
## 一、执行计划
explain这个命令来查看一个SQL语句的执行计划,查看该SQL语句有没有使用上了索引,有没有做全表扫描等;
举例来说:
```
select * from card_info;
explain select * from card_info;
```
一个例子:
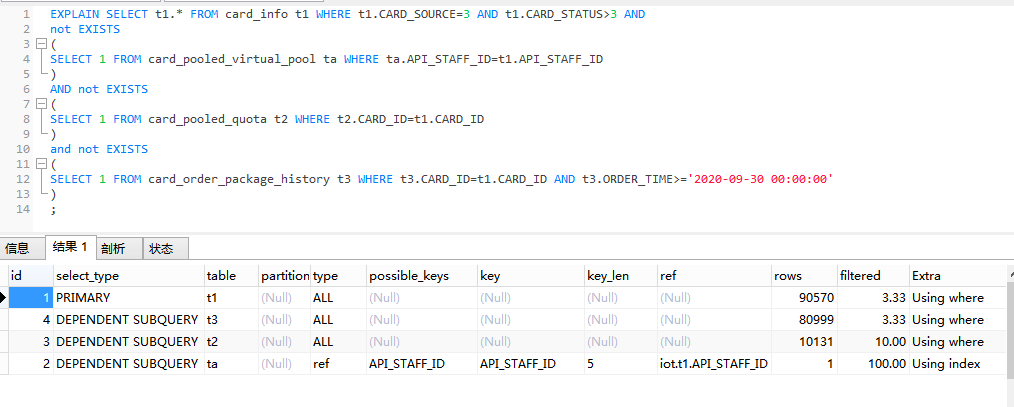
解释:
| 列名 | 说明 |
| --- | --- |
| id | 选择标识符 |
|select_type |表示查询的类型。|
|table |输出结果集的表 |
|partitions |匹配的分区 |
|type |表示表的连接类型 |
|possible_keys |表示查询时,可能使用的索引 |
|key |表示实际使用的索引 |
|key_len |索引字段的长度 |
|ref |列与索引的比较 |
|rows |扫描出的行数(估算的行数) |
|filtered |按表条件过滤的行百分比 |
|Extra |执行情况的描述和说明 |
### **id**
查询的序号,包含一组数字,表示查询中执行select子句或操作表的顺序
1. id相同,执行顺序从上往下;
2. id不同,id值越大,优先级越高,越先执行;
### **select_type**
表示查询中每个select子句的类型;
查询类型,主要用于区别普通查询,联合查询,子查询等的复杂查询
1. simple ——简单的select查询,查询中不包含子查询或者UNION
2. primary ——查询中若包含任何复杂的子部分,最外层查询被标记
3. subquery/dependent subquery——在select或where列表中包含了子查询;
4. derived——在from列表中包含的子查询被标记为derived(衍生),MySQL会递归执行这些子查询,把结果放到临时表中;
5. union——如果第二个select出现在UNION之后,则被标记为UNION,如果union包含在from子句的子查询中,外层select被标记为derived,故在union中第二个及之后的select。
6. union result:UNION 临时表检索结果的select。
### **table**
输出的行所引用的表;
### **partitions**
如果查询基于分区表,将会显示访问的是哪个区;
### **type**
显示连接类型,显示查询使用了何种类型,按照从最佳到最坏类型排序:
1.system:表中仅有一行(=系统表)这是const联结类型的一个特例;
2.const:表示通过索引一次就找到,const用于比较primary key或者unique索引。因为只匹配一行数据,所以如果将主键置于where列表中,mysql能将该查询转换为一个常量;
3.eq_ref:唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配常见于唯一索引或者主键扫描,常用于连接查询。简单查询不会出现该类型;
4.ref:非唯一性索引扫描,返回匹配某个单独值的所有行,本质上也是一种索引访问,是使用普通索引或者唯一性索引的部分前缀,它返回所有匹配某个单独值的行,可能会找多个符合条件的行,属于查找和扫描的混合体;
5.range:只检索给定范围的行,使用一个索引来选择行。key列显示使用了哪个索引,一般就是where语句中出现了between,in等范围的查询。这种范围扫描索引扫描比全表扫描要好,因为它开始于索引的某一个点,而结束另一个点,不用全表扫描;
6.index:index 与all区别为index类型只遍历索引树。通常比all快,因为索引文件比数据文件小很多;
7.all:遍历全表以找到匹配的行;
>[danger]
> 1、性能按照type排序:system > const > eq_ref > ref > range > index > ALL;
> 2、注意:一般保证查询至少达到range级别,最好能达到ref;
### **possible_keys**
指出MySQL能使用哪个索引在表中找到记录,查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被查询使用(该查询可以利用的索引,如果没有任何索引显示 null);
### **Key**
显示MySQL实际决定使用的键(索引)。如果没有选择索引,键是NULL。查询中如果使用覆盖索引,则该索引和查询的select字段重叠。
要想强制mysql使用或者忽视possible_key列中的索引,在查询中使用force index、use index或者ignore index。
### **key_len**
表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度(key_len显示的值为索引字段的最大可能长度,并非实际使用长度,即key_len是根据表定义计算而得,不是通过表内检索出的);
>[danger] 不损失精确性的情况下,长度越短越好
### **ref**
显示索引的哪一列被使用了,如果有可能是一个常数,哪些列或常量被用于查询索引列上的值;
### **rows**
估算出结果集行数,表示MySQL根据表统计信息及索引选用情况,估算的找到所需的记录所需要读取的行数;
### **filtered**
指返回结果的行占需要读到的行(rows列的值)的百分比;
### **Extra**
包含不适合在其他列中显示,但是十分重要的额外信息;
1、Using filesort:说明mysql会对数据适用一个外部的索引排序。而不是按照表内的索引顺序进行读取。MySQL中无法利用索引完成排序操作称为“文件排序”;
2、Using temporary:使用了临时表保存中间结果,mysql在查询结果排序时使用临时表。常见于排序order by和分组查询group by;
3、Using index:表示相应的select操作用使用覆盖索引,避免访问了表的数据行。如果同时出现using where,表名索引被用来执行索引键值的查找;如果没有同时出现using where,表名索引用来读取数据而非执行查询动作;
4、Using where :表明使用where过滤;
5、using join buffer:使用了连接缓存;
6、impossible where:where子句的值总是false,不能用来获取任何元组;
7、select tables optimized away:在没有group by子句的情况下,基于索引优化Min、max操作或者对于MyISAM存储引擎优化count(*),不必等到执行阶段再进行计算,查询执行计划生成的阶段即完成优化;
8、distinct:优化distinct操作,在找到第一匹配的元组后即停止找同样值的动作;
>[danger] 性能按照extra排序
> Using index>Using index condition>Using where>Using join buffer (Block Nested Loop)>Using filesort>Using temporary>Start temporary, End temporary>FirstMatch(tbl_name)
## 二、优化手段
1. SQL语句中IN包含的值不应过多,不能超过200个,200个以内查询优化器计算成本时比较精准,超过200个是估算的成本,另外建议能用between就不要用in,这样就可以使用range索引了。
2. SELECT语句务必指明字段名称:SELECT * 增加很多不必要的消耗(cpu、io、内存、网络带宽);增加
了使用覆盖索引的可能性;当表结构发生改变时,前断也需要更新。所以要求直接在select后面接上字段名;
3. 当只需要一条数据的时候,使用limit 1;
4. 排序时注意是否能用到索引;
5. 使用or时如果没有用到索引,可以改为union all 或者union;
6. 如果in不能用到索引,可以改成exists看是否能用到索引;
7. 不要用全表update或非索引条件update,会导致锁表,引起性能问题;例如,如下语句`update SysStaff set sts=:sts where expDate !='' and expDate<=:now`,必须确保expDate 字段为索引,方可使用,否则,每次执行会锁表;
8. 只要列中包含有NULL值都将不会被包含在索引中,复合索引中只要有一列含有NULL值,那么这一列对于此复合索引就是无效的。所以我们在数据库设计时不要让字段的默认值为NULL;
9. 创建复合索引时应该将最常用作限制条件的列放在最左边,依次递减,因为如果在area、age两列上创建复合索引的话将带来更高的效率。如果我们创建了(area, age,salary)的复合索引,那么其实相当于创建了(area,age,salary)、(area,age)、(area)三个索引,这被称为最佳左前缀特性;
10. 如果取值范围有限,那么也不必建立索引,比如性别可能就只有两个值,建索引不仅没什么优势,还会影响到更新速度,这被称为过度索引;
- 引言
- 01、开发工具
- Maven
- 术语
- 仓库
- Archetype
- 安装配置
- 典型配置
- 内置变量
- eclipse插件
- 本地包安装
- 依赖库更新
- 依赖库排错
- 常见问题
- Gradle
- build.gradle
- gradle插件
- eclipse插件
- Eclipse
- json生成bean
- 常见问题
- IDEA Community
- 工程管理
- maven操作
- 格式化
- 常见问题
- Git
- GitHub
- 快速开始
- 既有工程
- 新建工程
- 日常提交
- PR操作
- 多人协作
- 常用命令
- 常见问题
- 同步代码
- 发布库包
- CodeGenerator
- VSCode
- 安装
- 配置
- 快速开始
- 与GitHub整合
- 断点调试
- 便捷开发
- 扩展
- prettier+
- Vetur
- 前端调试
- F12调试工具
- Vue前端调试
- 测试工具
- 压力测试
- 接口测试
- 抓包工具
- 导入证书
- SecureCRT
- 02、前端技术
- 前端设计
- javascript
- 基本语法
- 数据类型
- 类型转换
- 错误处理
- console对象
- 标准库
- 异步操作
- ES6及后续增强
- 模块化
- 扩展运算符
- 解构变量
- 箭头函数
- 混入模式
- web标准
- css
- html
- HistoryApi
- dom
- 如何理解
- 虚拟dom
- JSON
- svg
- WebAssembly
- web components
- HtmlComponents
- Custom Elements
- 标准扩展
- javascript
- Babel
- TypeScript
- JavaScript
- ECMAScript
- 模块化
- CommonJS
- require
- exports与module.exports
- ES6模块
- export
- import
- AMD
- define
- require
- CMD
- define
- require
- Web Storage
- JSX
- ES6语法
- 语法糖
- ==和===
- let与const
- call&apply
- 内置对象
- Object
- Class
- Promise对象
- then
- catch
- finally
- resolve
- reject
- Module
- Generator函数
- arguments
- 函数扩展
- 数组
- 对象
- Set和Map
- Proxy对象
- css
- sass
- less
- postcss
- CSS Modules
- Node.js
- 安装
- npm
- ls
- init
- install
- run
- uninstall
- update
- version
- npm生态
- yarn
- package.json
- node_modules
- 常用技术
- 应用实例
- Web框架
- Express
- Egg.js
- Mock
- Mock.js
- 语法规范
- 非核心api
- 核心api
- easymock
- 开发测试
- ESLint
- jest
- Travis
- Prettier
- stylelint
- 构建工具
- gulp
- Browserify
- webpack
- 安装配置
- 入口起点entry
- 输出output
- 装载器loader
- 插件plugins
- webpack-cli
- public目录
- 技术概念
- CSR与SSR
- polyfill
- axios
- 请求对象
- 响应对象
- 自定义实例
- 拦截器
- 跨域访问
- 03、前端框架
- mvvm
- vue.js
- 简明指南
- vue文件结构
- 组件指南
- 组件命名
- 应用流程
- 单文件组件
- 组件导入导出
- 生命周期
- Prop
- 复用方法
- 懒加载
- 全局环境
- 全局配置
- 全局API
- 选项对象
- 混入选项
- vue实例$
- vue指令
- v-bind(:)
- v-on(@)
- v-model
- 特殊属性
- 内置组件
- 自定义机制
- 组件
- 指令
- 过滤器
- 混入
- slot插槽
- 渲染函数
- 注意事项
- 总结
- vueCli
- 安装
- 组成部分
- vue.config.js
- vue核心文件
- 状态管理
- 简单状态
- Vuex
- 构造器选项
- 实例属性
- 实例方法
- 绑定辅助函数
- 模块化
- 总结
- 路由管理
- 简单路由
- Vue Router
- 路由模式
- route
- router
- <router-link>与编程式
- <router-view>
- 嵌套路由
- 导航守卫
- 总结
- vue插件
- Vue Loader
- 实战举例
- vue快速入门
- vue与后台联动
- vue完整实例
- vue组件库
- vue-ls
- Enquire.js
- lodash
- md5.js
- moment
- nprogress
- viser-vue
- vue-clipboard2
- vue-cropper
- vue-quill-editor
- wangeditor
- vue-svg-icon-loader
- 实战参考
- Vue Antd Admin
- ant-design-vue
- 快速开始
- 要点解析
- vuepress
- vant
- 04、后端框架
- SprigBoot
- 快速入门
- 完整示例
- 完整进阶
- 核心技术
- 核心标记
- 页面技术
- Thymeleaf
- 数据访问
- 基本用法
- 事务控制
- 事务规则
- 注意事项
- 实体状态
- 数据查询
- 普通查询
- 分页查询
- 统计查询
- 命名访问
- 公用共享
- 缓存机制
- 服务层
- 控制器
- AOP
- 定时任务
- 异步任务
- 静态注入
- WebClient
- 启动机制
- 应用监控
- 线程安全
- 调试测试
- 打包部署
- 打jar包
- 常见问题
- 配置问题
- 开发问题
- 文档生成
- 相关技术
- springfox
- knife4j
- actuator
- kaptcha
- YAML
- API Blueprint
- 启用https
- SpringSecurity
- 快速入门
- 核心元素
- jwt
- 与springsecurity集成
- 05、运行容器
- artemis
- 协议支持
- mqtt
- 安装运行
- 管理配置
- 日志配置
- 业务配置
- 安全配置
- 数据存储
- SSL支持
- 运行维护
- mosquitto
- 安装运行
- 管理配置
- SSL支持
- rocketmq
- 安装运行
- 控制台
- 代码实例
- kafka
- ZooKeeper
- 安装运行
- 代码实例
- zookeeper
- 安装运行
- 应用实例
- dubbo
- 代码实例
- hadoop
- 安装配置
- 快速运行
- netty
- 06、相关技术
- Serverless
- Protobuf
- SSL
- 证书
- 认证类型
- 硬件技术
- 基础知识
- 开发技术
- 消息协议
- 07、项目实战
- 前端开发
- 从零开始开发
- 开发环境搭建
- 原生技术开发
- 路由守卫
- 动态路由菜单
- 全局API
- 登录认证
- 与后端交互
- 代码开发调试
- 快速打包发布
- 常见问题收集
- 后端开发
- 从零开始开发
- 开发环境搭建
- 常用注解说明
- 常用基础设施
- 核心业务约定
- 平台配置文件
- 业务配置清单
- 关键配置参数
- 项目必配参数
- 项目调优参数
- 返回结果处理
- 字段翻译机制
- 列表字段翻译
- 实体字段翻译
- 组合字段翻译
- 列表数据增强
- 列表数据简化
- 返回字段过滤
- 返回字段改名
- 定制返回结果
- 原生技术开发
- 动态级联字典
- 简单数据查询
- 短信验证业务
- 测试数据模拟
- 开放平台登陆
- 微信开放平台
- 抖音开放平台
- 文件处理方案
- 文件字段存储
- 文件字段解析
- 图像数据存取
- 文件资源方案
- 服务集成开发
- redis服务集成
- mqtt服务集成
- kafka集成
- rocketmq集成
- websocket集成
- elasticsearch集成
- netty集成
- 外部工具开发
- 发送短信服务
- 发送邮件服务
- 动态pdf生成
- 数据处理开发
- 同步导出数据
- 异步导出数据
- 同步导入数据
- 异步导入数据
- 多线程与并发
- 线程并发安全
- 操作间隔控制
- 异步待办机制
- 平台定时任务
- 平台异步任务
- 常见注意事项
- 安全相关开发
- 接口安全策略
- 接口限流策略
- 接口授权策略
- 权限相关开发
- 路由权限方案
- 组织权限方案
- 数据权限方案
- 字段权限方案
- 按钮权限方案
- 支付相关开发
- 微信原生支付
- 微信H5支付
- 微信JSAPI支付
- 微信批量转账
- 微信动态支付
- 支付宝移动网站支付
- 支付宝PC网站支付
- 平台缓存机制
- 内置进程内缓存
- 内置分布式缓存
- 平台自定义缓存
- 平台插件机制
- 账号的邀请码
- 账号的二维码
- 定制事件机制
- 约定实现机制
- 请求回调机制
- 启动自动加载
- 平台基础设施
- 动态参数加载
- 定制待定常量
- 定制单位组织
- 平台缓存机制
- 平台外访机制
- 静态资源获取
- 调试打印机制
- 数据源随时用
- 上下文随处拿
- 平台诊断机制
- 平台内置资源
- 强制间隔时间
- 账号扩展开发
- 账号变更事件
- 业务开发指南
- 字典数据获取
- 数据层持久化
- 基础服务调用
- 查询时间范围
- 代码开发调试
- 常见问题收集
- 从零开始
- PCV1运行
- PCV2运行
- H5端运行
- 开发进阶
- 最佳实践
- 开发方案
- 前后分离
- 跨域访问
- 库表设计
- 模型设计
- 容器部署
- 集群部署
- 日志收集
- 动态配置
- 开发管理
- 开发环境
- 代码控制
- 问题跟踪
- 进度跟踪
- 测试环境
- 调试辅助
- DevOps
- 代码风格
- 运行维护
- 基本监控知识
- 线程堆栈分析
- 内存堆栈分析
- 应用诊断工具
- 工程示范
- 后端开发
- 前端开发
- PC端
- 移动端
- 08、内置容器
- 调度服务
- 调度容器
- 快速开发
- 线程并发
- 多点部署
- 本地调试
- 常见问题
- 开放服务
- 快速接入
- 接口开发
- 09、开放平台
- 微信公号
- 环境准备
- 环境配置
- 技术方案
- 获取OpenId
- 常见问题
- 10、平台功能
- 系统管理
- 单位组织
- 角色管理
- 账号管理
- 子账号
- 财务账户
- 开放数据
- 绑定数据
- 套餐权益
- 会员定义
- 变更审核
- 注册审核
- 系统配置
- 路由配置
- 参数配置
- 属性配置
- 树形设置
- 服务接口
- 访问设置
- 系统监控
- 在线用户
- 内存数据
- 系统变量
- 外访数据
- 到访数据
- 操作记录
- 静态字典
- 日志管理
- 元数据
- 接入管理
- 微信公号
- 微信支付
- 开放服务
- 客户端
- 服务列表
- 请求历史
- 请求服务
- 调度服务
- 调度监控
- 11、补充语言
- php
- 生产环境
- 安装
- 初始配置
- nginx集成
- 配置文件
- 语法
- 变量和常量
- 数据类型
- 条件控制
- 运算符
- 数组
- 指针
- 循环控制
- 函数
- 语法糖
- 预定义变量
- session和cookie
- 命名空间
- 面向对象
- 数据库操作
- 表单
- 错误
- 异常
- 过滤器
- JSON
- XML
- AJAX
- Composer
- 开发环境
- 本地调试
- 远程调试
- .net
- 开发环境
- C#快速入门
- 12、依赖容器
- elasticsearch
- 运行配置
- 命令操作
- 中文分词
- Kibana
- Logstash
- 开发技术
- 搜索类型
- 代码示例
- 应用场景
- 常见问题
- nginx
- 下载安装
- 基本配置
- 服务启停
- 安全防护
- 常见问题
- linux
- 常用操作
- 常用命令
- 用户管理
- ftp服务
- 防火墙
- 运维
- 网络安全
- 内核参数
- 安装
- yum源问题
- mysql
- 安装配置
- 快速安装
- 正式安装
- 参数配置
- 性能优化
- 语句优化
- 配置优化
- 设计优化
- 运维常识
- 系统监控
- 连接数
- 超时
- cpu利用率
- 数据备份
- 导入复制
- 经验举例
- 故障处理
- 用户管理
- 系统日志
- 日志清理
- 安全经验
- 集群方案
- MySQL Replication
- MySQL Cluster
- 常见问题
- redis
- 安装配置
- 安装运行
- 参数配置
- 运维常识
- 技术要点
- pubSub
- 操作命令
- 持久化
- 常见问题
- docker
- 安装运行
- 镜像操作
- 容器操作
- 仓库操作
- 实战案例
- kubernetes
- 后记