
[TOC]
## 架构
SQLite采用了模块的设计,它由三个子系统,包括8个独立的模块构成。
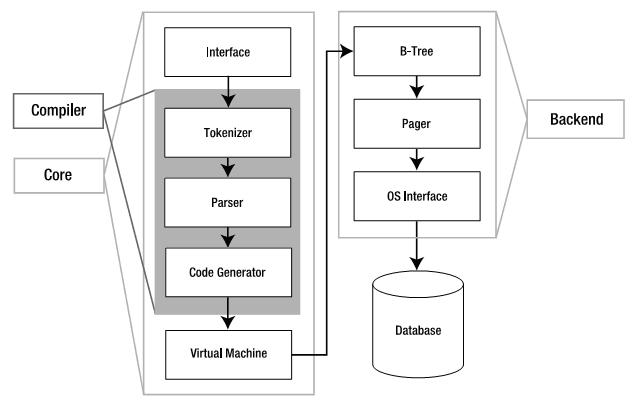
### 接口(Interface)
接口由SQLite C API组成,也就是说不管是程序、脚本语言还是库文件,最终都是通过它与SQLite交互的(我们通常用得较多的ODBC/JDBC最后也会转化为相应C API的调用)。
### 编译器(Compiler)
在编译器中,分词器(Tokenizer)和分析器(Parser)对SQL进行语法检查,然后把它转化为底层能更方便处理的分层的数据结构---语法树,然后把语法树传给代码生成器(code generator)进行处理。而代码生成器根据它生成一种针对SQLite的汇编代码,最后由虚拟机(Virtual Machine)执行。
### 虚拟机(Virtual Machine)
架构中最核心的部分是虚拟机,或者叫做虚拟数据库引擎(Virtual Database Engine,VDBE)。它和Java虚拟机相似,解释执行字节代码。VDBE的字节代码由128个操作码(opcodes)构成,它们主要集中在数据库操作。它的每一条指令都用来完成特定的数据库操作(比如打开一个表的游标)或者为这些操作栈空间的准备(比如压入参数)。总之,所有的这些指令都是为了满足SQL命令的要求(关于VM,后面会做详细介绍)。
### 后端(Back-End)
后端由B-树(B-tree),页缓存(page cache,pager)和操作系统接口(即系统调用)构成。B-tree和page cache共同对数据进行管理。B-tree的主要功能就是索引,它维护着各个页面之间的复杂的关系,便于快速找到所需数据。而pager的主要作用就是通过OS接口在B-tree和Disk之间传递页面。
SQLite由很多部分组成-parser,tokenize,virtual machine等等。但是从程序员的角度,最需要知道的是:connection, statements, B-tree和pager
## API层
由两部分组成: 核心API(core API) 和扩展API(extension API)
核心API的函数实现基本的数据库操作:连接数据库,处理SQL,遍历结果集。它也包括一些实用函数,比如字符串转换,操作控制,调试和错误处理。
扩展API通过创建你自定义的SQL函数去扩展SQLite。

### Connection
一个连接(Connection)代表在一个独立的事务环境下的一个连接A
### Statements
每一个statement都和一个connection关联,它通常表示一个编译过的SQL语句,在内部,它以VDBE字节码表示。Statement包括执行一个命令所需要一切,包括保存VDBE程序执行状态所需的资源,指向硬盘记录的B-树游标,以及参数等等。
### Transaction
一个连接(connection)可以包含多个(statement),而且每个连接有一个与数据库关联的B-tree和一个pager。Pager在连接中起着很重要的作用,因为它管理事务、锁、内存缓存以及负责崩溃恢复(crash recovery)。当你进行数据库写操作时,记住最重要的一件事:在任何时候,只在一个事务下执行一个连接。
一个事务的生命和statement差不多,你也可以手动结束它。默认情况下,事务自动提交,当然你也可以通过BEGIN..COMMIT手动提交。接下来就是锁的问题。
### 锁的状态
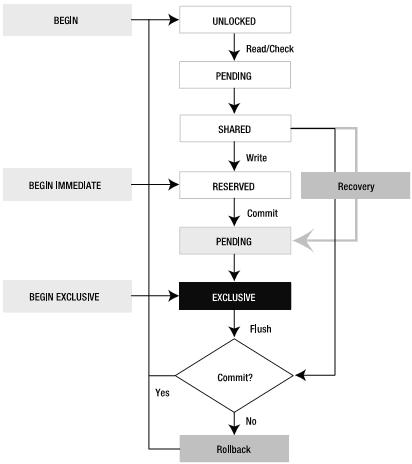
关于这个图有以下几点值得注意:
一个事务可以在UNLOCKED,RESERVED或EXCLUSIVE三种状态下开始。默认情况下在UNLOCKED时开始。
白色框中的UNLOCKED, PENDING, SHARED和 RESERVED可以在一个数据库的同一时存在。
从灰色的PENDING开始,事情就变得严格起来,意味着事务想得到排斥锁(EXCLUSIVE)(注意与白色框中的区别)。
//1. 【读】会获取到SHARED锁 ;【写page】会获取到RESERVED锁
//2. SQLite可以高效的处理在同一时刻的多个读连接和一个写连接。
//3. page要写入数据库文件时,会先去获取EXCLUSIVE锁(排斥锁)
虽然锁有这么多状态,但是从体质上来说,只有两种情况:读事务和写事务。
#### 读事务
~~~
db = open('foods.db')
db.exec('BEGIN')
db.exec('SELECT * FROM episodes')
db.exec('SELECT * FROM episodes')
db.exec('COMMIT')
db.close()
~~~
由于显式的使用了BEGIN和COMMIT,两个SELECT命令在一个事务下执行。第一个exec()执行时,connection处于SHARED,然后第二个exec()执行,当事务提交时,connection又从SHARED回到UNLOCKED状态,如下:
UNLOCKED→PENDING→SHARED→UNLOCKED
如果没有BEGIN和COMMIT两行时如下:
UNLOCKED→PENDING→SHARED→UNLOCKED→PENDING→ SHARED→UNLOCKED
## 后端
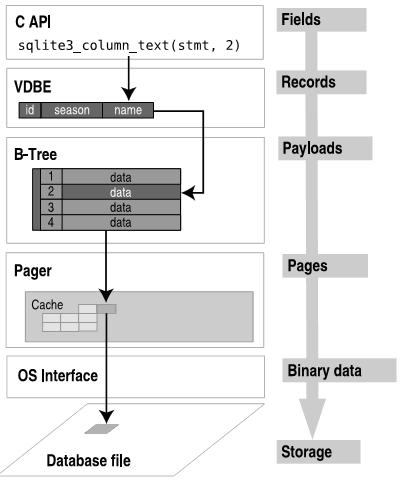
### B-tree
B-Tree使得VDBE可以在**O(logN)**下查询,插入和删除数据,以及O(1)下双向遍历结果集。B-Tree不会直接读写磁盘,它仅仅维护着页面(pages)之间的关系。当B-TREE需要页面或者修改页面时,它就会调用Pager。当修改页面时,pager保证原始页面首先写入日志文件,当它完成写操作时,pager根据事务状态决定如何做。B-tree不直接读写文件,而是通过page cache这个缓冲模块读写文件对于性能是有重要意义的。
B-tree中页面由B-tree记录组成,也叫做payloads。每一个B-tree记录,或者payload有两个域:**关键字域(key field)和数据域(data field)**。**Key field就是ROWID的值,或者数据库中表的关键字的值。从B-tree的角度,data field可以是任何无结构的数据。**数据库的记录就保存在这些data fields中。B-tree的任务就是排序和遍历,它最需要就是关键字。Payloads的大小是不定的,这与内部的关键字和数据域有关,当一个payload太大不能存在一个页面内进便保存到多个页面。
### Page Cache事务处理
pager层是SQLite实现最为核心的模块,它具有四大功能:I/O,页面缓存,并发控制和日志恢复。而这些功能不仅是上层Btree的基础,而且对系统的性能和健壮性有关至关重要的影响。其中并发控制和日志恢复是事务处理实现的基础。SQLite并发控制的机制非常简单——封锁机制;别外,它的查询优化机制也非常简单——基于索引。
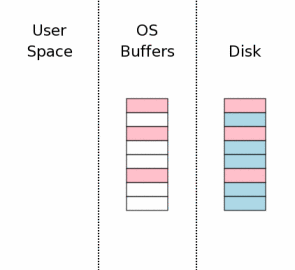
#### 初始状态
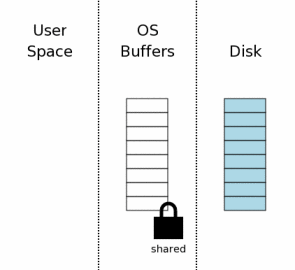
当一个数据库连接第一次打开时,状态如图所示。图中最右边(“Disk”标注)表示保存在存储设备中的内容。每个方框代表一个扇区。蓝色的块表示这个扇区保存了原始数据。图中中间区域是操作系统的磁盘缓冲区。开始的时候,这些缓存是还没有被使用,因此这些方框是空白的。图中左边区域显示SQLite用户进程的内存。因为这个数据库连接刚刚打开,所以还没有任何数据记录被读入,所以这些内存也是空的。
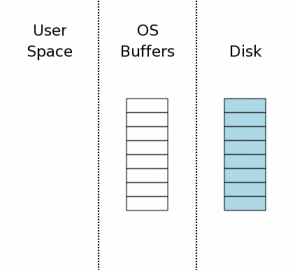
#### 获取读锁
在SQLite写数据库之前,它必须先从数据库中读取相关信息。比如,在插入新的数据时,SQLite会先从sqlite\_master表中读取数据库模式(相当于数据字典),以便编译器对INSERT语句进行分析,确定数据插入的位置。
在进行读操作之前,必须先获取数据库的共享锁(shared lock),共享锁允许两个或更多的连接在同一时刻读取数据库。但是共享锁不允许其它连接对数据库进行写操作
shared lock存在于操作系统磁盘缓存,而不是磁盘本身。文件锁的本质只是操作系统的内核数据结构,当操作系统崩溃或掉电时,这些内核数据也会随之消失。
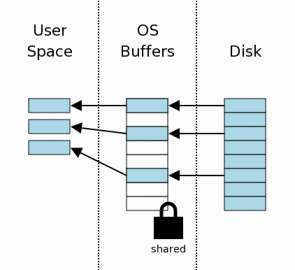
#### 读取数据
一旦得到shared lock,就可以进行读操作。如图所示,数据先由OS从磁盘读取到OS缓存,然后再由OS移到用户进程空间。一般来说,数据库文件分为很多页,而一次读操作只读取一小部分页面。如图,从8个页面读取3个页面
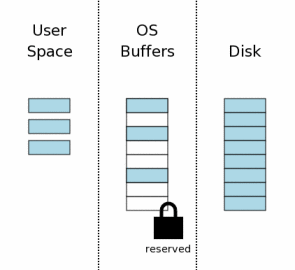
#### 获取Reserved Lock
在对数据进行修改操作之前,先要获取数据库文件的Reserved Lock,Reserved Lock和shared lock的相似之处在于,它们都允许其它进程对数据库文件进行读操作。Reserved Lock和Shared Lock可以共存,但是只能是一个Reserved Lock和多个Shared Lock——多个Reserved Lock不能共存。所以,在同一时刻,只能进行一个写操作。
Reserved Lock意味着当前进程(连接)想修改数据库文件,但是还没开始修改操作,所以其它的进程可以读数据库,但不能写数据库
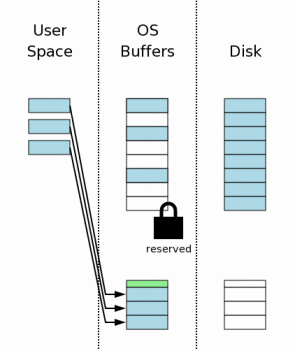
#### 创建恢复日志(Creating A Rollback Journal File)
在对数据库进行写操作之前,SQLite先要创建一个单独的日志文件,然后把要修改的页面的原始数据写入日志。回滚日志包含一个日志头(图中的绿色)——记录数据库文件的原始大小。所以即使数据库文件大小改变了,我们仍知道数据库的原始大小。
从OS的角度来看,当一个文件创建时,大多数OS(Windows,Linux,Mac OS X)不会向磁盘写入数据,新创建的文件此时位于磁盘缓存中,之后才会真正写入磁盘。如图,日志文件位于OS磁盘缓存中,而不是位于磁盘。
#### 修改位于用户进程空间的页面(Changing Database Pages In User Space)
页面的原始数据写入日志之后,就可以修改页面了——位于用户进程空间。每个数据库连接都有自己私有的空间,所以页面的变化只对该连接可见,而对其它连接的数据仍然是磁盘缓存中的数据。从这里可以明白一件事:一个进程在修改页面数据的同时,其它进程可以继续进行读操作。图中的红色表示修改的页面。
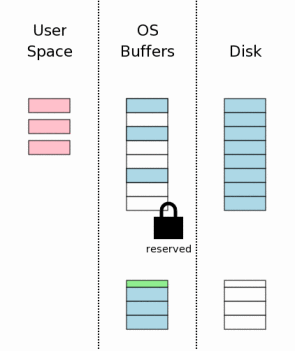
#### 日志文件刷入磁盘(Flushing The Rollback Journal File To Mass Storage)
接下来把日志文件的内容刷入磁盘,这对于数据库从意外中恢复来说是至关重要的一步。而且这通常也是一个耗时的操作,因为磁盘I/O速度很慢。
这个步骤不只把日志文件刷入磁盘那么简单,它的实现实际上分成两步:首先把日志文件的内容刷入磁盘(即页面数据);然后把日志文件中页面的数目写入日志文件头,再把header刷入磁盘(这一过程在代码中清晰可见)。
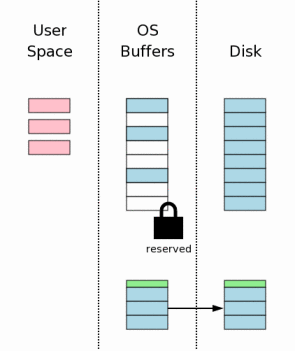
#### 获取排斥锁(Obtaining An Exclusive Lock)
在对数据库文件进行修改之前(注:这里不是内存中的页面),我们必须得到数据库文件的排斥锁(Exclusive Lock)。得到排斥锁的过程可分为两步:首先得到Pending lock;然后Pending lock升级到exclusive lock。
Pending lock允许其它已经存在的Shared lock继续读数据库文件,但是不允许产生新的shared lock,这样做目的是为了防止写操作发生饿死情况。一旦所有的shared lock完成操作,则pending lock升级到exclusive lock。
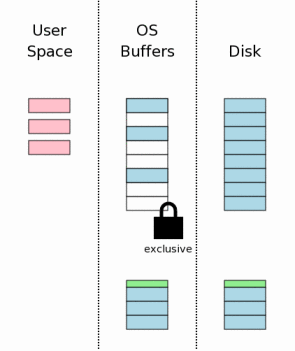
#### 修改的页面写入文件(Writing Changes To The Database File)
一旦得到exclusive lock,其它的进程就不能进行读操作,此时就可以把修改的页面写回数据库文件,但是通常OS都把结果暂时保存到磁盘缓存中,直到某个时刻才会真正把结果写入磁盘。
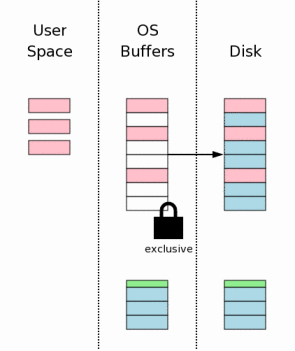
#### 修改结果刷入存储设备(Flushing Changes To Mass Storage)
为了保证修改结果真正写入磁盘,这一步必不要少。对于数据库存的完整性,这一步也是关键的一步。由于要进行实际的I/O操作,所以和第7步一样,将花费较多的时间

#### 删除日志文件(Deleting The Rollback Journal)
一旦更改写入设备,日志文件将会被删除,这是事务真正提交的时刻。如果在这之前系统发生崩溃,就会进行恢复处理,使得数据库和没发生改变一样;如果在这之后系统发生崩溃,表明所有的更改都已经写入磁盘。SQLite就是根据日志存在情况决定是否对数据库进行恢复处理。
删除文件本质上不是一个原子操作,但是从用户进程的角度来看是一个原子操作,所以一个事务看起来是一个原子操作。
在许多系统中,删除文件也是一个高代价的操作。作为优化,SQLite可以配置成把日志文件的长度截为0或者把日志文件头清零。
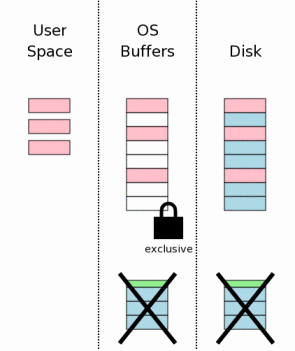
#### 释放锁(Releasing The Lock)
作为原子提交的最后一步,释放排斥锁使得其它进程可以开始访问数据库了。
## 参考资料
[深入理解sqlite](https://www.kancloud.cn/kangdandan/sqlite/64352)
- Android
- 四大组件
- Activity
- Fragment
- Service
- 序列化
- Handler
- Hander介绍
- MessageQueue详细
- 启动流程
- 系统启动流程
- 应用启动流程
- Activity启动流程
- View
- view绘制
- view事件传递
- choreographer
- LayoutInflater
- UI渲染概念
- Binder
- Binder原理
- Binder最大数据
- Binder小结
- Android组件
- ListView原理
- RecyclerView原理
- SharePreferences
- AsyncTask
- Sqlite
- SQLCipher加密
- 迁移与修复
- Sqlite内核
- Sqlite优化v2
- sqlite索引
- sqlite之wal
- sqlite之锁机制
- 网络
- 基础
- TCP
- HTTP
- HTTP1.1
- HTTP2.0
- HTTPS
- HTTP3.0
- HTTP进化图
- HTTP小结
- 实践
- 网络优化
- Json
- ProtoBuffer
- 断点续传
- 性能
- 卡顿
- 卡顿监控
- ANR
- ANR监控
- 内存
- 内存问题与优化
- 图片内存优化
- 线下内存监控
- 线上内存监控
- 启动优化
- 死锁监控
- 崩溃监控
- 包体积优化
- UI渲染优化
- UI常规优化
- I/O监控
- 电量监控
- 第三方框架
- 网络框架
- Volley
- Okhttp
- 网络框架n问
- OkHttp原理N问
- 设计模式
- EventBus
- Rxjava
- 图片
- ImageWoker
- Gilde的优化
- APT
- 依赖注入
- APT
- ARouter
- ButterKnife
- MMKV
- Jetpack
- 协程
- MVI
- Startup
- DataBinder
- 黑科技
- hook
- 运行期Java-hook技术
- 编译期hook
- ASM
- Transform增量编译
- 运行期Native-hook技术
- 热修复
- 插件化
- AAB
- Shadow
- 虚拟机
- 其他
- UI自动化
- JavaParser
- Android Line
- 编译
- 疑难杂症
- Android11滑动异常
- 方案
- 工业化
- 模块化
- 隐私合规
- 动态化
- 项目管理
- 业务启动优化
- 业务架构设计
- 性能优化case
- 性能优化-排查思路
- 性能优化-现有方案
- 登录
- 搜索
- C++
- NDK入门
- 跨平台
- H5
- Flutter
- Flutter 性能优化
- 数据跨平台