
### 等待队列中线程出队列时机
回到最初的源码:
~~~
// java.util.concurrent.locks.AbstractQueuedSynchronizer
public final void acquire(int arg) {
if (!tryAcquire(arg) && acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
~~~
上文解释了addWaiter方法,这个方法其实就是把对应的线程以Node的数据结构形式加入到双端队列里,返回的是一个包含该线程的Node。而这个Node会作为参数,进入到acquireQueued方法中。acquireQueued方法可以对排队中的线程进行“获锁”操作。
总的来说,一个线程获取锁失败了,被放入等待队列,acquireQueued会把放入队列中的线程不断去获取锁,直到获取成功或者不再需要获取(中断)。
下面我们从“何时出队列?”和“如何出队列?”两个方向来分析一下acquireQueued源码:
~~~
// java.util.concurrent.locks.AbstractQueuedSynchronizer
final boolean acquireQueued(final Node node, int arg) {
// 标记是否成功拿到资源
boolean failed = true;
try {
// 标记等待过程中是否中断过
boolean interrupted = false;
// 开始自旋,要么获取锁,要么中断
for (;;) {
// 获取当前节点的前驱节点
final Node p = node.predecessor();
// 如果p是头结点,说明当前节点在真实数据队列的首部,就尝试获取锁(别忘了头结点是虚节点)
if (p == head && tryAcquire(arg)) {
// 获取锁成功,头指针移动到当前node
setHead(node);
p.next = null; // help GC
failed = false;
return interrupted;
}
// 说明p为头节点且当前没有获取到锁(可能是非公平锁被抢占了)或者是p不为头结点,这个时候就要判断当前node是否要被阻塞(被阻塞条件:前驱节点的waitStatus为-1),防止无限循环浪费资源。具体两个方法下面细细分析
if (shouldParkAfterFailedAcquire(p, node) && parkAndCheckInterrupt())
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
}
~~~
注:setHead方法是把当前节点置为虚节点,但并没有修改waitStatus,因为它是一直需要用的数据。
~~~
// java.util.concurrent.locks.AbstractQueuedSynchronizer
private void setHead(Node node) {
head = node;
node.thread = null;
node.prev = null;
}
// java.util.concurrent.locks.AbstractQueuedSynchronizer
// 靠前驱节点判断当前线程是否应该被阻塞
private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {
// 获取头结点的节点状态
int ws = pred.waitStatus;
// 说明头结点处于唤醒状态
if (ws == Node.SIGNAL)
return true;
// 通过枚举值我们知道waitStatus>0是取消状态
if (ws > 0) {
do {
// 循环向前查找取消节点,把取消节点从队列中剔除
node.prev = pred = pred.prev;
} while (pred.waitStatus > 0);
pred.next = node;
} else {
// 设置前任节点等待状态为SIGNAL
compareAndSetWaitStatus(pred, ws, Node.SIGNAL);
}
return false;
}
~~~
parkAndCheckInterrupt主要用于挂起当前线程,阻塞调用栈,返回当前线程的中断状态。
~~~
// java.util.concurrent.locks.AbstractQueuedSynchronizer
private final boolean parkAndCheckInterrupt() {
LockSupport.park(this);
return Thread.interrupted();
}
~~~
上述方法的流程图如下:
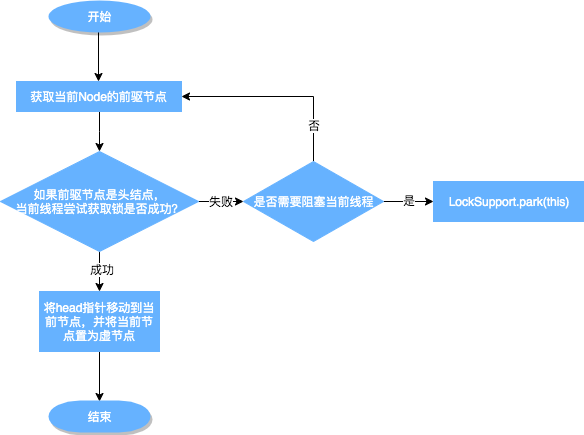
从上图可以看出,跳出当前循环的条件是当“前置节点是头结点,且当前线程获取锁成功”。为了防止因死循环导致CPU资源被浪费,我们会判断前置节点的状态来决定是否要将当前线程挂起,具体挂起流程用流程图表示如下(shouldParkAfterFailedAcquire流程):
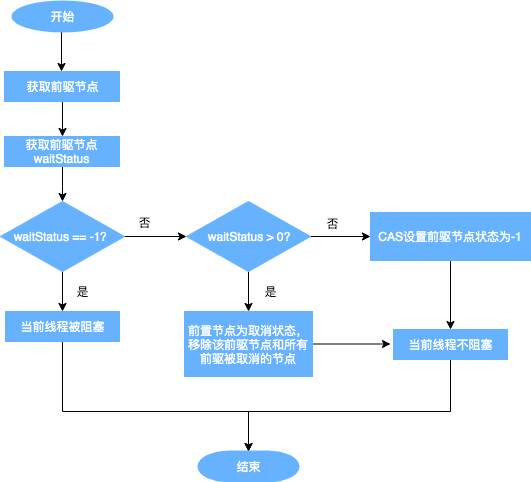
从队列中释放节点的疑虑打消了,那么又有新问题了:
* shouldParkAfterFailedAcquire中取消节点是怎么生成的呢?什么时候会把一个节点的waitStatus设置为-1?
* 是在什么时间释放节点通知到被挂起的线程呢?
### CANCELLED状态节点生成
acquireQueued方法中的Finally代码:
~~~
// java.util.concurrent.locks.AbstractQueuedSynchronizer
final boolean acquireQueued(final Node node, int arg) {
boolean failed = true;
try {
...
for (;;) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
...
failed = false;
...
}
...
} finally {
if (failed)
cancelAcquire(node);
}
}
~~~
通过cancelAcquire方法,将Node的状态标记为CANCELLED。接下来,我们逐行来分析这个方法的原理:
~~~
// java.util.concurrent.locks.AbstractQueuedSynchronizer
private void cancelAcquire(Node node) {
// 将无效节点过滤
if (node == null)
return;
// 设置该节点不关联任何线程,也就是虚节点
node.thread = null;
Node pred = node.prev;
// 通过前驱节点,跳过取消状态的node
while (pred.waitStatus > 0)
node.prev = pred = pred.prev;
// 获取过滤后的前驱节点的后继节点
Node predNext = pred.next;
// 把当前node的状态设置为CANCELLED
node.waitStatus = Node.CANCELLED;
// 如果当前节点是尾节点,将从后往前的第一个非取消状态的节点设置为尾节点
// 更新失败的话,则进入else,如果更新成功,将tail的后继节点设置为null
if (node == tail && compareAndSetTail(node, pred)) {
compareAndSetNext(pred, predNext, null);
} else {
int ws;
// 如果当前节点不是head的后继节点,1:判断当前节点前驱节点的是否为SIGNAL,2:如果不是,则把前驱节点设置为SINGAL看是否成功
// 如果1和2中有一个为true,再判断当前节点的线程是否为null
// 如果上述条件都满足,把当前节点的前驱节点的后继指针指向当前节点的后继节点
if (pred != head && ((ws = pred.waitStatus) == Node.SIGNAL || (ws <= 0 && compareAndSetWaitStatus(pred, ws, Node.SIGNAL))) && pred.thread != null) {
Node next = node.next;
if (next != null && next.waitStatus <= 0)
compareAndSetNext(pred, predNext, next);
} else {
// 如果当前节点是head的后继节点,或者上述条件不满足,那就唤醒当前节点的后继节点
unparkSuccessor(node);
}
node.next = node; // help GC
}
}
~~~
当前的流程:
* 获取当前节点的前驱节点,如果前驱节点的状态是CANCELLED,那就一直往前遍历,找到第一个waitStatus <= 0的节点,将找到的Pred节点和当前Node关联,将当前Node设置为CANCELLED。
* 根据当前节点的位置,考虑以下三种情况:
(1) 当前节点是尾节点。
(2) 当前节点是Head的后继节点。
(3) 当前节点不是Head的后继节点,也不是尾节点。
根据上述第二条,我们来分析每一种情况的流程。
当前节点是尾节点
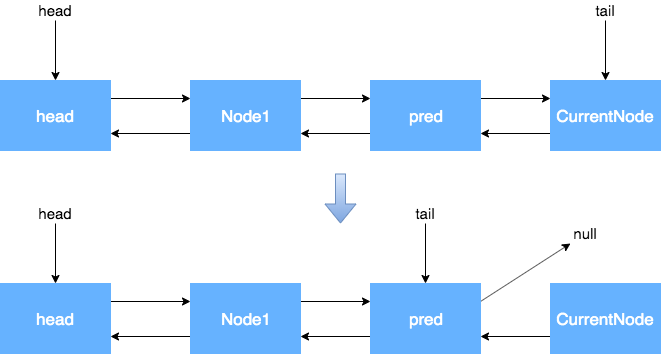
当前节点是Head的后继节点
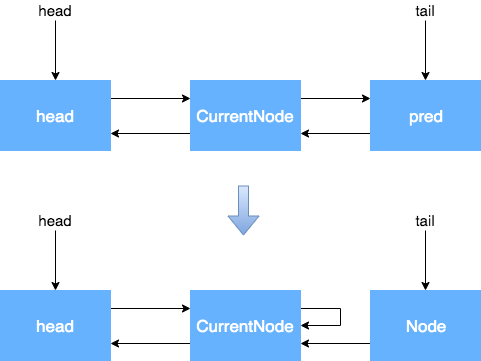
当前节点不是Head的后继节点,也不是尾节点
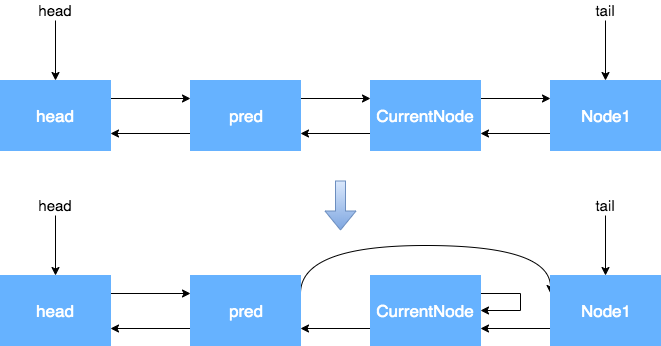
通过上面的流程,我们对于CANCELLED节点状态的产生和变化已经有了大致的了解,但是为什么所有的变化都是对Next指针进行了操作,而没有对Prev指针进行操作呢?什么情况下会对Prev指针进行操作?
> 执行cancelAcquire的时候,当前节点的前置节点可能已经从队列中出去了(已经执行过Try代码块中的shouldParkAfterFailedAcquire方法了),如果此时修改Prev指针,有可能会导致Prev指向另一个已经移除队列的Node,因此这块变化Prev指针不安全。 shouldParkAfterFailedAcquire方法中,会执行下面的代码,其实就是在处理Prev指针。shouldParkAfterFailedAcquire是获取锁失败的情况下才会执行,进入该方法后,说明共享资源已被获取,当前节点之前的节点都不会出现变化,因此这个时候变更Prev指针比较安全。
>
> ~~~
> do {
> node.prev = pred = pred.prev;
> } while (pred.waitStatus > 0);
> ~~~
- 简介
- 概述
- 进程vs线程
- 资源限制
- 有关并行的两个定律
- 线程同步和阻塞
- 线程阻塞
- 线程的特性
- 守护线程
- 线程异常
- Thread
- 线程状态
- 线程中断
- wait¬ify
- suspend&resume
- join&yield
- notify¬ifyAll
- Thread.sleep
- 线程任务
- Runnable
- Callable
- Future模式
- FutureTask
- 线程实现方式
- 内核线程实现
- 用户线程实现
- 混合实现
- Java线程的实现
- java与协程
- 纤程-Fiber
- 线程调度
- 多线程协作方式
- 阻塞
- 放弃
- 休眠
- 连接线程
- 线程估算公式
- 线程活跃性
- 死锁
- 线程安全性
- 对象的发布与逸出
- 构造方法溢出
- 线程封闭
- 对象的可变性
- 原子性
- 原子操作
- CPU原子操作原理
- 总线锁
- 缓存锁
- JAVA如何实现原子操作
- long和double读写操作原子性
- Adder和Accumulator
- 线程性能
- 同步工具类
- 闭锁
- CountDownLatch
- FutureTask
- 信号量
- 栅栏
- CyclicBarrier
- Exchanger
- 并发编程
- volatile
- synchronized
- 无锁
- 偏向锁
- 轻量级锁
- 锁的优缺点对比
- 锁升级
- 锁消除
- Monitor
- synchronized语法
- Mutex Lock
- synchronized实践问题
- synchronized&ReentrantLock
- Lock
- ReentrantLock
- Condition
- 读写锁
- ReadWriteLock
- StampedLock
- 线程池
- Executor
- ExecutorService
- Executors
- ThreadPoolExecutor
- RejectedExecutionHandler
- ThreadFactory
- 线程池大小公式
- 动态调整线程池大小
- Fork/Join框架
- ForkJoinPool
- CompletableFuture
- JUC并发工具包
- LockSupport
- 延时任务与周期任务
- Timer
- TimerTask
- 异构任务并行化
- CompletionService
- volatile和synchronized比较
- 锁优化
- 锁相关概念
- 悲观锁(排它锁)
- 乐观锁
- 自旋锁
- 乐观锁vs悲观锁
- JVM锁优化-锁消除
- ThreadLocal
- InheritableThreadLocal
- TransmittableThreadLocal
- ThreadLocalRandom
- 无锁
- AtomicInteger
- Unsafe
- AtomicReference
- AtomicStampedReference
- AtomicIntegerArray
- AtomicIntegerFieldUpdater
- 无锁Vector
- LongAdder
- LongAccumulator
- 常见锁类型
- 悲观锁&独占锁
- 乐观锁
- 乐观锁vs悲观锁
- 自旋锁vs适应性自旋锁
- 公平锁vs非公平锁
- 可重入锁vs非可重入锁
- 独享锁vs共享锁
- 互斥锁
- CAS
- AQS介绍
- AQS深入剖析
- AQS框架
- AQS核心思想
- AQS数据结构
- 同步状态State
- ReentrantLock vs AQS
- AQS与ReentrantLock的关联
- ReentrantLock具体实现
- 线程加入等待队列
- 等待队列中线程出队列时机
- 如何解锁
- 中断恢复后的执行流程
- ReentrantLock的可重入应用
- JUC中的应用场景
- 自定义同步工具
- CLH锁
- 并发框架
- Akka
- Disruptor-无锁缓存框架
- 常见面试题
- 两个线程交替打印A和B
- 附录