[TOC]
## 一、单选题
**1.一般,k-NN最近邻方法在()的情况下效果较好** B
A.样本较多但典型性不好
B.样本较少但典型性好
C.样本呈团状分布
D.样本呈链状分布
**2. bootstrap数据是什么意思?( )** C
A.有放回地从总共M个特征中抽样m个特征
B.无放回地从总共M个特征中抽样m个特征
C.有放回地从总共N个样本中抽样n个样本
D.无放回地从总共N个样本中抽样n个样本
**3.对于下图,一个比较好的主成分选择是多少?()** B
A. 7
B. 30
C. 35
D.不能确定
**4.数据科学家可能会同时使用多个算法(模型)进行预测, 并且最后把这些算法的结果集成起来进行最后的预测(集成学习),以下对集成学习说法正确的是()** B
A.单个模型之间有高相关性
B.单个模型之间有低相关性
C.在集成学习中使用“平均权重”而不是“投票”会比较好
D.单个模型都是用的一个算法
**5.某超市研究销售纪录数据后发现,买啤酒的人很大概率也会购买尿布.这种属于数据挖掘的哪类问题?( )** A
A、 关联规则分析
B、 聚类
C、 分类
D、 自然语言处理
**6.当不知道数据所带标签时,可以使用哪种技术促使带同类标签的数据与带其他标签的数据相分离? ( )** B
A、分类
B、聚类
C、关联规则发现
D、主成分分析
**7. Nave Bayes是一种特殊的Bayes分类器,特征变量是X,类别标签是C,它的一个假定是( )** C
A、各类别的先验概率P(C)是相等的
B、以0为均值. sqr(2)/2为标准差的正态分布
C、特征变量X的各个维度是类别条件独立随机变量
D、P(X|C)是高斯分布
**8. Lasso回归与传统的线性回归方程区别是( )** A
A、增加L1范数惩罚因子
B、增加L2范数惩罚因子
C、无区别
D、Lasso回归是线性方程在sigmoid函数上的嵌套
**9.协同过滤算法解决的是数据挖掘中的哪类问题( )** C
A、分类问题
B、聚类问题
C、推荐问题
D、自然语言处理问题
**10.交叉验证如果设置K=5,会训练几次?( )** B
A、4
B、5
C、6
D、7
**11.评估完模型之后,发现模型存在高偏差(high bias),应该如何解决?( )** B
A、 减少模型的特征数量
B、 增加模型的特征数量
C、 增加样本数量
D、 以上说法都正确
**12.将两个簇的邻近度定义为不同簇中任意两点的最短距离,它是一种( )度量方式。** A
A.单链接
B.全链接
C.组平均
D.质心距离
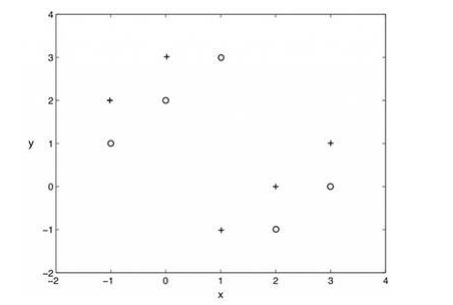
**13.使用k=1的knn算法,下图二类分类问题, “+”和“o”分别代表两个类,那么,用仅拿出一个测试样本的交叉验证方法,交叉验证的错误率是多少( )** B
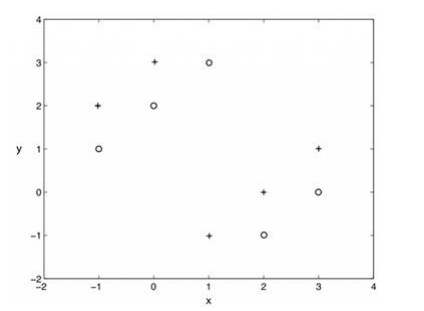
A、0%
B、100%
C、0%到100
D、 以上都不是
**14.下面有关分类算法的准确率,召回率,F1值的描述,错误的是( )** C
A、 准确率是检索出相关文档数与检索出的文档总数的比率,衡量的是检索系统的查准率
B、 召回率是指检索出的相关文档数和文档库中所有的相关文档数的比率,衡量的是检索系统的查全
率
C、 正确率、召回率和F值取值都在0和1之间,数值越接近0,查准率或查全率就越高
D、 为了解决准确率和召回率冲突问题,引入了F1分数
**15.以下哪个算法是无监督学习算法:( )** C
A、朴素贝叶斯
B、LinearRegression
C、K-Means
D、支持向量机
**16.下面哪个算法可以将文本数据转换为数值数据?( )** A
A、TF-IDF
B、 决策树
C、PCA
D、DBSCAN
**17.以下哪个是回归模型评判的指标?( )** A
A、mean\_squared\_error
B、 准确率
C、 召回率
D、 轮廓系数
**18.如果我使用数据集的全部特征并且能够达到100%的准确率,但在测试集上仅能达到70%左右,这说明( )** C
A、 欠拟合
B、 模型很棒
C、 过拟合
D、 算法不好
**19.在以下不同的场景中,使用的分析方法不正确的是?( )** B
A.根据商家最近一年的经营及服务数据,用聚类算法判断出天猫商家在各自主营类目下所属的商家层级
B.根据商家近几年的成交数据,用聚类算法拟合出用户未来一个月可能的消费金额公式
C.用关联规则算法分析出购买了汽车坐垫的买家,是否适合推荐汽车脚垫
D.根据用户最近购买的商品信息,用决策树算法识别出淘宝买家可能是男还是女
**20.将两个簇的邻近度定义为不同簇的所有点对的邻近度的平均值,它是一种( )度量方式。** C
A.单链接
B.全链接
C.组平均
D.质心距离
**21.以下哪个算法是无监督学习算法( )** A
A. DBSCAN
B. RandomForestRegressor
C. KNN
D. SVC
**22.在使用sklearn的时候,我们经常使用train\_test\_split函数来切分数据集为训练数据和测试数据,该函数位于哪个模块( )** D
A. cluster
B. preprocessing
C. linear\_model
D. model\_selection
**23.以下哪个指标不是用来评估分类模型( )** C
A.准确率(Accuracy)
B.召回率(Recall)
C.轮廓系数(SilhouetteScore)
D. F1-score
**24. “点击率问题”是这样一个预测问题, 99%的人是不会点击的,而1%的人是会点击进去的,所以这是一个非常不平衡的数据集.假设,现在我们已经建了一个模型来分类,而且有了99%的预测准确率,我们可以下的结论是( )** C
A.模型预测准确率已经很高了,我们不需要做什么了
B.模型预测准确率不高,我们需要做点什么改进模型
C.无法下结论
D.以上都不对
**25.以下哪种算法是关联规则挖掘( )** B
A. SVC
B. FP-growth
C. OPTICS
D. PCA
**26.为了可以把多个评估器链接成一个整体,sklearn中提供了PipeLine机制,下面关于PipeLine描述不正确的是( )** A
A.管道中的最后一个评估器一定要是一个实现了predict方法的学习器
B.管道中的所有评估器,除了最后一个评估器,管道中的所有评估器必须都是转换器。
C.管道中的评估器参数可以通过\_\_语义来访问
D.管道中的评估器可以通过索引或名称访问
**27.在进行数据挖掘任务的时候,通常面临样本数据特征过多的情况,我们可以通过Filter过滤法选择那些对我们分析任务更有帮助的特征,下列方法哪个不是用来做特征过滤的( )** D
A.卡方检验
B. F检验
C.互信息法
D.奇异值分解
**28.关于频繁模式,下面哪一个陈述是正确的( ) C**
A. K项集频繁则K-1项则必定不频繁
B. K项集不频繁则K-1项则必定不频繁
C. K项集频繁则K-1项则必定频繁
D.以上说法都不正确
**29. NaiveBayes是Bayes分类器的一种,如特征变量是X,类别标签是C,它的假定是( )** C
A.各类别的先验概率P(C)是相等的
B. X服从以0为均值,1为标准差的正态分布
C.特征变量X的各个维度是类别条件独立随机变量
D. P(X|C)是高斯分布
**30. Pandas处理缺失值的函数有( )** A
A. fillna
B. iloc
C. fit
D. transform
**31.决 策 树 算 法 很 容 易 出 现 过 拟 合 , 我 们 通 常 会 使 用 一 些 剪 枝 手 段 来 改 善 这 一 现 象。 对 于sklearn.tree.DecisionTreeClassifier模型,下面这些参数哪个不能起到剪枝的作用( )** A
A. criterion
B. max\_depth
C. min\_samples\_split
D. min\_impurity\_split
**32.以下哪种算法是关联规则挖掘( )** C
A. SVC
B. KNN
C. Apriori
D. PCA
**33.如果一个分类模型经训练后,能在训练集上达到99%的准确率,但在测试集上仅能达到75%左右,这说明( )** B
A.欠拟合
B.过拟合
C.正常现象
D.模型选择不合适
**34.在sklearn中,下面哪个类或方法,位于preprocessing模块( )** B
A. train\_test\_split
B. LabelEncoder
C. accuracy\_score
D. DecisionTreeClassifier
**35.以下哪个指标不是用来评估回归模型( )** D
A. R2
B. MSE(Mean Squared Error)
C. MAE(Mean Absolute Error)
D. Recall
**36.逻辑回归适用于以下哪种问题 ( )** B
A.回归问题
B.二分类问题
C.聚类问题
D.关联规则
**37. Lasso回归与传统的线性回归最主要的区别是( )** A
A.增加L1正则项
B.增加L2正则项
C.无区别
D. Lasso回归是线性方程在sigmoid函数上的嵌套
**38.设有如下所示的某商场购物记录集合,每个购物篮中包含若干商品:**

**现在要基于该数据集进行关联规则挖掘。如果设置最小支持度为60%,则如下频繁项集中,符合条件的是()** A
A.啤酒,尿布
B.面包,尿布,牛奶
C.面包,牛奶
D.面包,啤酒,尿布
**39.数据的多重共线性导致我们无法使用最小二乘法求解线性回归问题,以下哪个算法从根本上解决了这一点( )** A
A. Ridge回归
B. Lasso回归
C.逻辑回归
D.多项式回归
**40.当数据样本的特征属性为自然数时,应采用以下那种算法进行分类( )** B
A.多项式朴素贝叶斯
B.高斯朴素贝叶斯
C.贝努利朴素贝叶斯
D. K均值算法
