
2021-03-28 周天
## 知识点
***2个数据结构(sds,dict),单机数据库***
### c语言字符串
```
redisLog(warning,'xxx')
```
其中xxx就是用普通字符串类型。
### sds
simple dynamic string - 简单动态字符串。

1. 存的字符串能被修改时,默认使用sds。(比如strings,hash里的key)
***buf指向一个数组,最后存的是一个'\0'空字符,不计算在len长度内***
2. 缓存区
aof 里的buff也是用sds实现。
### dict
保存键值对,也叫做映射,或者关联。
因为C语言没有实现这种高级的数据结构,所以redis实现了自己的字典数据结构。
并且基于字典实现了redis数据库。
应用在hash键和数据库内。
1. dict数据结构
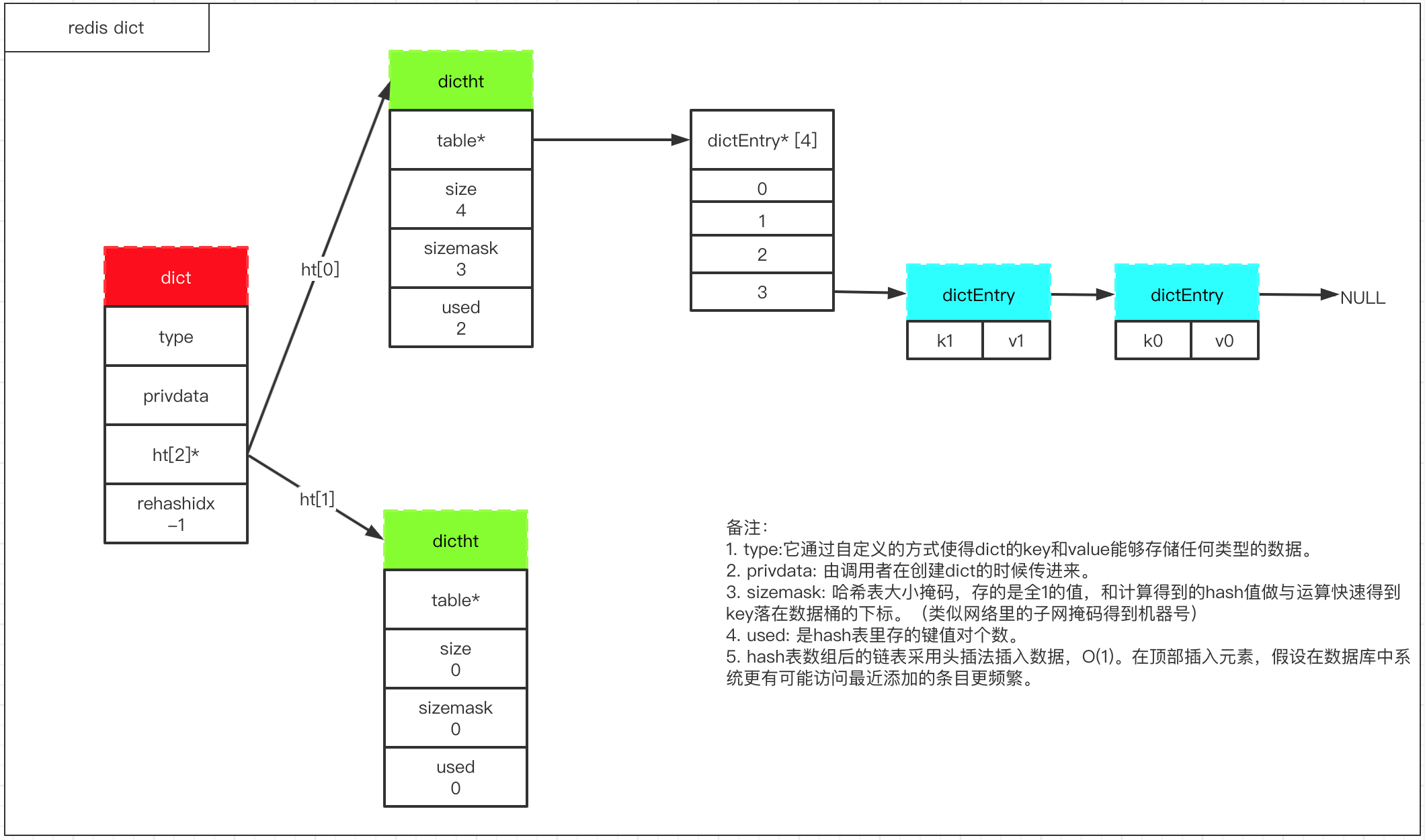
2. hash算法
> Redis不同版本使用的哈希算法并不一样.
> 5.0,4.0 版本使用的siphash.
> 3.2, 3.0, 2.8 使用的是murmurhash2.
3. hash冲突解决
因为就算使用了hash算法,数据量大起来后,会用不同的key落在同一个hash桶的同一个下标,于是数组后面挂的是链表,这样就能解决hash冲突。
4. dict rehash
redis的dict rehash采用渐进式的方式,具体请参考[redis中的hash扩容、渐进式rehash过程](https://zhuanlan.zhihu.com/p/258340429)。
注意点:
* `rehash`时`ht[1].size=ht[0].size * 2`。
* hash表的负载因子计算方式(`load_factor = ht[0].used / ht[0].size`)
* 服务端在存在持久化子进程时,load_factor>=5才会扩容;不存在时,load_factor>=1时会扩容;load_factor<=0.1,会缩容。
* rehash过程是渐进式完成的,比如有1万个key需要转移,会将整个操作分散到客户端对该dict的新增,查询,修改,删除里,分而治之。
* 在rehash过程中,rehashidx=0开始,直到ht[0].used=0,表示rehash完成,rehashidx重置为-1。
* 在rehash过程中,查询操作会先查找ht[0],再查询ht[1];新增操作则直接插入到ht[1]里,保证ht[0].used一直减少。
### redisDb数据库
1. redisServer 和 redisDb的数据结构
``` c
struct redisServer {
...
redisDb *db; /* 一个数组,保存服务端所有数据库 */
int dbnum; /* 配置初始化的db数量,默认16 */
...
}
```
``` c
struct redisDb {
dict *dict; /* 数据库键空间 */
dict *expires; /* 键的超时时间空间 */
...
int id; /* 数据库下标 */
...
}
```
2. redisDb里的键空间,过期时间空间
redis是一个key-value型数据库服务器,服务器上的每个数据库都是由redisDb里的dict字典来保存所有键值对,将这个字典称之为"键空间"。
* 键空间里的键就是数据库里的key,是字符串对象,用的sds。
* 键空间里的值就是数据库里的value,是redis支持的对象类型,比如字符串,列表,哈希表,集合,有序集合对象中的一种。
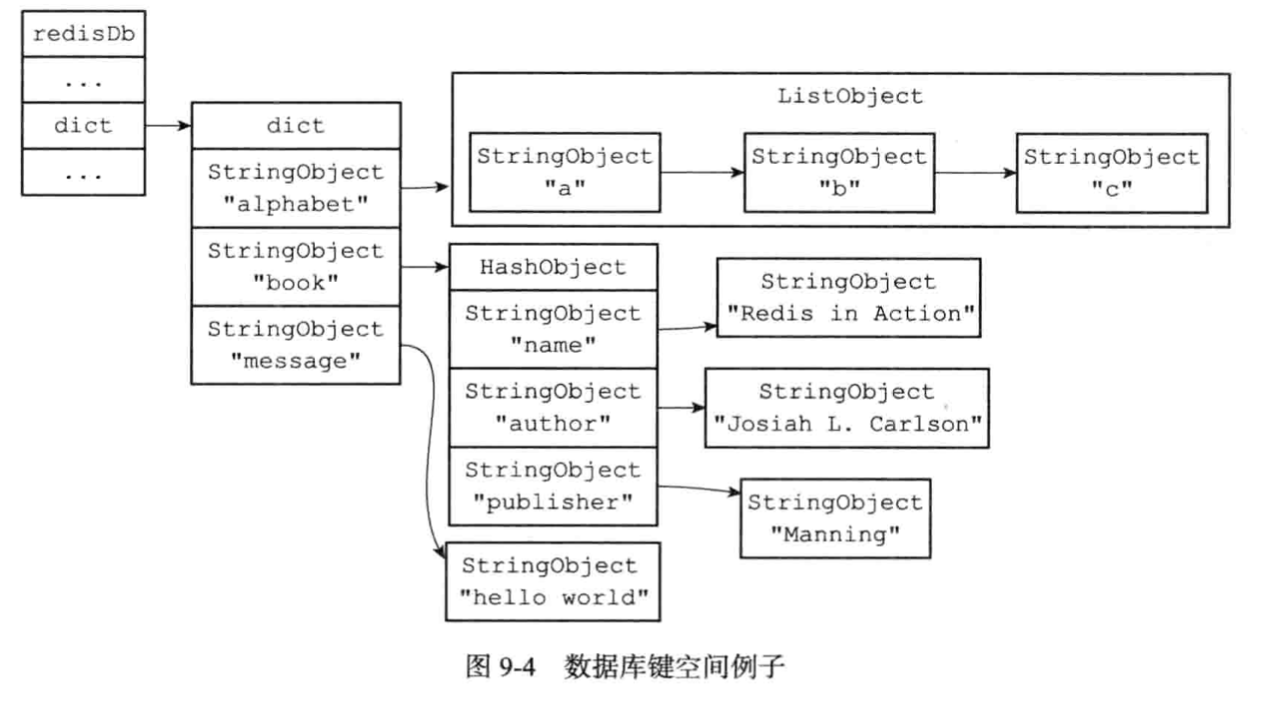
其中超时时间也是用dict字典空间来存储的,而且存的是计算后的时刻。
TTL - 剩余生存时间。
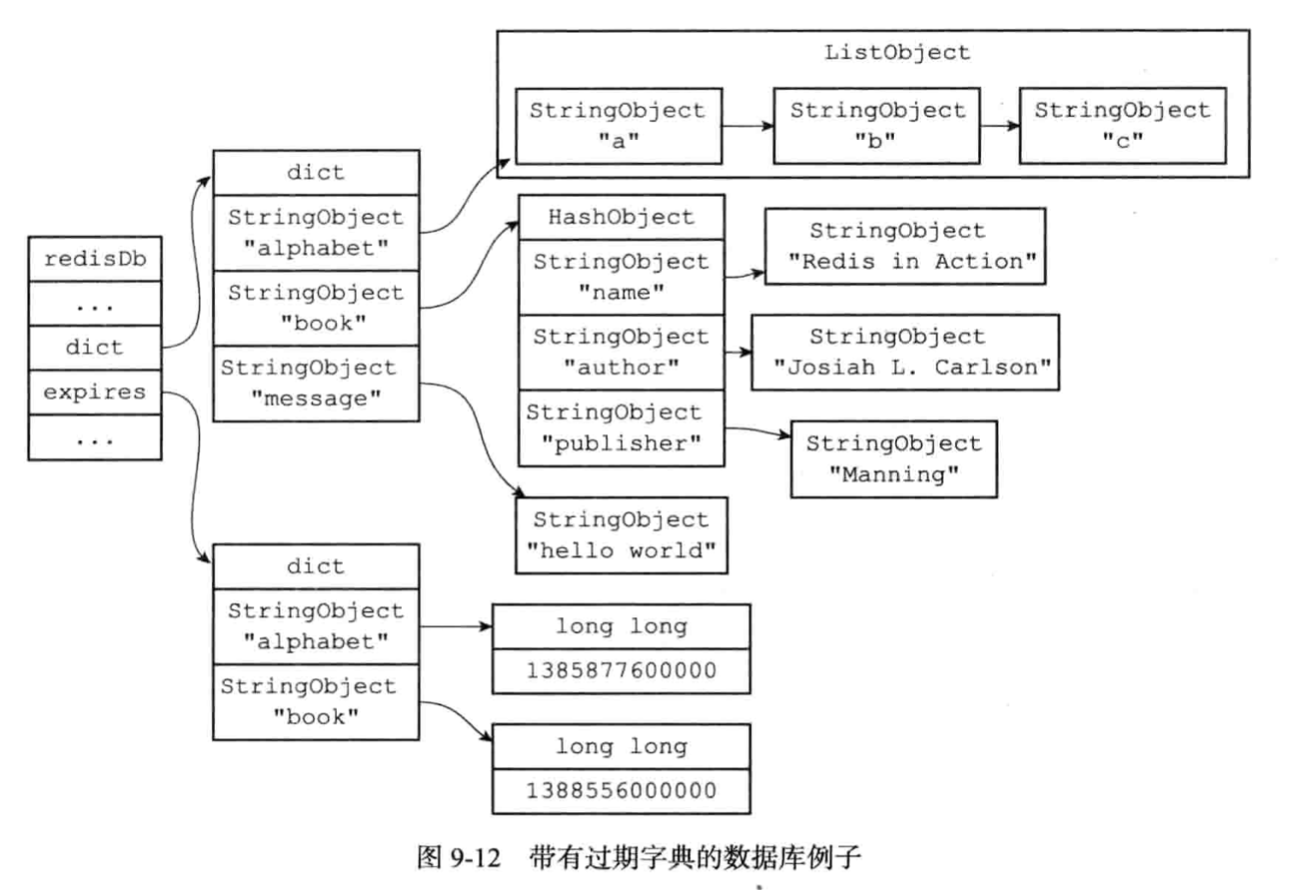
***请参考[info命令统计信息](https://zhuanlan.zhihu.com/p/78297083)***
3. 过期键删除
有如下3种,定时删除策略,惰性删除策略,定期删除策略。
***而redis采用的是惰性删除和定期删除策略***
* 惰性删除实现
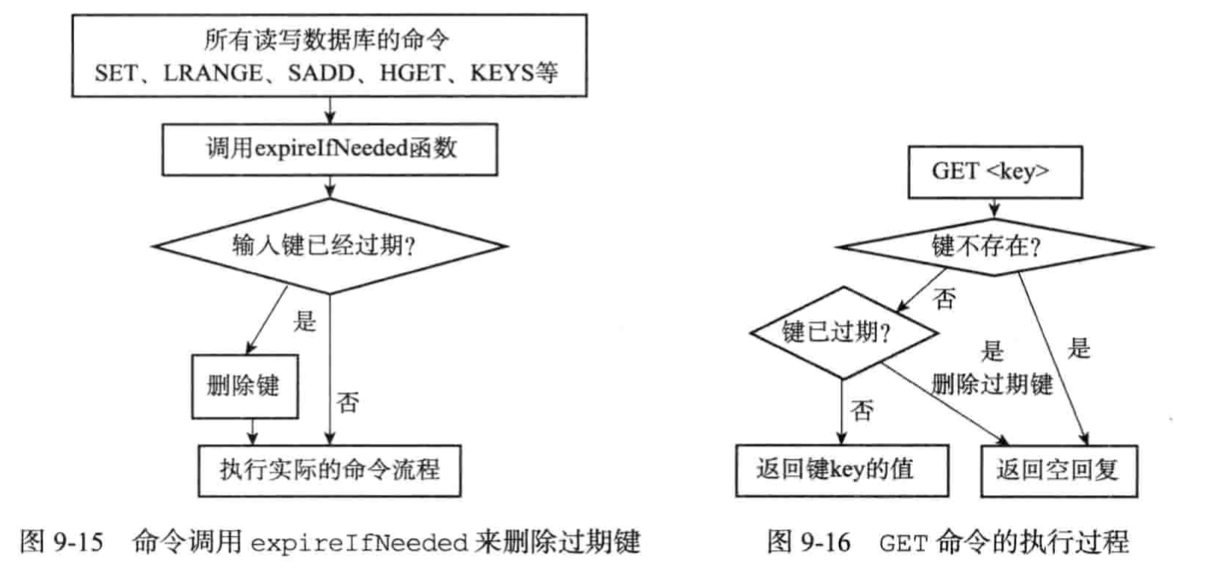
* 定期删除实现
每当服务端执行serverCron周期性执行函数时,就会执行`activeExpiressCycle`函数

分多次检查16个数据库,每个库20个键,如果失效就删除。没有执行完就下次接着执行,unsigned long expires\_cursor; /* Cursor of the active expire cycle. */。
## 会后讨论
* sds vs C字符串
1. sds 长度O(1),C字符串 长度O(n)。
2. sds不需要指定分配长度大小,从而杜绝缓冲区溢出。
3. sds的free实现了空间预分配和惰性释放2种优化方式减少空间重分配次数。
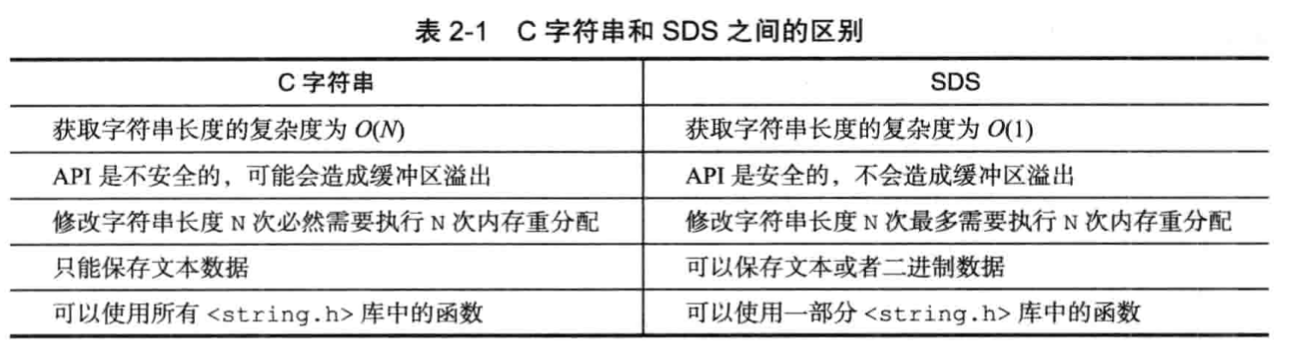
* 二进制安全
sds里存的是字节数组,就是二进制数据。存入什么,读取什么,不会被篡改。不会因为客户端编码异常。
* 序列化
1. 概念
> 序列化:把对象转化为可传输的字节序列过程称为序列化。
> 反序列化:把字节序列还原为对象的过程称为反序列化。
2. 目的
序列化最终的目的是为了对象可以跨平台存储,和进行网络传输。
3. 场景
凡是需要进行“跨平台存储”和”网络传输”的数据,都需要进行序列化。
4. 方式
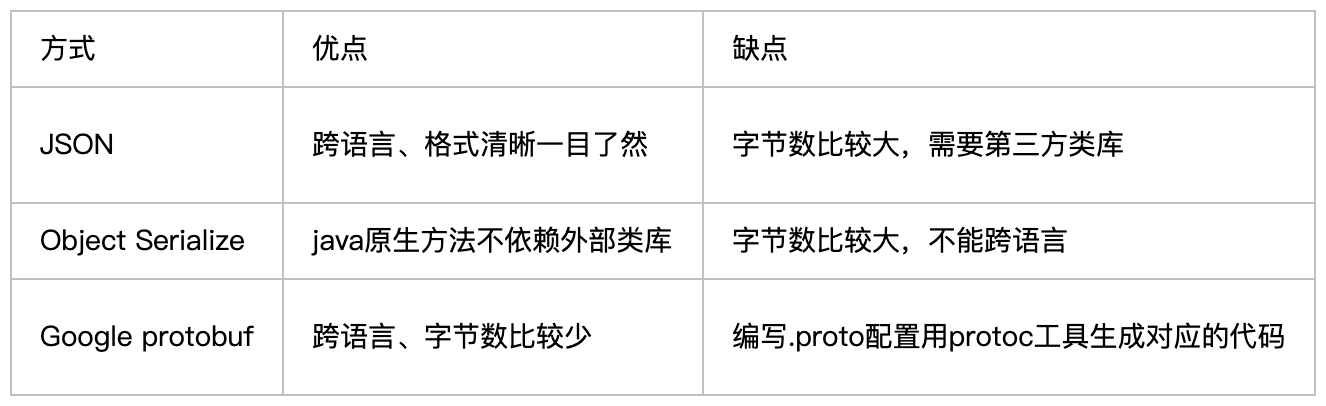
JDK(不支持跨语言)、JSON、XML、Hessian、Kryo(不支持跨语言)、Thrift、Protostuff、FST(不支持跨语言)
5. Java序列化pk
- Redis来回摩擦
- redis的数据结构SDS和DICT
- redis的持久化和事件模型
- Java
- 从何而来之Java IO
- 发布Jar包到公共Maven仓库
- Java本地方法调用
- 面试突击
- Linux
- Nginx
- SpringBoot
- Springboot集成Actuator和SpringbootAdminServer监控
- SpringCloud
- Spring Cloud初识
- Spring Cloud的5大核心组件
- Spring Cloud的注册中心
- Spring Cloud注册中心之Eureka
- Spring Cloud注册中心之Consul
- Spring Cloud注册中心之Nacos
- Spring Cloud的负载均衡之Ribbon
- Spring Cloud的服务调用之Feign
- Spring Cloud的熔断器
- Spring Cloud熔断器之Hystrix
- Spring Cloud的熔断器监控
- Spring Cloud的网关
- Spring Cloud的网关之Zuul
- Spring Cloud的配置中心
- Spring Cloud配置中心之Config Server
- Spring Cloud Config配置刷新
- Spring Cloud的链路跟踪
- Spring Cloud的链路监控之Sleuth
- Spring Cloud的链路监控之Zipkin
- Spring Cloud集成Admin Server
- Docker
- docker日常基本使用
- docker-machine的基本使用
- Kubernetes
- kubernetes初识
- kubeadm安装k8s集群
- minikube安装k8s集群
- k8s的命令行管理工具
- k8s的web管理工具
- k8s的相关发行版
- k3s初识及安装
- rancher的安装及使用
- RaspberryPi
- 运维
- 域名证书更新
- 腾讯云主机组建内网
- IDEA插件开发
- 第一个IDEA插件hello ide开发
- 千呼万唤始出来的IDEA笔记插件mdNote
- 大刚学算法
- 待整理
- 一些概念和知识点
- 位运算
- 数据结构
- 字符串和数组
- LC242-有效的字母异位词
- 链表
- LC25-K个一组翻转链表
- LC83-删除有序单链表重复的元素
- 栈
- LC20-有效的括号
- 队列
- 双端队列
- 优先队列
- 树
- 二叉树
- 二叉树的遍历
- 二叉树的递归序
- 二叉树的前序遍历(递归)
- 二叉树的前序遍历(非递归)
- 二叉树的中序遍历(递归)
- 二叉树的中序遍历(非递归)
- 二叉树的后序遍历(递归)
- 二叉树的后序遍历(非递归)
- 二叉树的广度优先遍历(BFS)
- 平衡二叉树
- 二叉搜索树
- 满二叉树
- 完全二叉树
- 二叉树的打印(二维数组)
- 树的序列化和反序列化
- 前缀树
- 堆
- Java系统堆优先队列
- 集合数组实现堆
- 图
- 图的定义
- 图的存储方式
- 图的Java数据结构(邻接表)
- 图的表达方式及对应场景创建
- 图的遍历
- 图的拓扑排序
- 图的最小生成树之Prim算法
- 图的最小生成树之Kruskal算法
- 图的最小单元路径之Dijkstra算法
- 位图
- Java实现位图
- 并查集
- Java实现并查集
- 滑动窗口
- 单调栈
- 排序
- 冒泡排序BubbleSort
- 选择排序SelectSort
- 插入排序InsertSort
- 插入排序InsertXSort
- 归并排序MergeSort
- 快速排序QuickSort
- 快速排序优化版QuickFastSort
- 堆排序HeapSort
- 哈希Hash
- 哈希函数
- guava中的hash函数
- hutool中的hash函数
- 哈希表实现
- Java之HashMap的实现
- Java之HashSet的实现
- 一致性哈希算法
- 经典问题
- 荷兰国旗问题
- KMP算法
- Manacher算法
- Go