
## 一、概述
在编程时,可以使用数组来保存多个对象,但数组长度不可变化,一旦在初始化数组时指定了数组长度,这个数组长度就是不可变的,如果需要保存数量变化的数据,数组就有点无能为力了。而且数组无法保存具有映射关系的数据,如成绩表为语文一79,数学一80。这种数据看上去像两个数组,但这两个数组的元素之间有一定的关联关系。
为了保存数量不确定的数据,以及保存具有映射关系的数据,[](http://c.biancheng.net/java/)Java 提供了集合类。Java 所有的集合类都位于 java.util 包下,提供了一个表示和操作对象集合的统一构架,包含大量集合接口,以及这些接口的实现类和操作它们的算法。
> 集合类和数组不一样,数组元素既可以是基本类型的值,也可以是对象(实际上保存的是对象的引用变量);而集合里只能保存对象(实际上只是保存对象的引用变量,但通常习惯上认为集合里保存的是对象)。
集合框架是一个类库的集合,包含实现集合的接口。
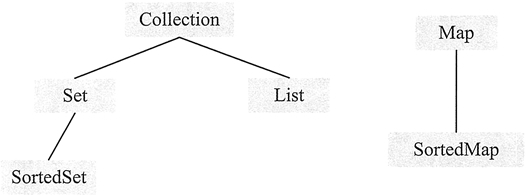
* Collection 接口:该接口是最基本的集合接口。
* List 接口:该接口实现了 Collection 接口。List 是有序集合,允许有相同的元素。使用 List 能够精确地控制每个元素插入的位置,用户能够使用索引来访问 List 中的元素,与数组类似。
* Set 接口:该接口也实现了 Collection 接口。它不能包含重复的元素,SortedSet 是按升序排列的 Set 集合。
* Map 接口:包含键值对,Map 不能包含重复的键。SortedMap 是一个按升序排列的 Map 集合。
:-: 
【选择】下列不属于 Collection 子接口的是()(选择一项)
```
A. List B. Map C. Queue D. Set
```
## 二、Collection 接口
Collection 接口是 List 接口和 Set 接口的父接口,通常情况下不被直接使用。Collection 接口定义了一些通用的方法,通过这些方法可以实现对集合的基本操作。
| 方法名称 | 说明 |
| --- | --- |
| boolean add(E e) | 向集合中添加一个元素,E 是元素的数据类型 |
| boolean addAll(Collection c) | 向集合中添加集合 c 中的所有元素 |
| void clear() | 删除集合中的所有元素 |
| boolean contains(Object o) | 判断集合中是否存在指定元素 |
| boolean containsAll(Collection c) | 判断集合中是否包含集合 c 中的所有元素 |
| boolean isEmpty() | 判断集合是否为空 |
| Iterator<E> iterator() | 返回一个 Iterator 对象,用于遍历集合中的元素 |
| boolean remove(Object o) | 从集合中删除一个指定元素 |
| boolean removeAll(Collection c) | 从集合中删除所有在集合 c 中出现的元素 |
| boolean retainAll(Collection c) | 仅仅保留集合中所有在集合 c 中出现的元素 |
| int size() | 返回集合中元素的个数 |
| Object\[\] toArray() | 返回包含此集合中所有元素的数组 |
## 三、List 集合
List 接口实现了 Collection 接口,它主要有两个实现类:ArrayList 类和 LinkedList 类。在 List 集合中允许出现重复元素。与 Set 集合不同的是,在 List 集合中的元素是有序的,可以根据索引位置来检索 List 集合中的元素,第一个添加到 List 集合中的元素的索引为 0,第二个为 1,依此类推。
### 3.1 ArrayList 类
ArrayList 类提供了快速的基于索引的成员访问方式,对尾部成员的增加和删除支持较好。使用 ArrayList 创建的集合,允许对集合中的元素进行快速的随机访问,不过,向 ArrayList 中插入与删除元素的速度相对较慢。
#### ArrayList 类的常用构造方法
* ArrayList():构造一个初始容量为 10 的空列表。
* ArrayList(Collection c):构造一个包含指定 Collection 的元素的列表,这些元素是按照该 Collection 的迭代器返回它们的顺序排列的。
#### ArrayList 类的常用方法
| 方法名称 | 说明 |
| --- | --- |
| E get(int index) | 获取集合中指定索引位置的元素,E 为元素的数据类型 |
| int index(Object o) | 返回集合中第一次出现指定元素的索引,如果不包含该元素,则返回 -1 |
| int lastIndexOf(Object o) | 返回集合中最后一次出现指定元素的索引,如果不包含该元素,则返回 -1 |
| E set(int index, E e) | 将此集合中指定索引位置的元素修改为指定的对象。返回此集合中指定索引位置的原元素。 |
| List subList(int fromlndex, int tolndex) | 返回一个新的集合,新集合中包含 fromlndex 和 tolndex 索引之间的所有元素。包含 fromlndex 处的元素,不包含 tolndex 索引处的元素。 |
【例题】使用 ArrayList 类向集合中添加三个商品信息,包括商品编号、名称和价格,然后遍历集合输出这些商品信息。
```
public class Product {
private int id; // 商品编号
private String name; // 名称
private float price; // 价格
public Product(int id, String name, float price) {
this.name = name;
this.id = id;
this.price = price;
}
// 这里是上面3个属性的setter/getter方法,这里省略
public String toString() {
return "商品编号:" + id + ",名称:" + name + ",价格:" + price;
}
}
public class Test {
public static void main(String[] args) {
Product pd1 = new Product(4, "辣条", 10);
Product pd2 = new Product(5, "方便面", 12);
Product pd3 = new Product(3, "饮料", 49);
List list = new ArrayList();
list.add(pd1);
list.add(pd2);
list.add(pd3);
System.out.println("*************** 商品信息 ***************");
for (int i = 0; i < list.size(); i++) {
System.out.println((Product) list.get(i));
}
}
}
```
【例题】下面的案例代码演示了 subList() 方法的具体用法。
```
public static void main(String[] args) {
List list = new ArrayList();
list.add("one");
list.add("two");
list.add("three");
list.add("four");
list.add("five");
list.add("six");
list.add("seven");
System.out.println("list 集合中的元素数量:" + list.size());
System.out.println("list 集合中的元素如下:");
Iterator it = list.iterator();
while (it.hasNext()) {
System.out.print(it.next() + "、");
}
List sublist = new ArrayList();
// 从list集合中截取索引2~5的元素,保存到sublist集合中
sublist = list.subList(2, 5);
System.out.println("\nsublist 集合中元素数量:" + sublist.size());
System.out.println("sublist 集合中的元素如下:");
it = sublist.iterator();
while (it.hasNext()) {
System.out.print(it.next() + "、");
}
}
```
### 3.2 LinkList 类
LinkedList 类采用链表结构保存对象,这种结构的优点是便于向集合中插入或者删除元素。需要频繁向集合中插入和删除元素时,使用 LinkedList 类比 ArrayList 类效果高,但是 LinkedList 类随机访问元素的速度则相对较慢。这里的随机访问是指检索集合中特定索引位置的元素。
| 方法名称 | 说明 |
| --- | --- |
| void addFirst(E e) | 将指定元素添加到此集合的开头 |
| void addLast(E e) | 将指定元素添加到此集合的末尾 |
| E getFirst() | 返回此集合的第一个元素 |
| E getLast() | 返回此集合的最后一个元素 |
| E removeFirst() | 删除此集合中的第一个元素 |
| E removeLast() | 删除此集合中的最后一个元素 |
【例题】在仓库管理系统中要记录入库的商品名称,并且需要输出第一个录入的商品名称和最后—个商品名称。
```
public static void main(String[] args) {
LinkedList<String> products = new LinkedList<String>(); // 创建集合对象
String p1 = new String("六角螺母");
String p2 = new String("10A 电缆线");
String p3 = new String("5M 卷尺");
String p4 = new String("4CM 原木方板");
products.add(p1); // 将 p1 对象添加到 LinkedList 集合中
products.add(p2); // 将 p2 对象添加到 LinkedList 集合中
products.add(p3); // 将 p3 对象添加到 LinkedList 集合中
products.add(p4); // 将 p4 对象添加到 LinkedList 集合中
String p5 = new String("标准文件夹小柜");
products.addLast(p5); // 向集合的末尾添加p5对象
System.out.print("*************** 商品信息 ***************");
System.out.println("\n目前商品有:");
for (int i = 0; i < products.size(); i++) {
System.out.print(products.get(i) + "\t");
}
System.out.println("\n第一个商品的名称为:" + products.getFirst());
System.out.println("最后一个商品的名称为:" + products.getLast());
products.removeLast(); // 删除最后一个元素
System.out.println("删除最后的元素,目前商品有:");
for (int i = 0; i < products.size(); i++) {
System.out.print(products.get(i) + "\t");
}
}
```
【选择】已知 ArrayList 的对象是 list,以下哪个方法是判断 ArrayList 中包含"dodoke"()(选择一项)
```
A. list.contains("dodoke");
B. list.add("dodoke");
C. list.remove("dodoke");
D. list.get("dodoke");
```
【编程】使用集合 ArrayList 对字符串进行存储和管理。效果图如下:
```
列表中元素的个数为:6
第1个为语文
第2个为数学
第3个为英语
第4个为化学
第5个为物理
第6个为生物
```
```
import java.util.ArrayList;
import java.util.List;
public class ListTest {
public static void main(String[] args) {
// 用 ArrayList 存储学科的名称
// 输出列表中元素的个数
// 遍历输出所有列表元素
}
}
```
【选择】下列哪个方法可以获取列表指定位置处的元素()(选择一项)
```
A. add(E e) B. remove() C. size() D. get(int index)
```
【编程】定义一个员工信息类 Employee,使用 ArrayList 对员工信息进行添加和显示。效果如下:
```
员工姓名 员工薪资
张三 5000.0
李四 5500.0
赵六 4000.0
```
```
import java.util.List;
import java.util.ArrayList;
public class EmployeeTest {
public static void main(String[] args) {
// 定义 ArrayList 对象
// 创建三个 Employee 类的对象
// 添加员工信息到 ArrayList 中
// 显示员工的姓名和薪资
}
}
```
## 四、Set 集合
Set 集合也实现了 Collection 接口,它主要有两个实现类:HashSet 类和 TreeSet类。Set 集合中的对象不按特定的方式排序,只是简单地把对象加入集合,集合中不能包含重复的对象,并且最多只允许包含一个 null 元素。
### 4.1 HashSet 类
HashSet 类是按照哈希算法来存储集合中的元素,使用哈希算法可以提高集合元素的存储速度,当向 Set 集合中添加一个元素时,HashSet 会调用该元素的 hashCode() 方法,获取其哈希码,然后根据这个哈希码计算出该元素在集合中的存储位置。
#### HashSet 类的常用构造方法
* HashSet():构造一个新的空的 Set 集合。
* HashSet(Collection c):构造一个包含指定 Collection 集合元素的新 Set 集合。
```
HashSet hs = new HashSet(); // 调用无参的构造函数创建HashSet对象
HashSet<String> hss = new HashSet<String>(); // 创建泛型的 HashSet 集合对象
```
【例题】使用 HashSet 创建一个 Set 集合,并向该集合中添加 5 本图书名称。
```
public static void main(String[] args) {
HashSet<String> bookSet = new HashSet<String>(); // 创建一个空的 Set 集合
String book1 = new String("如何成为 Java 编程高手");
String book2 = new String("Java 程序设计一百例");
String book3 = new String("从零学 Java 语言");
String book4 = new String("论 java 的快速开发");
bookSet.add(book1); // 将 book1 存储到 Set 集合中
bookSet.add(book2); // 将 book2 存储到 Set 集合中
bookSet.add(book3); // 将 book3 存储到 Set 集合中
bookSet.add(book4); // 将 book4 存储到 Set 集合中
System.out.println("新进图书有:");
Iterator<String> it = bookSet.iterator();
while (it.hasNext()) {
System.out.println("《" + (String) it.next() + "》"); // 输出 Set 集合中的元素
}
System.out.println("共采购 " + bookSet.size() + " 本图书!");
}
```
### 4.2 TreeSet 类
TreeSet 类同时实现了 Set 接口和 SortedSet 接口。SortedSet 接口是 Set 接口的子接口,可以实现对集合进行自然排序,因此使用 TreeSet 类实现的 Set 接口默认情况下是自然排序的,这里的自然排序指的是升序排序。
TreeSet 只能对实现了 Comparable 接口的类对象进行排序,因为 Comparable 接口中有一个 compareTo(Object o) 方法用于比较两个对象的大小。例如 a.compareTo(b),如果 a 和 b 相等,则该方法返回 0;如果 a 大于 b,则该方法返回大于 0 的值;如果 a 小于 b,则该方法返回小于 0 的值。
TreeSet 类除了实现 Collection 接口的所有方法之外,还提供了如下方法。
| 方法名称 | 说明 |
| --- | --- |
| E first() | 返回集合中的第一个元素。E 表示集合中元素的数据类型 |
| E last() | 返回此集合中的最后一个元素 |
| E poolFirst() | 获取并移除此集合中的第一个元素 |
| E poolLast() | 获取并移除此集合中的最后一个元素 |
| SortedSet<E> subSet(E fromElement, E toElement) | 返回一个新的集合,新集合包含原集合中 fromElement 对象与 toElement对象之间的所有对象。包含 fromElement 对象,不包含 toElement 对象 |
| SortedSet<E> headSet(E toElement) | 返回一个新的集合,新集合包含原集合中 toElement 对象之前的所有对象。不包含 toElement 对象。 |
| SortedSet<E> tailSet(E fromElement) | 返回一个新的集合,新集合包含原集合中 fromElement 对象之后的所有对象。包含 fromElement 对象。 |
【例题】本次有 5 名学生参加考试,当老师录入每名学生的成绩后,程序将按照从低到高的排列顺序显示学生成绩。此外,老师可以查询本次考试是否有满分的学生存在,不及格的成绩有哪些,90 分以上成绩的学生有几名。
```
public static void main(String[] args) {
TreeSet<Double> scores = new TreeSet<Double>(); // 创建 TreeSet 集合
Scanner input = new Scanner(System.in);
System.out.println("------------学生成绩管理系统-------------");
for (int i = 0; i < 5; i++) {
System.out.println("第" + (i + 1) + "个学生成绩:");
double score = input.nextDouble(); // 将学生成绩转换为Double类型,添加到TreeSet集合中
scores.add(Double.valueOf(score));
}
Iterator<Double> it = scores.iterator(); // 创建 Iterator 对象
System.out.println("学生成绩从低到高的排序为:");
while (it.hasNext()) {
System.out.print(it.next() + "\t");
}
System.out.println("\n请输入要查询的成绩:");
double searchScore = input.nextDouble();
if (scores.contains(searchScore)) {
System.out.println("成绩为: " + searchScore + " 的学生存在!");
} else {
System.out.println("成绩为: " + searchScore + " 的学生不存在!");
}
// 查询不及格的学生成绩
SortedSet<Double> score1 = scores.headSet(60.0);
System.out.println("\n不及格的成绩有:");
for (int i = 0; i < score1.toArray().length; i++) {
System.out.print(score1.toArray()[i] + "\t");
}
// 查询90分以上的学生成绩
SortedSet<Double> score2 = scores.tailSet(90.0);
System.out.println("\n90 分以上的成绩有:");
for (int i = 0; i < score2.toArray().length; i++) {
System.out.print(score2.toArray()[i] + "\t");
}
}
```
【选择】下列有关 HashSet 的描述正确的是()(选择两项)
```
A. HashSet 是 Set 的一个重要实现类
B. HashSet 中的元素无序但可以重复
C. HashSet 中只允许一个 null 元素
D. 不适用于存取和查找
```
【选择】以下关于 Set 对象和创建错误的是()(选择一项)
```
A. Set set = new Set();
B. Set set = new HashSet();
C. HashSet set = new HashSet();
D. Set set = new HashSet(10);
```
【选择】关于 Iterator 的描述错误的是()(选择一项)
```
A. Iterator 可以对集合 Set 中的元素进行遍历
B. hasNext() 方法用于检查集合中是否还有下一个元素
C. next() 方法返回集合中的下一个元素
D. next() 方法的返回值为 false 时,表示集合中的元素已经遍历完毕
```
【选择】定义一个 Worker 类,关于 hashCode() 方法的说法正确的是()(选择一项)
```
A. 在 Worker 类中,hashCode() 方法必须被重写
B. 如果 hashCode 的值相同,则两个 Worker 类的对象就认为是相等的
C. hashCode 的值不同时,则两个对象必定不同
D. 以上说法均正确
```
【编程】定义一个学生类,使用 HashSet 对学生类的对象进行管理:执行添加操作,然后解决重复数据的添加问题。
```
[学号:3,姓名:张三,成绩:65.0]
[学号:1,姓名:李四,成绩:87.0]
[学号:2,姓名:王五,成绩:95.0]
```
【选择】下列相关迭代器描述不正确的是()(选择一项)
```
A. Iterator 接口可以以统一的方式对各种集合元素进行遍历
B. hashNext() 是 Iterator 接口的一个方法,是用来检测集合中是否还有下一个元素
C. next() 是 Iterator 接口的一个方法,是用来返回集合中的下一个元素
D. hasNext() 是 Iterator 接口的一个方法,是用来返回集合中的下一个元素
```
【选择】以下关于 Set 和 List 的说法正确的是()(选择一项)
```
A. Set 中的元素是可以重复的
B. List 中的元素是无序的
C. HashSet 中只允许有一个 null 元素
D. List 中的元素是不可以重复的
```
## 五、Map 集合
Map 是一种键-值对(key-value)集合,Map 集合中的每一个元素都包含一个键对象和一个值对象。其中,键对象不允许重复,而值对象可以重复,并且值对象还可以是 Map 类型的,就像数组中的元素还可以是数组一样。
Map 接口主要有两个实现类:HashMap 类和 TreeMap 类。其中,HashMap 类按哈希算法来存取键对象,而 TreeMap 类可以对键对象进行排序。
Map接口的常用方法
| 方法名称 | 说明 |
| --- | --- |
| V get(Object key) | 返回 Map 中指定键对象所对应的值。V 表示值的数据类型 |
| V put(K key, V value) | 向 Map 中添加键-值对,返回 key 以前对应的 value,如果没有, 则返回 null。 |
| V remove(Object key) | 从 Map 中删除 key 对应的键-值对,返回 key 对应的 value,如果没有,则返回null。 |
| Set entrySet() | 返回 Map 中所有键-值对的 Set 集合,此 Set 集合中元素的数据类型为 Map.Entry。 |
| Set keySet() | 返回 Map 中所有键对象的 Set 集合。 |
【例题】每名学生都有属于自己的唯一编号,即学号。在毕业时需要将该学生的信息从系统中移除。
```
public static void main(String[] args) {
HashMap users = new HashMap();
// 将学生信息键值对存储到 Map 中
users.put("11", "张浩太");
users.put("22", "刘思诚");
users.put("33", "王强文");
users.put("44", "李国量");
users.put("55", "王路路");
System.out.println("******** 学生列表 ********");
Iterator it = users.keySet().iterator();
// 遍历 Map
while (it.hasNext()) {
Object key = it.next();
Object val = users.get(key);
System.out.println("学号:" + key + ",姓名:" + val);
}
Scanner input = new Scanner(System.in);
System.out.println("请输入要删除的学号:");
int num = input.nextInt();
if (users.containsKey(String.valueOf(num))) { // 判断是否包含指定键
users.remove(String.valueOf(num)); // 如果包含就删除
} else {
System.out.println("该学生不存在!");
}
System.out.println("******** 学生列表 ********");
it = users.keySet().iterator();
while (it.hasNext()) {
Object key = it.next();
Object val = users.get(key);
System.out.println("学号:" + key + ",姓名:" + val);
}
}
```
【选择】HashMap 的数据是以 key-value 的形式存储的,以下关于 HashMap 的说法正确的是()(选择一项)
```
A. HashMap 中的键不能为 null
B. HashMap 中的 Entry 对象是有序排列的
C. key 值不允许重复
D. value 值不允许重复
```
【编程】已知数据,世界杯冠军及夺冠年份:德国(2014)、西班牙(2010)、意大利(2006)、巴西(2002)、法国(1998),将夺冠年份作为 key 值,冠军队名作为 value 值,存储至少三条数据到 HashMap 中,并循环打印输出如下:
```
使用迭代器方法进行输出:
意大利 德国 西班牙
使用 EntrySet 进行输出:
2006-意大利
2014-德国
2010-西班牙
```
```
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Map.Entry;
import java.util.Set;
public class FootballTest {
public static void main(String[] args) {
// 定义 HashMap 的对象并添加数据
// 使用迭代器的方式遍历
// 使用 EntrySet 同时获取 key 和 value
}
}
```
【选择】已知 HashMap 对象,空白处应添加的语句是()(选择一项)
```
Map<String, String> hashMap = new HashMap<>();
hashMap.put("1", "stu01");
hashMap.put("2", "stu02");
Set<String> keySet = hashMap.keySet();
for (String key : keySet) {
// 根据 key 值输出 value 的值
System.out.println( );
}
```
```
A. hashMap.get(key);
B. hashMap.getValue();
C. hashMap.getKey();
D. hashMap.Value();
```
- 阶段一 Java 零基础入门
- 步骤1:基础语法
- 第01课 初识
- 第02课 常量与变量
- 第03课 运算符
- 第04课 选择结构
- 第05课 循环结构
- 第06课 一维数组
- 第08课 方法
- 第09课 数组移位与统计
- 第10课 基础语法测试
- 第09课 基础语法测试(含答案)
- 步骤2:面向对象
- 第01课 类和对象
- 第02课 封装
- 第03课 学生信息管理
- 第04课 继承
- 第05课 单例模式
- 第06课 多态
- 第07课 抽象类
- 第08课 接口
- 第09课 内部类
- 第10课 面向对象测试
- 第10课 面向对象测试(含答案)
- 步骤3:常用工具类
- 第01课 异常
- 第02课 包装类
- 第03课 字符串
- 第04课 集合
- 第05课 集合排序
- 第06课 泛型
- 第07课 多线程
- 第08课 输入输出流
- 第09课 案例:播放器
- 第10课 常用工具测试(一)
- 第10课 常用工具测试(一)(答案)
- 第10课 常用工具测试(二)
- 第10课 常用工具测试(二)(答案)
- 阶段二 从网页搭建入门 JavaWeb
- 步骤1:HTML 与 CSS
- 第01课 HTML 入门
- 第01课 HTML 入门(作业)
- 第02课 CSS 入门
- 第02课 CSS 入门(作业)
- 第03课 CSS 布局
- 第03课 CSS 布局(作业)
- 步骤2:JavaScript 与前端案例
- 第01课 JavaScript 入门
- 第01课 JavaScript 入门(作业)
- 第02课 仿计算器
- 第03课 前端油画商城案例
- 第04课 轮播图
- 第05课 网页搭建测试
- 第05课 网页搭建测试(含答案)
- 步骤3:JavaScript 教程
- 入门
- 概述
- 基本语法
- 数据类型
- 概述
- 数值
- 字符串
- undefined, null 和布尔值
- 对象
- 函数
- 数组
- 运算符
- 算术运算符
- 比较运算符
- 布尔运算符
- 位运算符
- 运算顺序
- 语法专题
- 数据类型的转换
- 错误处理机制
- 标准库
- String
- Date
- Math
- DOM
- 概述
- Document 节点
- 事件
- EventTarget 接口
- 事件模型
- 常见事件
- 阶段三 数据库开发与实战
- 步骤1:初始数据库操作
- 第01课 数据类型
- 第02课 表的管理
- 第03课 数据管理
- 第04课 常用函数
- 第05课 JDBC 入门
- 第06课 Java 反射
- 第07课 油画商城
- 第08课 数据库基础测试
- 步骤2:MyBatis 从入门到进阶
- 第01课 IntelliJ IDEA 开发工具入门
- 第02课 Maven 入门
- 第03课 工厂模式
- 第04课 MyBatis 入门
- 第05课 MyBatis 进阶
- 第06课 商品信息管理
- 第07课 MyBatis 基础测试
- 步骤3:Redis 数据库与 Linux 下项目部署
- 第01课 Linux 基础
- 第02课 Linux 下 JDK 环境搭建及项目部署
- 第03课 Redis 入门
- 阶段四 SSM 到 Spring Boot 入门与综合实战
- 步骤1:Spring 从入门到进阶
- 第01课 Spring 入门
- 第02课 Spring Bean 管理
- 第03课 Spring AOP
- 第04课 基于 AspectJ 的 AOP 开发
- 第05课 JDBC Template
- 第06课 Spring 事务管理
- 第07课 人员管理系统开发
- 第08课 Spring 从入门到进阶测试
- 步骤2:Spring MVC 入门与 SSM 整合开发
- 第01课 Spring MVC 入门与数据绑定
- 第02课 Restful 风格的应用
- 第03课 SpringMVC 拦截器
- 第04课 办公系统核心模块
- 步骤3:Spring Boot 实战
- 第01课 Spring Boot 入门
- 第02课 校园商铺项目准备
- 第03课 校园商铺店铺管理
- 第04课 校园商铺商品管理及前台展示
- 第05课 校园商铺框架大换血
- 步骤4:Java 面试
- 第01课 面试准备
- 第02课 基础面试技巧
- 第03课 Web基础与数据处理
- 第04课 主流框架