
[TOC]
# 数据模型
## 主流模型
### 1. 关系数据库:
<span style='color:blue;background:#ff0;'>关系数据模型</span>通常使用关系数据库进行存储,例如MySQL,Oracle,PostgreSQL等。这些数据库使用表格来表示数据,并使用SQL语言进行查询和操作。关系数据库适用于需要支持事务处理和数据一致性的应用场景。
``````
# 在该模型中,电影库包含多个电影,每个电影有多个演员和多个评论,同时每个评论和电影之间存在评分的关系。
+---------+ +----------+ +--------+
| Movie | | Actor | | Review |
+---------+ +----------+ +--------+
| id | | id | | id |
| title | | name | | movie_id |
| genre | | age | | reviewer|
| release | | movies |<--------| rating |
| reviews |<----------| | | comment|
+---------+ +----------+ +--------+
# 使用Movie类来表示电影的数据结构,其中包含电影ID、电影名称、电影类型、上映日期和评论列表等字段。使用Actor类来表示演员的数据结构,其中包含演员ID、演员姓名、演员年龄和参演电影列表等字段。使用Review类来表示评论的数据结构,其中包含评论ID、电影ID、评价人、评分和评论等字段。
``````
*****
### 2. 对象数据库:
<span style='color:blue;background:#ff0;'>物件模型</span>通常使用对象数据库进行存储,例如`db4o,Versant,ObjectDB`等。这些数据库使用类和对象来表示数据,并支持面向对象的查询语言。对象数据库适用于需要高度灵活性和可扩展性的应用场景。
``````
# 汽车销售系统包含多个车型,每个车型有多个配置,每个配置又包含多个零配件。同时,每个车型和配置都可以被多个订单所使用。
+--------------+ +----------+
| CarSales | | CarModel 车型 |
+--------------+ +----------+
| name | | name |
| description |-----------| price |
| models | | options |
+--------------+
+-----------+ +---------+
| CarModel | | Option 配置|
+-----------+ +---------+
| name | | name |
| price |------------| price |
| options | | parts |
| orders | +---------+
+-----------+
+---------+ +---------+
| Option | | Part 零件 |
+---------+ +---------+
| name | | name |
| price |------------| price |
| parts | | supplier|
+---------+ +---------+
+---------+ +----------+
| Order | | Customer |
+---------+ +----------+
| orderNo | | name |
| date |-----------| email |
| model | | orders |
+---------+ +----------+
``````
*****
### 3. 图数据库:
<span style='color:blue;background:#ff0;'>无向图数据模型</span>通常使用图数据库进行存储,例如Neo4j,ArangoDB,OrientDB等。这些数据库使用节点和边来表示数据,并支持图形查询和遍历。图数据库适用于需要处理复杂关系和大量数据的应用场景.
``````
# 在该模型中,社交网络由多个用户组成,每个用户可以与其他用户建立双向的关注关系。
+-------+ +-------+
| Graph | | User |
+-------+ +-------+
| nodes | | name |
| edges |<-------| posts |
+-------+ | likes |
+-------+
# 使用Graph类来表示无向图的数据结构,其中包含节点和边列表等字段。使用User类来表示社交网络中的用户,其中包含用户姓名、帖子列表和点赞列表等字段。使用箭头来表示类之间的关系和依赖,
``````
*****
### 4. 多重关系数据模型:
<span style='color:blue;background:#ff0;'>多重关系数据模型</span>通常使用关系数据库进行存储,例如MySQL,Oracle,PostgreSQL等。这些数据库使用表格来表示数据,并使用SQL语言进行查询和操作。此外,一些图数据库也支持多重关系数据模型,例如Neo4j。
``````
# 在该模型中,一个在线商店包含多个商品,每个商品属于一个类别,有多个客户可以购买多个商品,每个客户有多个订单。同时,每个订单包含多个商品和一个客户。
+-------------+ +----------+
| OnlineShop | | Category |
+-------------+ +----------+
| name | | name |
| description |------------| products |
| categories | +----------+
+-------------+
+----------+ +----------+
| Category | | Product |
+----------+ +----------+
| name | | name |
| products |------------| price |
+----------+ | category |
+----------+
+---------+ +----------+
| Customer| | Order |
+---------+ +----------+
| name | | orderNo |
| email | | date |
| orders |------------| customer|
+---------+ | products |
+----------+
``````
*****
### 5. Hierarchical (hier) 数据模型:
<span style='color:blue;background:#ff0;'>Hierarchical数据模型(树状)</span>通常使用层次数据库进行存储,例如IMS,IDMS等。这些数据库使用树形结构来表示数据,其中每个节点都具有一个父节点和零个或多个子节点。此外,一些关系数据库也支持Hierarchical数据模型,例如Oracle。
``````
# 在该模型中,组织机构由多个部门组成,每个部门包含多个员工。每个员工又拥有自己的属性,例如姓名、职位、工资等。
+------------------+ +------------+
| Organization | | Department |
+------------------+ +------------+
| name | | name |
| address |-----------| employees |
| phone | +------------+
| departments |
+------------------+
+-------------+ +-----------+
| Department | | Employee |
+-------------+ +-----------+
| name | | name |
| employees |-----------| position |
+-------------+ | salary |
| hireDate |
+-----------+
# 层次模型 Organization组织 -》Department部门 -》 Employee员工
# 使用Organization类来表示组织机构的数据结构,其中包含名称、地址、电话等字段,以及与部门相关的部门列表。
# 使用Department类来表示部门的数据结构,其中包含名称和员工列表等字段。
# 使用Employee类来表示员工的数据结构,其中包含姓名、职位、工资、入职日期等字段。
``````
*****
### 6. 文件数据模型(CSV,JSON,XML files , etc.):
<span style='color:blue;background:#ff0;'>文件数据模型</span>通常使用文件系统或NoSQL数据库进行存储,例如MongoDB,Couchbase等。这些数据库可以存储和管理各种文件格式的数据,例如CSV,JSON和XML文件。此外,一些关系数据库也支持文件数据模型,例如PostgreSQL。
``````
# 在该模型中,一个电影包含标题、导演、演员、评分等属性,同时与电影类型和上映时间等信息相关联。
+-------------+ +-------------+
| Movie | | Type |
+-------------+ +-------------+
| title | | name |
| director |------------| description|
| actors | +-------------+
| rating | | movies |
| type |<-----------| |
| releaseDate | +-------------+
+-------------+
# 使用箭头来表示Movie类依赖于Type类,并使用Type对象来表示电影类型和电影列表的关系。
``````
*****
## 其它模型
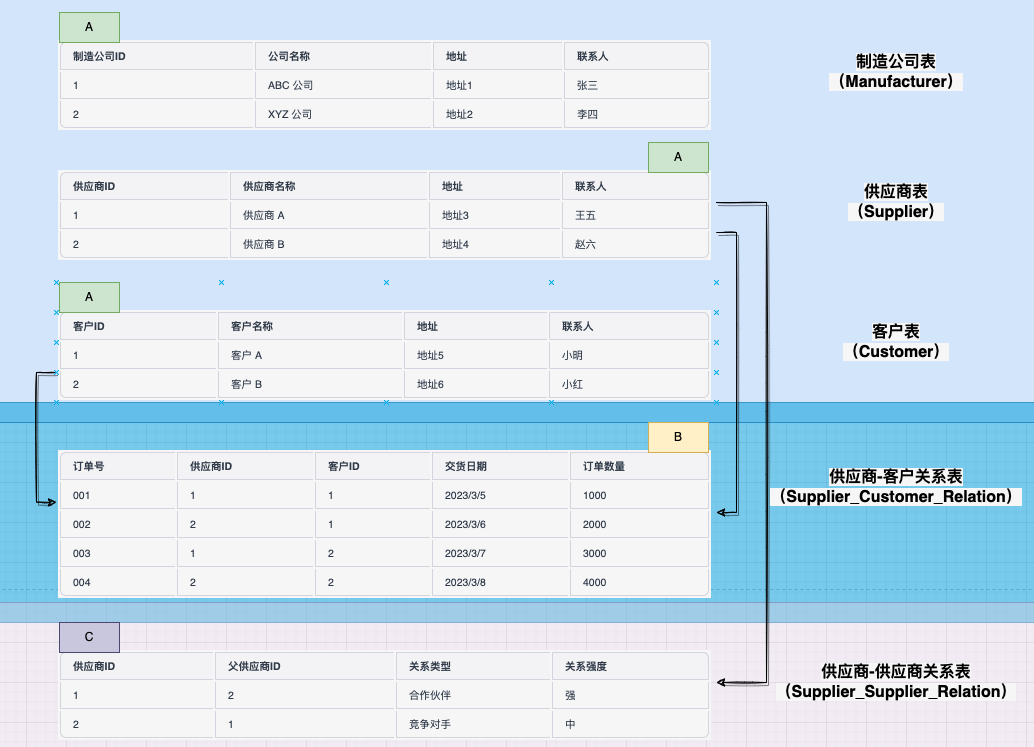
### 1. 网状数据模型
``````
# 在该模型中,电影推荐系统包含多个用户和多个电影,每个用户可以看多个电影,每个电影也可以被多个用户看。同时,每个电影还包含多个演员和多个导演,每个演员和导演也可以参演多个电影。
+--------+ +---------+ +--------+
| User | | Movie | | Person |
+--------+ +---------+ +--------+
| id | | id | | id |
| name | | title | | name |
| gender | | genre |<-----| type |
| age | | actors()|----->| movies()|
| movies |<------->| | +--------+
+--------+ | |
| |
| |
| |
+---------+
# 使用User类来表示用户的数据结构,其中包含用户ID、用户名、用户性别和用户年龄等字段。
# 使用Movie类来表示电影的数据结构,其中包含电影ID、电影标题、电影类型和电影演员列表等字段。
# 使用Person类来表示演员和导演的数据结构,其中包含人员ID、人员姓名、人员类型和参演电影列表等字段。
``````
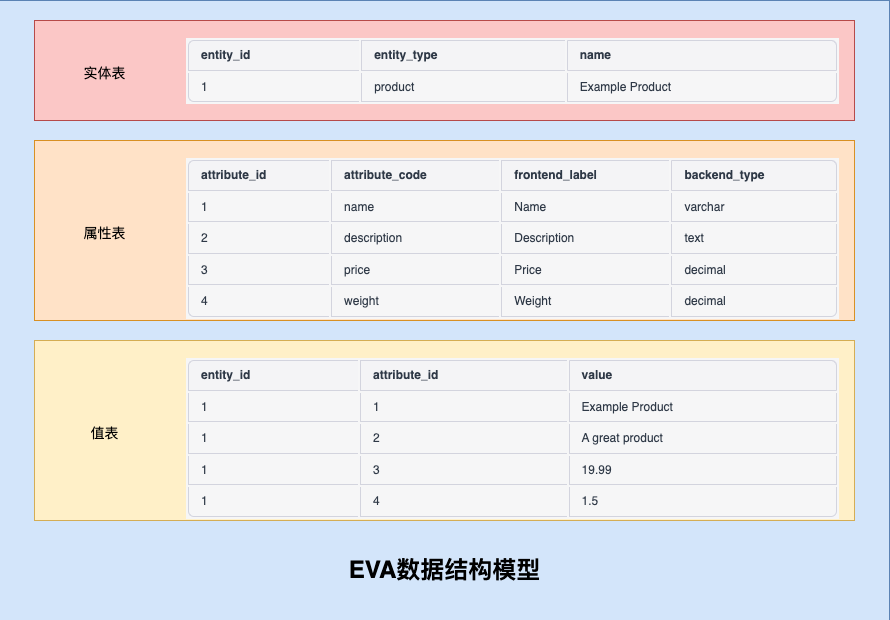
### 2. EVA数据模型——面向对象模型
``````
# 在该模型中,电商平台包含多个产品,每个产品有多个属性和多个属性值,同时每个属性和属性值之间存在关联关系。
+---------+ +------------+ +-------------+
| Product | | Attribute | | Value |
+---------+ +------------+ +-------------+
| id | | id | | id |
| name | | name | | value |
| type | | type | | attribute |
| price |<--------->| values() |<-------->| product_id |
| size | | product_id | +-------------+
| color | +------------+
+---------+
# 使用Product类来表示产品的数据结构,其中包含产品ID、产品名称、产品类型、产品价格和属性列表等字段。
# 使用Attribute类来表示属性的数据结构,其中包含属性ID、属性名称、属性类型和对应的属性值列表等字段。
# 使用Value类来表示属性值的数据结构,其中包含属性值ID、属性值名称和对应的属性ID和产品ID等字段。
``````
### 3. ——面向切面模型
#### 1). 数据拦截器(Data Interceptor)模型:
数据拦截器模型是一种将横切关注点嵌入到数据访问层的数据模型。在该模型中,拦截器可以截获和处理数据层面的操作,
例如查询、插入、更新和删除等,从而实现对数据的审计、性能优化和安全控制等功能。Hibernate、Entity Framework是一个使用数据拦截器模型的ORM框架。
``````
# 在该模型中,电商平台包含多个数据源,例如用户信息、订单信息、支付信息等。数据拦截器可以对这些数据源进行拦截和处理,并提供一些数据加工的功能,例如数据过滤、数据转换、数据聚合等。
+----------------+ +--------------+ +-----------------+
| DataInterceptor| | DataSource | | DataProcessor |
+----------------+ +--------------+ +-----------------+
| intercept() |<>------->| getData() |<--------| process() |
| filter() | | | | transform() |
| transform() | | | | aggregate() |
+----------------+ +--------------+ +-----------------+
# 使用DataInterceptor类来表示数据拦截器的数据结构,其中包含拦截、过滤和转换等方法。
# 使用DataSource类来表示数据源的数据结构,其中包含获取数据的方法。
# 使用DataProcessor类来表示数据处理器的数据结构,其中包含处理、转换和聚合等方法。
``````
>Java:
``````
# 定义一个拦截器类,继承自Hibernate的Interceptor类。在该类中,可以重写多个拦截器方法,例如onFlushDirty(),用于在更新操作之前截获和处理更新请求。
public class AuditInterceptor extends EmptyInterceptor {
@Override
public boolean onFlushDirty(Object entity, Serializable id, Object[] currentState, Object[] previousState, String[] propertyNames, Type[] types) {
if (entity instanceof User) {
// 获取当前用户
User currentUser = getCurrentUser();
// 记录用户更新操作
AuditLog log = new AuditLog();
log.setUserId(currentUser.getId());
log.setOperation("update");
log.setEntity("User");
log.setEntityId(id.toString());
log.setTimestamp(new Date());
// 保存操作记录
saveAuditLog(log);
}
return super.onFlushDirty(entity, id, currentState, previousState, propertyNames, types);
}
// 获取当前用户
private User getCurrentUser() {
// TODO: 从当前会话中获取当前用户
return null;
}
// 保存操作记录
private void saveAuditLog(AuditLog log) {
// TODO: 将操作记录保存到数据库中
}
}
# 然后,在使用Hibernate进行数据库操作时,需要将拦截器类传递给SessionFactory对象,以便Hibernate在进行数据更新操作时调用拦截器方法。
Configuration configuration = new Configuration();
configuration.setInterceptor(new AuditInterceptor());
SessionFactory sessionFactory = configuration.buildSessionFactory();
Session session = sessionFactory.openSession();
// 更新用户信息
User user = session.get(User.class, 1L);
user.setName("New Name");
session.update(user);
session.close();
``````
#### 2). 数据管道(Data Pipeline)模型:
数据管道模型是一种将横切关注点嵌入到数据流程中的数据模型。在该模型中,数据管道可以对数据进行预处理、转换、验证和过滤等操作,从而实现对数据的清洗和转换等功能。Apache Beam是一个使用数据管道模型的分布式数据处理框架。
``````
# 在该模型中,数据处理系统包含多个数据处理单元,每个数据处理单元可以处理数据并将其传递给下一个数据处理单元。数据管道模型可以按照一定的顺序和规则,对数据进行处理、转换、聚合等操作,并输出最终的结果。
+----------+ +----------+ +----------+
| DataSource| | Processor| | Sink |
+----------+ +----------+ +----------+
| getData()|-------->| process()|------->| write() |
+----------+ | | +----------+
+----------+
# 在以上示例中,使用DataSource类来表示数据源的数据结构,其中包含获取数据的方法。使用Processor类来表示数据处理单元的数据结构,其中包含处理、转换和聚合等方法。使用Sink类来表示数据输出单元的数据结构,其中包含将数据写入输出目标的方法。
``````
>Java:
``````
# 1. 首先,需要定义一个管道类,使用Apache Flink提供的StreamExecutionEnvironment类来创建数据管道,并定义一系列数据处理步骤。在该类中,可以使用Flink提供的多个转换函数和操作函数,例如map(),用于对数据进行转换和操作。
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class UserBehaviorPipeline {
private final String inputTopic;
private final String outputTopic;
public UserBehaviorPipeline(String inputTopic, String outputTopic) {
this.inputTopic = inputTopic;
this.outputTopic = outputTopic;
}
public void run() throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 从Kafka主题中读取用户行为数据
FlinkKafkaConsumer<String> consumer = new FlinkKafkaConsumer<>(inputTopic, new SimpleStringSchema(), properties);
DataStream<String> userBehavior = env.addSource(consumer);
// 转换用户行为数据
DataStream<UserEvent> userEvents = userBehavior
.map(new ExtractFields())
.filter(new FilterEvents())
.assignTimestampsAndWatermarks(new AscendingTimestampExtractor<UserEvent>() {
@Override
public long extractAscendingTimestamp(UserEvent element) {
return element.getTimestamp();
}
});
// 实时处理用户行为数据
DataStream<Recommendation> recommendations = userEvents
.keyBy(UserEvent::getUserId)
.timeWindow(Time.minutes(10))
.process(new RecommendationProcessFunction());
// 将推荐结果写入到Kafka主题中
FlinkKafkaProducer<String> producer = new FlinkKafkaProducer<>(outputTopic, new SimpleStringSchema(), properties);
recommendations.map(Recommendation::toJsonString).addSink(producer);
env.execute("UserBehaviorPipeline");
}
}
# 2. 然后,可以定义自定义的数据转换函数和操作函数,例如ExtractFields()和FilterEvents()函数。这些函数可以根据具体的业务需求进行自定义实现。
public class ExtractFields implements MapFunction<String, UserEvent> {
@Override
public UserEvent map(String value) throws Exception {
// 解析JSON格式的用户行为数据
JsonObject data = JsonParser.parseString(value).getAsJsonObject();
// 提取用户行为数据中的关键字段
long userId = data.get("user_id").getAsLong();
String eventType = data.get("event_type").getAsString();
long timestamp = data.get("timestamp").getAsLong();
return new UserEvent(userId, eventType, timestamp);
}
}
public class FilterEvents implements FilterFunction<UserEvent> {
@Override
public boolean filter(UserEvent value) throws Exception {
// 过滤掉无用的事件
return value.getEventType().equals("click") || value.getEventType().equals("add_to_cart") || value.getEventType().equals("purchase");
}
}
# 3. 最后,在启动管道时,需要传递输入和输出主题的名称,并调用run()方法启动数据管道的执行。
String inputTopic = "[INPUT_TOPIC_NAME]";
String outputTopic = "[OUTPUT_TOPIC_NAME]";
UserBehaviorPipeline pipeline= new UserBehaviorPipeline(inputTopic, outputTopic);
pipeline.run();
``````
#### 3). 数据代理(Data Proxy)模型:
数据代理模型是一种将横切关注点嵌入到数据访问代理中的数据模型。在该模型中,数据代理可以截获和处理数据的访问请求,例如读取和写入操作,从而实现对数据的缓存、路由和安全控制等功能。MyBatis是一个使用数据代理模型的ORM框架。
``````
# 在该模型中,数据管理系统包含多个数据源和多个客户端,数据代理可以作为中介,协调数据源和客户端之间的数据访问和交互。数据代理可以提供一些数据管理的功能,例如数据缓存、数据验证、数据加密等。
+----------------+ +--------------+ +-----------------+
| DataProxy | | DataSource | | Client |
+----------------+ +--------------+ +-----------------+
| cache() |<>------->| getData() |<--------| request() |
| validate() | | | | handleResponse()|
| encrypt() | | | | |
+----------------+ +--------------+ +-----------------+
# 使用DataProxy类来表示数据代理的数据结构,其中包含缓存、验证和加密等方法。使用DataSource类来表示数据源的数据结构,其中包含获取数据的方法。使用Client类来表示客户端的数据结构,其中包含请求数据和处理响应的方法。
``````
>Java:
``````
# 首先,需要定义一个代理类,使用Spring Boot提供的RestController注解来创建Web服务器,并定义一系列路由和数据处理函数。在该类中,可以使用多个Java库和工具,例如Retrofit、OkHttp、Gson等,来进行数据处理和控制操作。
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class DeviceDataProxy {
private final String deviceServiceUrl;
public DeviceDataProxy(String deviceServiceUrl) {
this.deviceServiceUrl = deviceServiceUrl;
}
@PostMapping("/device_data")
public String handleDeviceData(@RequestBody String deviceData) throws IOException {
// 向设备服务发送数据请求
OkHttpClient client = new OkHttpClient();
RequestBody body = RequestBody.create(MediaType.parse("application/json"), deviceData);
Request request = new Request.Builder()
.url(deviceServiceUrl)
.post(body)
.build();
Response response = client.newCall(request).execute();
// 返回设备服务的响应结果
return response.body().string();
}
}
# 最后,在启动数据代理时,需要传递代理的地址和端口,并调用run()方法启动Web服务器的执行。
String deviceServiceUrl = "[DEVICE_SERVICE_URL]";
int port = [PORT];
DeviceDataProxy deviceDataProxy = new DeviceDataProxy(deviceServiceUrl);
SpringApplication app = new SpringApplication(DeviceDataProxy.class);
app.setDefaultProperties(Collections.singletonMap("server.port", port));
app.run();
``````
- 系统设计
- 需求分析
- 概要设计
- 详细设计
- 逻辑模型设计
- 物理模型设计
- 产品设计
- 数据驱动产品设计
- 首页
- 逻辑理解
- 微服务架构的关系数据库优化
- Java基础架构
- 编程范式
- 面向对象编程【模拟现实】
- 泛型编程【参数化】
- 函数式编程
- 响应式编程【异步流】
- 并发编程【多线程】
- 面向切面编程【代码复用解耦】
- 声明式编程【注解和配置】
- 函数响应式编程
- 语法基础
- 包、接口、类、对象和切面案例代码
- Springboot按以下步骤面向切面设计程序
- 关键词
- 内部类、匿名类
- 数组、字符串、I/O
- 常用API
- 并发包
- XML
- Maven 包管理
- Pom.xml
- 技术框架
- SpringBoot
- 项目文件目录
- Vue
- Vue项目文件目录
- 远程组件
- 敏捷开发前端应用
- Pinia Store
- Vite
- Composition API
- uniapp
- 本地方法JNI
- 脚本机制
- 编译器API
- 注释
- 源码级注释
- Javadoc
- 安全
- Swing和图形化编程
- 国际化
- 精实或精益
- 精实软件数据库设计
- 精实的原理与方法
- 项目
- 零售软件
- 扩展
- 1001_docker 示例
- 1002_Docker 常用命令
- 1003_微服务
- 1004_微服务数据模型范式
- 1005_数据模型
- 1006_springCloud
- AI 流程图生成
- Wordpress_6
- Woocommerce_7
- WooCommerce常用的API和帮助函数
- WooCommerce的钩子和过滤器
- REST API
- 数据库API
- 模板系统
- 数据模型
- 1.Woo主题开发流程
- Filter
- Hook
- 可视编辑区域的函数工具
- 渲染字段函数
- 类库和框架
- TDD 通过测试来驱动开发
- 编程范式对WordPress开发
- WordPress和WooCommerce的核心代码类库组成
- 数据库修改
- 1.WP主题开发流程与时间规划
- moho
- Note 1
- 基础命令