
## IO模型
在网络通信的过程中,应用程序可能接收数据包,也有可能发送数据包。这个网络的IO模型正式基于应用程序的数据包的读写而进行演变的。
1. 应用程序发送数据包
:-: 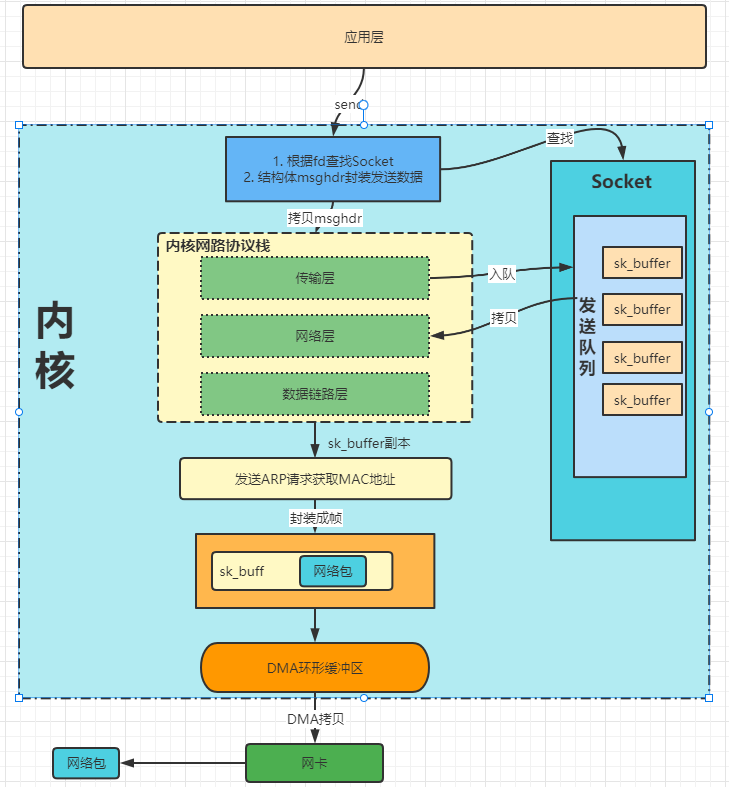
- 调用系统调用send方法的时候,用户线程切换到内核态,在内核中根据fd找到对应的Socket对象,根据这个Socket对象构造出**msghdr**结构体对象。将用户需要发送的全部数据封装在这个**msghdr**结构体中。
- 之后调用内核网络协议栈的`inet_sendmsg`方法,进入内核协议栈的处理流程,根据具体的协议调用对应传输层方法(tcp_sendmsg或者upd_sendmsg)。
- 以tcp_sendmsg为例,将msghdr拷贝到sk_buffer,将新创建的sk_buffer添加到Socket发送队列的尾部。
- 如果符合tcp协议的发送条件,则会调用`tcp_write_xmit`方法,循环获取发送队列的内容,然后进行拥塞控制和流量控制。
- 将发送队列中的sk_buffer重新拷贝一份设置TCP头部后交给网络层(拷贝的目的在于可以超时重传)。
- 之后填充IP头,查找MAC地址,封装成帧。将数据放入RingBuffer中,调用网卡驱动程序来发送数据。
2. 应用程序接收数据包
:-: 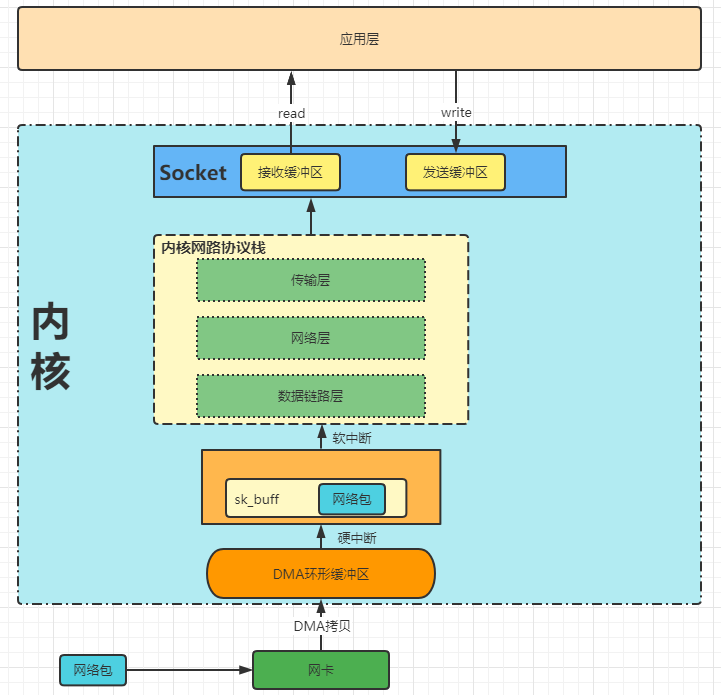
- 当网络包到达网卡的时候,操作系统通过**DMA**的方式将网络包放到环形缓冲区(RingBuffer)。当RingBuffer满的时候新来的数据帧将会被丢弃。
- DMA操作完成的时候,网卡向CPU发送一个**硬中断**,CPU调用对应的`硬中断响应程序`,该响应程序会将RingBuffer中的内容拷贝到sk_buffer中。
- 当数据拷贝到sk_buffer中后会触发**软中断**,内核线程ksoftirqd发现有软中断请求时,会调用网卡驱动注册程序的poll函数,该函数将sk_buffer中的网络包发送到`内核协议栈`中的`ip_rcv`函数中。
- 在`ip_rcv`函数中(网络层),取出数据包的IP头,判断该数据包的走向,如果是ip与本主机的ip相同,则取出传输层的协议类型,去掉ip头,调用传输层的处理函数(tcp_rcv或者upd_rcv)。
- 如果采用的是tcp协议,则会去掉tcp头,找到对应socket四元组,将数据拷贝到Socket的接受缓冲区中。如果没有找到对应的Socket四元组,则会发送一个`目标不可达`的ICMP包。
- 当应用程序调用read读取Socket缓冲区的数据时,如果没有数据,**应用程序就会在系统上阻塞(进入阻塞状态)**直到Socket缓冲区有数据,然后CPU将Socket缓冲区的内容拷贝到用户空间,最后read方法返回,应用程序读取数据。
> 硬中断:由硬件产生,例如磁盘、网卡、键盘、时钟等,每个设备都有自己的硬件请求,基于硬件请求CPU可以将相应的请求发送到对应的硬件驱动程序上。硬中断可以直接中断CPU。
> 软中断:处理方式非常像硬中断,但是是由当前正在运行的进程产生的。不会直接中断CPU。
> ksoftirqd线程:每个CPU都会绑定一个ksoftirqd线程专门处理软中断响应。
> sk_buffer缓冲区:维护网络帧结构的双向链表,链表中的每个元素都是一个数据帧。
对上面的应用程序接收和发送数据的过程进一步抽象,可以划分为如下的两个部分:
:-: 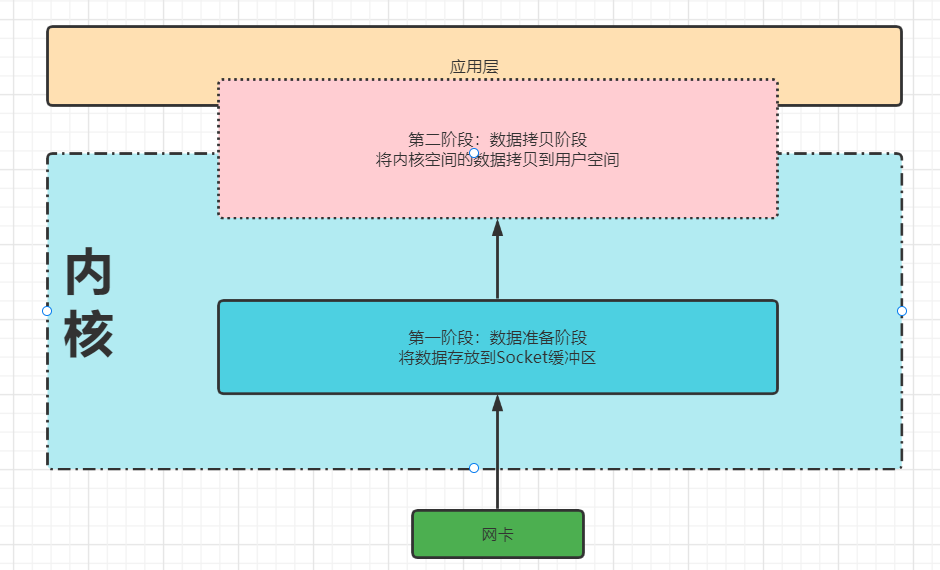
对于接收数据的过程中,其可以分为两个主要的阶段:
1. 数据准备阶段:网卡中的数据经过DMA、硬中断、软中断、网络协议栈处理最终到达Socket缓冲区(ksoftirqd线程处理)。
2. 数据拷贝阶段:将内核Socket缓冲区中的数据拷贝到应用层,应用程序才能读取数据。
## 阻塞与非阻塞、同步与异步
有了上面应用程序读取网卡数据抽象出来的两个过程,也就可以更好的理解阻塞和非阻塞究竟是发生在哪一个过程了。
1. 阻塞和非阻塞
- 阻塞:用户线程发生系统调用会去读取Socket缓冲区的内容,如果此时Socket缓冲区没有数据,则**会对阻塞用户线程**,直到Socket缓冲区有数据之后唤醒用户线程,**用户线程负责**将Socket缓冲区的内容拷贝到用户空间中,这个过程用户线程也是阻塞的。`阻塞发生在第一第二阶段`
- 非阻塞:与阻塞相比发生在第一阶段,如果此时Socket缓冲区没有数据,则会直接返回。如果Socket缓冲区有数据,则用户线程负责将Socket缓冲区的内容拷贝到用户空间。`非阻塞的特点是在第一阶段不会等待,但是第二阶段仍然会等待。`
2. 同步和异步
- 同步:在数据拷贝阶段,是由**用户线程负责将Socket缓冲区的内容拷贝到用户空间**。
- 异步:在数据拷贝阶段,是由**内核来负责将Socket缓冲区的内容拷贝到用户空间,接着通知用户线程IO操作已经完成。**
> 异步需要操作系统内核的支持,做的比较好的是Windows系统,Linux系统还不是很完善。
因此可以这么理解成阻塞与非阻塞主要关注的是**数据准备**阶段,而同步与异步主要关注的是**数据拷贝**阶段。
> 是不是可以理解为什么没有`异步阻塞`这种模型了呢?
> 阻塞的意思意味着**用户线程**要去等待Socket缓冲区有数据,而异步的意思意味着数据从用户态拷贝到内核态不是由用户线程执行的。那么用户线程的等待就没有意义了。
## IO模型
在《UNIX网络编程》中一共介绍了5种IO模型:`阻塞IO、非阻塞IO、IO多路复用、信号驱动IO、异步IO`。其演变过程的原则是:**如何用尽可能少的线程去处理更多的连接。**
### 阻塞IO
由上面可知,阻塞IO模型会在数据准备阶段和数据拷贝阶段用户线程都会进行等待。
- 阻塞读:用户线程发生系统调用,查看Socket缓冲区是否有数据到来,如果有则用户线程拷贝将Socket缓冲区的数据拷贝到用户空间。如果没有则阻塞线程(等待事件,进入阻塞状态),直到Socket缓冲区有数据了(事件发生),则唤醒线程进入就绪状态,等待CPU的调度将数据拷贝回去用户空间。
- 阻塞写:当Socket缓冲区能够容纳下发送数据时,用户线程会将全部的发送数据写入Socket缓冲区中;Socket缓冲区不够的时候用户线程会进入阻塞状态,直到Socket缓冲区有足够的空间能够容纳下全部发送数据时,内核唤醒用户线程,继续发送数据。
在阻塞模型下:每个请求都需要被一个独立的线程处理,一个线程在同一时刻只能与一个连接绑定。同时网络连接并不是总是有事件发生的,因此也就会导致有大量的线程处于阻塞状态了。
适用场景:连接少、并发度低的内部管理系统。
### 非阻塞IO
先来看看非阻塞IO的读写过程:
- 非阻塞读:用户线程判断Socket缓冲区是否有内容,没有内容则直接返回不等待。有数据则将数据拷贝会用户空间,这个过程是等待的。
- 非阻塞写:用户线程直接将数据写入Socket缓冲区中,如果缓冲区已满了则直接返回;当Socket缓冲区有空间的时候将数据拷贝到Socket缓冲区中。
根据这非阻塞IO的特点,也就可以在线程数量这块做出优化了:
一个或者少数几个线程(假设称为**轮询线程**)遍历每个缓冲区是否有数据到达,如果没有数据则继续遍历下一个,如果有数据则将读写数据的业务处理交给**业务线程或业务线程池**进行处理,轮询线程继续轮询。下面是java中使用非阻塞IO的编程方式:
~~~
public static void main(String[] args) throws Exception {
// 保留所有的Socket连接
LinkedList<SocketChannel> clients = new LinkedList<>();
ServerSocketChannel ss = ServerSocketChannel.open();
ss.bind(new InetSocketAddress(9090));
ss.configureBlocking(false); //设置为非阻塞IO模式
while (true) {
SocketChannel client = ss.accept(); //没有连接来则不会阻塞
if (client == null) {
System.out.println("null.....");
} else {
// 有连接了则将连接添加进集合里面
client.configureBlocking(false);
int port = client.socket().getPort();
System.out.println("client...port: " + port);
clients.add(client);
}
for (SocketChannel c : clients) {
// 遍历每个Socket连接,处理具体的读写事件
}
}
}
}
~~~
由于是非阻塞的,在上面的轮询各个Socket连接可以交由一个线程来做,处理具体的IO事件和业务的读写逻辑的时候可以交由线程池去处理。这样就可以使用少量的线程来处理较多的连接了。
**非阻塞与阻塞已经在线程的数量的优化迈出巨大的一步了。但是在高并发的场景下任然有个致命的问题就是:每次轮询判断是否有数据时都要发生一次系统调用,进行上下文的切换,随着并发量的增加,这个开销也是非常巨大的。**
> 应用场景:C10K以下的场景。
### IO多路复用
再强调一遍,**IO模型的核心是应用如何使用少量的线程来处理大量的连接。**
上面的非阻塞IO提供了解决阻塞IO需要创建大量线程的问题,那么在高并发场景下存在大量系统调用的问题又该如何解决呢?于是就演变出IO多路复用这个IO模型。
- 多路:指的是要处理的众多连接。
- 复用:可以理解为多次系统调用复用为一次系统调用,实现了复用就解决了非阻塞IO模型下存在的大量系统调用而导致上下文切换开销的问题。
> 如何去实现复用?在非阻塞IO中需要在用户空间中轮询是否有数据,这样的每次轮询就会发生一次系统调用,也就是说能不能将这个轮询的过程交由内核空间来完成,这样的话只需要一次系统调用(这个系统调用就是多路复用器)就能找到所有有状态的连接了。
Linux提供了三种多路复用器:
#### Select
Select多路复用器的工作方式如下:
:-: 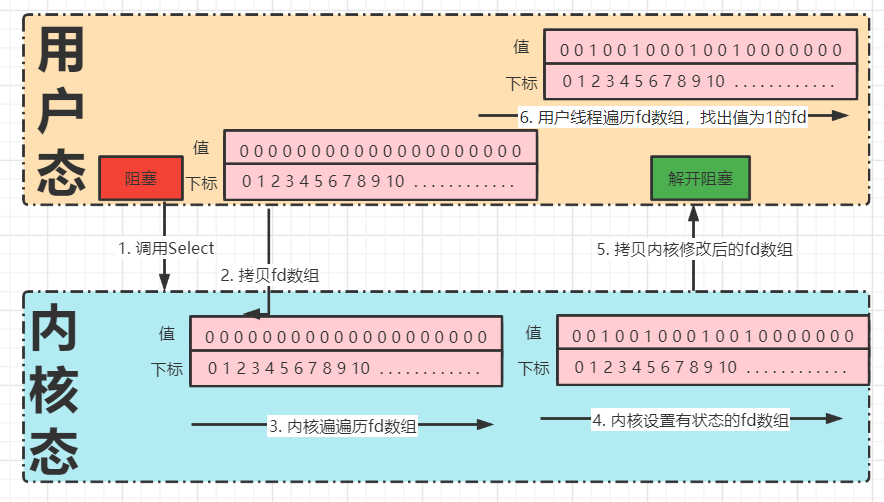
1. 调用select方法,用户代码的执行流程会阻塞在select系统调用上,用户线程从用户态切换到内核态。
2. 用户线程将需要监听的Socket对应的文件描述符fd数组通过select系统调用传递给内核,这个fd数组的索引表示进程对应的文件描述符,值表示文件描述符的状态。
3. 用户线程在内核空间开始轮询文件描述符数组。
4. 修改有读写状态的文件描述符,设置为1。
5. 内核将修改后的fd数组拷贝会用户空间,此时用户代码的执行流程从select中恢复,阻塞解除。
6. 用户线程在用户空间遍历fd数组,找出值为1的fd进行对应的处理。
> 这里的fd数组其实是一个Bitmap结构,该结构最多支持1024个位(FD_SETSIZE),因此select只支持最多处理1024个Socket连接。每一位对应的索引就是一个文件描述符fd。
> 在Linux中Socket也是一个文件,在PCB控制块(task_struct结构体)中有一个属性files_struct *files的结构体属性,它最终指向了进程的所有打开文件表数组中,该数组的元素是一个封装了文件信息的file结构体,**打开文件表数组中的下标也就是常说的文件描述符fd。**
> 注意:由于内核返回的文件描述符数组会修改到原来的状态,因此用户线程在每个处理完之后需要重新设置文件描述符的状态。
性能开销:
1. 一次系统调用,两次上下文的切换,这是不可避免的。
2. 两次fd数组的全量拷贝(但是其实最多只能有128个字节大小的bitmap)。
3. 两次fd数组的全量遍历,一次在内核中遍历是否有事件,另外一次在用户空间中遍历哪些有事件。
> 注意:select系统调用不是线程安全的,因为进程fd数组是共享的。
#### poll
poll的工作原理和select没有太大的区别,主要是在文件描述符数组的结构和文件描述符大小的限制上。其将Bitmap换成一个没有固定长度的链表,链表中的元素如下:
```
struct pollfd {
int fd; // 文件描述符
short events; // 需要监听的事件
short revents; // 实际发生的事件,由内核修改
}
```
性能开销方面和select是一样的。
两者的问题:
> 1. 每次新增、删除要监听的Socket时,都需要进行全量的拷贝。
> 2. 遍历的开销会随着文件描述符数量的增大而增大。
性能瓶颈产生的原因:
> 1. 内核空间不会保存要监听的socket集合,所以需要全量拷贝。
> 2. 内核不会通知具体IO就绪的Socket,所以需要全量遍历并对IO就绪的Socket打上标记。
#### epoll
epoll提供了select和poll性能瓶颈的解决方案,即在**内核保存要监听的socket集合和通知具体就绪的IO。**
其主要包括三个系统调用:
**一、 epoll_create**
内核提供的一个创建epoll对象的系统调用,在用户进程调用epoll_create时,内核会创建一个**eventpoll**的结构体,并且创建相对应的file对象与之相关联(也就是说epoll对象也是个文件,“一切皆文件”),同时将这个文件放入进程的打开文件表中。eventpoll的定义如下:
```
struct eventpoll {
// 等待队列,阻塞在epoll上的进程会放在这里
wait_queue_head_t wq;
// 就绪队列,IO就绪的Socket连接会放在这里
struct list_head rdllist;
// 红黑树,用来监听所有的socket连接
struct rb_root rbr;
// 关联的文件对象
struct file *file;
}
```
1. `wait_queue_head_t`,epoll中的等待队列,存放阻塞在epoll上的用户线程,在IO就绪的时候epoll通过这个队列中的线程并唤醒。
2. `list_head rdllist`,存放IO就绪的Socket连接,阻塞在epoll上的线程被唤醒时可以直接读取这个队列获取有事件发生的Socket,不用再次遍历整个集合(**避免全量遍历**)。
3. `rb_root rbr`,红黑树在查找、插入、删除等方面的综合性能比较优,epoll内部使用一颗红黑手来管理大量的Socket连接。
> select用数组来管理,poll用链表来管理。
**二、 epoll_ctl**
当创建出来epoll对象eventpoll后,可以利用epoll_ctl向epoll对象中添加要管理的Socket连接。这个过程如下:
1. 首先会在内核中创建一个表示Socket连接的数据结构epitem,这个epitem就是红黑树的一个节点。
```
strict epitem {
// 指向所属的epoll对象
struct eventpoll *ep;
// 注册感兴趣的事件,也就是用户空间的epoll_event
struct epoll_event event;
// 指向epoll中的就绪队列
struct list_head rdllink;
// 指向epoll中的红黑树节点
struct rb_node rbn;
// 指向epitem所表示的Socket文件
struct epoll_filefd ffd;
}
```
2. 内核在创建完epitem结构后,需要在Socket中的等待队列上创建等待项wait_queue_t,并且注册epoll的回调函数ep_poll_callback。这个回调函数是epoll同步IO事件通知机制的核心所在,也是区别于select、poll采用轮询方式性能差异所在。ep_poll_callback会找到epitem,将IO就绪的epitem放入到epoll的就绪队列中。(通过一个epoll_entry的结构关联Socket等待队列上的wait_queue_t和epitem)
3. 在Socket等待队列创建好等待项,注册回调函数并关联好epitem后,就可以将epitem插入红黑树中了。
> epoll红黑树优化点之一:插入删除Socket连接不需要像select、poll那样全量复制。
**三、epoll_wait**
epoll_wait用于同步阻塞获取IO就绪的Socket。
1. 用户程序调用epoll_wait后,进入内核首先会找到epoll中的就绪队列eventpoll->rdllit是否有就绪的epitem。如果有的话将epitm中封装的socket信息封装到epoll_event返回。
2. 如果就绪队列中没有IO就绪的epitem,则会创建等待项,将用户线程的fd关联到wait_queue_t->private上,并注册回调函数`default_wake_function`。最后将等待项添加到epoll中的等待队列(eventpoll->wq)中。用户线程让出CPU,进入阻塞状态。
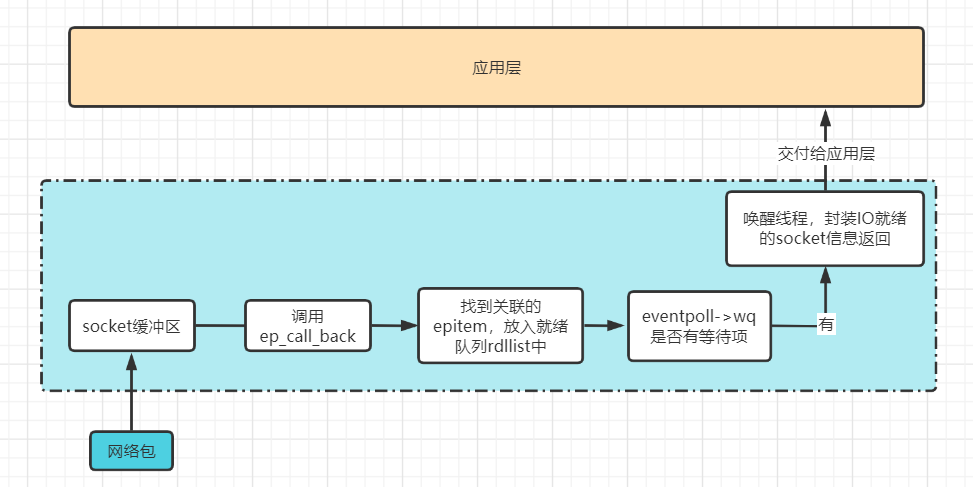
epoll有事件发生时的工作流程:
1. 当数据包通过软中断经过内核协议栈到达Socket的接受缓冲区的时候,调用数据就绪回调函数。在socket的等待队列中找到等待项,该等待项注册的回调函数为ep_poll_callback。
2. 在回调函数ep_poll_callback中找到关联的epitem对象,并将它放到epoll的就绪队列(eventpoll->rdllist)中。
3. 接着查看epoll中的等待队列中是否有等待项,如果有的话唤醒线程,将socket信息封装到epoll_event中返回。
4. 用户线程拿到epoll_event获取IO就绪的socket,就可以对该socket发起系统调用读取数据了。
:-: 
**边缘触发和水平触发**
从上面的执行流程来看,边缘触发和水平触发最关键的区别在于**当socket接收缓冲区还有数据可读时,epoll_wait是否会清空rdllist**。
1. 边缘触发:epoll_wait获取到IO就绪的Socket后会直接清空rdllist,不管socket上是否还有数据可读。因此使用边缘触发模式需要一次性尽可能的将socket上的数据读取完毕,否则用户程序无法再次获得这个socket,直到该socket下次有数据到达被重新放入rdllist。因此边缘触发只会从epoll_wait中苏醒一次。
2. 水平触发:epoll_wait获取到IO就绪的Socket后不会清空rdllist,假如Socket中的数据只读取了一部分没有读取完毕,再次调用epoll_wait(用户线程调用)会检查这些Socket中的接受缓冲区是否还有数据可读,如果有数据可读,则会将这些socket重新放回rdllist中。下次再调用epoll_wait时仍然可以获得这些没有读取完数据的Socket。
总之:边缘触发模式的epoll_wait会清空就绪队列,水平触发模式的epoll_wait不会清空rdllist。
> Netty中的EpollSocketChannel默认的是`边缘触发`模式。
> JDK的NIO默认的是`水平触发`模式。
**总结epoll的优化点**
1. 内核中通过红黑树维护海量连接,在调用epoll_wait时不需要出入监听的Socket集合,内核只需要将就绪队列中的Socket集合返回即可。
2. epoll通过同步IO事件的机制将IO就绪的Socket放入就绪队列中。不用去遍历监听的所有Socket集合。
应用场景:各大主流网络框架用到的网络IO模型,可以解决C10K、C100K甚至是C1000K的问题。
## 信号驱动IO
用户线程通过系统调用`sigaction函数`发起一个IO请求,在对应的Socket注册一个`信号回调`,不阻塞用户线程,用户线程继续工作。当数据就绪的时候(放到Socket缓冲区),就会为该线程产生一个`SIGIO信号`,通过信号回调通知线程进行相关的IO操作。
**信号驱动仍然是同步IO,引用在数据拷贝阶段是需要用户线程自己拷贝的。**
> TCP很少回去使用信号驱动IO,因为其信号事件比较多;UDP只有一种信号事件,可以采用信号驱动IO。
## 异步IO(AIO)
如果信号驱动IO是通知用户线程数据已经到达了可以去拷贝了,那么异步IO就是同时数据已经拷贝好了,可以去使用了。
异步IO的系统调用需要内核的支持,目前只有Window中的IOCP实现了非常成熟的异步IO机制,Linux系统对异步IO机制的实现不够成熟,但是在5.1版本后引入了io_uring异步IO库,改善了一些性能。
上面的IO模型是从内核空间的角度进行的,从用户空间角度的话就可以引出`IO线程模型`,这些不同的IO线程模型都是在讨论如何在多线程中分配工作,谁负责接收连接、谁负责响应读写、谁负责计算、谁负责发送和接收等等。`Reactor模型就对这些分工做出了具体的划分`。
> IO线程模型有Reactor和Proactor。
## Reactor
利用NIO对IO线程进行不同的分工:
- 利用IO多路复器进行IO事件的注册和监听。
- 将监听到的就绪IO事件分发到各个具体的Handler进行处理。
通过IO多路复用技术就可以不断的监听IO事件,不断的分发,就想一个反应堆一样,于是就将这种模型称为Reactor模型。可以分为如下的几种:
1. 单Reactor单线程
例如使用epoll来进行IO多路复用、监听IO就绪事件。
- 单Reactor:意味着**只有一个epoll对象**,用来监听所有的事件,连接事件、读写事件等。
- 单线程:意味着只有一个线程来执行epoll_wait获取IO就绪的Socket,然后对这些就绪的Socket执行读写操作、业务逻辑操作。
**其实就只有一个线程。**
2. 单Reactor多线程
- 单Reactor:只有一个epoll对象来监听所有的IO事件,一个线程来调用epoll_wait获取IO就绪的Socket。
- 多线程:当获取到IO就绪的Socket时,通过线程池来处理具体的IO事件及业务逻辑。
3. 主从Reactor多线程
- 主从Reactor:将原来的单Reactor变为了多Reactor,主Reactor负责监听Socket连接事件。将要监听的read事件注册到从Reactor中,由从Reactor监听Socket的读写事件。。
- 多线程:将读写的业务逻辑交由线程池处理。
## Netty中的IO模型
Netty支持三种Reactor模型,但是常用的是`主从Reactor多线程模型`。注意三种Reactor只是一种设计思想,具体实现不一定严格按照其来实现。Netty中的主从Reactor多线程模型如下:
:-: 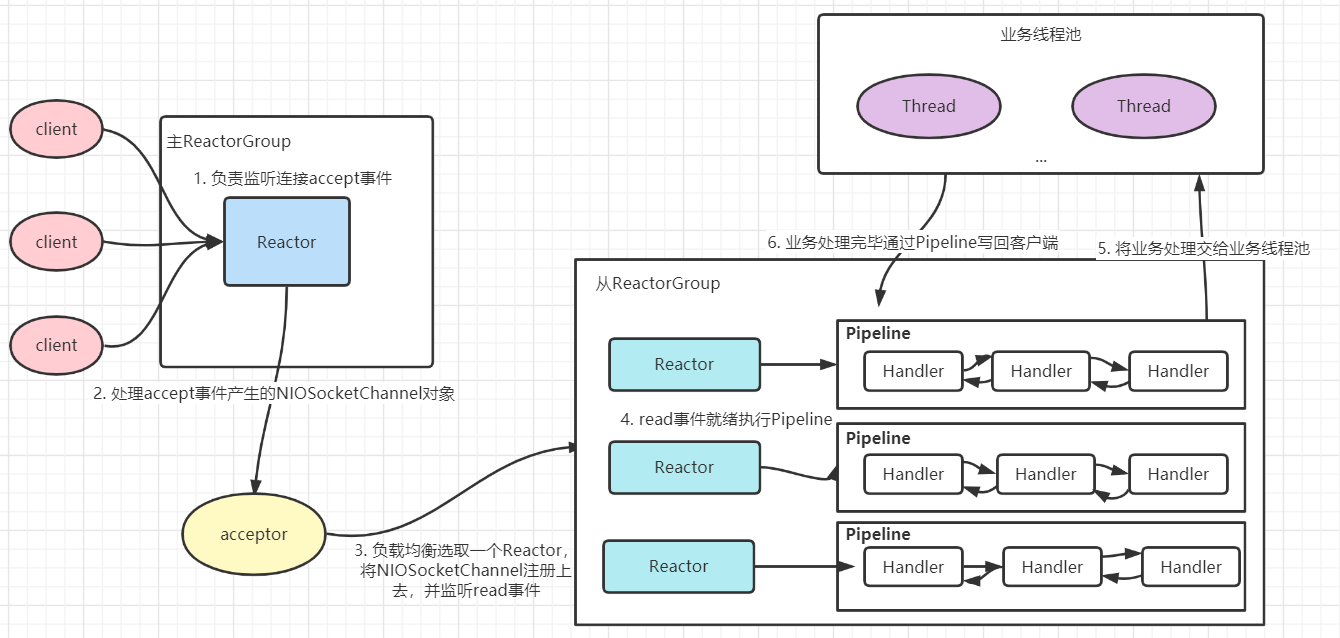
- Reactor在netty中以group的形式出现,Netty中将Reactor分为两组,一组是MainReactorGroup,也就是EventLoopGroup=BossGroup。另外一组是SubReactorGroup,也就是EventLoopGroup=workerGoup。主Reactor负责监听,将产生的NIOSocketChannel对象通过负载均衡的方式注册到从Reactor中。(单个Reactor的原因是一般只监听一个端口)。从Reactor一般有多个,默认的Reactor个数为CPU核心数*2,主要负责Socket上的读写事件。
- 一个Reactor分配一个IO线程,这个IO线程负责从Reactor中获取IO就绪事件,执行IO调用获取IO数据,执行Pipeline。同时每个Socket会被绑定到固定的Reactor中,实现无锁串行化,避免线程安全问题。
- 当`IO请求`在业务线程中完成相应的业务逻辑处理后,在业务线程中利用持有的`ChannelHandlerContext`引用将响应数据在`PipeLine`中反向传播,最终写回给客户端。
**配置各种模型**
1. 配置单Reactor单线程
```
EventLoopGroup eventGroup = new NioEventLoopGroup(1);
ServerBootstrap serverBootstrap = new ServerBootstrap();
serverBootstrap.group(eventGroup);
```
指定线程数为1。
2. 配置单Reactor多线程
```
EventLoopGroup eventGroup = new NioEventLoopGroup();
ServerBootstrap serverBootstrap = new ServerBootstrap();
serverBootstrap.group(eventGroup);
```
默认线程数为CPU*2。
3. 配置主从Reactor多线程
```
EventLoopGroup bossGroup = new NioEventLoopGroup(1);
EventLoopGroup workerGroup = new NioEventLoopGroup();
ServerBootstrap serverBootstrap = new ServerBootstrap();
serverBootstrap.group(bossGroup, workerGroup);
```
:-: 
【参考】
https://mp.weixin.qq.com/s/zAh1yD5IfwuoYdrZ1tGf5Q
- 第一章 Java基础
- ThreadLocal
- Java异常体系
- Java集合框架
- List接口及其实现类
- Queue接口及其实现类
- Set接口及其实现类
- Map接口及其实现类
- JDK1.8新特性
- Lambda表达式
- 常用函数式接口
- stream流
- 面试
- 第二章 Java虚拟机
- 第一节、运行时数据区
- 第二节、垃圾回收
- 第三节、类加载机制
- 第四节、类文件与字节码指令
- 第五节、语法糖
- 第六节、运行期优化
- 面试常见问题
- 第三章 并发编程
- 第一节、Java中的线程
- 第二节、Java中的锁
- 第三节、线程池
- 第四节、并发工具类
- AQS
- 第四章 网络编程
- WebSocket协议
- Netty
- Netty入门
- Netty-自定义协议
- 面试题
- IO
- 网络IO模型
- 第五章 操作系统
- IO
- 文件系统的相关概念
- Java几种文件读写方式性能对比
- Socket
- 内存管理
- 进程、线程、协程
- IO模型的演化过程
- 第六章 计算机网络
- 第七章 消息队列
- RabbitMQ
- 第八章 开发框架
- Spring
- Spring事务
- Spring MVC
- Spring Boot
- Mybatis
- Mybatis-Plus
- Shiro
- 第九章 数据库
- Mysql
- Mysql中的索引
- Mysql中的锁
- 面试常见问题
- Mysql中的日志
- InnoDB存储引擎
- 事务
- Redis
- redis的数据类型
- redis数据结构
- Redis主从复制
- 哨兵模式
- 面试题
- Spring Boot整合Lettuce+Redisson实现布隆过滤器
- 集群
- Redis网络IO模型
- 第十章 设计模式
- 设计模式-七大原则
- 设计模式-单例模式
- 设计模式-备忘录模式
- 设计模式-原型模式
- 设计模式-责任链模式
- 设计模式-过滤模式
- 设计模式-观察者模式
- 设计模式-工厂方法模式
- 设计模式-抽象工厂模式
- 设计模式-代理模式
- 第十一章 后端开发常用工具、库
- Docker
- Docker安装Mysql
- 第十二章 中间件
- ZooKeeper