
# [这篇文章比我这篇讲得好...](https://mp.weixin.qq.com/s?__biz=MzUyNDYxNDAyMg==&mid=2247484343&idx=1&sn=efb2f0eacc32e24ca2dd8bed0900f85e&chksm=fa2be35ecd5c6a48246107307ea838c42e807fb6ddf4838228ef552a387e0a02f0c64f1a4606&mpshare=1&scene=23&srcid=#rd)
web都是基于http协议的,作为前端肯定是有必要非常的熟悉http协议。
说道http肯定会讲到网络模型,比如OSI的七层模型,TCP/IP模型,因为以前大学专业学的网络工程,所以一提到网络模型第一个就想到各个层啊之间的联系啊,然后周边什么ip地址 子网划分 mac vlan arp ospf什么的搞得脑子有点乱因为大学也没怎么好好学网络专业(现在还是有点后悔)。现在我们仅仅把自己当做一名前端开发人员来写http相关的吧。
OSI的七层模型(OSI类似于前端中的w3c 一个制定标准的)简化为四层(有说五层将网络接口层又细分为数据链路层、物理层) 现在实际应用中使用的是TCP/IP 四层的模型,最上面上的应用层、中间运输层和网际层,下面网络接口层。 找来一张图,如下能很好说明:
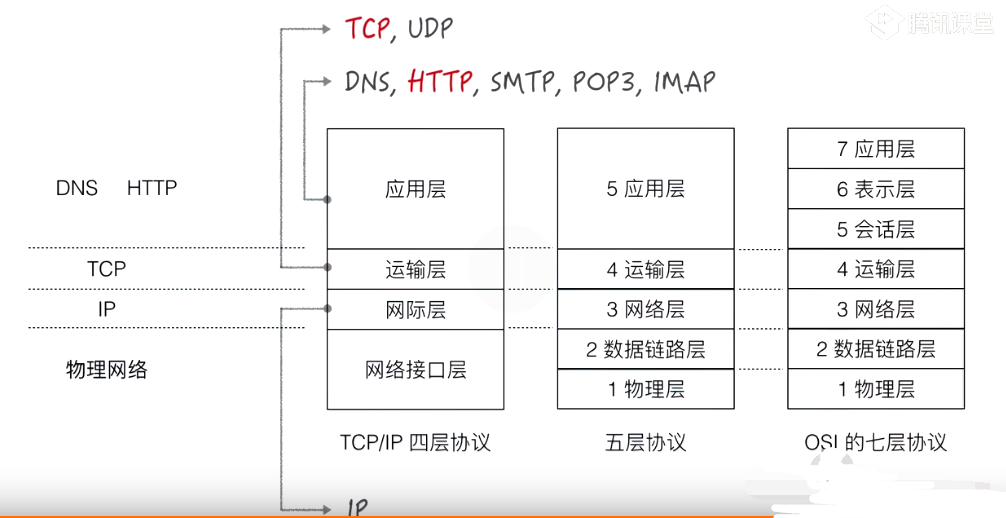
我们前端接触中的http协议属于最上层的协议,在传输层呢使用的是tcp协议,这个tcp协议呢是可靠的协议(有三次握手),但是速度呢逼udp慢一点点,在传输层中使用udp协议的多是对速度比较有需求的比如应用层请求真是IP地址的的dns在传输层就是使用的udp来传输,还有包括像QQ视频也是采用udp(因为是不可靠的,但是最求速度)所有在网速慢的时候 会掉帧其实也就是我们的udp包掉了。
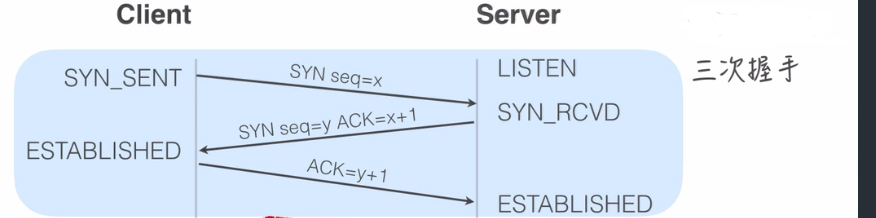
说道**tcp**,其实这个我个人觉得了解一下就好了,因为这个tcp是传输层的协议,仅仅是前端接触最多的http协议在网络模型中传输层采用这个tcp协议来传输,所以有必要了解一下,没必要深入了解,因为就一个tcp协议都够一本砖头厚的书去了解了,如果不是想成CCIE的大牛还是不要浪费时间去深入何况我们只是一枚可爱的小前端,会把脑子搞晕的,下面这张图就是三次握手的过程
## http
接下来说一下**http**,如果说tcp协议只是基于传输层我们可以简单去了解一下,那么http做为上层的应用层协议,那就需要很熟悉了。
MDN的解释可以说非常的好:
> 超文本传输协议(HTTP)是用于传输诸如HTML的超媒体文档的应用层协议。它被设计用于Web浏览器和Web服务器之间的通信,但它也可以用于其他目的。 HTTP遵循经典的客户端-服务端模型,客户端打开一个连接以发出请求,然后等待它收到服务器端响应。 HTTP是无状态协议,意味着服务器不会在两个请求之间保留任何数据(状态)
>
HTTP报文结构
做开发抓包分析肯定是少不了,但是作为前端的话只需要关心http报文即可,所以不需要像一些cs软件开发,装什么wireshake什么包一股脑给你抓过来,我们只关心http的包所以其实个人觉得谷歌浏览器的network差不多够我自己用了,而且报文处理过更加易读。
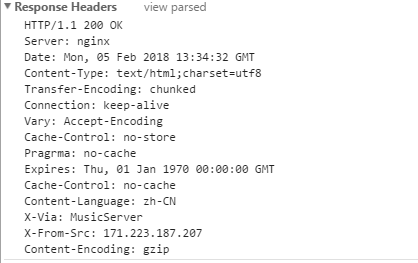
打开浏览器 输入网易云回车 看看http的报文如下:
请求报文头部:

返回的报文头部
返回的主体内容
一般一个请求报文的格式如下:
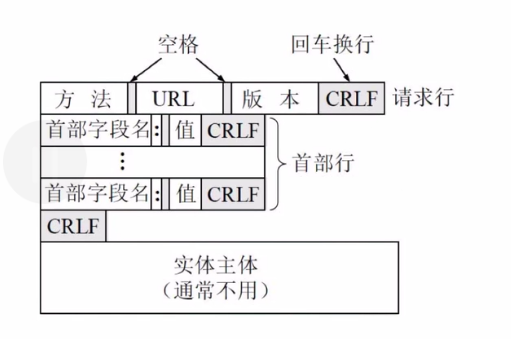
一般一个返回报文的格式如下:
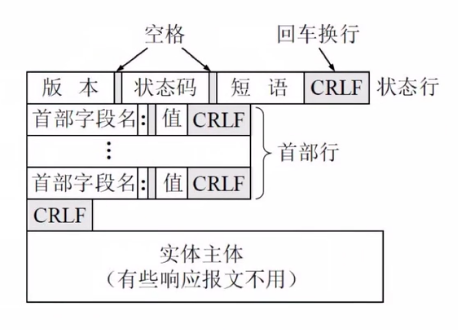
这里返回报文的状态码,比较常见的有4xx(找不到客户端出错),2xx(ok),3xx(缓存重定向),5xx(服务器的锅T.T)
#### **浏览器的缓存**
在想怎么写明白浏览器缓存的时候检索到一篇非常好的文章,来自一位腾讯的大牛博客的文章,写的非常好非常的清楚,我就不献丑了,下面直接转载这位大牛的文章了,大牛的博客地址:www.villainhr.com 。
亲,你知道缓存是什么吗?
其实缓存就像办健身卡,我第一次花了699办了一年的卡之后,接下来的一年我都可以免费锻炼。 在web 中, 我们交的不是钱,而是空间,我们耗费一定的空间之后,能够获得网页打开速度质的飞跃。 当我们第一次访问一个页面时,我们需要交纳一定的空间, 将下载的css,js,html已经img等相关资源保存在本地。 在第二次,第三次。。。访问时,就可以不用去下载文件了。 通常来说,设置文件的缓存有两种方式,一种是在服务器内设置响应头文件,另外一个是使用h5的manifest文件来进行相关设置. 我们先看看报文设置响应头的方式吧
这里的缓存分为2种,一种是强缓存,一种是协商缓存(原文没有,我在这里补充的)
### 服务器的缓存协商
这种方式设置的缓存有两种,一种是需要服务器验证,另外一种是不用发送请求验证。
### ETag/Last-Modified
这两种方式做法类似,都要向服务器发送一次请求进行验证。简直,缓存就缓存呗,为什么还要验证呢? 其实,这是该协议的一种特有方式,发送一次验证主要是检查文件是否发生变化。
#### ETag
ETag是用来计算文件的内容是否发生变化,比如,你在文件中删除一个空格,这样都算文件内容发生变化。 通常做法是用md5或者SHA1算法,计算出文件的唯一值。 在前端其实都可以完成, 找到一个文件文件解析的md5算法,然后将文件传入,就可以得到ETag的值。 不过这里,我们着重点并不是让你生成Etag,而是看看ETag在缓存中的重要作用。 ETag是HTTP/1.1A的一种办法,由Web服务器生成,并写入响应头中。
~~~
//response Headers
ETag:"751F63A30AB5F98F855D1D90D217B356"
~~~
接着,到了浏览器之后,便缓存在本地。 当下次打开同样的文章时,会在请求头中发送If-None-Match, 给服务器检查文件是否发生变化。如果没有,则告诉浏览器使用本地的,否则返回新文件
~~~
//request Headers
If-None-Match: "751F63A30AB5F98F855D1D90D217B356"
~~~
通常情况下,服务器默认是打开Etag的,但是为了防止你的同事,或者后台哥哥的后台配置文件不正确,关闭了Etag,这时候,就需要你对对配置文件做一些设置。 这里我以Nginx为例: 打开ngnix.conf文件,检查是否有以下语句:
~~~
etag off;
more_set_headers -s 404 -t 'ETag';
more_clear_headers 'Etag';
~~~
如果有则将其删除掉。然后重启nginx就可以了。他们将Etag关闭的原因其实也很简单,就是因为,Etag打开之后会增加服务器的负载,造成性能的局限性,所以,关闭或者打开Etag都要经过权衡的。
### Last-Modified
这和文档内容信息验证不同,这里采用的是日期验证办法。 即,服务器上会对文件打上一个文件改动的日期,然后客户端接受该日期,下次请求时,返回该日期,服务器验证,如果日期未变,则告诉浏览器使用本地缓存即可。 即,在服务器的相应头中,可以设置Last-Modified,来启用这一缓存协议.
~~~
//Response Header
Last-Modified:Tue, 03 Mar 2015 01:38:18 GMT
~~~
接受到这一响应头之后,浏览器会对该文件做一个缓存,并保存该日期。当下次请求的时候,会通过If-Modified-Since将日期传入并验证:
~~~
If-Modified-Since:Tue, 03 Mar 2015 01:38:18 GMT
~~~
如果日期未变,则告诉浏览器使用缓存。 那我们通常应该怎样启用服务器这一功能呢? 默认情况下,服务器会对静态资源发送Last-modified的tag。 但是,需要注意,Last-Modified的更新时间只能以秒来计,如果你文件改动过于频繁,Last-Modified是无效的(不过,谁牛逼到1s内能多次更新文件嘞~) 实际上.Last-Modified的这个标签的我们通常并不会单独使用它,通常与expires结合,形成一个可降级的缓存.
### Expires/Cache-Control
Expires/Cache协议与上述验证协议最大的不同在于,他可以省略发送验证请求环节,不需要服务器的验证,而直接使用本地缓存。 通常这种方式,适用于,项目稳定,版本迭代不多的时候。
### Expires
在服务器端可以设置Expires的一个绝对时间。
~~~
//Response Headers
Expires:Tue, 03 May 2016 09:33:34 GMT
~~~
这告诉浏览器,在2016.5.3号之前,可以直接使用该文本的缓存副本。但是,可能会因为服务器和客户端的GMT时间不同,会有一定的bug。 所以,这里只提议在长时间缓存的情况下使用。否则,应该选择Cache-Control. 那在服务器端该怎么设置呢? 这里以nginx为例:
~~~
location ~* \.(?:css|js)$ {
expires 1d;
access_log off;
add_header Cache-Control "public";
}
~~~
通过expires设置过期时间为一天,此时,服务器会根据当前的时间,加上一天.同时添加Expires和Cache-Control头部标签。 即,得到的Response Header为:
~~~
Expires: Fri, 28 Feb 2014 10:42:09 GMT
Cache-Control: max-age=86400 //24*60*60
(HTTP规定,如果出现max-age和expires,则max-age默认覆盖掉expires) 当expires为负数表示no-cache,正数或零表示max-age=time。 如果你不想缓存,可以直接设置:
expires -1; //永远过期,Cache-Control: no-cache
~~~
### Cache-Control
这应该是HTTP1.1为了解决HTTP1.0中expires的时间差的bug,而新添加的一个tag. 他的配置项很多,其实完全都可以取代expires(现在大多数服务器都支持). 引用一段原话:
> Cache-Control 头在 HTTP/1.1 规范中定义,取代了之前用来定义响应缓存策略的头(例如 Expires)。当前的所有浏览器都支持 Cache-Control,因此,使用它就够了。
>
不过,目前大部分服务器都会将两者添加上,因为HTTP规定,如果Cache-Control和expires同时出现的话,expires会默认被覆盖掉。 此时,返回的响应码不再是304(文件未改动),而是200(资源成功访问).
当前每次发送请求之前浏览器会检查缓存系统里,是否有相应文件的备份,如果有的话,则直接从本地模仿一个Response头 理论知识铺垫完毕,我们来take a look. 看看cache-control 有哪些可以配置的属性(以下属性都跟在cache-control后)
> public: 共有缓存,可被缓存代理服务器缓存,比如CDN
> private: 私有缓存,不能被共有缓存代理服务器缓存,可被用户的代理缓存如浏览器。
> max-age=[秒]:表示在这个时间范围内缓存是新鲜的无需更新。类似Expires时间,不过这个时间是相对的,而不是绝对的。也就是某次请求成功后多少秒内缓存是新鲜的。
> s-maxage=[秒]:类似max-age, 除了仅应用于共享缓存(如代理)。
> no-cache:这里不是不缓存的意思,只是每次在使用缓存之前都强制发送请求给源服务器进行验证,检查文件该没改变(其实这里和ETag/Last区别不大)
> no-store:就是禁止缓存,不让浏览器保留缓存副本
> must-revalidate:告诉浏览器,你这必须再次验证检查信息是否过期, 返回的代号就不是200而是304了。
> proxy-revalidate:类似must-revalidate,除了只能应用于代理缓存。
> 比如,这里我可以设置Cache-Control为:
>
比如,这里我可以设置Cache-Control为:
~~~
//Response Headers
Cache-Control:private, max-age=0, must-revalidate
~~~
该文件是一个私有文件,只能被浏览器缓存,而不能被代理缓存。max-age标识该缓存立即过期,其实和no-cache实际上区别不大. 然后must-revalidate告诉浏览器,你必须给我再验证文件过没过期,比如接下来可能会验证Last-Modified或者ETag.如果没有过期则使用本地缓存. 其实上面可以直接等同于:
//Response Headers
Cache-Control:private,no-cache
使用no-store的结果
//Response Headers
Cache-Control:no-store;
这样表明,不管一不一样都需要重新下载. 强烈表示,不让你使用缓存文件。后续的就不会去验证ETag了。 当然,如果你将IE6那种古老的浏览器考虑进来的话,那你干脆就做的不要脸一点,直接用下面的tag就行:
Cache-Control: no-cache, no-store, must-revalidate //HTTP1.1
Pragma: no-cache //HTTP1.0
Expires: 0 //Proxy
不过现在基本上也没有不支持Cache-Control的浏览器了。
常在nginx怎么配置对应的cache-control头呢?
~~~
##设置no-cache
//Nginx
expires -1;
//cache-control
Cache-Control:no-cache
##设置max-age=0
//Nginx
expires 0;
//cache-control
Cache-Control:max-age=0
##设置其他头部
//nginx
add_header Cache-Control "no-cache";
add_header Pragma no-cache;
~~~
上面说的基本上是服务器的响应头,那在浏览器的Request headers里存在cache-control代表什么呢? 当请求头中有:Cache-Control: max-age=0,表示缓存需要进行验证(ETag||Last-Modified),如果缓存未过期,则可以使用。 当请求头中有:Cache-Control: no-cache,表示浏览器只能获取最新的文件。 和Response Header中的no-store相对应。
## 组合拳法之缓存策略
上面介绍的last/ETag/Expires/Cache都是HTTP协议的缓存策略。当然,缓存不止这一种,比如在HTML 4.0中定义的某些meta也可以实现自定义缓存的
<meta http-equiv="Cache-Control" content="no-cache, no-store, must-revalidate" />
<meta http-equiv="Pragma" content="no-cache" />
<meta http-equiv="Expires" content="0" />
但,实际情况是,这些meta只能在file:// 本地文件中使用,如果是服务器则默认被覆盖。现在目前主流的就是使用HTTP1.1协议缓存 不过我们一般都不会单独使用某一项。 但是,组合之后他们的效果是怎样的呢?
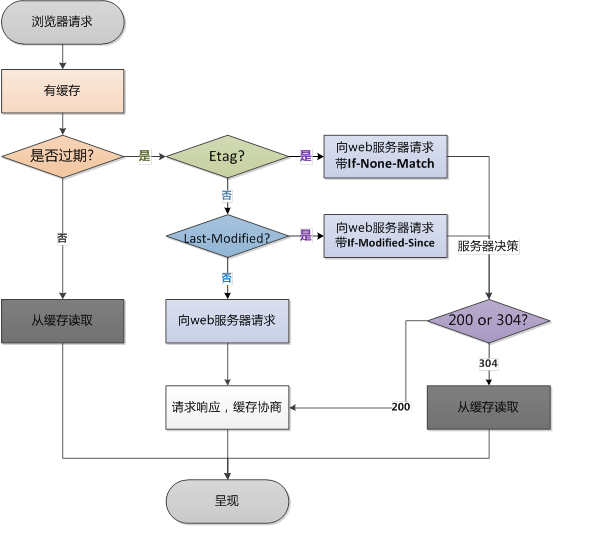
如果你的网页不是什么特别定制化的(私密)的,使用缓存能给你网站的性能带来极大的提升。所以很推荐使用。 一个网站,说白了就是HTML+JS+CSS+fonts+img 这几类文件(视频就呵呵了). 我们可以针对这几类文件做一些缓存层级

上面只是一个简单的设置,要知道HTML是一定不能缓存的(大部分网页)。 缓存设置时间应该在你版本稳定之后设置,否则会得不偿失。 另外设置Cache-Control还可以配合ETag或者Last-Modified进行补偿验证,如果后面文件变化也可以及时反映出来。
### 清除缓存
最常用的办法就是修改文件的版本号,或者生成随机文件名。 如果你只是在本地测试,想手动清楚缓存的话,可以使用.
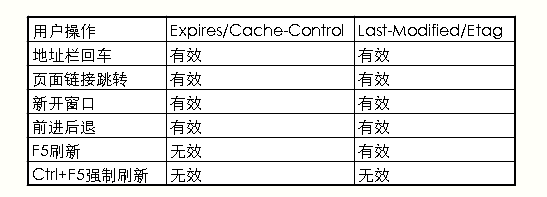
但是在Mac中不一样,使用command+R = F5刷新, command+shift+R= ctrl+F5硬性重新加载.
**另外,即使你设置了缓存策略,但是他也不会进行缓存的文件。 这些文件包括动态认证的文件,比如需要cookie验证,输入验证码等产生的文件。POST请求文件不能被缓存。**
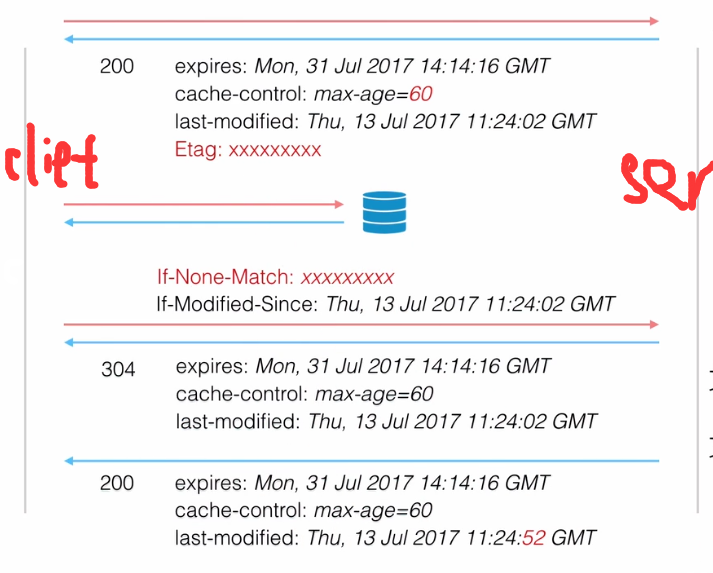
最后补上一张图
- 前言
- 工作中的一些记录
- 破解快手直播间的webSocket的连接
- 快手「反」反爬虫的研究记录
- HTML AND CSS
- 遇到的一些还行的css笔试题
- css常见面试题
- JavaScript 深度剖析
- ES6到ESNext新特性
- 关于http与缓存
- 关于页面性能
- 关于浏览器的重排(reflow、layout)与重绘
- 手写函数节流
- 手写promise
- 手写函数防抖
- 手写图片懒加载
- 手写jsonp
- 手写深拷贝
- 手写new
- 数据结构和算法
- 前言
- 时间复杂度
- 栈
- 队列
- 集合
- 字典
- 链表
- 树
- 图
- 堆
- 排序
- 搜索
- Webpack
- Webpack原理与实践
- Vue
- Vuejs的Virtual Dom的源码实现
- minVue
- Vuex实现原理
- 一道关于diff算法的面试题
- Vue2源码笔记:源码目录设计
- vue-router源码分析(v4.x)
- React及周边
- 深入理解redux(一步步实现一个 redux)
- React常见面试题汇总
- Taro、小程序等
- TypeScript
- CI/CD
- docker踩坑笔记
- jenkins
- 最后