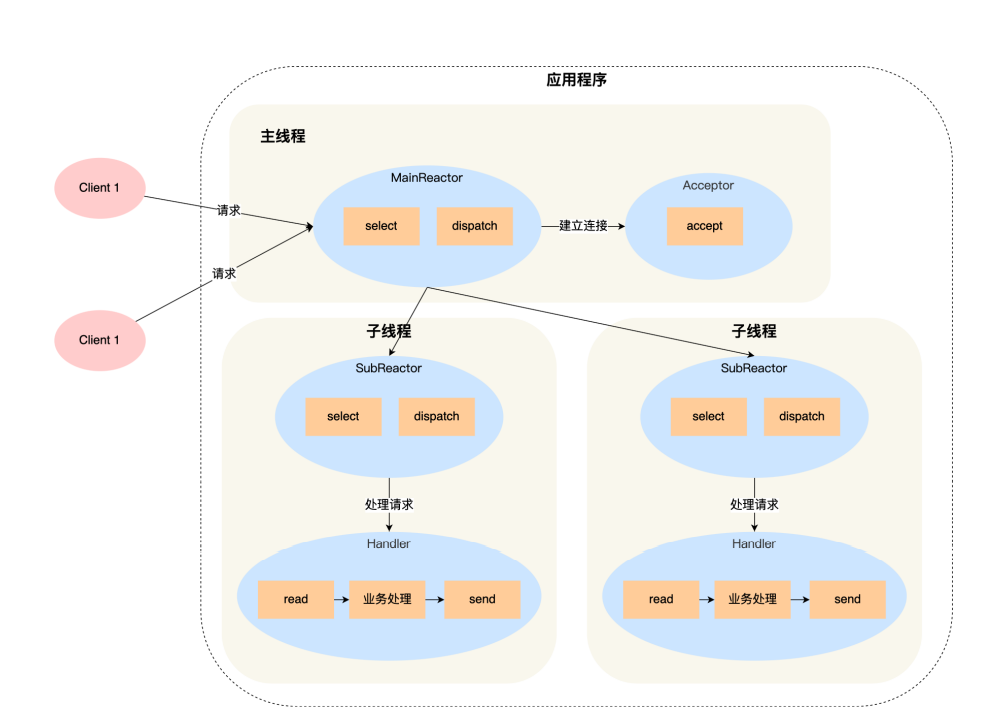
**Netty就是使用这种。**
- 第一章 Java基础
- ThreadLocal
- Java异常体系
- Java集合框架
- List接口及其实现类
- Queue接口及其实现类
- Set接口及其实现类
- Map接口及其实现类
- JDK1.8新特性
- Lambda表达式
- 常用函数式接口
- stream流
- 面试
- 第二章 Java虚拟机
- 第一节、运行时数据区
- 第二节、垃圾回收
- 第三节、类加载机制
- 第四节、类文件与字节码指令
- 第五节、语法糖
- 第六节、运行期优化
- 面试常见问题
- 第三章 并发编程
- 第一节、Java中的线程
- 第二节、Java中的锁
- 第三节、线程池
- 第四节、并发工具类
- AQS
- 第四章 网络编程
- WebSocket协议
- Netty
- Netty入门
- Netty-自定义协议
- 面试题
- IO
- 网络IO模型
- 第五章 操作系统
- IO
- 文件系统的相关概念
- Java几种文件读写方式性能对比
- Socket
- 内存管理
- 进程、线程、协程
- IO模型的演化过程
- 第六章 计算机网络
- 第七章 消息队列
- RabbitMQ
- 第八章 开发框架
- Spring
- Spring事务
- Spring MVC
- Spring Boot
- Mybatis
- Mybatis-Plus
- Shiro
- 第九章 数据库
- Mysql
- Mysql中的索引
- Mysql中的锁
- 面试常见问题
- Mysql中的日志
- InnoDB存储引擎
- 事务
- Redis
- redis的数据类型
- redis数据结构
- Redis主从复制
- 哨兵模式
- 面试题
- Spring Boot整合Lettuce+Redisson实现布隆过滤器
- 集群
- Redis网络IO模型
- 第十章 设计模式
- 设计模式-七大原则
- 设计模式-单例模式
- 设计模式-备忘录模式
- 设计模式-原型模式
- 设计模式-责任链模式
- 设计模式-过滤模式
- 设计模式-观察者模式
- 设计模式-工厂方法模式
- 设计模式-抽象工厂模式
- 设计模式-代理模式
- 第十一章 后端开发常用工具、库
- Docker
- Docker安装Mysql
- 第十二章 中间件
- ZooKeeper