
[TOC]
# 背景知识
### CPU 与 GPU(软件绘制和硬件绘制)
除了屏幕,UI 渲染还依赖两个核心的硬件:CPU 与 GPU。UI 组件在绘制到屏幕之前,都需要经过 Rasterization(栅格化)操作,而栅格化操作又是一个非常耗时的操作。GPU(Graphic Processing Unit )也就是图形处理器,它主要用于处理图形运算,可以帮助我们加快栅格化操作。
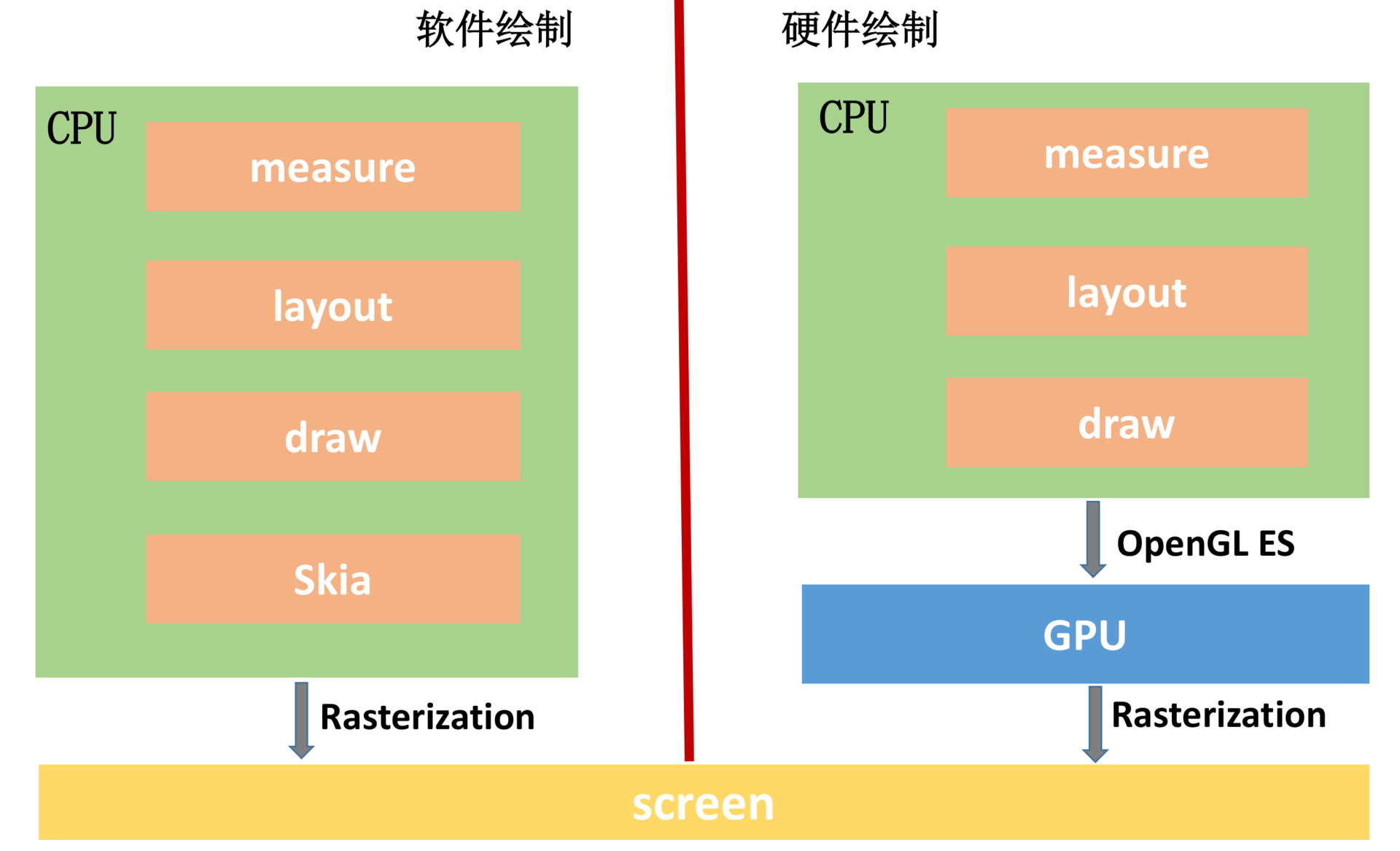
你可以从图上看到,软件绘制使用的是 Skia 库,它是一款能在低端设备如手机上呈现高质量的 2D 跨平台图形框架,类似 Chrome、Flutter 内部使用的都是 Skia 库。
### OpenGL
对于硬件绘制,我们通过调用 OpenGL ES 接口利用 GPU 完成绘制。[OpenGL](https://developer.android.com/guide/topics/graphics/opengl)是一个跨平台的图形 API,它为 2D/3D 图形处理硬件指定了标准软件接口。而 OpenGL ES 是 OpenGL 的子集,专为嵌入式设备设计。
在官方[硬件加速](https://developer.android.com/guide/topics/graphics/hardware-accel)的文档中,可以看到很多 API 都有相应的 Android API level 限制。
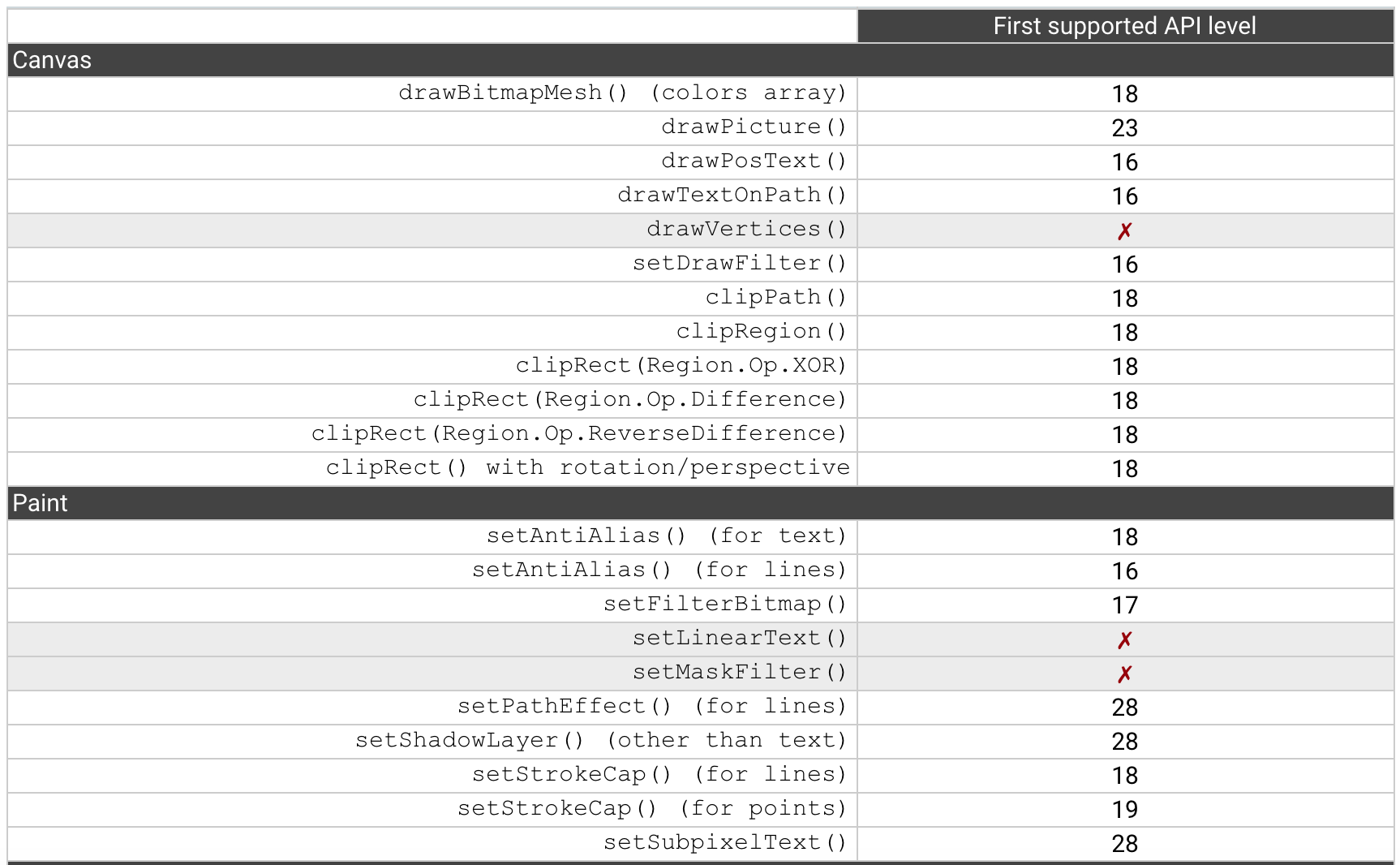
这是为什么呢?其实这主要是受[OpenGL ES](https://www.khronos.org/opengles/)版本与系统支持的限制,直到最新的 Android P,有 3 个 API 是仍然没有支持。对于不支持的 API,我们需要使用软件绘制模式,渲染的性能将会大大降低。
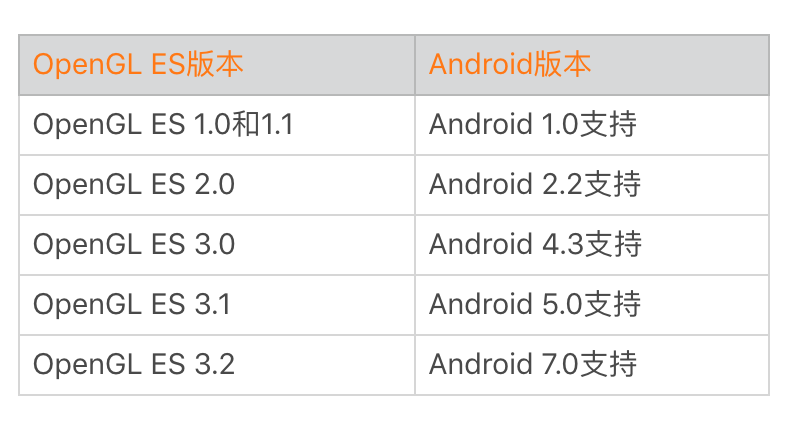
Android 7.0 把 OpenGL ES 升级到最新的 3.2 版本同时,还添加了对[Vulkan](https://source.android.com/devices/graphics/arch-vulkan)的支持。
### Vulkan
Vulkan 是用于高性能 3D 图形的低开销、跨平台 API。相比 OpenGL ES,Vulkan 在改善功耗、多核优化提升绘图调用上有着非常明显的[优势](https://zhuanlan.zhihu.com/p/20712354)。
## Android 渲染的演进
### 图形系统的
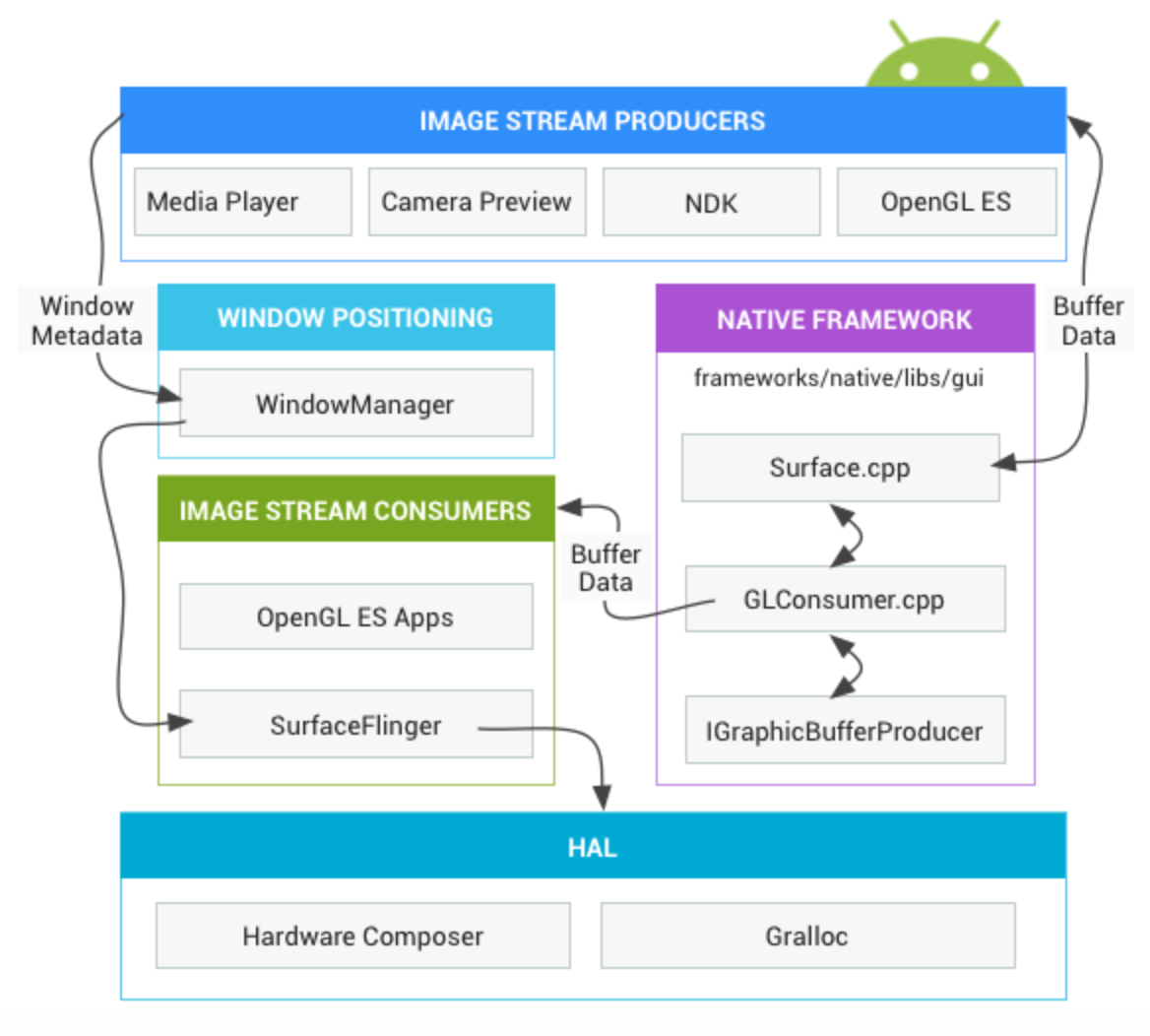
我曾经在一篇文章看过一个生动的比喻,如果把应用程序图形渲染过程当作一次绘画过程,那么绘画过程中 Android 的各个图形组件的作用是:
* 画笔:Skia 或者 OpenGL。我们可以用 Skia 画笔绘制 2D 图形,也可以用 OpenGL 来绘制 2D/3D 图形。正如前面所说,前者使用 CPU 绘制,后者使用 GPU 绘制。
* 画纸:Surface。所有的元素都在 Surface 这张画纸上进行绘制和渲染。在 Android 中,Window 是 View 的容器,每个窗口都会关联一个 Surface。而 WindowManager 则负责管理这些窗口,并且把它们的数据传递给 SurfaceFlinger。
* 画板:Graphic Buffer。Graphic Buffer 缓冲用于应用程序图形的绘制,在 Android 4.1 之前使用的是双缓冲机制;在 Android 4.1 之后,使用的是三缓冲机制。
* 显示:SurfaceFlinger。它将 WindowManager 提供的所有 Surface,通过硬件合成器 Hardware Composer 合成并输出到显示屏。
接下来我将通过 Android 渲染演进分析的方法,帮你进一步加深对 Android 渲染的理解。
### 1\. Android 4.0:开启硬件加速[¶](https://blog.yorek.xyz/android/paid/master/ui_1/#1-android-40 "Permanent link")
在 Android 3.0 之前,或者没有启用硬件加速时,系统都会使用软件方式来渲染 UI。
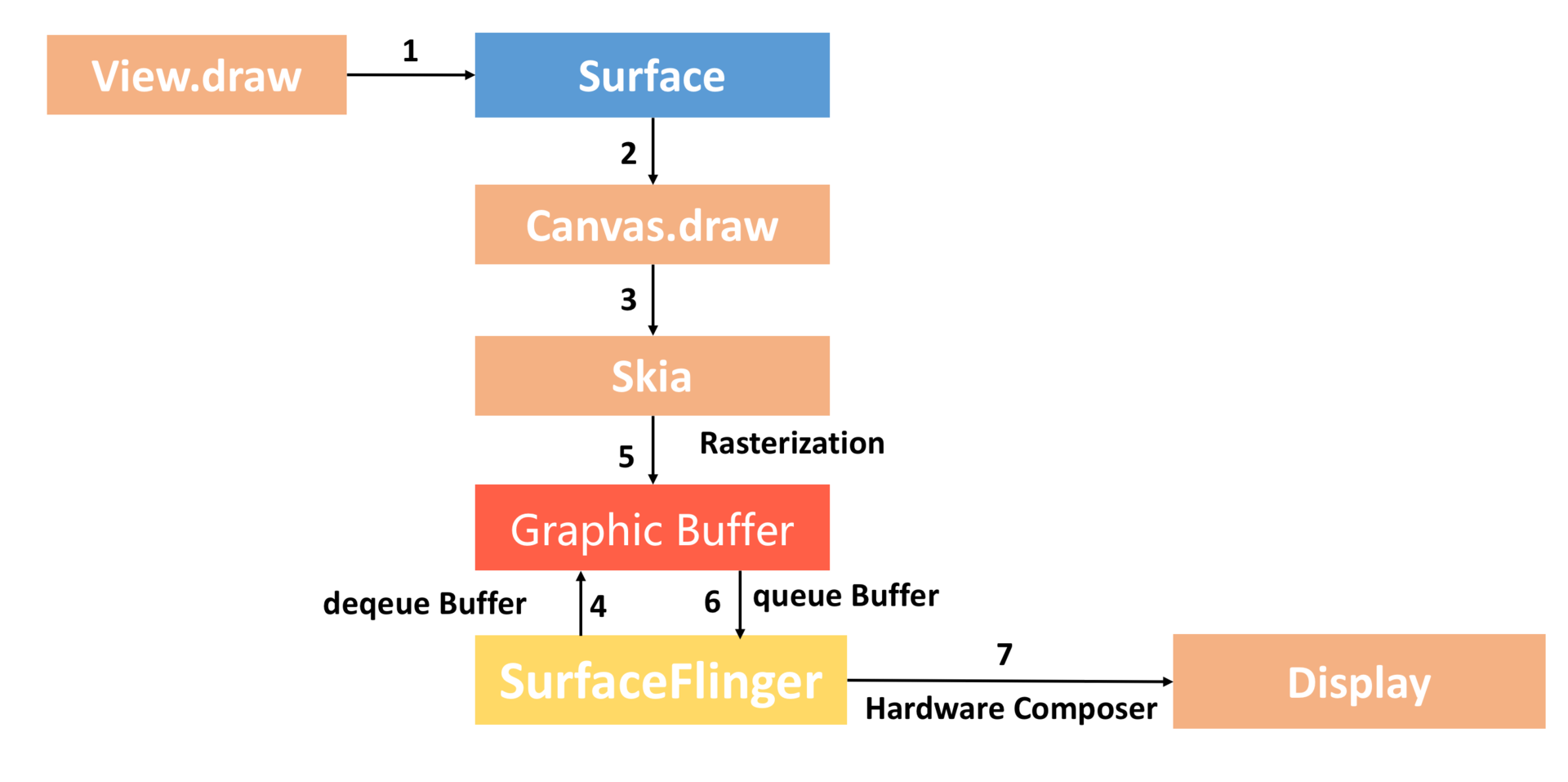
整个流程如上图所示:
* Surface。每个 View 都由某一个窗口管理,而每一个窗口都关联有一个 Surface。
* Canvas。通过 Surface 的 lock 函数获得一个 Canvas,Canvas 可以简单理解为 Skia 底层接口的封装。
* Graphic Buffer。SurfaceFlinger 会帮我们托管一个[BufferQueue](https://source.android.com/devices/graphics/arch-bq-gralloc),我们从 BufferQueue 中拿到 Graphic Buffer,然后通过 Canvas 以及 Skia 将绘制内容栅格化到上面。
* SurfaceFlinger。通过 Swap Buffer 把 Front Graphic Buffer 的内容交给 SurfaceFinger,最后硬件合成器 Hardware Composer 合成并输出到显示屏。
整个渲染流程是不是非常简单?但是正如我前面所说,CPU 对于图形处理并不是那么高效,这个过程完全没有利用到 GPU 的高性能。
#### 硬件加速绘制[¶](https://blog.yorek.xyz/android/paid/master/ui_1/#_1 "Permanent link")
所以从 Androd 3.0 开始,Android 开始支持硬件加速,到 Android 4.0 时,默认开启硬件加速。
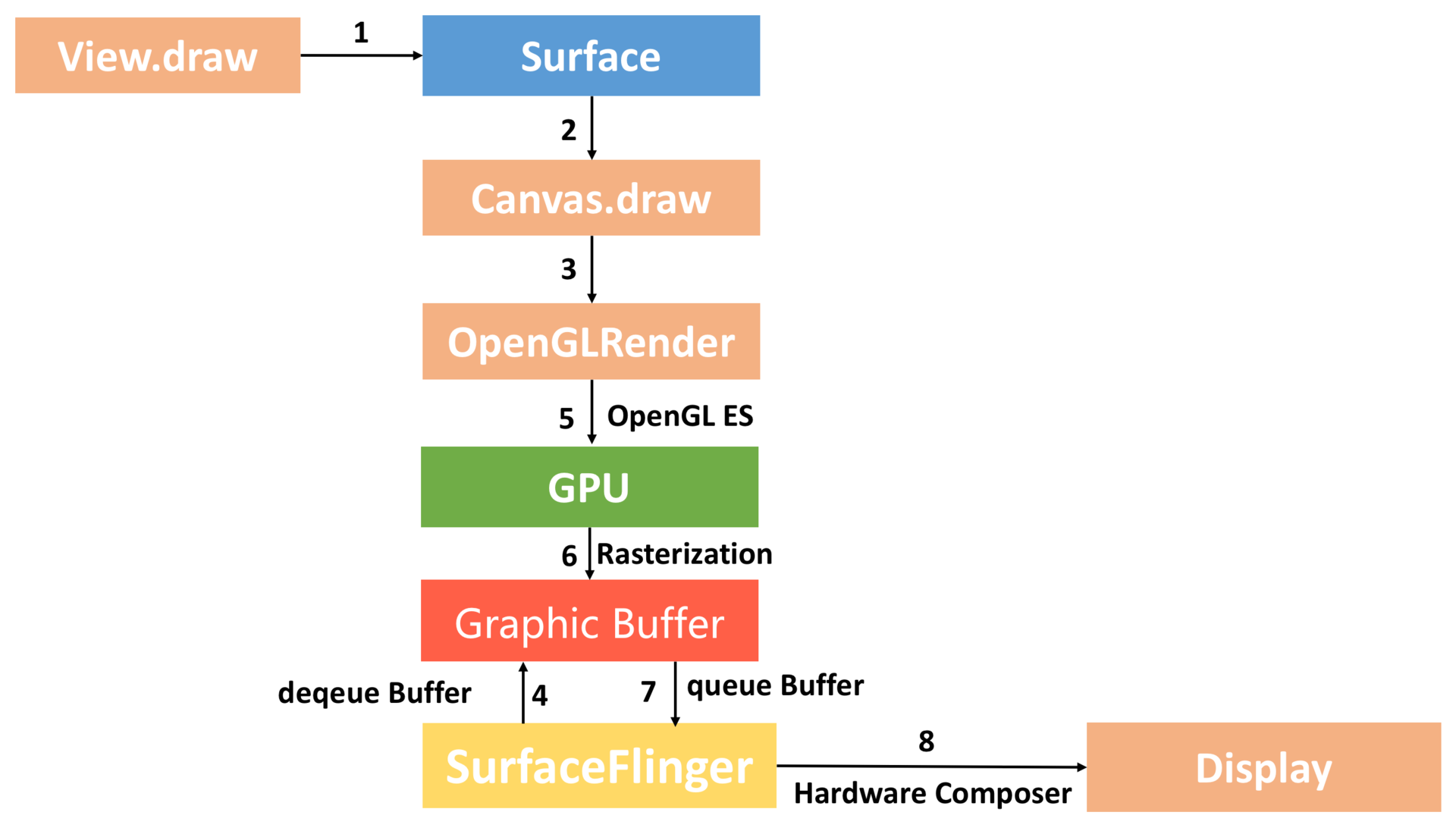
硬件加速绘制与软件绘制整个流程差异非常大,最核心就是我们通过 GPU 完成 Graphic Buffer 的内容绘制。此外硬件绘制还引入了一个 DisplayList 的概念,每个 View 内部都有一个 DisplayList,当某个 View 需要重绘时,将它标记为 Dirty。
当需要重绘时,仅仅只需要重绘一个 View 的 DisplayList,而不是像软件绘制那样需要向上递归。这样可以大大减少绘图的操作数量,因而提高了渲染效率。
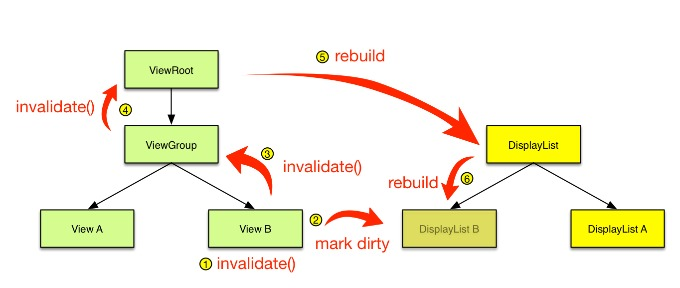
### 2\. Android 4.1:Project Butter[¶](https://blog.yorek.xyz/android/paid/master/ui_1/#2-android-41project-butter "Permanent link")
优化是无止境的,Google 在 2012 年的 I/O 大会上宣布了 Project Butter 黄油计划,并且在 Android 4.1 中正式开启了这个机制。
Project Butter 主要包含两个组成部分,一个是 VSYNC,一个是 Triple Buffering。
#### VSYNC 信号[¶](https://blog.yorek.xyz/android/paid/master/ui_1/#vsync "Permanent link")
在讲文件 I/O 跟网络 I/O 的时候,我讲到过中断的概念。对于 Android 4.0,CPU 可能会因为在忙别的事情,导致没来得及处理 UI 绘制。
为解决这个问题,Project Buffer 引入了[VSYNC](https://source.android.com/devices/graphics/implement-vsync),它类似于时钟中断。每收到 VSYNC 中断,CPU 会立即准备 Buffer 数据,由于大部分显示设备刷新频率都是 60Hz(一秒刷新 60 次),也就是说一帧数据的准备工作都要在 16ms 内完成。
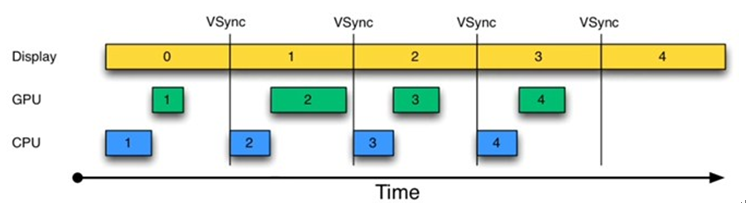
这样应用总是在 VSYNC 边界上开始绘制,而 SurfaceFlinger 总是 VSYNC 边界上进行合成。这样可以消除卡顿,并提升图形的视觉表现。
#### 三缓冲机制 Triple Buffering[¶](https://blog.yorek.xyz/android/paid/master/ui_1/#triple-buffering "Permanent link")
在 Android 4.1 之前,Android 使用双缓冲机制。怎么理解呢?一般来说,不同的 View 或者 Activity 它们都会共用一个 Window,也就是共用同一个 Surface。
而每个 Surface 都会有一个 BufferQueue 缓存队列,但是这个队列会由 SurfaceFlinger 管理,通过匿名共享内存机制与 App 应用层交互。
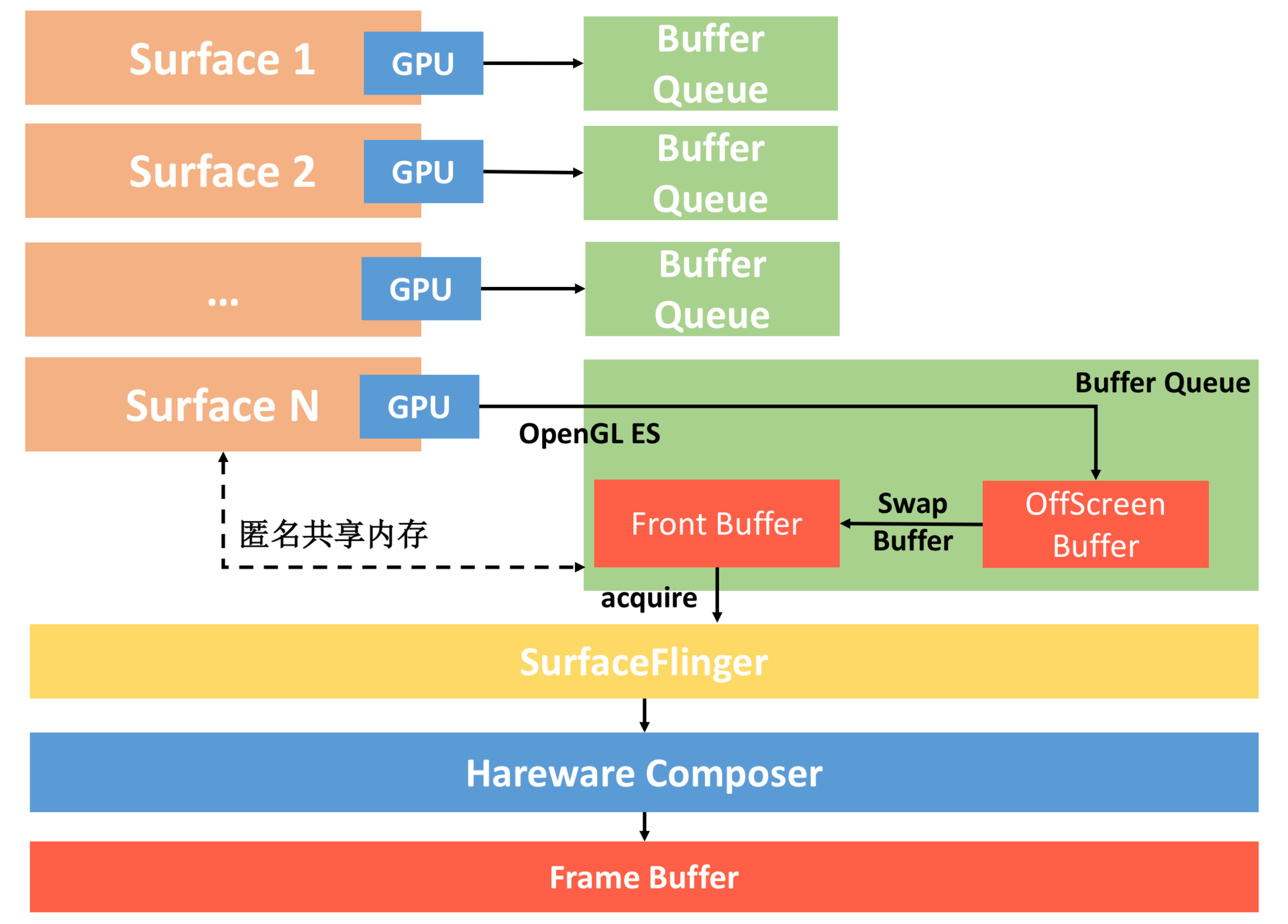
整个流程如下:
* 每个 Surface 对应的 BufferQueue 内部都有两个 Graphic Buffer ,一个用于绘制一个用于显示。我们会把内容先绘制到离屏缓冲区(OffScreen Buffer),在需要显示时,才把离屏缓冲区的内容通过 Swap Buffer 复制到 Front Graphic Buffer 中。
* 这样 SurfaceFlinge 就拿到了某个 Surface 最终要显示的内容,但是同一时间我们可能会有多个 Surface。这里面可能是不同应用的 Surface,也可能是同一个应用里面类似 SurefaceView 和 TextureView,它们都会有自己单独的 Surface。
* 这个时候 SurfaceFlinger 把所有 Surface 要显示的内容统一交给 Hareware Composer,它会根据位置、Z-Order 顺序等信息合成为最终屏幕需要显示的内容,而这个内容会交给系统的帧缓冲区 Frame Buffer 来显示(Frame Buffer 是非常底层的,可以理解为屏幕显示的抽象)。
如果你理解了双缓冲机制的原理,那就非常容易理解什么是三缓冲区了。如果只有两个 Graphic Buffer 缓存区 A 和 B,如果 CPU/GPU 绘制过程较长,超过了一个 VSYNC 信号周期,因为缓冲区 B 中的数据还没有准备完成,所以只能继续展示 A 缓冲区的内容,这样缓冲区 A 和 B 都分别被显示设备和 GPU 占用,CPU 无法准备下一帧的数据。
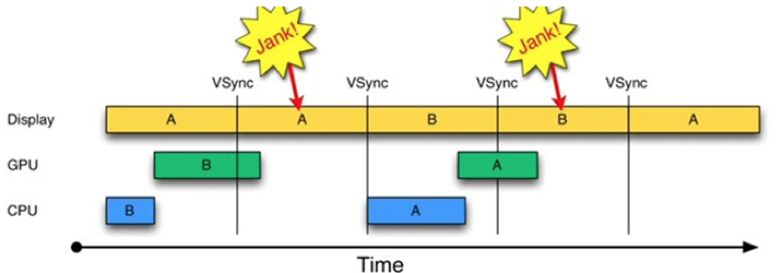
如果再提供一个缓冲区,CPU、GPU 和显示设备都能使用各自的缓冲区工作,互不影响。简单来说,三缓冲机制就是在双缓冲机制基础上增加了一个 Graphic Buffer 缓冲区,这样可以最大限度的利用空闲时间,带来的坏处是多使用的了一个 Graphic Buffer 所占用的内存。
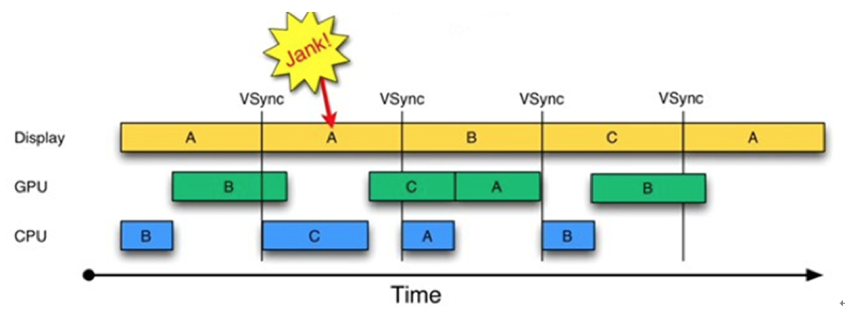
对于 VSYNC 信号和 Triple Buffering 更详细的介绍,可以参考[《Android Project Butter 分析》](https://blog.csdn.net/innost/article/details/8272867)。
#### 数据测量[¶](https://blog.yorek.xyz/android/paid/master/ui_1/#_2 "Permanent link")
“工欲善其事,必先利其器”,Project Butter 在优化 UI 渲染性能的同时,也希望可以帮助我们更好地排查 UI 相关的问题。
在 Android 4.1,新增了 Systrace 性能数据采样和分析工具。在卡顿和启动优化中,我们已经使用过 Systrace 很多次了,也可以用它来检测每一帧的渲染情况。
Tracer for OpenGL ES 也是 Android 4.1 新增加的工具,它可逐帧、逐函数的记录 App 用 OpenGL ES 的绘制过程。它提供了每个 OpenGL 函数调用的消耗时间,所以很多时候用来做性能分析。但因为其强大的记录功能,在分析渲染问题时,当 Traceview、Systrace 都显得棘手时,还找不到渲染问题所在时,此时这个工具就会派上用场了。
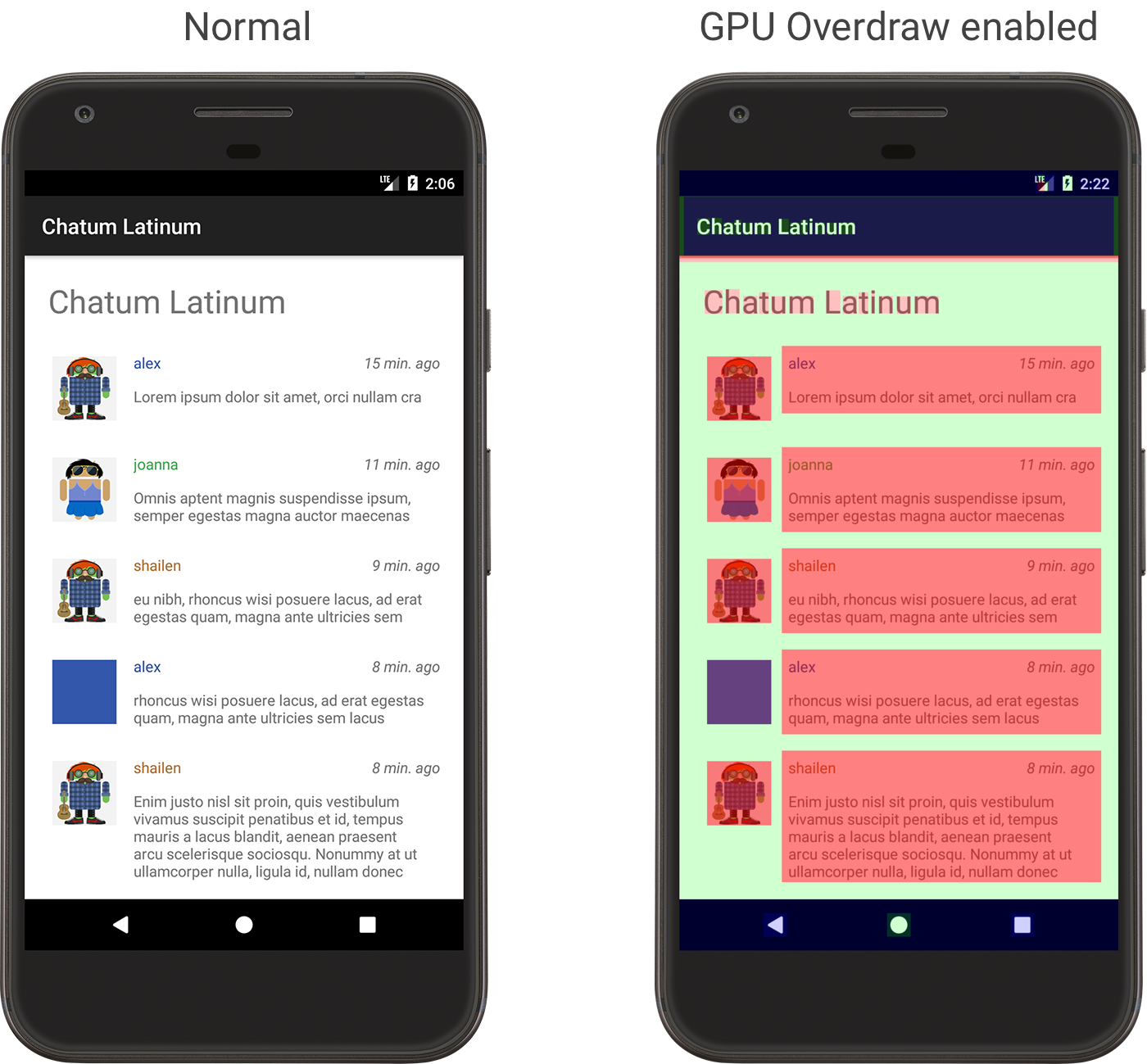
在 Android 4.2,系统增加了检测绘制过度工具,具体的使用方法可以参考[《检查 GPU 渲染速度和绘制过度》](https://developer.android.com/studio/profile/inspect-gpu-rendering)。
### 3\. Android 5.0:RenderThread[¶](https://blog.yorek.xyz/android/paid/master/ui_1/#3-android-50renderthread "Permanent link")
经过 Project Butter 黄油计划之后,Android 的渲染性能有了很大的改善。但是不知道你有没有注意到一个问题,虽然我们利用了 GPU 的图形高性能运算,但是从计算 DisplayList,到通过 GPU 绘制到 Frame Buffer,整个计算和绘制都在 UI 主线程中完成。

UI 主线程“既当爹又当妈”,任务过于繁重。如果整个渲染过程比较耗时,可能造成无法响应用户的操作,进而出现卡顿。GPU 对图形的绘制渲染能力更胜一筹,如果使用 GPU 并在不同线程绘制渲染图形,那么整个流程会更加顺畅。
正因如此,在 Android 5.0 引入了两个比较大的改变。一个是引入了 RenderNode 的概念,它对 DisplayList 及一些 View 显示属性做了进一步封装。另一个是引入了 RenderThread,所有的 GL 命令执行都放到这个线程上,渲染线程在 RenderNode 中存有渲染帧的所有信息,可以做一些属性动画,这样即便主线程有耗时操作的时候也可以保证动画流畅。
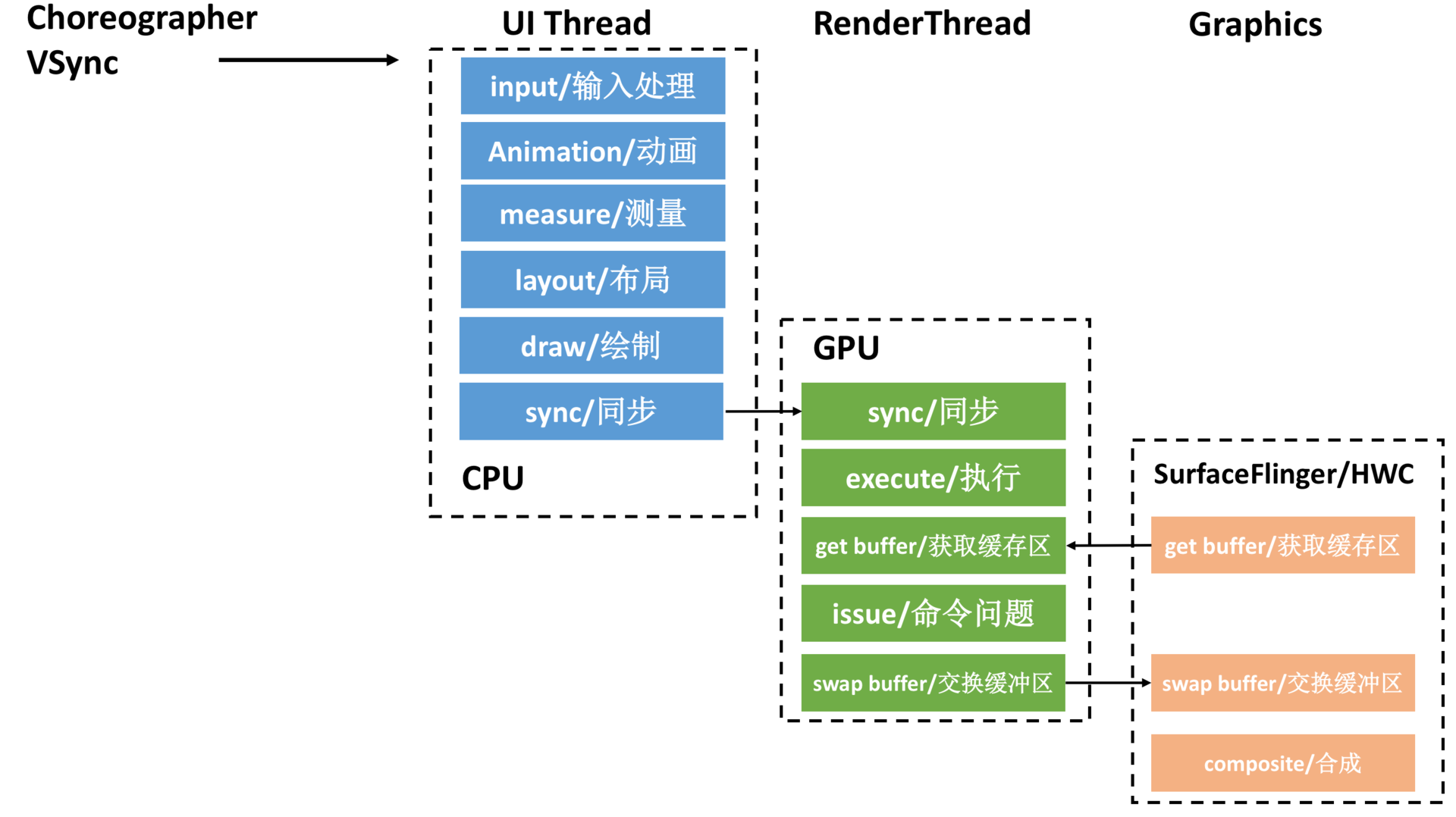
在官方文档[《检查 GPU 渲染速度和绘制过度》](https://developer.android.com/studio/profile/inspect-gpu-rendering)中,我们还可以开启 Profile GPU Rendering 检查。在 Android 6.0 之后,会输出下面的计算和绘制每个阶段的耗时:

如果我们把上面的步骤转化线程模型,可以得到下面的流水线模型。CPU 将数据同步(sync)给 GPU 之后,一般不会阻塞等待 GPU 渲染完毕,而是通知结束后就返回。而 RenderThread 承担了比较多的绘制工作,分担了主线程很多压力,提高了 UI 线程的响应速度。
# 参考资料
[# 20 | UI 优化(上):UI 渲染的几个关键概念](https://blog.yorek.xyz/android/paid/master/ui_1/)
- Android
- 四大组件
- Activity
- Fragment
- Service
- 序列化
- Handler
- Hander介绍
- MessageQueue详细
- 启动流程
- 系统启动流程
- 应用启动流程
- Activity启动流程
- View
- view绘制
- view事件传递
- choreographer
- LayoutInflater
- UI渲染概念
- Binder
- Binder原理
- Binder最大数据
- Binder小结
- Android组件
- ListView原理
- RecyclerView原理
- SharePreferences
- AsyncTask
- Sqlite
- SQLCipher加密
- 迁移与修复
- Sqlite内核
- Sqlite优化v2
- sqlite索引
- sqlite之wal
- sqlite之锁机制
- 网络
- 基础
- TCP
- HTTP
- HTTP1.1
- HTTP2.0
- HTTPS
- HTTP3.0
- HTTP进化图
- HTTP小结
- 实践
- 网络优化
- Json
- ProtoBuffer
- 断点续传
- 性能
- 卡顿
- 卡顿监控
- ANR
- ANR监控
- 内存
- 内存问题与优化
- 图片内存优化
- 线下内存监控
- 线上内存监控
- 启动优化
- 死锁监控
- 崩溃监控
- 包体积优化
- UI渲染优化
- UI常规优化
- I/O监控
- 电量监控
- 第三方框架
- 网络框架
- Volley
- Okhttp
- 网络框架n问
- OkHttp原理N问
- 设计模式
- EventBus
- Rxjava
- 图片
- ImageWoker
- Gilde的优化
- APT
- 依赖注入
- APT
- ARouter
- ButterKnife
- MMKV
- Jetpack
- 协程
- MVI
- Startup
- DataBinder
- 黑科技
- hook
- 运行期Java-hook技术
- 编译期hook
- ASM
- Transform增量编译
- 运行期Native-hook技术
- 热修复
- 插件化
- AAB
- Shadow
- 虚拟机
- 其他
- UI自动化
- JavaParser
- Android Line
- 编译
- 疑难杂症
- Android11滑动异常
- 方案
- 工业化
- 模块化
- 隐私合规
- 动态化
- 项目管理
- 业务启动优化
- 业务架构设计
- 性能优化case
- 性能优化-排查思路
- 性能优化-现有方案
- 登录
- 搜索
- C++
- NDK入门
- 跨平台
- H5
- Flutter
- Flutter 性能优化
- 数据跨平台