
# IO
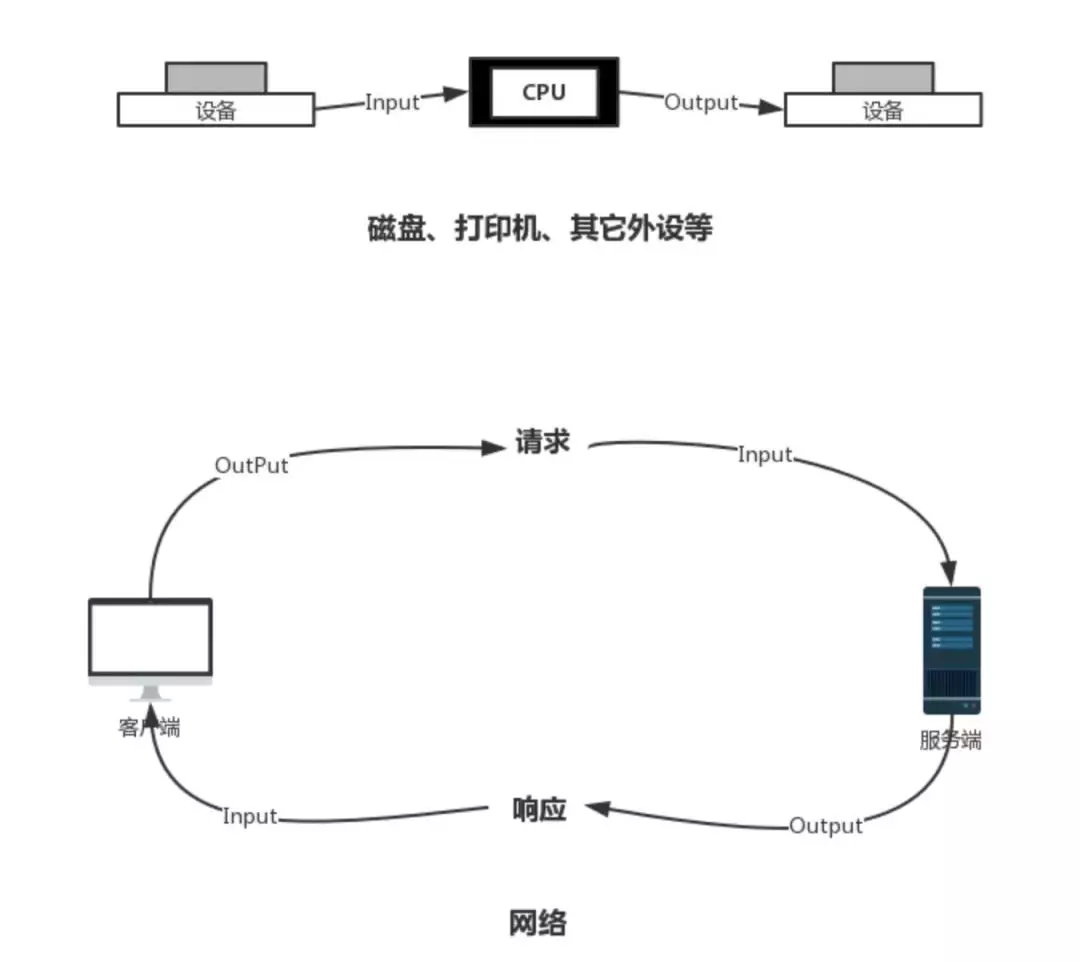
程序与运行时数据在内存中驻留,由CPU负责执行,涉及到数据交换的地方,如磁盘、网络等,就需要IO接口。IO包括输入流(Input Stream)和输出流(Output Stream),来表达数据从一端到另一端的过程。
Input Stream和Output Stream可以以内存为参照标准,加载到内存的是输入流,从内存输出到别的地方的是输出流。比如File存于磁盘中,程序获取File数据用来进行其它操作,这是将数据读入内存中的过程,所以为输入流。反之,程序将各种信息保存入File中,是将数据读出内存的过程,所以为输出流。
再比如,网络操作,请求从客户端来到服务端,也就是数据从客户端到达了服务端,那么对于客户端,是输出流,对服务端,是输入流,响应则相反。如图:
## IO原理
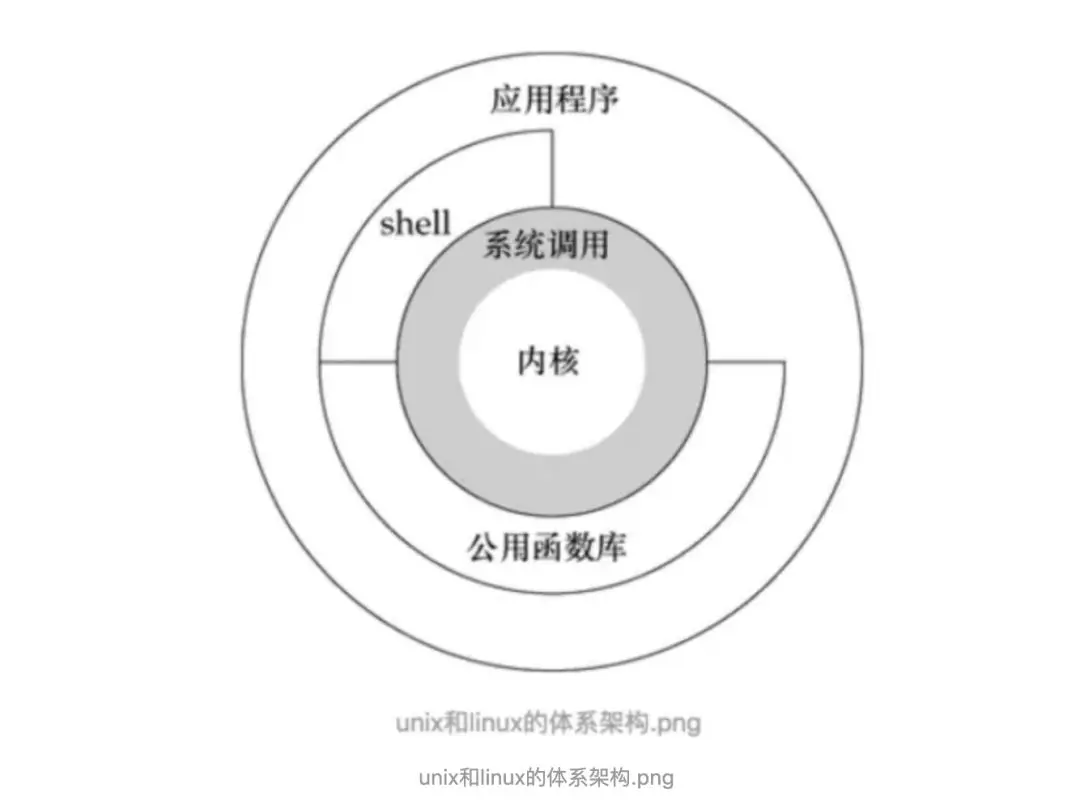
对于操作系统而言,JVM只是一个用户进程,处于用户态空间中,处于用户态空间的进程是不能操作底层硬件的(如磁盘、网卡)。
用户态的进程要访问磁盘和网卡,必须通过系统调用,从用户态切换到内核态才行。因此Java IO读取数据时,用户进程发起读操作,会导致“syscall read”系统调用来从磁盘或网络读取数据;用户进程发起写操作,会导致“syscall write”系统调用来写入到磁盘中或发送到网络中。
1、由于局部性原理,操系统不会每次只读取一个字节(代价太大),而是一次性读取一片(一个或者若干个磁盘块)的数据。
2、用户态与内核态的转化是一个耗时操作,因此IO操作时应尽量减少转化操作。
基于以上两点,需要有一个“中间缓冲区”——即内核缓冲区。用户(JVM)发起读操作时,系统先把数据从磁盘读到内核缓冲区中,然后再把数据从内核缓冲区搬到用户缓冲区;用户(JVM)发起写操作时,先把数据从用户缓冲区搬到内核缓冲区,再把数据从内核缓冲区写入到磁盘或网络中。
# Java IO
数据在两个设备之前的传输序列称为流,设备可以为文件、网络、内存,传输的内容可以为基本类型、序列化对象、本地化字符集
## 分类
根据处理数据类型不同分为:字节流和字符流。
* 字节流:以字节为单位(1Byte)。字节流能处理所有类型的数据
* 字符流:以字符为单位,根据编码格式一次可能读取多个字节。字符流只能处理字符类型的数据
根据流的方向不同可分为:输入流和输出流
* 输入流:表示从一个设备源读取数据,只能进行读操作
* 输出流:表示向一个目标设备写数据,只能进行写操作
Java 相关类:
类|说明
---|---
InputStream|字节输入流
OutputStream|字节输出流
Reader|字符输入流
Writer|字符输出流
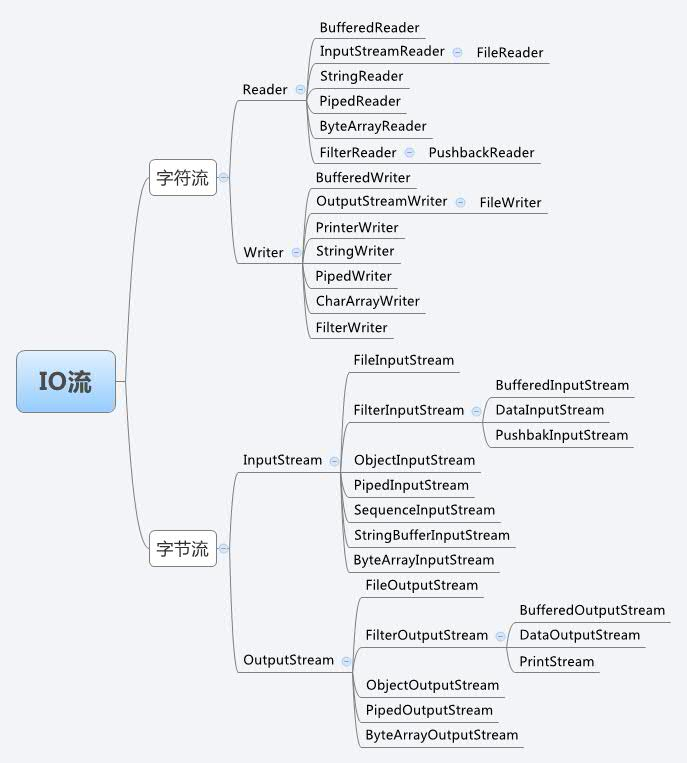
Java 流类图结构:
## InputStream
InputStream 类是所有输入字节流的父类。
其常用子类包括:ByteArrayInputstream、StringBufferInputStream 和 FileInputStream。分别代表从 Byte 数组、StringBuffer 和 本地文件中读取数据
## OutputStream
OutputStream 类是所有输出字节流的父类。
其常用子类包括:ByteArrayOutputstream 和 FileOutputStream。分别代表向 Byte 数组和本地文件中写入数据
## Reader
Reader 类是所有输入字符流的父类。
其常用子类包括:CharReader 和 StringReader。分别代表从 Char 数组和 String 中读取数据
## Writer
Writer 类是所有输出字符流的父类。
其常用子类包括:CharArrayWriter 和 StringWriter。分别代表向 Char 数组和 String 中写入数据
## BufferedOutputStream与BufferedInputStream
### BufferedInputStream
构建一个输入流,示例如下:
```java
DataInputStream dataInputStream = new DataInputStream(new BufferedInputStream(new FileInputStream("test.txt")));
```
使用FileInputStream的read方法读取一个文件时,每次读取一个字节,就需要访问一次磁盘,频繁操作磁盘,效率低下。为了减少访问磁盘的次数,提高文件读取的性能, Java提供了BufferedInputstream类,为其他输入流提供缓冲功能。
创建BufferedInputStream时,会通过构造函数为其指定某个输入流为参数,BufferedInputStream会将该输入流分批读取,每次读取一部分到缓冲区中。当程序需要读取数据时,直接从缓冲区进行读取,由于是从内存缓冲区中读取数
据,比每次从磁盘读取效率高很多。
BufferedInputStream的缓冲区:
```java
// 默认缓冲区大小:8Kb
private static final int DEFAULT_BUFFER_SIZE = 8192;
// 存储数据的缓冲区
protected volatile byte buf[];
// 当前缓冲区的数据索引
protected int pos;
// 构造方法
public BufferedInputStream(InputStream in) {
this(in, DEFAULT_BUFFER_SIZE);
}
public BufferedInputStream(InputStream in, int size) {
super(in);
if (size <= 0) {
throw new IllegalArgumentException("Buffer size <= 0");
}
buf = new byte[size];
}
```
下面来看看从缓冲区读取数据的代码:
```java
public synchronized int read(byte b[], int off, int len) throws IOException {
// 通过查看缓冲区buf是否为null,来判断流是否被释放
getBufIfOpen();
// 检查b[]是否放得下数据
if ((off | len | (off + len) | (b.length - (off + len))) < 0) {
throw new IndexOutOfBoundsException();
} else if (len == 0) {
return 0;
}
int n = 0;
for (;;) {
// 调用私有方法read1来读取数据,nread为已读取到的字节数,没有读取或读取不到数据返回-1
int nread = read1(b, off + n, len - n);
// 读不到数据了,返回
if (nread <= 0)
return (n == 0) ? nread : n;
n += nread;
// 已经读到了目标长度的数据,返回
if (n >= len)
return n;
// 如果输入流已关闭,返回
InputStream input = in;
if (input != null && input.available() <= 0)
return n;
}
}
private int read1(byte[] b, int off, int len) throws IOException {
// 缓冲区的有效数据量
int avail = count - pos;
if (avail <= 0) {
// 需要读取的数据量大于缓冲区的大小,此时使用缓冲区无意义
if (len >= getBufIfOpen().length && markpos < 0) {
// 直接交给InputStream去读取
return getInIfOpen().read(b, off, len);
}
// 缓冲区已经没有数据可以读取,进行填充数据
fill();
// 缓冲区有效数据量
avail = count - pos;
// InputsStream中已经没有有效数据可以读取
if (avail <= 0) return -1;
}
int cnt = (avail < len) ? avail : len;
// 将缓冲区的数据读入b[]
System.arraycopy(getBufIfOpen(), pos, b, off, cnt);
// 更新缓冲区索引位置
pos += cnt;
return cnt;
}
```
其中填充缓冲区方法fill的代码如下:
```java
private void fill() throws IOException {
// 获取缓冲区
byte[] buffer = getBufIfOpen();
if (markpos < 0) {
pos = 0;
} else if (pos >= buffer.length) {
if (markpos > 0) {
int sz = pos - markpos;
System.arraycopy(buffer, markpos, buffer, 0, sz);
pos = sz;
markpos = 0;
} else if (buffer.length >= marklimit) {
markpos = -1;
pos = 0;
} else if (buffer.length >= MAX_BUFFER_SIZE) {
throw new OutOfMemoryError("Required array size too large");
} else { /* grow buffer */
int nsz = (pos <= MAX_BUFFER_SIZE - pos) ?
pos * 2 : MAX_BUFFER_SIZE;
if (nsz > marklimit)
nsz = marklimit;
byte nbuf[] = new byte[nsz];
System.arraycopy(buffer, 0, nbuf, 0, pos);
if (!bufUpdater.compareAndSet(this, buffer, nbuf)) {
throw new IOException("Stream closed");
}
buffer = nbuf;
}
}
count = pos;
// 从InputStream读取数据到缓冲区
int n = getInIfOpen().read(buffer, pos, buffer.length - pos);
if (n > 0) {
count = n + pos;
}
}
```
### BufferedOutputStream
构建一个输出流,示例如下:
```java
DataOutputStream dataOutputStream = new DataOutputStream(new BufferedOutputStream(new FileOutputStream("filePath")));
```
BufferedOutputStream与BufferedInputStream类似,只不过方向是相反的。创建BufferedOutputStream时,也会在构造函数中为其指定一个输出流作为参数,BufferedOutputStream会从OutputStream中分批接收数据并放入缓冲区中,当缓冲区已满时,调用flush方法触发系统调用,将缓冲区数据写入文件或网络。
来看看分批将数据写入缓冲区的write方法:
```java
public synchronized void write(byte b[], int off, int len) throws IOException {
// 要写出的数据大于缓冲区的容量,就不使用缓冲区策略了
if (len >= buf.length) {
// 先将缓冲区数据写出
flushBuffer();
// 调用OutputStream的write方法直接将数据写出
out.write(b, off, len);
return;
}
// 要写出的数据大于缓冲区的剩余容量
if (len > buf.length - count) {
// 先将缓冲区的数据写出
flushBuffer();
}
// 将要写出的数据写入到缓冲区
System.arraycopy(b, off, buf, count, len);
// 更新缓冲区已添加的数据容量
count += len;
}
```
看看flushBuffer方法:
```java
private void flushBuffer() throws IOException {
if (count > 0) {
out.write(buf, 0, count);
count = 0;
}
}
```
代码很简单,就是将缓冲区中的数据写入到输出流中。
## Java IO总结
IO缓冲区的存在,减少了系统调用的次数,提高了效率,但有缓冲区存在必然存在copy的过程,当涉及到双流操作时,比如从一个输入流读入,写入到一个输出流中,就会存在冗余copy的操作,如下:
* 从输入流读出到缓冲区
* 从缓冲区copy到b[]
* 将b[] copy到输出流缓冲区
* 输出缓冲区的数据再读出数据到输出流
上面的情况存在冗余copy操作,我们来看看Okio是怎么处理的。
# Okio
Okio使用Segment来做数据存储,代码如下:
```kotlin
// 存储具体数据的数组
@JvmField val data: ByteArray
// 有效数据索引起始位置
@JvmField var pos: Int = 0
// 有效数据索引结束位置
@JvmField var limit: Int = 0
// 指示Segment是否为共享状态
@JvmField var shared: Boolean = false
// 指示当前Segment是否为数据拥有者
@JvmField var owner: Boolean = false
// 指向下一个Segment
@JvmField var next: Segment? = null
// 指向上一个Segment
@JvmField var prev: Segment? = null
companion object {
// 默认容量大小
const val SIZE = 8192
// 最小分享数据量
const val SHARE_MINIMUM = 1024
}
```
Segment被设计成可以分割的,用pos和limit来标记有效的数据范围,用owner和shared来标识Segment是owner还是被共享者;同时,Segment可以采用双向链表结构进行连接。
# 参考
[Java IO深入理解BufferedInputStream]([https://blog.csdn.net/yhl\_jxy/article/details/79318713](https://blog.csdn.net/yhl_jxy/article/details/79318713))
[Okio好在哪里?](https://url.cn/5xHNb05)
- 导读
- Java知识
- Java基本程序设计结构
- 【基础知识】Java基础
- 【源码分析】Okio
- 【源码分析】深入理解i++和++i
- 【专题分析】JVM与GC
- 【面试清单】Java基本程序设计结构
- 对象与类
- 【基础知识】对象与类
- 【专题分析】Java类加载过程
- 【面试清单】对象与类
- 泛型
- 【基础知识】泛型
- 【面试清单】泛型
- 集合
- 【基础知识】集合
- 【源码分析】SparseArray
- 【面试清单】集合
- 多线程
- 【基础知识】多线程
- 【源码分析】ThreadPoolExecutor源码分析
- 【专题分析】volatile关键字
- 【面试清单】多线程
- Java新特性
- 【专题分析】Lambda表达式
- 【专题分析】注解
- 【面试清单】Java新特性
- Effective Java笔记
- Android知识
- Activity
- 【基础知识】Activity
- 【专题分析】运行时权限
- 【专题分析】使用Intent打开三方应用
- 【源码分析】Activity的工作过程
- 【面试清单】Activity
- 架构组件
- 【专题分析】MVC、MVP与MVVM
- 【专题分析】数据绑定
- 【面试清单】架构组件
- 界面
- 【专题分析】自定义View
- 【专题分析】ImageView的ScaleType属性
- 【专题分析】ConstraintLayout 使用
- 【专题分析】搞懂点九图
- 【专题分析】Adapter
- 【源码分析】LayoutInflater
- 【源码分析】ViewStub
- 【源码分析】View三大流程
- 【源码分析】触摸事件分发机制
- 【源码分析】按键事件分发机制
- 【源码分析】Android窗口机制
- 【面试清单】界面
- 动画和过渡
- 【基础知识】动画和过渡
- 【面试清单】动画和过渡
- 图片和图形
- 【专题分析】图片加载
- 【面试清单】图片和图形
- 后台任务
- 应用数据和文件
- 基于网络的内容
- 多线程与多进程
- 【基础知识】多线程与多进程
- 【源码分析】Handler
- 【源码分析】AsyncTask
- 【专题分析】Service
- 【源码分析】Parcelable
- 【专题分析】Binder
- 【源码分析】Messenger
- 【面试清单】多线程与多进程
- 应用优化
- 【专题分析】布局优化
- 【专题分析】绘制优化
- 【专题分析】内存优化
- 【专题分析】启动优化
- 【专题分析】电池优化
- 【专题分析】包大小优化
- 【面试清单】应用优化
- Android新特性
- 【专题分析】状态栏、ActionBar和导航栏
- 【专题分析】应用图标、通知栏适配
- 【专题分析】Android新版本重要变更
- 【专题分析】唯一标识符的最佳做法
- 开源库源码分析
- 【源码分析】BaseRecyclerViewAdapterHelper
- 【源码分析】ButterKnife
- 【源码分析】Dagger2
- 【源码分析】EventBus3(一)
- 【源码分析】EventBus3(二)
- 【源码分析】Glide
- 【源码分析】OkHttp
- 【源码分析】Retrofit
- 其他知识
- Flutter
- 原生开发与跨平台开发
- 整体归纳
- 状态及状态管理
- 零碎知识点
- 添加Flutter到现有应用
- Git知识
- Git命令
- .gitignore文件
- 设计模式
- 创建型模式
- 结构型模式
- 行为型模式
- RxJava
- 基础
- Linux知识
- 环境变量
- Linux命令
- ADB命令
- 算法
- 常见数据结构及实现
- 数组
- 排序算法
- 链表
- 二叉树
- 栈和队列
- 算法时间复杂度
- 常见算法思想
- 其他技术
- 正则表达式
- 编码格式
- HTTP与HTTPS
- 【面试清单】其他知识
- 开发归纳
- Android零碎问题
- 其他零碎问题
- 开发思路