[TOC]
## **1.概念**
**关联分析(Association analysis)**,最早用于分析超市中顾客一次购买的物品之间的关联性。发现大量数据中隐藏的关联性和相关性,进而描述出一个事物中某些属性同时出现的规律和模式,这些规律和模式即关联规则。
* 项、项集、k项集、频繁项集
* 支持度、置信度、提升度、杠杆率、确信度
* 关联规则、强关联规则
## **2.基本步骤**
(1)频繁项集的产生
产生所有支持度大于支持度阈值的项集
(2)强关联规则的产生
从频繁项集中产生高置信度的规则,即强关联规则
(3)寻找有用的强关联规则
## **3. Apriori**
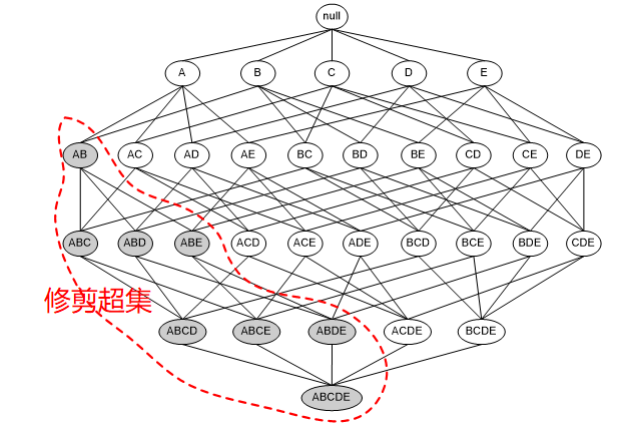
两条基本规则:
(1)如果一个集合是频繁项集,则它的所有子集都是频繁项集。
(2)如果一个集合不是频繁项集,则它的所有超集都不是频繁项集。
## **4. FP-Growth**
Han等人提出FP-Growth(频繁模式增长)算法,通过把交易集D中的信息压缩到一个FP(Frequent
Pattern)树结构中,可以在寻找频繁集的过程中不需要产生候选集,大大减少了扫描全库的次数,从而
大大提高了运算效率。
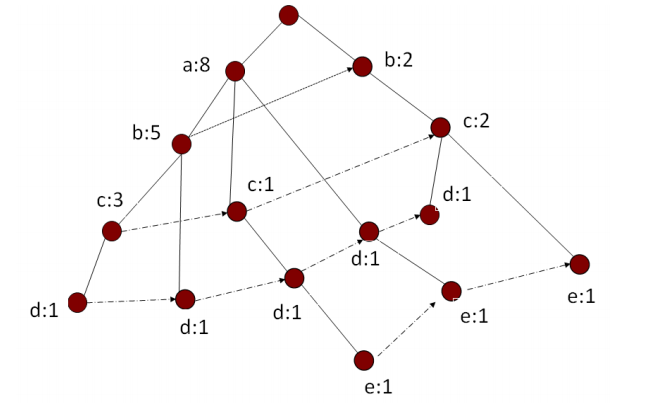
* 相比Apriori算法需要多次扫描数据库,FPGrowth只需要对数据库扫描2次。
* 第1次扫描获得单个项的频率,去掉不满足支持度要求的项,并对剩下的项排序。
* 第2次扫描,对于每条数据剔除非频繁1项集,并按照支持度降序排列。建立FP-Tree。
* 从FP-Tree中抽取频繁项集,但不能发现数据之间的关联规则
