
[TOC]
# 协程
## 什么是协程?
**`Kotlin`协程的核心竞争力在于:它能简化异步并发任务,以同步方式写异步代码**
这也是为什么要引入协程的原因了:简化异步并发任务
## 协程与线程的区别是什么?
协程基于线程,但相对于线程轻量很多,可理解为在用户层模拟线程操作;
每创建一个协程,都有一个内核态线程动态绑定,用户态下实现调度、切换,真正执行任务的还是内核线程。
线程的上下文切换都需要内核参与,而协程的上下文切换,完全由用户去控制,避免了大量的中断参与,减少了线程上下文切换与调度消耗的资源。
线程是操作系统层面的概念,协程是语言层面的概念
**线程与协程最大的区别在于:线程是被动挂起恢复,协程是主动挂起恢复**
## `Kotlin`中的协程是什么?
"假"协程,`Kotlin`在语言级别并没有实现一种同步机制(锁),还是依靠`Kotlin-JVM`的提供的`Java`关键字(如`synchronized`),即锁的实现还是交给线程处理
因而`Kotlin`协程本质上只是一套基于原生`Java线程池` 的封装。
`Kotlin` 协程的核心竞争力在于:它能简化异步并发任务,以同步方式写异步代码。
# 协程要点 suspend
上面的代码之所以能写成类似`同步`的方式,关键还是在于那三个请求函数的定义。与普通函数不同的地方在于,它们都被 `suspend` 修饰,这代表它们都是:`挂起函数`。
~~~kotlin
// delay(1000L)用于模拟网络请求
//挂起函数
// ↓
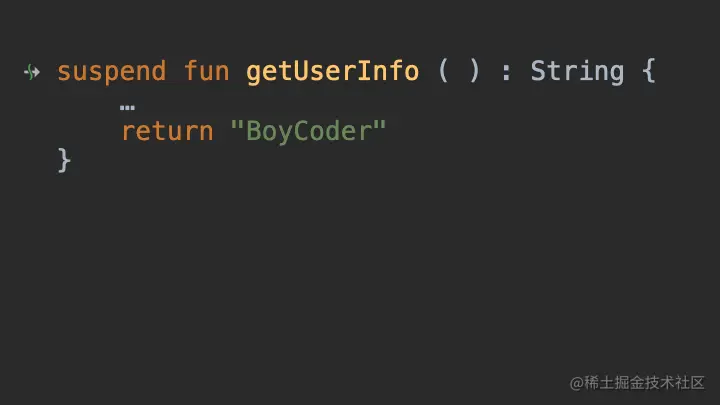
suspend fun getUserInfo(): String {
withContext(Dispatchers.IO) {
delay(1000L)
}
return "BoyCoder"
}
//挂起函数
// ↓
suspend fun getFriendList(user: String): String {
withContext(Dispatchers.IO) {
delay(1000L)
}
return "Tom, Jack"
}
//挂起函数
// ↓
suspend fun getFeedList(list: String): String {
withContext(Dispatchers.IO) {
delay(1000L)
}
return "{FeedList..}"
}
复制代码
~~~
那么,挂起函数到底是什么?
## 挂起函数
挂起函数(Suspending Function),从字面上理解,就是`可以被挂起的函数`。suspend 有:挂起,`暂停`的意思。在这个语境下,也有点暂停的意思。暂停更容易被理解,但挂起更准确。
挂起函数,能被**挂起**,当然也能**恢复**,他们一般是成对出现的。
我们来看看挂起函数的执行流程,注意动画当中出现的`闪烁`,这代表正在请求网络。
**一定要多看几遍,确保没有遗漏其中的细节。**

从上面的动画,我们能知道:
* 表面上看起来是同步的代码,实际上也涉及到了线程切换。
* 一行代码,切换了两个线程。
* `=`左边:主线程
* `=`右边:IO线程
* 每一次从`主线程`到`IO线程`,都是一次协程`挂起`(suspend)
* 每一次从`IO线程`到`主线程`,都是一次协程`恢复`(resume)。
* 挂起和恢复,这是挂起函数特有的能力,普通函数是不具备的。
* 挂起,只是将程序执行流程转移到了其他线程,主线程并未被阻塞。
* 如果以上代码运行在 Android 系统,我们的 App 是仍然可以响应用户的操作的,主线程并不繁忙,这也很容易理解。
挂起函数的执行流程我们已经很清楚了,那么,Kotlin 协程到底是如何做到`一行代码切换两个线程`的?
这一切的`魔法`都藏在了挂起函数的`suspend`关键字里。
# suspend原理
`CPS`与`状态机`就是协程实现的核心
1. 增加了`Continuation`类型的参数 (callback 返回结果)
2. 返回类型从`String`转变成了`Any`(返回是否被挂起)
3. `continuation.label` 是状态流转的关键,`label`改变一次代表协程发生了一次挂起恢复
4. 我们写在协程里的代码,被拆分到状态机里各个状态中,分开执行
## CPS 转化
下面用动画演示挂起函数在 `CPS` 转换过程中,函数签名的变化:
 可以看出主要有两点变化
1.增加了`Continuation`类型的参数
2.返回类型从`String`转变成了`Any`
参数的变化我们之前讲过,为什么返回值要变呢?
### 挂起函数返回值
挂起函数经过 `CPS` 转换后,它的返回值有一个重要作用:标志该挂起函数有没有被挂起。
听起来有点奇怪,挂起函数还会不挂起吗?
> 只要被`suspend`修饰的函数都是挂起函数,但是不是所有挂起函数都会被挂起
> 只有当挂起函数里包含异步操作时,它才会被真正挂起
由于 `suspend` 修饰的函数,既可能返回 `CoroutineSingletons.COROUTINE_SUSPENDED`,表示挂起
也可能返回同步运行的结果,甚至可能返回 null
为了适配所有的可能性,`CPS` 转换后的函数返回值类型就只能是 `Any?`了。
## 状态机
`kotlin`协程的实现依赖于状态机
想要查看其实现,可以将`kotin`源码反编译成字节码来查看编译后的代码
关于字节码的分析之前已经有很多人做过了,而且做的很好,可参考:[Kotlin Jetpack 实战 | 09. 图解协程原理](https://juejin.cn/post/6883652600462327821#heading-14 "https://juejin.cn/post/6883652600462327821#heading-14")
读者可通过上面的链接进行详细的学习,下面给出状态机的动画演示

1. 协程实现的核心就是`CPS`变换与状态机
2. 协程执行到挂起函数,一个函数如果被挂起了,它的返回值会是:`CoroutineSingletons.COROUTINE_SUSPENDED`
3. 挂起函数执行完成后,通过`Continuation.resume`方法回调,这里的`Continuation`是通过`CPS`传入的
4. 传入的`Continuation`实际上是`ContinuationImpl`,`resume`方法最后会再次回到`invokeSuspend`方法中
5. `invokeSuspend`方法即是我们写的代码执行的地方,在协程运行过程中会执行多次
6. `invokeSuspend`中通过状态机实现状态的流转
7. `continuation.label` 是状态流转的关键,`label`改变一次代表协程发生了一次挂起恢复
8. 通过`break label`实现`goTo`的跳转效果
9. 我们写在协程里的代码,被拆分到状态机里各个状态中,分开执行
10. 每次协程切换后,都会检查是否发生异常
11. 切换协程之前,状态机会把之前的结果以成员变量的方式保存在 `continuation` 中。
以上是状态机流转的大概流程,读者可跟着参考链接,过一下编译后的字节码执行流程后,再来判断这个流程是否正确
# 协程怎么进行线程切换
简单来讲主要包括以下步骤:
1.向`CoroutineContext`添加`Dispatcher`,指定运行的协程
2.在启动时将`suspend block`创建成`Continuation`,并调用`intercepted`生成`DispatchedContinuation`
3.`DispatchedContinuation`就是对原有协程的装饰,在这里调用`Dispatcher`完成线程切换任务后,`resume`被装饰的协程,就会执行协程体内的代码了
**其实`kotlin`协程就是用装饰器模式实现线程切换的**
# Flow
`Flow` 就是 `Kotlin` 协程与响应式编程模型结合的产物,你会发现它与 `RxJava` 非常像,二者之间也有相互转换的 `API`,使用起来非常方便。
`Flow`有以下特点:
1.冷数据流,不消费则不生产,这一点与`Channel`正相反:`Channel`的发送端并不依赖于接收端。
2.`Flow`通过`flowOn`改变数据发射的线程,数据消费线程则由协程所在线程决定
3.与`RxJava`类似,支持通过`catch`捕获异常,通过`onCompletion` 回调完成
4.`Flow`没有提供取消方法,可以通过取消`Flow`所在协程的方式来取消
## `Flow`为什么是个冷流?
冷流即开始消费时才生产数据,不消费则不生产,我们来看下源码
先看下`flow{}`中发生了什么
~~~kotlin
public fun <T> flow(@BuilderInference block: suspend FlowCollector<T>.() -> Unit): Flow<T> = SafeFlow(block)
// Named anonymous object
private class SafeFlow<T>(private val block: suspend FlowCollector<T>.() -> Unit) : AbstractFlow<T>() {
override suspend fun collectSafely(collector: FlowCollector<T>) {
collector.block()
}
}
复制代码
~~~
可以看出,`flow{}`中做的事也很简单,主要就是创建了一个继承自`AbstractFlow`的`SafeFlow`
再来看下`AbstractFlow`中的内容
~~~kotlin
public abstract class AbstractFlow<T> : Flow<T> {
@InternalCoroutinesApi
public final override suspend fun collect(collector: FlowCollector<T>) {
// 1. collector 做一层包装
val safeCollector = SafeCollector(collector, coroutineContext)
try {
// 2. 处理数据接收者
collectSafely(safeCollector)
} finally {
// 3. 释放协程相关的参数
safeCollector.releaseIntercepted()
}
}
// collectSafely 方法应当遵循以下的约束
// 1. 不应当在collectSafely方法里面切换线程,比如 withContext(Dispatchers.IO)
// 2. collectSafely 默认不是线程安全的
public abstract suspend fun collectSafely(collector: FlowCollector<T>)
}
private class SafeFlow<T>(private val block: suspend FlowCollector<T>.() -> Unit) : AbstractFlow<T>() {
override suspend fun collectSafely(collector: FlowCollector<T>) {
collector.block()
}
}
复制代码
~~~
发现主要做了三件事:
1.对数据接收方`FlowCollector` 做了一层包装,也就是这个`SafeCollector`
2.调用它里面的抽象方法`AbstractFlow#collectSafely` 方法。
3.释放协程的一些信息。
结合以下之前看的`SafeFlow`,它实现了`AbstractFlow#collectSafely`方法,调用了`collector.block()`,也就是运行了`flow{}`块中的代码。
现在就很清晰了,为什么`Flow`是冷流?
**因为它会在每一次`collect`的时候才会去触发发送数据的动作**
## `Flow`是怎么切换线程的
`Flow`切换线程的方式与协程切换线程是类似的
都是通过启动一个子协程,然后通过`CoroutineContext`中的`Dispatchers`切换线程
不同的地方在于`Flow`切换过程中利用了`Channel`来传递数据
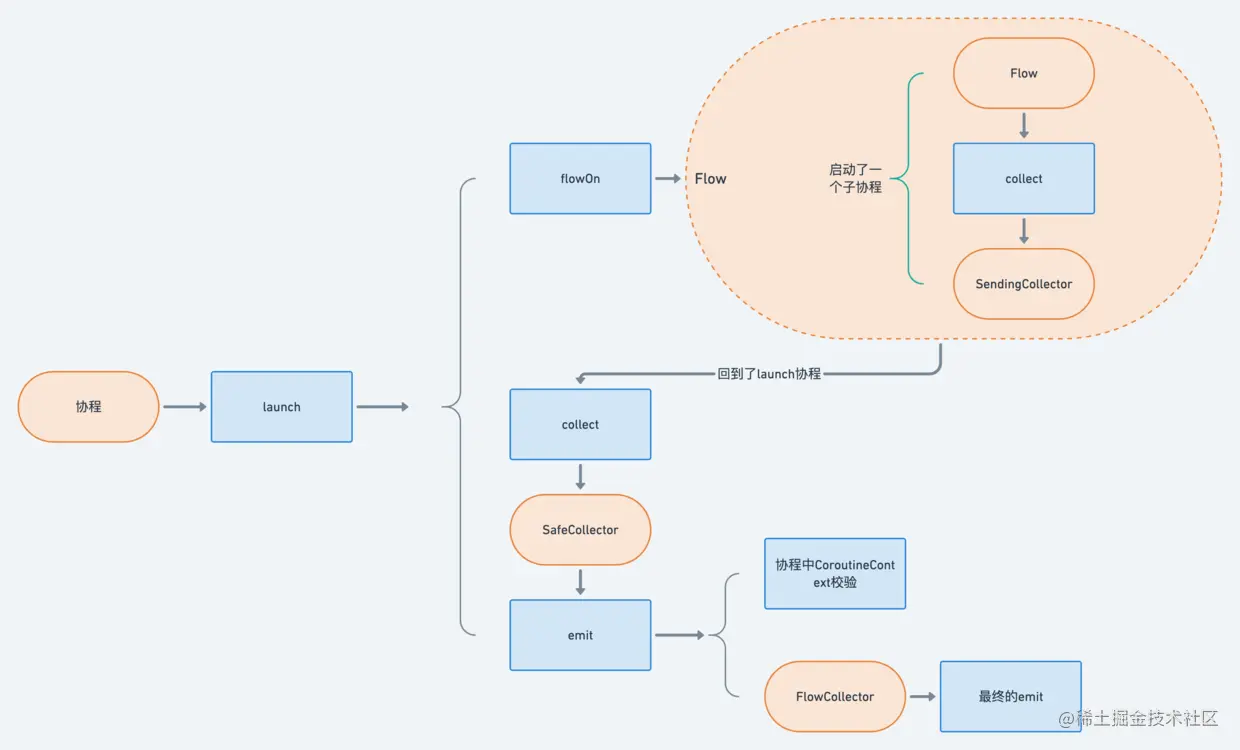
由于`Flow`切换线程的源码过多,就不在这里缀述了,有兴趣的同学可以跟一下源码,详情可见:[flowOn()如何做到切换协程](https://juejin.cn/post/6914802148614242312#heading-9 "https://juejin.cn/post/6914802148614242312#heading-9")
# 协程异常处理
## CoroutineExceptionHandler
* “ CoroutineExceptionHandler是用于全局“全部捕获”行为的最后手段。 您无法从CoroutineExceptionHandler中的异常中恢复。 当调用处理程序时,协程已经完成,并带有相应的异常。 通常,处理程序用于记录异常,显示某种错误消息,终止和/或重新启动应用程序。
* 为了使CoroutineExceptionHandler起作用,必须将其设置在CoroutineScope或顶级协程中。
* 如果需要在代码的特定部分处理异常,建议在协程内部的相应代码周围使用try / catch。 这样,您可以防止协程异常完成(现在已捕获异常),重试该操作和/或采取其他任意操作:
# 异常的传播机制
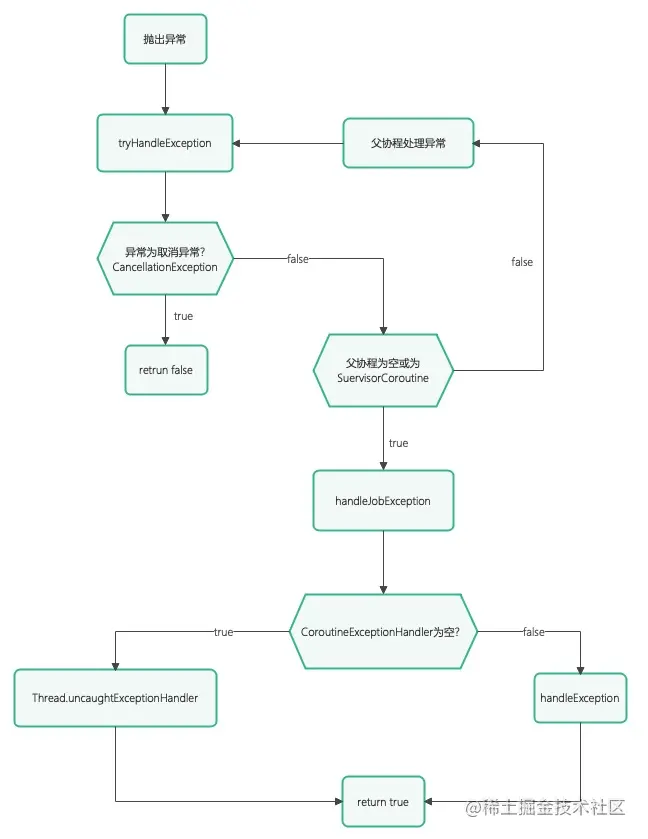
本文主要分析了`kotlin`协程的异常传播机制,主要分为以下几步
1. 协程体内抛出异常
2. 判断是否是`CancellationException`,如果是则不做处理
3. 判断父协程是否为空或为`supervisorScope`,如果是则调用`handleJobException`,处理异常
4. 如果不是则将异常传递给父协程,然后父协程再进行一遍上面的流程
以上步骤总结为流程图如下所示:
# 参考资料
[全民 Kotlin:协程特别篇](https://mp.weixin.qq.com/s/xqAdliU4g0cV1oIwwwYJlA)
[【带着问题学】协程到底是什么?](https://juejin.cn/post/6973650934664527885)
[Kotlin Jetpack 实战 | 09. 图解协程原理](https://juejin.cn/post/6883652600462327821)
[协程异常机制与优雅封装 | 技术点评](https://juejin.cn/post/6935472332735512606)
- Android
- 四大组件
- Activity
- Fragment
- Service
- 序列化
- Handler
- Hander介绍
- MessageQueue详细
- 启动流程
- 系统启动流程
- 应用启动流程
- Activity启动流程
- View
- view绘制
- view事件传递
- choreographer
- LayoutInflater
- UI渲染概念
- Binder
- Binder原理
- Binder最大数据
- Binder小结
- Android组件
- ListView原理
- RecyclerView原理
- SharePreferences
- AsyncTask
- Sqlite
- SQLCipher加密
- 迁移与修复
- Sqlite内核
- Sqlite优化v2
- sqlite索引
- sqlite之wal
- sqlite之锁机制
- 网络
- 基础
- TCP
- HTTP
- HTTP1.1
- HTTP2.0
- HTTPS
- HTTP3.0
- HTTP进化图
- HTTP小结
- 实践
- 网络优化
- Json
- ProtoBuffer
- 断点续传
- 性能
- 卡顿
- 卡顿监控
- ANR
- ANR监控
- 内存
- 内存问题与优化
- 图片内存优化
- 线下内存监控
- 线上内存监控
- 启动优化
- 死锁监控
- 崩溃监控
- 包体积优化
- UI渲染优化
- UI常规优化
- I/O监控
- 电量监控
- 第三方框架
- 网络框架
- Volley
- Okhttp
- 网络框架n问
- OkHttp原理N问
- 设计模式
- EventBus
- Rxjava
- 图片
- ImageWoker
- Gilde的优化
- APT
- 依赖注入
- APT
- ARouter
- ButterKnife
- MMKV
- Jetpack
- 协程
- MVI
- Startup
- DataBinder
- 黑科技
- hook
- 运行期Java-hook技术
- 编译期hook
- ASM
- Transform增量编译
- 运行期Native-hook技术
- 热修复
- 插件化
- AAB
- Shadow
- 虚拟机
- 其他
- UI自动化
- JavaParser
- Android Line
- 编译
- 疑难杂症
- Android11滑动异常
- 方案
- 工业化
- 模块化
- 隐私合规
- 动态化
- 项目管理
- 业务启动优化
- 业务架构设计
- 性能优化case
- 性能优化-排查思路
- 性能优化-现有方案
- 登录
- 搜索
- C++
- NDK入门
- 跨平台
- H5
- Flutter
- Flutter 性能优化
- 数据跨平台