
使用内核线程实现的方式也被称为1:1实现。内核线程(Kernel-Level Thread,KLT)就是直接由操作系统内核(Kernel,下称内核)支持的线程,这种线程由内核来完成线程切换,内核通过操纵调度器(Scheduler)对线程进行调度,并负责将线程的任务映射到各个处理器上。每个内核线程可以视为内核的一个分身,这样操作系统就有能力同时处理多件事情,支持多线程的内核就称为多线程内核 (Multi-Threads Kernel)
程序一般不会直接使用内核线程,而是使用内核线程的一种高级接口——轻量级进程(Light Weight Process,LWP),轻量级进程就是我们通常意义上所讲的线程,由于每个轻量级进程都由一个 内核线程支持,因此只有先支持内核线程,才能有轻量级进程。这种轻量级进程与内核线程之间1:1 的关系称为一对一的线程模型
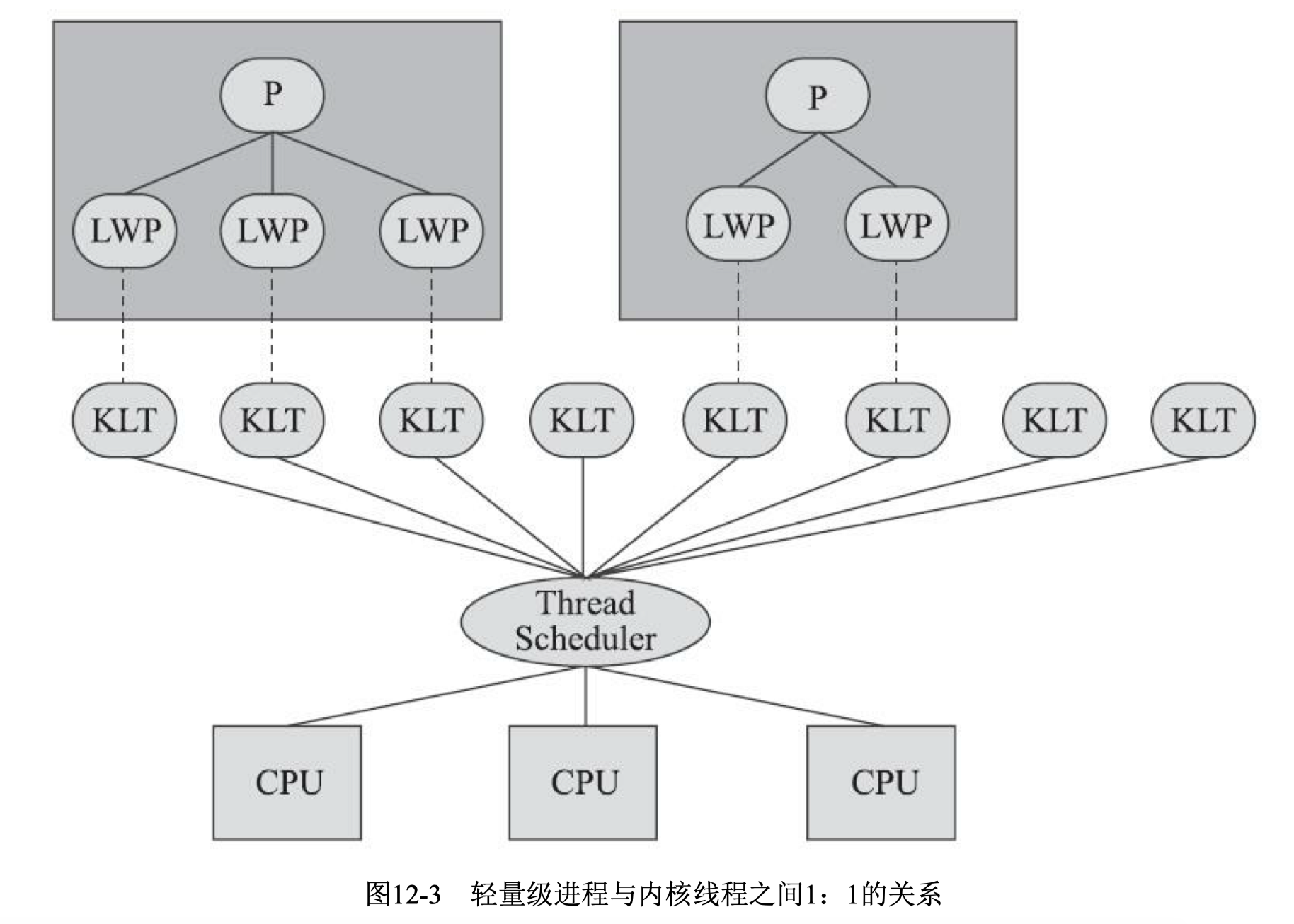
由于内核线程的支持,每个轻量级进程都成为一个独立的调度单元,即使其中某一个轻量级进程 在系统调用中被阻塞了,也不会影响整个进程继续工作。轻量级进程也具有它的局限性:首先,由于是基于内核线程实现的,所以各种线程操作,如创建、析构及同步,都需要进行系统调用。而系统调用的代价相对较高,需要在用户态(User Mode)和内核态(Kernel Mode)中来回切换。其次,每个轻量级进程都需要有一个内核线程的支持,因此轻量级进程要消耗一定的内核资源(如内核线程的栈空间),因此一个系统支持轻量级进程的数量是有限的;
处理器要去执行线程A的程序代码时,并不是仅有代码程序就能跑得起来,程序是数据与代码的 组合体,代码执行时还必须要有上下文数据的支撑。而这里说的“上下文”,以程序员的角度来看,是 方法调用过程中的各种局部的变量与资源;以线程的角度来看,是方法的调用栈中存储的各类信息; 而以操作系统和硬件的角度来看,则是存储在内存、缓存和寄存器中的一个个具体数值。物理硬件的 各种存储设备和寄存器是被操作系统内所有线程共享的资源,当中断发生,从线程A切换到线程B去执 行之前,操作系统首先要把线程A的上下文数据妥善保管好,然后把寄存器、内存分页等恢复到线程B 挂起时候的状态,这样线程B被重新激活后才能仿佛从来没有被挂起过。这种保护和恢复现场的工 作,免不了涉及一系列数据在各种寄存器、缓存中的来回拷贝,当然不可能是一种轻量级的操作
#### 缺点
1:1的内核线程模型是如今Java虚拟 机线程实现的主流选择,但是这种映射到操作系统上的线程天然的缺陷是切换、调度成本高昂,系统 能容纳的线程数量也很有限。以前处理一个请求可以允许花费很长时间在单体应用中,具有这种线程 切换的成本也是无伤大雅的,但现在在每个请求本身的执行时间变得很短、数量变得很多的前提下, 用户线程切换的开销甚至可能会接近用于计算本身的开销,这就会造成严重的浪费
```
内核线程的调度成本主要来自于用户态与核心态之间的状态转换,而这两种状态转换的开销主要 来自于响应中断、保护和恢复执行现场的成本
```
- 简介
- 概述
- 进程vs线程
- 资源限制
- 有关并行的两个定律
- 线程同步和阻塞
- 线程阻塞
- 线程的特性
- 守护线程
- 线程异常
- Thread
- 线程状态
- 线程中断
- wait¬ify
- suspend&resume
- join&yield
- notify¬ifyAll
- Thread.sleep
- 线程任务
- Runnable
- Callable
- Future模式
- FutureTask
- 线程实现方式
- 内核线程实现
- 用户线程实现
- 混合实现
- Java线程的实现
- java与协程
- 纤程-Fiber
- 线程调度
- 多线程协作方式
- 阻塞
- 放弃
- 休眠
- 连接线程
- 线程估算公式
- 线程活跃性
- 死锁
- 线程安全性
- 对象的发布与逸出
- 构造方法溢出
- 线程封闭
- 对象的可变性
- 原子性
- 原子操作
- CPU原子操作原理
- 总线锁
- 缓存锁
- JAVA如何实现原子操作
- long和double读写操作原子性
- Adder和Accumulator
- 线程性能
- 同步工具类
- 闭锁
- CountDownLatch
- FutureTask
- 信号量
- 栅栏
- CyclicBarrier
- Exchanger
- 并发编程
- volatile
- synchronized
- 无锁
- 偏向锁
- 轻量级锁
- 锁的优缺点对比
- 锁升级
- 锁消除
- Monitor
- synchronized语法
- Mutex Lock
- synchronized实践问题
- synchronized&ReentrantLock
- Lock
- ReentrantLock
- Condition
- 读写锁
- ReadWriteLock
- StampedLock
- 线程池
- Executor
- ExecutorService
- Executors
- ThreadPoolExecutor
- RejectedExecutionHandler
- ThreadFactory
- 线程池大小公式
- 动态调整线程池大小
- Fork/Join框架
- ForkJoinPool
- CompletableFuture
- JUC并发工具包
- LockSupport
- 延时任务与周期任务
- Timer
- TimerTask
- 异构任务并行化
- CompletionService
- volatile和synchronized比较
- 锁优化
- 锁相关概念
- 悲观锁(排它锁)
- 乐观锁
- 自旋锁
- 乐观锁vs悲观锁
- JVM锁优化-锁消除
- ThreadLocal
- InheritableThreadLocal
- TransmittableThreadLocal
- ThreadLocalRandom
- 无锁
- AtomicInteger
- Unsafe
- AtomicReference
- AtomicStampedReference
- AtomicIntegerArray
- AtomicIntegerFieldUpdater
- 无锁Vector
- LongAdder
- LongAccumulator
- 常见锁类型
- 悲观锁&独占锁
- 乐观锁
- 乐观锁vs悲观锁
- 自旋锁vs适应性自旋锁
- 公平锁vs非公平锁
- 可重入锁vs非可重入锁
- 独享锁vs共享锁
- 互斥锁
- CAS
- AQS介绍
- AQS深入剖析
- AQS框架
- AQS核心思想
- AQS数据结构
- 同步状态State
- ReentrantLock vs AQS
- AQS与ReentrantLock的关联
- ReentrantLock具体实现
- 线程加入等待队列
- 等待队列中线程出队列时机
- 如何解锁
- 中断恢复后的执行流程
- ReentrantLock的可重入应用
- JUC中的应用场景
- 自定义同步工具
- CLH锁
- 并发框架
- Akka
- Disruptor-无锁缓存框架
- 常见面试题
- 两个线程交替打印A和B
- 附录