
[TOC]
## 原理
IOCanary 将收集应用的文件中所有 I/O 信息并进行相关统计,再依据一定的算法规则进行检测,发现问题,将之上报到 Matrix 后台进行分析展示。流程图如下:
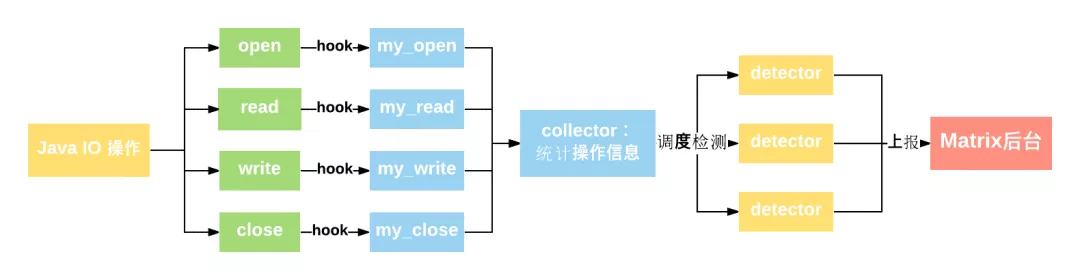
### Hook 方案简介
IOCanary 采用 hook (ELF hook) 的方案收集 I/O 信息,代码无侵入,从而使得开发者可以**无感知接入**。方案主要通过 hook os posix 的四个关键的文件操作接口:
~~~
int open(const char *pathname, int flags, mode_t mode);//成功时返回值就是fd
ssize_t read(int fd, void *buf, size_t size);
ssize_t write(int fd, const void *buf, size_t size);
int close(int fd);
~~~
由上得知,通过 hook 这几个接口,可以拿到大部分关键操作信息。这里举 open 的例子介绍下原理。 简单起见,只结合**Android M**的代码以及大家最常用的 FileInputStream 分析。关键要找到 posix open 是在哪里被调用。由上往下我们列了大致的调用关系:
~~~
java : FileInputStream -> IoBridge.open -> Libcore.os.open
-> BlockGuardOs.open -> Posix.open
↓
jni : libcore_io_Posix.cpp
static jobject Posix_open(...) {
...
int fd = throwIfMinusOne(env, "open", TEMP_FAILURE_RETRY(open(path.c_str(), flags, mode)));
...
}
~~~
由上看到, android 框架的 FileInputStream ,最终是在 libcore\_io\_Posix.cpp 那里调到了posix的open接口。
最后我们再找它被编到哪个 so ,通过查阅源码对应的 NativeCode.mk ,可以找到:
~~~
LOCAL_MODULE := libjavacore
~~~
因此,只要 hook libjavacore.so 的 open 符号就 ok 了。**找到 hook 目标 so 的目的是把 hook 的影响范围尽可能地降到最小**。同样, write,read,close 也是大同小异。不同的 Android 版本会有些坑需要填,这里不细述, 目前兼容到Android P。
由此, 通过ELF hook 便可以收集到应用在文件读写时的相关信息:**文件路径、fd、buffer 大小**等,并可以**统计耗时、操作次数**等。基于这些信息,就可以设定一些策略进行检测判断。
## 监控问题
### 1\. 主线程 I/O
我不止一次说过,有时候 I/O 的写入会突然放大,即使是几百 KB 的数据,还是尽量不要在主线程上操作。在线上也会经常发现一些 I/O 操作明明数据量不大,但是最后还是 ANR 了。
当然如果把所有的主线程 I/O 都收集上来,这个数据量会非常大,所以我会添加“连续读写时间超过 100 毫秒”这个条件。之所以使用连续读写时间,是因为发现有不少案例是打开了文件句柄,但不是一次读写完的。
在上报问题到后台时,为了能更好地定位解决问题,我通常还会把 CPU 使用率、其他线程的信息以及内存信息一并上报,辅助分析问题。
### 2\. 读写 Buffer 过小
我们知道,对于文件系统是以 block 为单位读写,对于磁盘是以 page 为单位读写,看起来即使我们在应用程序上面使用很小的 Buffer,在底层应该差别不大。那是不是这样呢?
~~~
read(53, "*****************"\.\.\., 1024) = 1024 <0.000447>
read(53, "*****************"\.\.\., 1024) = 1024 <0.000084>
read(53, "*****************"\.\.\., 1024) = 1024 <0.000059>
~~~
虽然后面两次系统调用的时间的确会少一些,但是也会有一定的耗时。如果我们的 Buffer 太小,会导致多次无用的系统调用和内存拷贝,导致 read/write 的次数增多,从而影响了性能。
那应该选用多大的 Buffer 呢?我们可以跟据文件保存所挂载的目录的 block size 来确认 Buffer 大小,数据库中的[pagesize](http://androidxref.com/6.0.1_r10/xref/frameworks/base/core/java/android/database/sqlite/SQLiteGlobal.java#61)就是这样确定的。
~~~
new StatFs("/data").getBlockSize()
~~~
所以我们最终选择的判断条件为:
* buffer size 小于 block size,这里一般为 4KB。
* read/write 的次数超过一定的阈值,例如 5 次,这主要是为了减少上报量。
buffer size 不应该小于 4KB,那它是不是越大越好呢?你可以通过下面的命令做一个简单的测试,读取测试应用的 iotest 文件,它的大小是 40M。其中 bs 就是 buffer size,bs 分别使用不同的值,然后观察耗时。
~~~
// 每次测试之前需要手动释放缓存
echo 3 > /proc/sys/vm/drop_caches
time dd if=/data/data/com.sample.io/files/iotest of=/dev/null bs=4096
~~~

通过上面的数据大致可以看出来,Buffer 的大小对文件读写的耗时有非常大的影响。耗时的减少主要得益于系统调用与内存拷贝的优化,Buffer 的大小一般我推荐使用 4KB 以上。
在实际应用中,ObjectOutputStream 和 ZipOutputStream 都是一个非常经典的例子,ObjectOutputStream 使用的 buffer size 非常小。而 ZipOutputStream 会稍微复杂一些,如果文件是 Stored 方式存储的,它会使用上层传入的 buffer size。如果文件是 Deflater 方式存储的,它会使用 DeflaterOutputStream 的 buffer size,这个大小默认是 512Byte。
**你可以看到,如果使用 BufferInputStream 或者 ByteArrayOutputStream 后整体性能会有非常明显的提升。**

正如我上一期所说的,准确评估磁盘真实的读写次数是比较难的。磁盘内部也会有很多的策略,例如预读。它可能发生超过你真正读的内容,预读在有大量顺序读取磁盘的时候,readahead 可以大幅提高性能。但是大量读取碎片小文件的时候,可能又会造成浪费。
你可以通过下面的这个文件查看预读的大小,一般是 128KB。
~~~
/sys/block/[disk]/queue/read_ahead_kb
~~~
一般来说,我们可以利用 /proc/sys/vm/block\_dump 或者[/proc/diskstats](https://www.kernel.org/doc/Documentation/iostats.txt)的信息统计真正的磁盘读写次数。
~~~
/proc/diskstats
块设备名字|读请求次数|读请求扇区数|读请求耗时总和\.\.\.\.
dm-0 23525 0 1901752 45366 0 0 0 0 0 33160 57393
dm-1 212077 0 6618604 430813 1123292 0 55006889 3373820 0 921023 3805823
~~~
### 3\. 重复读
微信之前在做模块化改造的时候,因为模块间彻底解耦了,很多模块会分别去读一些公共的配置文件。
有同学可能会说,重复读的时候数据都是从 Page Cache 中拿到,不会发生真正的磁盘操作。但是它依然需要消耗系统调用和内存拷贝的时间,而且 Page Cache 的内存也很有可能被替换或者释放。
你也可以用下面这个命令模拟 Page Cache 的释放。
~~~
echo 3 > /proc/sys/vm/drop_caches
~~~
如果频繁地读取某个文件,并且这个文件一直没有被写入更新,我们可以通过缓存来提升性能。不过为了减少上报量,我会增加以下几个条件:
* 重复读取次数超过 3 次,并且读取的内容相同。
* 读取期间文件内容没有被更新,也就是没有发生过 write。
加一层内存 cache 是最直接有效的办法,比较典型的场景是配置文件等一些数据模块的加载,如果没有内存 cache,那么性能影响就比较大了。
~~~
public String readConfig() {
if (Cache != null) {
return cache;
}
cache = read("configFile");
return cache;
}
~~~
### 4\. 资源泄漏
在崩溃分析中,我说过有部分的 OOM 是由于文件句柄泄漏导致。资源泄漏是指打开资源包括文件、Cursor 等没有及时 close,从而引起泄露。这属于非常低级的编码错误,但却非常普遍存在。
如何有效的监控资源泄漏?这里我利用了 Android 框架中的 StrictMode,StrictMode 利用[CloseGuard.java](http://androidxref.com/8.1.0_r33/xref/libcore/dalvik/src/main/java/dalvik/system/CloseGuard.java)类在很多系统代码已经预置了埋点。
到了这里,接下来还是查看源码寻找可以利用的 Hook 点。这个过程非常简单,CloseGuard 中的 REPORTER 对象就是一个可以利用的点。具体步骤如下:
* 利用反射,把 CloseGuard 中的 ENABLED 值设为 true。
* 利用动态代理,把 REPORTER 替换成我们定义的 proxy。
虽然在 Android 源码中,StrictMode 已经预埋了很多的资源埋点。不过肯定还有埋点是没有的,比如 MediaPlayer、程序内部的一些资源模块。所以在程序中也写了一个 MyCloseGuard 类,对希望增加监控的资源,可以手动增加埋点代码。
## I/O 与启动优化
通过 I/O 跟踪,可以拿到整个启动过程所有 I/O 操作的详细信息列表。我们需要更加的苛刻地检查每一处 I/O 调用,检查清楚是否每一处 I/O 调用都是必不可少的,特别是 write()。
当然主线程 I/O、读写 Buffer、重复读以及资源泄漏是首先需要解决的,特别是重复读,比如 cpuinfo、手机内存这些信息都应该缓存起来。
对于必不可少的 I/O 操作,我们需要思考是否有其他方式做进一步的优化。
* 对大文件使用 mmap 或者 NIO 方式。[MappedByteBuffer](https://developer.android.com/reference/java/nio/MappedByteBuffer)就是 Java NIO 中的 mmap 封装,正如上一期所说,对于大文件的频繁读写会有比较大的优化。
* 安装包不压缩。对启动过程需要的文件,我们可以指定在安装包中不压缩,这样也会加快启动速度,但带来的影响是安装包体积增大。事实上 Google Play 非常希望我们不要去压缩 library、resource、resource.arsc 这些文件,这样对启动的内存和速度都会有很大帮助。而且不压缩文件带来只是安装包体积的增大,对于用户来说,Download size 并没有增大。
* Buffer 复用。我们可以利用[Okio](https://github.com/square/okio)开源库,它内部的 ByteString 和 Buffer 通过重用等技巧,很大程度上减少 CPU 和内存的消耗。
* 存储结构和算法的优化。是否可以通过算法或者数据结构的优化,让我们可以尽量的少 I/O 甚至完全没有 I/O。比如一些配置文件从启动完全解析,改成读取时才解析对应的项;替换掉 XML、JSON 这些格式比较冗余、性能比较较差的数据结构,当然在接下来我还会对数据存储这一块做更多的展开。
- Android
- 四大组件
- Activity
- Fragment
- Service
- 序列化
- Handler
- Hander介绍
- MessageQueue详细
- 启动流程
- 系统启动流程
- 应用启动流程
- Activity启动流程
- View
- view绘制
- view事件传递
- choreographer
- LayoutInflater
- UI渲染概念
- Binder
- Binder原理
- Binder最大数据
- Binder小结
- Android组件
- ListView原理
- RecyclerView原理
- SharePreferences
- AsyncTask
- Sqlite
- SQLCipher加密
- 迁移与修复
- Sqlite内核
- Sqlite优化v2
- sqlite索引
- sqlite之wal
- sqlite之锁机制
- 网络
- 基础
- TCP
- HTTP
- HTTP1.1
- HTTP2.0
- HTTPS
- HTTP3.0
- HTTP进化图
- HTTP小结
- 实践
- 网络优化
- Json
- ProtoBuffer
- 断点续传
- 性能
- 卡顿
- 卡顿监控
- ANR
- ANR监控
- 内存
- 内存问题与优化
- 图片内存优化
- 线下内存监控
- 线上内存监控
- 启动优化
- 死锁监控
- 崩溃监控
- 包体积优化
- UI渲染优化
- UI常规优化
- I/O监控
- 电量监控
- 第三方框架
- 网络框架
- Volley
- Okhttp
- 网络框架n问
- OkHttp原理N问
- 设计模式
- EventBus
- Rxjava
- 图片
- ImageWoker
- Gilde的优化
- APT
- 依赖注入
- APT
- ARouter
- ButterKnife
- MMKV
- Jetpack
- 协程
- MVI
- Startup
- DataBinder
- 黑科技
- hook
- 运行期Java-hook技术
- 编译期hook
- ASM
- Transform增量编译
- 运行期Native-hook技术
- 热修复
- 插件化
- AAB
- Shadow
- 虚拟机
- 其他
- UI自动化
- JavaParser
- Android Line
- 编译
- 疑难杂症
- Android11滑动异常
- 方案
- 工业化
- 模块化
- 隐私合规
- 动态化
- 项目管理
- 业务启动优化
- 业务架构设计
- 性能优化case
- 性能优化-排查思路
- 性能优化-现有方案
- 登录
- 搜索
- C++
- NDK入门
- 跨平台
- H5
- Flutter
- Flutter 性能优化
- 数据跨平台