
[TOC]
# Lifecycle
## 解决问题:
* activity的生命周期内有大量管理组件的代码,难以维护。
* 无法保证组件会在 Activity/Fragment停止后不执行启动
## 实现
LifecycleOwner(如Activity)在生命周期状态改变时(也就是生命周期方法执行时),遍历观察者,获取每个观察者的方法上的注解。
# LifeData
**LiveData使得 数据的更新 能以观察者模式 被observer感知,且此感知只发生在 LifecycleOwner的活跃生命周期状态**。
## 基本用法
1. 创建LiveData实例,指定源数据类型
2. 创建Observer实例,实现onChanged()方法,用于接收源数据变化并刷新UI
3. LiveData实例使用observe()方法添加观察者,并传入LifecycleOwner
4. LiveData实例使用setValue()/postValue()更新源数据 (子线程要postValue())
## LiveData与MutableLiveData区别
1. MutableLiveData的父类是LiveData
2. LiveData在实体类里可以通知指定某个字段的数据更新.
3. MutableLiveData则是完全是整个实体类或者数据类型变化后才通知.不会细节到某个字段
4. LiveData不可变,MutableLiveData是可变的
## 源码分析(观察者模式)
LiveData原理是观察者模式,下面就先从LiveData.observe()方法看起:
~~~
//key 观察者 value 包装的LifecycleOwner
private SafeIterableMap<Observer<? super T>, ObserverWrapper> mObservers =
new SafeIterableMap<>();
~~~
## 事件推送,解决防止事件丢失
投递事件时,如果判断Lifecycle是否激活,如果NO,则把数据暂存起来
## 解决数据倒灌
对于这个问题,总结一下发生的核心原因。对于LiveData,其初始的version是-1,当我们调用了其setValue或者postValue,其vesion会+1;对于每一个观察者的封装ObserverWrapper,其初始version也为-1,也就是说,每一个新注册的观察者,其version为-1;当LiveData设置这个ObserverWrapper的时候,如果LiveData的version大于ObserverWrapper的version,LiveData就会强制把当前value推送给Observer。
那么能不能从**Map容器mObservers中取到LifecycleBoundObserver,然后再更改version呢**?答案是肯定的,通过查看SafeIterableMap的源码我们发现有一个protected的get方法。因此,在调用observe的时候,我们可以通过反射拿到LifecycleBoundObserver,再把LifecycleBoundObserver的version设置成和LiveData一致即可。
# ViewModel
## 特点
### 生命周期长于Activity
ViewModel最重要的特点是 生命周期长于Activity。来看下官网的一张图:
看到在因屏幕旋转而重新创建Activity后,ViewModel对象依然会保留。 只有Activity真正Finish的时ViewModel才会被清除。
也就是说,因系统配置变更Activity销毁重建,ViewModel对象会保留并关联到新的Activity。而Activity的正常销毁(系统不会重建Activity)时,ViewModel对象是会清除的。
那么很自然的,因系统配置变更Activity销毁重建,ViewModel内部存储的数据 就可供重新创建的Activity实例使用了。这就解决了第一个问题。
### 不持有UI层引用
我们知道,在MVP的Presenter中需要持有IView接口来回调结果给界面。
而ViewModel是不需要持有UI层引用的,那结果怎么给到UI层呢?答案就是使用上一篇中介绍的基于观察者模式的LiveData。 并且,ViewModel也不能持有UI层引用,因为ViewModel的生命周期更长。
所以,ViewModel不需要也不能 持有UI层引用,那么就避免了可能的内存泄漏,同时实现了解耦。这就解决了第二个问题。
## 原理
### ViewModelStore
```
**
* 用于存储ViewModels.
* ViewModelStore实例 必须要能 在系统配置改变后 依然存在。
*/
public class ViewModelStore {
private final HashMap<String, ViewModel> mMap = new HashMap<>();
final void put(String key, ViewModel viewModel) {
ViewModel oldViewModel = mMap.put(key, viewModel);
if (oldViewModel != null) {
oldViewModel.onCleared();
}
}
final ViewModel get(String key) {
return mMap.get(key);
}
Set<String> keys() {
return new HashSet<>(mMap.keySet());
}
/**
* 调用ViewModel的clear()方法,然后清除ViewModel
* 如果ViewModelStore的拥有者(Activity/Fragment)销毁后不会重建,那么就需要调用此方法
*/
public final void clear() {
for (ViewModel vm : mMap.values()) {
vm.clear();
}
mMap.clear();
}
}
```
### 配置更改重建后ViewModel依然存在
* 如果存储器是空,就先尝试 从lastNonConfigurationInstance从获取
* mLastNonConfigurationInstances是在Activity的attach方法中赋值
* ActivityThread 中的 ActivityClientRecord 是不受 activity 重建的影响,那么ActivityClientRecord中lastNonConfigurationInstances也不受影响
# MVVM
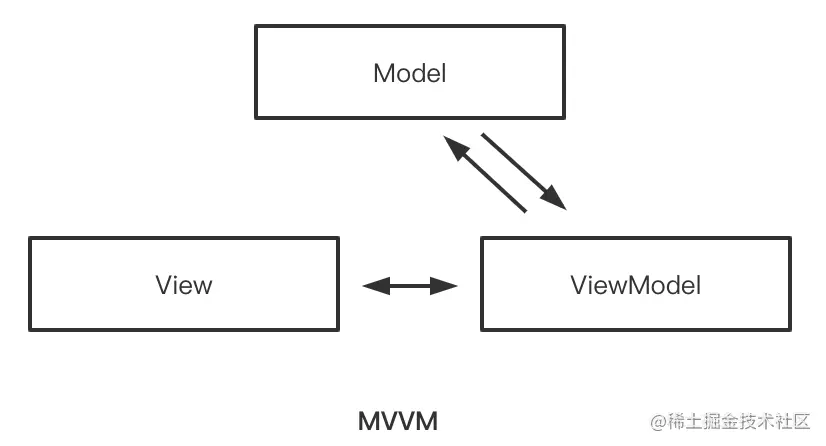
**MVVM各职责如下**:
* Model模型:业务相关的数据(如网络请求数据、本地数据库数据等)及其对数据的处理
* View视图:页面视图(Activity/Fragment),负责接收用户输入、发起数据请求及展示结果页面
* ViewModel:M与V之间的桥梁,负责业务逻辑
**MVVM特点**:
* View层接收用户操作,并通过持有的ViewModel去处理业务逻辑,请求数据;
* ViewModel层通过Model去获取数据,然后Model又将最新的数据传回ViewModel层,到这里,ViewModel与Presenter所做的事基本是一样的。但是ViewModel不会也不能持有View层的引用,而是View层会通过观察者模式监听ViewModel层的数据变化,当有新数据时,View层能自动收到新数据并刷新界面。
#### UI驱动 vs 数据驱动
`MVP`中,`Presenter`中需要持有`View`层的引用,当数据变化时,需要主动调用`View`层对应的方法将数据传过去并进行UI刷新,这种可以认为是UI驱动;而`MVVM`中,`ViewModel`并不会持有`View`层的引用,`View`层会监听数据变化,当`ViewModel`中有数据更新时,`View`层能直接拿到新数据并完成UI更新,这种可以认为是数据驱动,显然,`MVVM`相比于`MVP`来说更加解耦。
# MVI架构
本质就是`单向数据流动`+`状态集中管理` (谷歌推荐的最佳实践)
## 单向数据流动
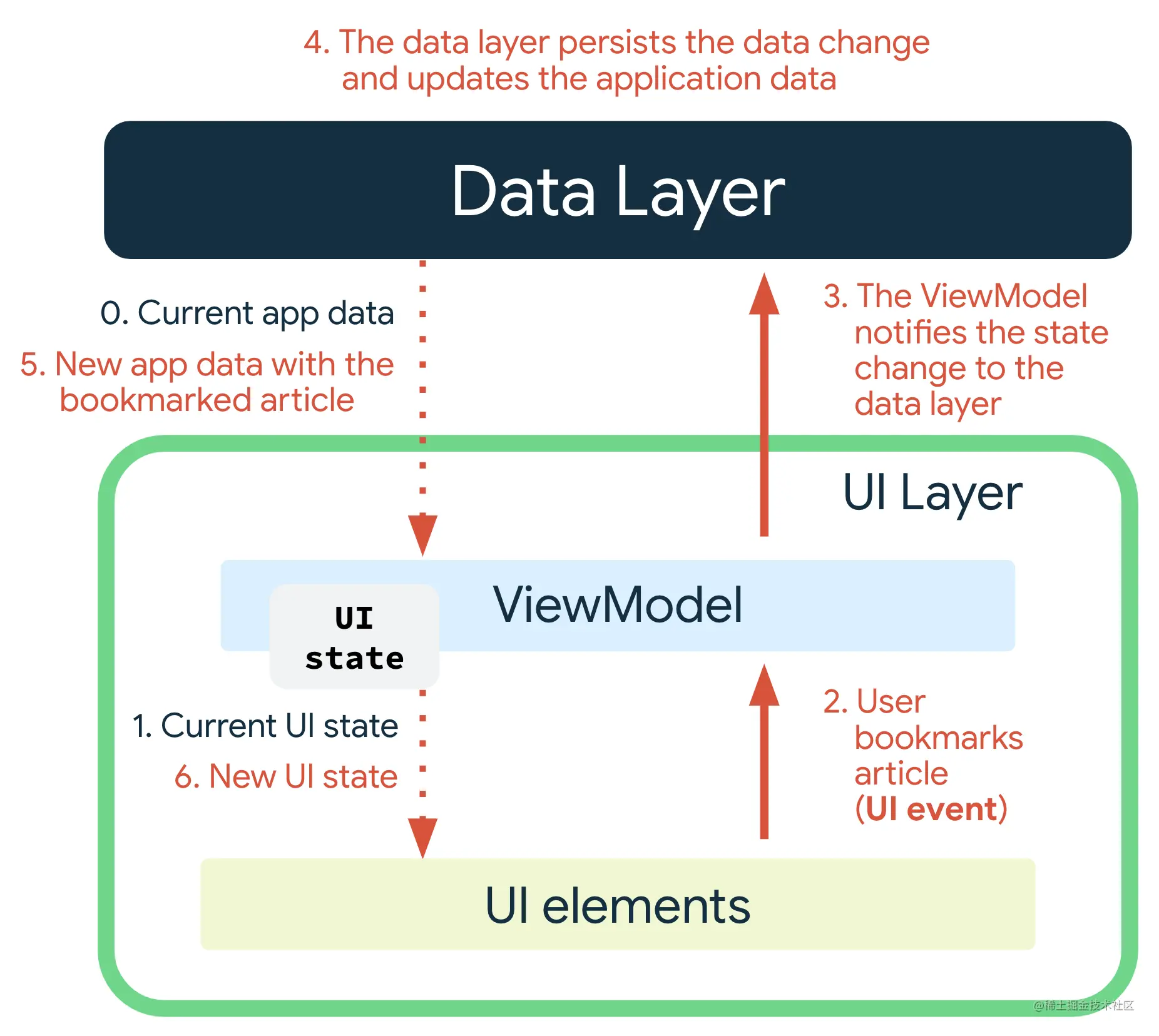
新`UI State`主要分为以下几步:
1. `ViewModel` 会存储并公开`UI State`。`UI State`是经过`ViewModel`转换的应用数据。
2. `UI`层会向`ViewModel`发送用户事件通知。
3. `ViewModel`会处理用户操作并更新`UI State`。
4. 更新后的状态将反馈给`UI`以进行呈现。
5. 系统会对导致状态更改的所有事件重复上述操作。
### 优势
单向数据流动可以实现关注点分离原则,它可以将状态变化来源位置、转换位置以及最终使用位置进行分离。
这种分离可让`UI`只发挥其名称所表明的作用:通过观察`UI State`变化来显示页面信息,并将用户输入传递给`ViewModel`以实现状态刷新。
换句话说,单向数据流动有助于实现以下几点:
1. 数据一致性。界面只有一个可信来源。
2. 可测试性。状态来源是独立的,因此可独立于界面进行测试。
3. 可维护性。状态的更改遵循明确定义的模式,即状态更改是用户事件及其数据拉取来源共同作用的结果。
## UIState 集中管理
### 缺点
* 不相关的数据类型:`UI`所需的某些状态可能是完全相互独立的。在此类情况下,将这些不同的状态捆绑在一起的代价可能会超过其优势,尤其是当其中某个状态的更新频率高于其他状态的更新频率时。
* `UiState diffing`:`UiState` 对象中的字段越多,数据流就越有可能因为其中一个字段被更新而发出。由于视图没有 `diffing` 机制来了解连续发出的数据流是否相同,因此每次发出都会导致视图更新。当然,我们可以对 `LiveData` 或`Flow`使用 `distinctUntilChanged()` 等方法来实现局部刷新,从而解决这个问题
### UI State实现局部刷新
下面我们就来看下`LiveData`怎么实现属性监听
~~~kotlin
//监听一个属性
fun <T, A> LiveData<T>.observeState(
lifecycleOwner: LifecycleOwner,
prop1: KProperty1<T, A>,
action: (A) -> Unit
) {
this.map {
StateTuple1(prop1.get(it))
}.distinctUntilChanged().observe(lifecycleOwner) { (a) ->
action.invoke(a)
}
}
//监听两个属性
fun <T, A, B> LiveData<T>.observeState(
lifecycleOwner: LifecycleOwner,
prop1: KProperty1<T, A>,
prop2: KProperty1<T, B>,
action: (A, B) -> Unit
) {
this.map {
StateTuple2(prop1.get(it), prop2.get(it))
}.distinctUntilChanged().observe(lifecycleOwner) { (a, b) ->
action.invoke(a, b)
}
}
internal data class StateTuple1<A>(val a: A)
internal data class StateTuple2<A, B>(val a: A, val b: B)
//更新State
fun <T> MutableLiveData<T>.setState(reducer: T.() -> T) {
this.value = this.value?.reducer()
}
~~~
1. 如上所示,主要是添加一个扩展方法,也是通过`distinctUntilChanged`来实现防抖
2. 如果需要监听多个属性,例如两个属性有其中一个变化了就触发刷新,也支持传入两个属性
3. 需要注意的是`LiveData`默认是不防抖的,这样改造后就是防抖的了,所以传入相同的值是不会回调的
4. 同时需要注意下承载`State`的数据类需要防混淆
# 参考资料
[Google 推荐使用 MVI 架构?卷起来了~](https://juejin.cn/post/7048980213811642382)
[“终于懂了“系列:Jetpack AAC完整解析(一)Lifecycle 完全掌握!](https://blog.csdn.net/hfy8971613/article/details/109641527)
[Android消息总线的演进之路:用LiveDataBus替代RxBus、EventBus](https://tech.meituan.com/2018/07/26/android-livedatabus.html)
- Android
- 四大组件
- Activity
- Fragment
- Service
- 序列化
- Handler
- Hander介绍
- MessageQueue详细
- 启动流程
- 系统启动流程
- 应用启动流程
- Activity启动流程
- View
- view绘制
- view事件传递
- choreographer
- LayoutInflater
- UI渲染概念
- Binder
- Binder原理
- Binder最大数据
- Binder小结
- Android组件
- ListView原理
- RecyclerView原理
- SharePreferences
- AsyncTask
- Sqlite
- SQLCipher加密
- 迁移与修复
- Sqlite内核
- Sqlite优化v2
- sqlite索引
- sqlite之wal
- sqlite之锁机制
- 网络
- 基础
- TCP
- HTTP
- HTTP1.1
- HTTP2.0
- HTTPS
- HTTP3.0
- HTTP进化图
- HTTP小结
- 实践
- 网络优化
- Json
- ProtoBuffer
- 断点续传
- 性能
- 卡顿
- 卡顿监控
- ANR
- ANR监控
- 内存
- 内存问题与优化
- 图片内存优化
- 线下内存监控
- 线上内存监控
- 启动优化
- 死锁监控
- 崩溃监控
- 包体积优化
- UI渲染优化
- UI常规优化
- I/O监控
- 电量监控
- 第三方框架
- 网络框架
- Volley
- Okhttp
- 网络框架n问
- OkHttp原理N问
- 设计模式
- EventBus
- Rxjava
- 图片
- ImageWoker
- Gilde的优化
- APT
- 依赖注入
- APT
- ARouter
- ButterKnife
- MMKV
- Jetpack
- 协程
- MVI
- Startup
- DataBinder
- 黑科技
- hook
- 运行期Java-hook技术
- 编译期hook
- ASM
- Transform增量编译
- 运行期Native-hook技术
- 热修复
- 插件化
- AAB
- Shadow
- 虚拟机
- 其他
- UI自动化
- JavaParser
- Android Line
- 编译
- 疑难杂症
- Android11滑动异常
- 方案
- 工业化
- 模块化
- 隐私合规
- 动态化
- 项目管理
- 业务启动优化
- 业务架构设计
- 性能优化case
- 性能优化-排查思路
- 性能优化-现有方案
- 登录
- 搜索
- C++
- NDK入门
- 跨平台
- H5
- Flutter
- Flutter 性能优化
- 数据跨平台