[TOC]
## 单选题
1-5 BCBBA
6-10 BCACB
11-15 BABCC
16-20 AACBC
21-25 ADCCB
26-30 ADCCA
31-35 ACBBD
36-40 BA(AC)AB
## 多选题
1.AB
2.ABCD
3.ACD
4.BC
5.ABD
6.ACD
7.ACD
8.BCD
## 填空题
1.DataFrame   Series
2.信息增益率  基尼指数
3.频繁项集的获取   强关系规则的发现
4.回归  分类
5.松弛系数   核函数
6.梯度下降  最小二乘法
7.单词计数向量  TF-IDF
8. Eps   MinPts
9.特征的类条件独立假设
10.fit   transform
11.标签编码  独热编码
12.离散   连续
13.ceof_   feature_importances
14.用户   物品
15.梯度下降   最小二乘法
16.欧式距离   曼哈顿距离  闵科夫斯基距离
## 综合题
### 1.K-means算法步骤:
(1)为每个聚类选择一个初始聚类中心;
(2)将样本集按照最小距离原则分配到最邻近聚类;
(3)使用每个聚类的样本均值更新聚类中心;
(4)重复步骤(2)、(3),直到聚类中心不再发生变化;
(5)输出最终的聚类中心和k个簇划分;
**缺点与改进**:
(1)对于不是凸的数据集比较难收敛(改进:基于密度的聚类算法更加适合,比如DESCAN算法)
(2)对噪音和异常点比较的敏感(改进1:离群点检测的LOF算法,通过去除离群点后再聚类,可以减少离群点和孤立点对于聚类效果的影响;改进2:改成求点的中位数,这种聚类方式即K-Mediods聚类(K中值))。
(3)初始聚类中心的选择(改进1:k-means++;改进2:二分K-means)
### 2.KNN算法的步骤:
1)计算已知类别数据集中的点与当前点的距离;
2)按距离递增次序排序;
3)选取与当前点距离最小的k个点;
4)统计前k个点所在的类别出现的频率;
5)返回前k个点出现频率最高的类别作为当前点的预测分类;
### 3.四个分类算法,简单介绍算法原理
1)K邻近算法(KNN): 所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表
2)决策树:找到具有决定性作用的特征,根据其决定性作用最大的那个特征作为根节点,然后递归找到各分支下子数据集中次大的决定性特征,直至子数据集中所有数据都属于同一类。
3)朴素贝叶斯:对于给出的待分类项,求解在此项出现的个条件各个类别出现的概率,哪个最大,就认为此分类项属于哪个类别。
4)支持向量机:是寻找一个超平面来对样本进行 分割,分割的原则是间隔最大化,最终转化为一个凸二次规划问题来求解
### 4.下表给出了一组数据的相似矩阵
1).使用单链接(MIN)方式进行层次聚类,请画出对应的树状图。
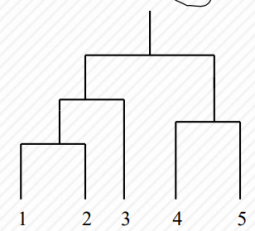
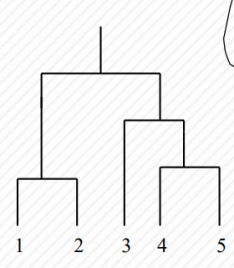
2). 使用全链接(MAX)方式进行层次聚类,请画出对应的树状图。
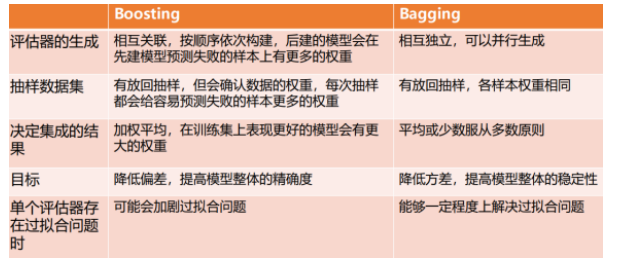
### 5. 请对比分析boosting和bagging。
### 6. 请简述数据挖掘的整个过程。
商业理解、数据理解、数据准备 建模 评价 部署
### 7. 请谈谈你对特征工程的理解。
最大限度地从原始数据进行预处理然后从中提取特征以供算法和模型使用
### 8. 请简述什么是过拟合问题、产生的原因有哪些以及解决过拟合的办法。
什么是过拟合问题:
过拟合是指模型过分的拟合训练样本,但对测试样本预测准确率不高的情况,也就是说模型泛化能力很差
原因:
(1)数据特征的角度
数据噪声导致的过拟合
缺乏代表性样本导致的过拟合:
(2)模型的角度
模型过度复杂,
过拟合的可能解决方法:
a、减少特征:
b、正则化:
c、得到更多的训练样本
d、迁移学习\-----可以解决由于训练数据较小引起的过拟合。
