
>最近和快手杠上了,后端又跑过来问我 python前端爬虫爬到的是韩文.... 说浏览器显示是正常的,但是F12源码里就是韩文... 没办法,又只好放下手中的事情,帮他看看.... 主要我也好奇咋实现的...
如下图 , 在dom中是类似于韩文的文字,在页面中显示又是正常的数据,这样就导致了,爬虫在爬取页面敏感数据的时候,得到的是“韩文”,而不是我们想要的数据,以此达到保护敏感数据的目的。
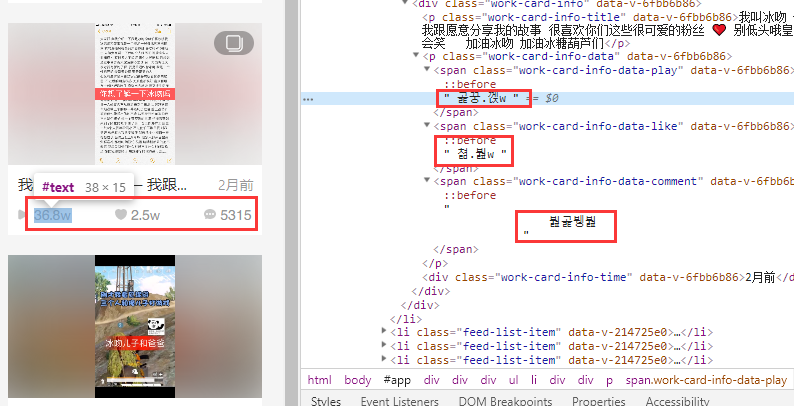
看一眼,如下图,觉得很神奇
但是仔细一研究,嘿,不就是自己定制的一套字体库么,唬谁呢。

我们这个“韩文”复制到网站[https://tool.chinaz.com/tools/unicode.aspx](https://tool.chinaz.com/tools/unicode.aspx) 在线转换编码一下,
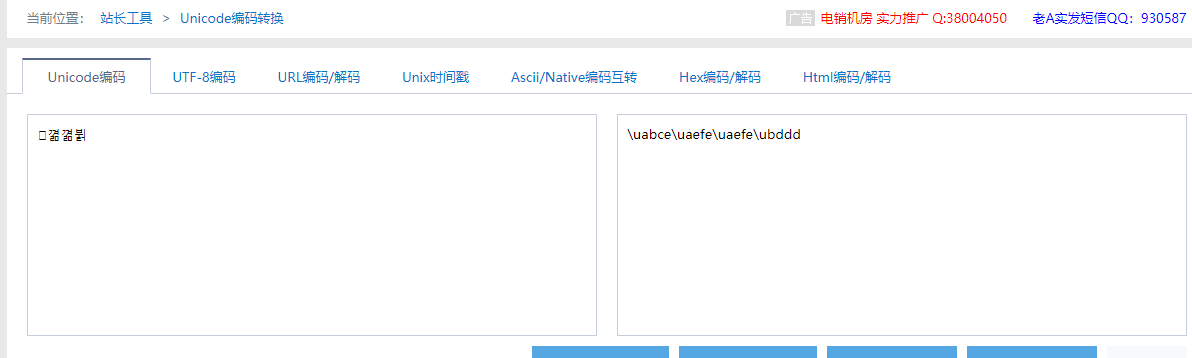
嘿嘿,知道怎么回事了三。
1. ꯎ껾껾뷝 (第一步)
2. \[b'\\\\uabce', b'\\\\uaefe', b'\\\\uaefe', b'\\\\ubddd'\] (第二步)
3. ['4', '0', '0', '1'] (第三步)
反正数字就10个,遍历一次,然后自己写套映射关系。
每次将抓到的“韩文”对比转换一下再入库,就完事啦~
- 前言
- 工作中的一些记录
- 破解快手直播间的webSocket的连接
- 快手「反」反爬虫的研究记录
- HTML AND CSS
- 遇到的一些还行的css笔试题
- css常见面试题
- JavaScript 深度剖析
- ES6到ESNext新特性
- 关于http与缓存
- 关于页面性能
- 关于浏览器的重排(reflow、layout)与重绘
- 手写函数节流
- 手写promise
- 手写函数防抖
- 手写图片懒加载
- 手写jsonp
- 手写深拷贝
- 手写new
- 数据结构和算法
- 前言
- 时间复杂度
- 栈
- 队列
- 集合
- 字典
- 链表
- 树
- 图
- 堆
- 排序
- 搜索
- Webpack
- Webpack原理与实践
- Vue
- Vuejs的Virtual Dom的源码实现
- minVue
- Vuex实现原理
- 一道关于diff算法的面试题
- Vue2源码笔记:源码目录设计
- vue-router源码分析(v4.x)
- React及周边
- 深入理解redux(一步步实现一个 redux)
- React常见面试题汇总
- Taro、小程序等
- TypeScript
- CI/CD
- docker踩坑笔记
- jenkins
- 最后