
[TOC]
# 显示原理
关于画面撕裂与垂直同步,可以参考这篇博文,讲解的很清晰[《什么是画面撕裂?垂直同步,G-sync,Freesync到底有啥用?》](https://zhuanlan.zhihu.com/p/41848908),本文部分摘录于此文。
## 显示基础
在一个典型的显示系统中,一般包括CPU、GPU、Display三个部分, CPU负责计算数据,把计算好数据交给GPU,GPU对图形数据进行渲染,渲染完成后放到帧缓冲区中存储,最后Display负责将帧缓冲区中的数据呈现到屏幕上。
Android手机作为微型计算机,同样由三部分组成。应用层绘制View有三个主要的步骤,分别是measure、layout和draw,具体分析可参考[http://wiki.xuchongyang.com/1262569](http://wiki.xuchongyang.com/1262569)。measure、layout和draw方法主要是运行在系统的应用框架层,而真正将数据渲染到屏幕上的则是系统Native层的SurfaceFlinger服务来完成的,也就是GPU做的。具体流程如下:
Android中LayoutInflater将布局中的xml标签转换为对象,CPU经过计算将它转化为多边形(Polygons)或Texture(纹理)。GPU对多边形或者纹理进行栅格化(Rasterization)操作,栅格化后的数据写入帧缓冲区中等待显示器显示。CPU和GPU是通过图形驱动层来进行连接的,图形驱动层维护了一个队列,CPU将display list添加到该队列中,这样GPU就可以从这个队列中取出数据进行绘制。如图:

### 帧

手机屏幕及显示器也是如此,看上去是“动画”,实际是靠连续播放无数张静态画面来达到一个视觉上的错觉,通过人眼的视觉暂留,让眼睛误以为这是动画。
### 帧速率
GPU是负责图形渲染的,也就是绘制“帧”。
FPS(Frames Per Second)帧速率代表GPU在一秒内绘制的帧数。GPU绘制好帧后交由屏幕来进行展示,理想状态下屏幕每秒展示60帧时人眼感受不到卡顿,动画会比较流畅。1000ms/60帧,即每帧绘制时间不应超过16.67ms。因此要想画面保持在60fps,则需要每个帧绘制时长在16ms以内。
### 屏幕刷新率
屏幕仅仅负责展示帧数据,屏幕都有一个自己的刷新频率,代表屏幕在一秒内刷新的次数。60Hz的屏幕一秒钟就刷新60张画面,120Hz一秒钟就刷新120张画面,其中每一张画面我们都称之为一帧。目前的手机屏幕一般是60Hz,即每16.66ms刷新一帧,当然一些最新推出的手机有些开始采用高刷新率,比如一加7 pro的90Hz。
### 逐行扫描
屏幕在刷新一帧的时候并不是一次性把整个画面刷新出来的,而是从上到下一行一行逐渐把图片绘制出来的,如下图。当然除了逐行扫描还有隔行扫描,也就是隔一行画一行,目前大多数显示器和手机屏幕都是采用逐行扫描。

## 缓冲机制
### 双缓冲机制
屏幕的刷新率是固定的,60Hz的屏幕每隔16.66ms逐行扫描显示一帧,但GPU绘制帧的时间是波动的,因为需要先由CPU进行measure、layout、draw操作,再将布局数据交给GPU进行渲染,当布局嵌套太多太过复杂时,CPU耗时变长,GPU绘制耗时变长,绘制一帧的时间相应也就变长。
GPU输出多个帧时,时间间隔也不一样,如第一帧与第二帧间隔0.01秒,第二帧与第三帧间隔0.04秒,第三帧与第四帧间隔0.03秒,GPU输出帧并不像屏幕固定刷新率,而是会受到视图复杂程度的波动影响。前半秒1帧,后半秒59帧,帧数也是60,但前半秒的帧耗时就很长。
为了避免屏幕刷新速率和GPU绘制帧速率不同造成冲突,引起画面卡顿、闪烁、撕裂等,不能让GPU直接提供帧数据给屏幕进行绘图,而是增加缓冲机制。
只设置一个缓冲区时,由于需要等屏幕读取完缓冲区中的帧数据,GPU才能再次往缓冲区中写入数据,效率较低。因此一般提供2个缓冲区,分别为前缓冲和后缓冲(整个过程中两者身份会互相交换),这就是双缓冲机制。
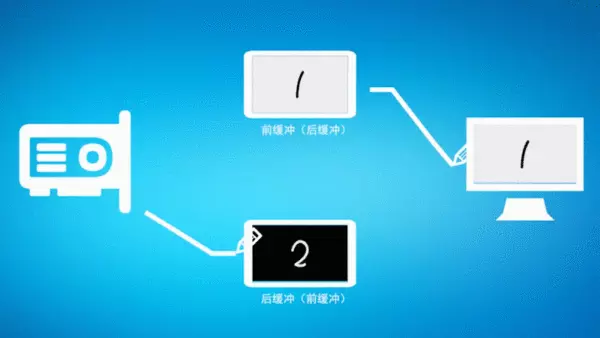
### 可能出现的问题
虽然有了双缓冲机制,但由于GPU绘制帧的时间受布局层级深度和视图复杂度影响较大,因此GPU绘制帧速率不可控,就会出现帧速率大于刷新率和帧速率小于刷新率两种情况:
1、帧速率大于刷新率:画面撕裂与错帧
当然双缓冲机制也会存在一个问题,因为GPU输出帧时间是不固定的,GPU就会出现抢跑的情况:
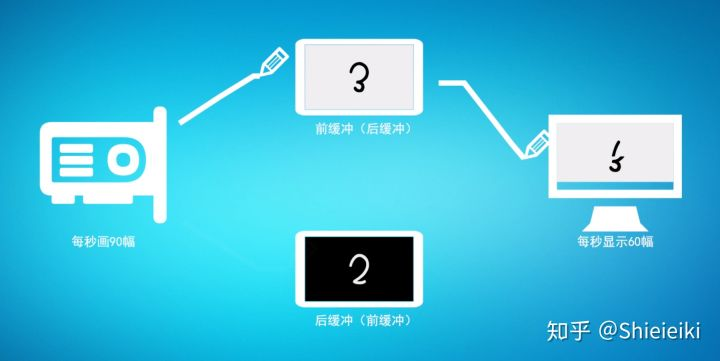
也就是GPU已经画完了1和2,但是屏幕还在逐行扫描1,此时GPU开始画3,就会把1的数据覆盖掉,屏幕继续逐行扫描出来的就是3的下半部分了,就会出现画面撕裂现象。具体如图所示:

在此例中,GPU输出三帧分别是1、2、3。屏幕进行逐行扫描时,第一帧中 1在画面中仅显示一半,接着显示了3的一半;第二帧显示了完整的2;第三帧显示了完整的3。因此虽然屏幕显示了3帧,但肉眼只看到2.5帧。因此当帧速率大于刷新率时,易发生错帧现象,也就是GPU绘制的帧数据并不会全都被显示出来。
2、帧速率小于刷新率:卡顿
如果屏幕刷新率比帧速率快,也就是屏幕已经绘制完缓冲区的数据,但是GPU还未绘制完成下一帧,此时屏幕会在两帧中显示同一个画面,当这种断断续续的情况发生时,用户将会很明显地察觉到动画卡住了或者掉帧,然后又恢复了流畅。我们称此现象为闪屏, 跳帧,延迟,也就是视觉上的卡顿。
3、总结
帧速率比屏幕刷新率高的时候,虽然有可能会丢失部分帧,但用户看到的是非常流畅的画面;而帧速率降下来(GPU绘制太多东西)时,屏幕刷新率比帧速率高,用户看到的就是画面卡顿。
## 垂直同步
垂直同步的出现是为了解决帧速率大于刷新率这种情况。
垂直同步会强制GPU帧速率和屏幕刷新率同步,如果屏幕还在显示前缓冲,而GPU已经写完了后缓冲将要写入前缓冲,此时禁止GPU进行绘制。直到屏幕将前缓冲的画面显示完整,开始显示后缓冲时,才允许GPU去写入前缓冲。
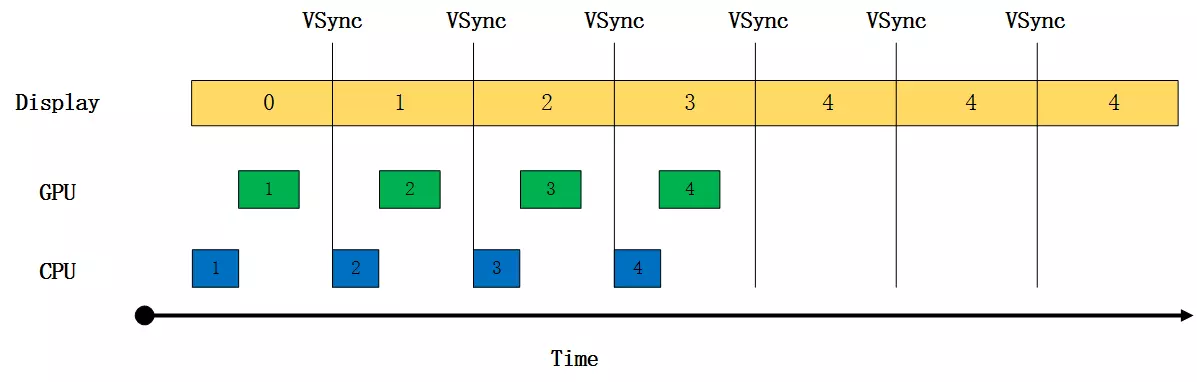
在Android中,系统层会每隔16.66ms发出一个VSYNC信号,GPU会等待VSYNC信号发出,开始绘制帧数据,绘制完一帧后等待下一个VSYNC信号到来时继续绘制。这样GPU绘制帧速率可以和屏幕刷新率保持一致,达到手机的刷新率上限60fps,当然这只是理想情况,当帧速率达到60fps时,GPU需要在16.66ms内准备好一帧,这对于应用的性能要求很高。
# 绘制优化
了解了绘制的原理后,我们就知道了应该在哪里下手要优化绘制。GPU绘制帧的过程我们是无法控制的,但CPU的计算工作我们是可以控制的,我们可以尽量减少measure、layout、draw的时间,留足够多的时间给GPU进行绘制帧。因此绘制优化最直接的操作就是在View的onDraw方法中要避免执行大量操作,具体如下:
1、onDraw中不要创建新的局部对象,因为onDraw方法会被频繁调用,会在瞬间产生大量临时对象,会占用过多内存而且导致频繁gc,降低效率
2、onDraw方法中不要执行耗时任务,也不要执行循环成千上万次的循环操作,大量循环会十分抢占CPU的时间片,造成View绘制过程不流畅。
# 分析GPU渲染速度
GPU 渲染模式分析工具以滚动直方图的形式直观地显示渲染界面窗口帧所花费的时间(以每帧 16 毫秒的速度作为对比基准)。
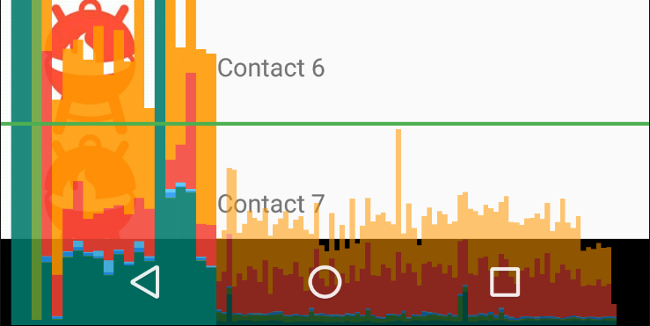
注意的几点:
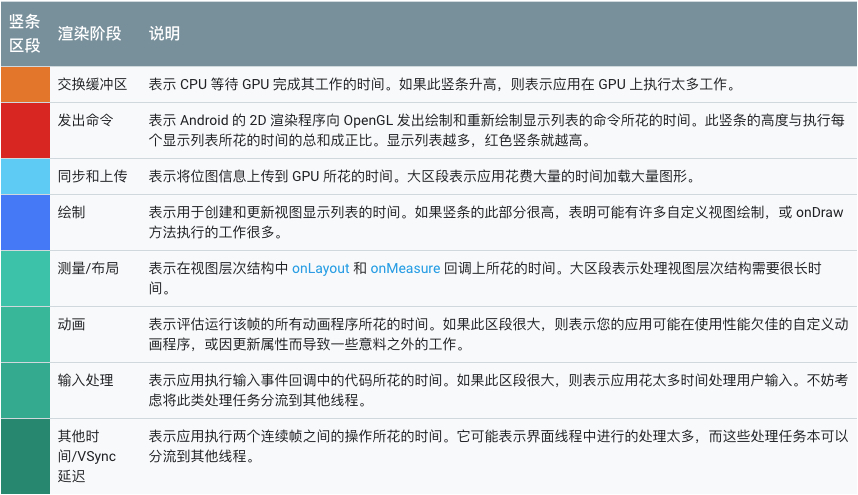
* 沿水平轴的每个竖条代表一个帧,每个竖条的高度表示渲染该帧所花的时间(以毫秒为单位)
* 水平绿线表示 16 毫秒。要实现每秒 60 帧,代表每个帧的竖条需要保持在此线以下。当竖条超出此线时,可能会使动画出现暂停
* 该工具通过加宽对应的竖条并降低透明度来突出显示超出 16 毫秒阈值的帧
* 每个竖条都有与渲染管道中某个阶段对应的彩色区段。区段数因设备的 API 级别不同而异
*****
Android 6.0 及更高版本的设备时分析器输出中某个竖条的每个区段:
Android 4.0 和 5.0 中的竖条区段:

# GPU过度绘制
## 定义
过度绘制(Overdraw)描述的是屏幕上的某个像素在同一帧的时间内被绘制了多次。在多层次重叠的 UI 结构里面,如果不可见的 UI 也在做绘制的操作,会导致某些像素区域被绘制了多次,同时也会浪费大量的 CPU 以及 GPU 资源,绘制示意图如下图所示
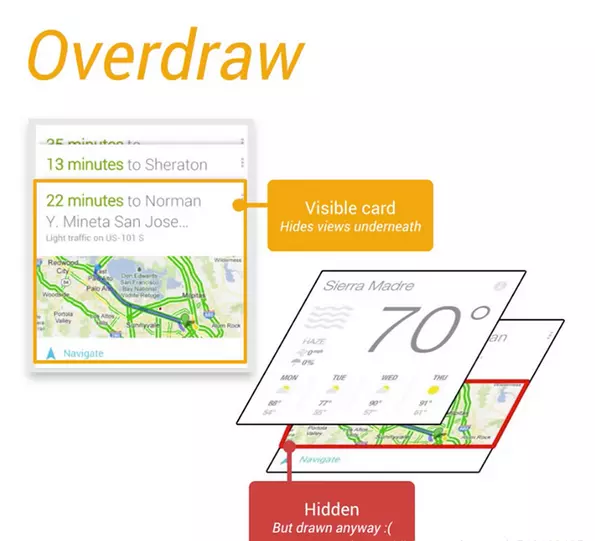
当应用在同一帧中多次绘制相同像素时,便会发生过度绘制。使用开发者选项中的“调试GPU过度绘制”可以可视化的查看过度绘制情况,Android 将按如下方式为界面元素着色,以确定过度绘制的次数:
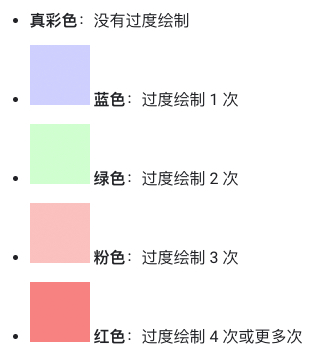
我们在开发应用过程中,应设法达到大部分显示真彩色或只有 1 次过度绘制(蓝色)的视觉效果,来提高应用性能。
## 解决方案
1、去掉Window的默认背景,在onCreate方法的setContentView()之后调用`getWindow().setBackgroundDrawable(null);`或者在theme中添加`android:windowbackground="null";`
2、去掉视图中不必要的背景
3、使用ViewStub仅在需要时才加载
4、使用\<merge>标签合并布局,来减少层级
5、使用\<include>标签重用布局,使布局更清晰明了
6、采用性能较好的ViewGroup如Constraintlayout来精简层级
# 源码角度分析
以下源码分析部分转载于:
[面试官又来了:你的app卡顿过吗?](https://juejin.im/post/5d837cd1e51d4561cb5ddf66)
从View的requestLayout方法开始分析源码,当视图内容有变更时可以调用此方法进行UI更新。
```java
protected ViewParent mParent;
//...
public void requestLayout() {
//...
if (mParent != null && !mParent.isLayoutRequested()) {
mParent.requestLayout();
}
}
```
会调用mParent#requestLayout方法,因为根View是DecorView,DecorView的parent是ViewRootImpl,所以来看看ViewRootImpl#requestLayout方法:
```java
public void requestLayout() {
if (!mHandlingLayoutInLayoutRequest) {
//1 检测线程
checkThread();
mLayoutRequested = true;
//2
scheduleTraversals();
}
}
```
注释1 检测当前是否为主线程:
```java
void checkThread() {
if (mThread != Thread.currentThread()) {
throw new CalledFromWrongThreadException(
"Only the original thread that created a view hierarchy can touch its views.");
}
}
```
注释2:
```java
void scheduleTraversals() {
//1、注意这个标志位,多次调用 requestLayout,要这个标志位false才有效
if (!mTraversalScheduled) {
mTraversalScheduled = true;
// 2. 同步屏障
mTraversalBarrier = mHandler.getLooper().getQueue().postSyncBarrier();
// 3. 向 Choreographer 提交一个任务
mChoreographer.postCallback(
Choreographer.CALLBACK_TRAVERSAL, mTraversalRunnable, null);
if (!mUnbufferedInputDispatch) {
scheduleConsumeBatchedInput();
}
//绘制前发一个通知
notifyRendererOfFramePending();
//这个是释放锁,先不管
pokeDrawLockIfNeeded();
}
}
```
注释1:防止短时间多次调用 requestLayout 重复绘制多次,假如调用requestLayout 之后还没有到这一帧绘制完成,再次调用是没什么意义的。
注释2: 涉及到Handler的一个知识点,同步屏障:往消息队列插入一个同步屏障消息,这时候消息队列中的同步消息不会被处理,而是优先处理异步消息。
注释3:mChoreographer.postCallback( Choreographer.CALLBACK_TRAVERSAL, mTraversalRunnable, null);,往Choreographer 提交一个任务 mTraversalRunnable,这个任务不会马上就执行
下面我们来看看Choreographer#postCallback方法:
```java
public void postCallback(int callbackType, Runnable action, Object token) {
postCallbackDelayed(callbackType, action, token, 0);
}
public void postCallbackDelayed(int callbackType, Runnable action, Object token, long delayMillis) {
if (action == null) {
throw new IllegalArgumentException("action must not be null");
}
if (callbackType CALLBACK\_LAST) {
thrownew IllegalArgumentException("callbackType is invalid");
}
postCallbackDelayedInternal(callbackType, action, token, delayMillis);
}
private void postCallbackDelayedInternal(int callbackType, Object action, Object token, long delayMillis) {
synchronized (mLock) {
finallong now = SystemClock.uptimeMillis();
finallong dueTime = now + delayMillis;
//1.将任务添加到队列
mCallbackQueues[callbackType].addCallbackLocked(dueTime, action, token);
//2. 正常延时是0,走这里
if (dueTime <= now) {
scheduleFrameLocked(now);
} else {
//3. 什么时候会有延时,绘制超时,等下一个vsync?
Message msg = mHandler.obtainMessage(MSG\_DO\_SCHEDULE\_CALLBACK, action);
msg.arg1 = callbackType;
msg.setAsynchronous(true);
mHandler.sendMessageAtTime(msg, dueTime);
}
}
}
```
注释1:将任务添加到队列,不会马上执行
注释2:scheduleFrameLocked,正常的情况下delayMillis是0,走这里
注释3:什么情况下会有延时,TextView中有调用到,暂时不管
下面来看看注释2 的Choreographer#scheduleFrameLocked方法:
```java
// Enable/disable vsync for animations and drawing. 系统属性参数,默认true
private static final boolean USE_VSYNC = SystemProperties.getBoolean(
"debug.choreographer.vsync", true);
...
private void scheduleFrameLocked(long now) {
//标志位,避免不必要的多次调用
if (!mFrameScheduled) {
mFrameScheduled = true;
if (USE_VSYNC) {
if (DEBUG_FRAMES) {
Log.d(TAG, "Scheduling next frame on vsync.");
}
// If running on the Looper thread, then schedule the vsync immediately,
// otherwise post a message to schedule the vsync from the UI thread
// as soon as possible.
//1 如果当前线程是UI线程,直接执行scheduleFrameLocked,否则通过Handler处理
if (isRunningOnLooperThreadLocked()) {
scheduleVsyncLocked();
} else {
Message msg = mHandler.obtainMessage(MSG_DO_SCHEDULE_VSYNC);
msg.setAsynchronous(true);
mHandler.sendMessageAtFrontOfQueue(msg);
}
} else {
final long nextFrameTime = Math.max(mLastFrameTimeNanos / TimeUtils.NANOS_PER_MS + sFrameDelay, now);
if (DEBUG_FRAMES) {
Log.d(TAG, "Scheduling next frame in " + (nextFrameTime - now) + " ms.");
}
Message msg = mHandler.obtainMessage(MSG_DO_FRAME);
msg.setAsynchronous(true);
mHandler.sendMessageAtTime(msg, nextFrameTime);
}
}
}
```
注释1: 判断当前线程如果是UI线程,直接执行scheduleVsyncLocked方法,否则,通过Handler发一个异步消息到消息队列,最终也是到主线程处理,所以直接看scheduleVsyncLocked方法。
那么来看看Choreographer#scheduleVsyncLocked方法:
```java
private final FrameDisplayEventReceiver mDisplayEventReceiver;
private void scheduleVsyncLocked() {
mDisplayEventReceiver.scheduleVsync();
}
```
```java
/**
* Schedules a single vertical sync pulse to be delivered when the next
* display frame begins.
*/
public void scheduleVsync() {
if (mReceiverPtr == 0) {
Log.w(TAG, "Attempted to schedule a vertical sync pulse but the display event "
+ "receiver has already been disposed.");
} else {
nativeScheduleVsync(mReceiverPtr); //1、请求vsync
}
}
// Called from native code. //2、vsync来的时候底层会通过JNI回调这个方法
@SuppressWarnings("unused")
private void dispatchVsync(long timestampNanos, int builtInDisplayId, int frame) {
onVsync(timestampNanos, builtInDisplayId, frame);
}
```
这里的逻辑就是:通过JNI,跟底层说,下一个vsync脉冲信号来的时候请通知我。然后在下一个vsync信号来的时候,就会收到底层的JNI回调,也就是dispatchVsync这个方法会被调用,然后会调用onVsync这个空方法,由实现类去自己做一些处理。
```java
public void onVsync(long timestampNanos, int builtInDisplayId, int frame) {
}
```
这里是屏幕刷新机制的重点,**应用必须向底层请求vsync信号,然后下一次vsync信号来的时候会通过JNI通知到应用,然后接下来才到应用绘制逻辑。**
那么来看看实现类在onVsync方法中做了什么呢?DisplayEventReceiver的实现类是 Choreographer 的内部类 FrameDisplayEventReceiver,来看看该类的onVsync方法:
```java
private final class FrameDisplayEventReceiver extends DisplayEventReceiver
implements Runnable {
private boolean mHavePendingVsync;
private long mTimestampNanos;
private int mFrame;
public FrameDisplayEventReceiver(Looper looper) {
super(looper);
}
@Override
public void onVsync(long timestampNanos, int builtInDisplayId, int frame) {
long now = System.nanoTime();
// 更正时间戳,当前纳秒
if (timestampNanos > now) {
timestampNanos = now;
}
if (mHavePendingVsync) {
//...
} else {
mHavePendingVsync = true;
}
mTimestampNanos = timestampNanos;
mFrame = frame;
Message msg = Message.obtain(mHandler, this); //1 callback是this,会回调run方法
msg.setAsynchronous(true);
mHandler.sendMessageAtTime(msg, timestampNanos / TimeUtils.NANOS_PER_MS);
}
@Override
public void run() {
mHavePendingVsync = false;
doFrame(mTimestampNanos, mFrame); //2
}
}
```
通过Handler,往消息队列插入一个异步消息,指定执行的时间,然后看注释1,callback传this,所以最终会回调run方法,run里面调用doFrame(mTimestampNanos, mFrame);
重点来了,如果Handler此时存在耗时操作,那么需要等耗时操作执行完,Looper才会轮循到下一条消息,run方法才会调用,然后才会调用到doFrame(mTimestampNanos, mFrame);,doFrame干了什么?调用慢了会怎么样?
来看看doFrame方法:
```java
void doFrame(long frameTimeNanos, int frame) {
final long startNanos;
synchronized (mLock) {
...
long intendedFrameTimeNanos = frameTimeNanos;
startNanos = System.nanoTime();
// 1 当前时间戳减去vsync来的时间,也就是主线程的耗时时间
final long jitterNanos = startNanos - frameTimeNanos;
if (jitterNanos >= mFrameIntervalNanos) {
//1帧是16毫秒,计算当前跳过了多少帧,比如超时162毫秒,那么就是跳过了10帧
final long skippedFrames = jitterNanos / mFrameIntervalNanos;
// SKIPPED_FRAME_WARNING_LIMIT 默认是30,超时了30帧以上,那么就log提示
if (skippedFrames >= SKIPPED_FRAME_WARNING_LIMIT) {
Log.i(TAG, "Skipped " + skippedFrames + " frames! "
+ "The application may be doing too much work on its main thread.");
}
// 取余,计算离上一帧多久了,一帧是16毫秒,所以lastFrameOffset 在0-15毫秒之间,这里单位是纳秒
final long lastFrameOffset = jitterNanos % mFrameIntervalNanos;
if (DEBUG_JANK) {
Log.d(TAG, "Missed vsync by " + (jitterNanos * 0.000001f) + " ms "
+ "which is more than the 8frame interval of "
+ (mFrameIntervalNanos * 0.000001f) + " ms! "
+ "Skipping " + skippedFrames + " frames and setting frame "
+ "time to " + (lastFrameOffset * 0.000001f) + " ms in the past.");
}
// 出现掉帧,把时间修正一下,对比的是上一帧时间
frameTimeNanos = startNanos - lastFrameOffset;
}
//2、时间倒退了,可能是由于改了系统时间,此时就重新申请vsync信号(一般不会走这里)
if (frameTimeNanos < mLastFrameTimeNanos) {
if (DEBUG_JANK) {
Log.d(TAG, "Frame time appears to be going backwards. May be due to a "
+ "previously skipped frame. Waiting for next vsync.");
}
//这里申请下一次vsync信号,流程跟上面分析一样了。
scheduleVsyncLocked();
return;
}
mFrameInfo.setVsync(intendedFrameTimeNanos, frameTimeNanos);
mFrameScheduled = false;
mLastFrameTimeNanos = frameTimeNanos;
}
//3 能绘制的话,就走到下面
try {
Trace.traceBegin(Trace.TRACE_TAG_VIEW, "Choreographer#doFrame");
AnimationUtils.lockAnimationClock(frameTimeNanos / TimeUtils.NANOS_PER_MS);
mFrameInfo.markInputHandlingStart();
doCallbacks(Choreographer.CALLBACK_INPUT, frameTimeNanos);
mFrameInfo.markAnimationsStart();
doCallbacks(Choreographer.CALLBACK_ANIMATION, frameTimeNanos);
mFrameInfo.markPerformTraversalsStart();
doCallbacks(Choreographer.CALLBACK_TRAVERSAL, frameTimeNanos);
doCallbacks(Choreographer.CALLBACK_COMMIT, frameTimeNanos);
}
}
```
分析:
1. 计算收到vsync信号到doFrame被调用的时间差,vsync信号间隔是16毫秒一次,大于16毫秒就是掉帧了,如果超过30帧(默认30),就打印log提示开发者检查主线程是否有耗时操作。
2. 如果时间发生倒退,可能是修改了系统时间,就不绘制,而是重新注册下一次vsync信号
3. 正常情况下会走到 doCallbacks 里去,callbackType 按顺序是Choreographer.CALLBACK\_INPUT、Choreographer.CALLBACK\_ANIMATION、Choreographer.CALLBACK\_TRAVERSAL、Choreographer.CALLBACK\_COMMIT
来看 doCallbacks 里的逻辑:
```java
void doCallbacks(int callbackType, long frameTimeNanos) {
CallbackRecord callbacks;
synchronized (mLock) {
final long now = System.nanoTime();
//1. 从队列取出任务,任务什么时候添加到队列的,上面有说过哈
callbacks = mCallbackQueues[callbackType].extractDueCallbacksLocked(now / TimeUtils.NANOS_PER_MS);
if (callbacks == null) {
return;
}
mCallbacksRunning = true;
...
//2.更新这一帧的时间,确保提交这一帧的时间总是在最后一帧之后
if (callbackType == Choreographer.CALLBACK_COMMIT) {
final long jitterNanos = now - frameTimeNanos;
Trace.traceCounter(Trace.TRACE_TAG_VIEW, "jitterNanos", (int) jitterNanos);
if (jitterNanos >= 2 * mFrameIntervalNanos) {
final long lastFrameOffset = jitterNanos % mFrameIntervalNanos + mFrameIntervalNanos;
if (DEBUG_JANK) {
Log.d(TAG, "Commit callback delayed by " + (jitterNanos * 0.000001f)
+ " ms which is more than twice the frame interval of "
+ (mFrameIntervalNanos * 0.000001f) + " ms! "
+ "Setting frame time to " + (lastFrameOffset * 0.000001f)
+ " ms in the past.");
mDebugPrintNextFrameTimeDelta = true;
}
frameTimeNanos = now - lastFrameOffset;
mLastFrameTimeNanos = frameTimeNanos;
}
}
}
try {
Trace.traceBegin(Trace.TRACE_TAG_VIEW, CALLBACK_TRACE_TITLES[callbackType]);
for (CallbackRecord c = callbacks; c != null; c = c.next) {
if (DEBUG_FRAMES) {
Log.d(TAG, "RunCallback: type=" + callbackType
+ ", action=" + c.action + ", token=" + c.token
+ ", latencyMillis=" + (SystemClock.uptimeMillis() - c.dueTime));
}
// 3. 执行任务,
c.run(frameTimeNanos);
}
} ...
}
```
这里主要就是取出对应类型的任务,然后执行任务。
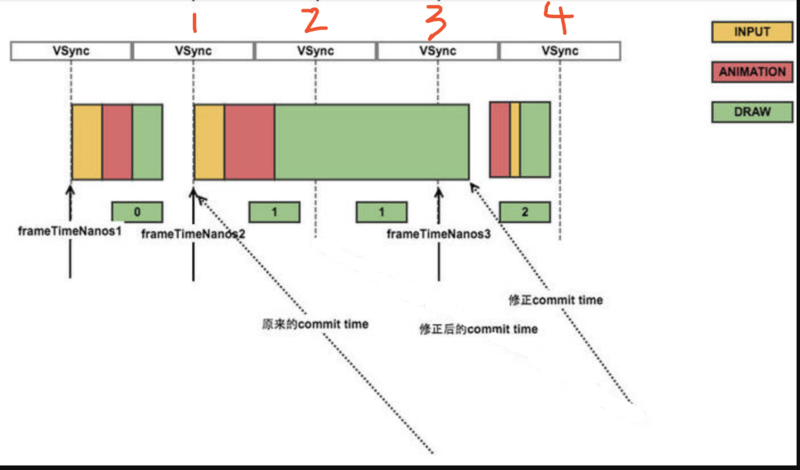
注释2:if (callbackType == Choreographer.CALLBACK\_COMMIT)是流程的最后一步,数据已经绘制完准备提交的时候,会更正一下时间戳,确保提交时间总是在最后一次vsync时间之后。这里文字可能不太好理解,引用一张图:
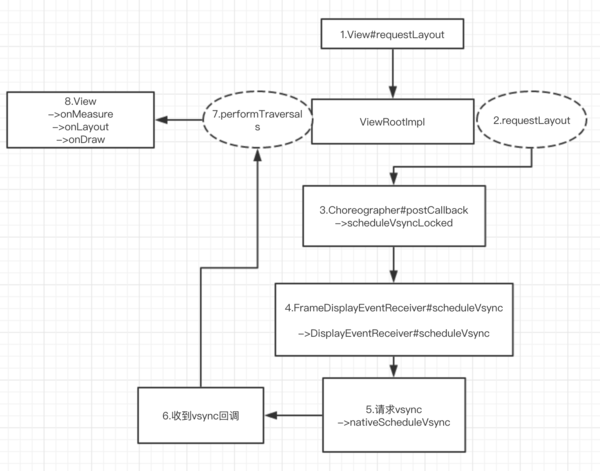
注释3,还没到最后一步的时候,取出其它任务出来run,这个任务肯定就是跟View的绘制相关了,记得开始requestLayout传过来的类型吗,Choreographer.CALLBACK\_TRAVERSAL,从队列get出来的任务类对应是mTraversalRunnable,类型是TraversalRunnable,定义在ViewRootImpl里面,饶了一圈,回到ViewRootImpl继续看~
来看看刚刚 scheduleTraversals 方法中的mTraversalRunnable被调用时做了什么:
```java
final class TraversalRunnable implements Runnable {
@Override
public void run() {
doTraversal();
}
}
```
```java
void doTraversal() {
if (mTraversalScheduled) {
mTraversalScheduled = false;
//移除同步屏障
mHandler.getLooper().getQueue().removeSyncBarrier(mTraversalBarrier);
performTraversals();
}
}
```
先移除同步屏障消息,然后调用performTraversals 方法,performTraversals 这个方法代码有点多,挑重点看:
```java
private void performTraversals() {
// mAttachInfo 赋值给View
host.dispatchAttachedToWindow(mAttachInfo, 0);
// Execute enqueued actions on every traversal in case a detached view enqueued an action
getRunQueue().executeActions(mAttachInfo.mHandler);
...
//1 测量
if (!mStopped || mReportNextDraw) {
// Ask host how big it wants to be
//1.1测量一次
performMeasure(childWidthMeasureSpec, childHeightMeasureSpec);
// Implementation of weights from WindowManager.LayoutParams
// We just grow the dimensions as needed and re-measure if
// needs be
if (lp.horizontalWeight > 0.0f) {
width += (int) ((mWidth - width) * lp.horizontalWeight);
childWidthMeasureSpec = MeasureSpec.makeMeasureSpec(width,
MeasureSpec.EXACTLY);
measureAgain = true;
}
if (lp.verticalWeight > 0.0f) {
height += (int) ((mHeight - height) * lp.verticalWeight);
childHeightMeasureSpec = MeasureSpec.makeMeasureSpec(height,
MeasureSpec.EXACTLY);
measureAgain = true;
}
//1.2、如果有设置权重,比如LinearLayout设置了weight,需要测量两次
if (measureAgain) {
performMeasure(childWidthMeasureSpec, childHeightMeasureSpec);
}
}
...
//2.布局
if (didLayout) {
// 会回调View的layout方法,然后会调用View的onLayout方法
performLayout(lp, mWidth, mHeight);
}
...
//3.画
if (!cancelDraw && !newSurface) {
performDraw();
}
}
```
可以看到,View的三个方法回调measure、layout、draw是在performTraversals 里面,需要注意的点是LinearLayout设置权重的情况下会measure两次。
## 源码分析总结
View 的 requestLayout 会调到ViewRootImpl 的 requestLayout方法,然后通过 scheduleTraversals 方法向Choreographer 提交一个绘制任务,然后再通过DisplayEventReceiver向底层请求vsync信号,当vsync信号来的时候,会通过JNI回调回来,通过Handler往主线程消息队列post一个异步任务,最终是ViewRootImpl去执行那个绘制任务,调用performTraversals方法,里面是View的三个方法的回调。
在我们应用中会造成掉帧有两种情况:
* 一个是主线程有其它耗时操作,导致doFrame没有机会在vsync信号发出之后16毫秒内调用
* 还有一个就是当前doFrame方法耗时,绘制太久,下一个vsync信号来的时候这一帧还没画完,造成掉帧
以上源码分析部分转载于:
[面试官又来了:你的app卡顿过吗?](https://juejin.im/post/5d837cd1e51d4561cb5ddf66)
# 参考
[Android绘制优化(一)绘制性能分析](https://blog.csdn.net/itachi85/article/details/61914979)
[番外——深入垂直同步机制(VSYNC)](https://www.jianshu.com/p/5f93b8ed3bbb)
[什么是画面撕裂?垂直同步,G-sync,Freesync到底有啥用?](https://zhuanlan.zhihu.com/p/41848908)
- 导读
- Java知识
- Java基本程序设计结构
- 【基础知识】Java基础
- 【源码分析】Okio
- 【源码分析】深入理解i++和++i
- 【专题分析】JVM与GC
- 【面试清单】Java基本程序设计结构
- 对象与类
- 【基础知识】对象与类
- 【专题分析】Java类加载过程
- 【面试清单】对象与类
- 泛型
- 【基础知识】泛型
- 【面试清单】泛型
- 集合
- 【基础知识】集合
- 【源码分析】SparseArray
- 【面试清单】集合
- 多线程
- 【基础知识】多线程
- 【源码分析】ThreadPoolExecutor源码分析
- 【专题分析】volatile关键字
- 【面试清单】多线程
- Java新特性
- 【专题分析】Lambda表达式
- 【专题分析】注解
- 【面试清单】Java新特性
- Effective Java笔记
- Android知识
- Activity
- 【基础知识】Activity
- 【专题分析】运行时权限
- 【专题分析】使用Intent打开三方应用
- 【源码分析】Activity的工作过程
- 【面试清单】Activity
- 架构组件
- 【专题分析】MVC、MVP与MVVM
- 【专题分析】数据绑定
- 【面试清单】架构组件
- 界面
- 【专题分析】自定义View
- 【专题分析】ImageView的ScaleType属性
- 【专题分析】ConstraintLayout 使用
- 【专题分析】搞懂点九图
- 【专题分析】Adapter
- 【源码分析】LayoutInflater
- 【源码分析】ViewStub
- 【源码分析】View三大流程
- 【源码分析】触摸事件分发机制
- 【源码分析】按键事件分发机制
- 【源码分析】Android窗口机制
- 【面试清单】界面
- 动画和过渡
- 【基础知识】动画和过渡
- 【面试清单】动画和过渡
- 图片和图形
- 【专题分析】图片加载
- 【面试清单】图片和图形
- 后台任务
- 应用数据和文件
- 基于网络的内容
- 多线程与多进程
- 【基础知识】多线程与多进程
- 【源码分析】Handler
- 【源码分析】AsyncTask
- 【专题分析】Service
- 【源码分析】Parcelable
- 【专题分析】Binder
- 【源码分析】Messenger
- 【面试清单】多线程与多进程
- 应用优化
- 【专题分析】布局优化
- 【专题分析】绘制优化
- 【专题分析】内存优化
- 【专题分析】启动优化
- 【专题分析】电池优化
- 【专题分析】包大小优化
- 【面试清单】应用优化
- Android新特性
- 【专题分析】状态栏、ActionBar和导航栏
- 【专题分析】应用图标、通知栏适配
- 【专题分析】Android新版本重要变更
- 【专题分析】唯一标识符的最佳做法
- 开源库源码分析
- 【源码分析】BaseRecyclerViewAdapterHelper
- 【源码分析】ButterKnife
- 【源码分析】Dagger2
- 【源码分析】EventBus3(一)
- 【源码分析】EventBus3(二)
- 【源码分析】Glide
- 【源码分析】OkHttp
- 【源码分析】Retrofit
- 其他知识
- Flutter
- 原生开发与跨平台开发
- 整体归纳
- 状态及状态管理
- 零碎知识点
- 添加Flutter到现有应用
- Git知识
- Git命令
- .gitignore文件
- 设计模式
- 创建型模式
- 结构型模式
- 行为型模式
- RxJava
- 基础
- Linux知识
- 环境变量
- Linux命令
- ADB命令
- 算法
- 常见数据结构及实现
- 数组
- 排序算法
- 链表
- 二叉树
- 栈和队列
- 算法时间复杂度
- 常见算法思想
- 其他技术
- 正则表达式
- 编码格式
- HTTP与HTTPS
- 【面试清单】其他知识
- 开发归纳
- Android零碎问题
- 其他零碎问题
- 开发思路