[TOC]
# db-spring-boot-starter
前面项目中,咱们使用了 [01.db-core模块](01.db-core%E6%A8%A1%E5%9D%97.md)为整个项目提供通用的数据库处理,现在我们将采用springboot 标准starter的做法,重构项目基础组件,利用org.springframework.boot.autoconfigure,完成对象的基本装配。同时他具有以下功能:
* 集成druid数据源
* 集成mybatis-plus
* 动态数据源切换
* pagehelper分页处理
* Guava
## db-spring-boot-starter代码分析
* 工具类
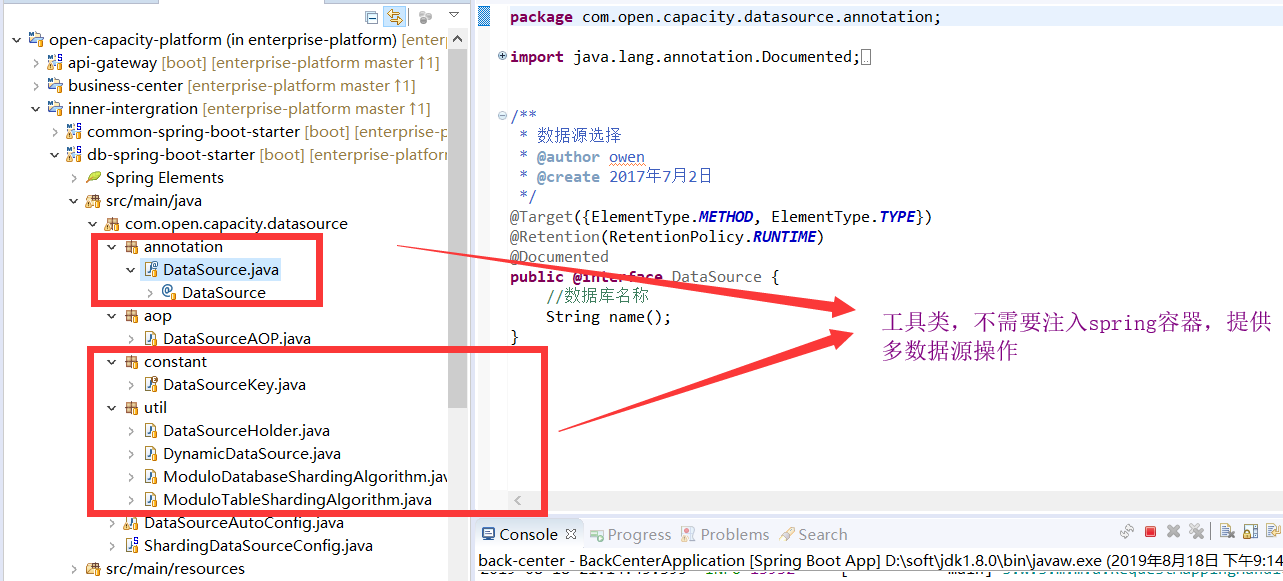
* AOP切换数据源类
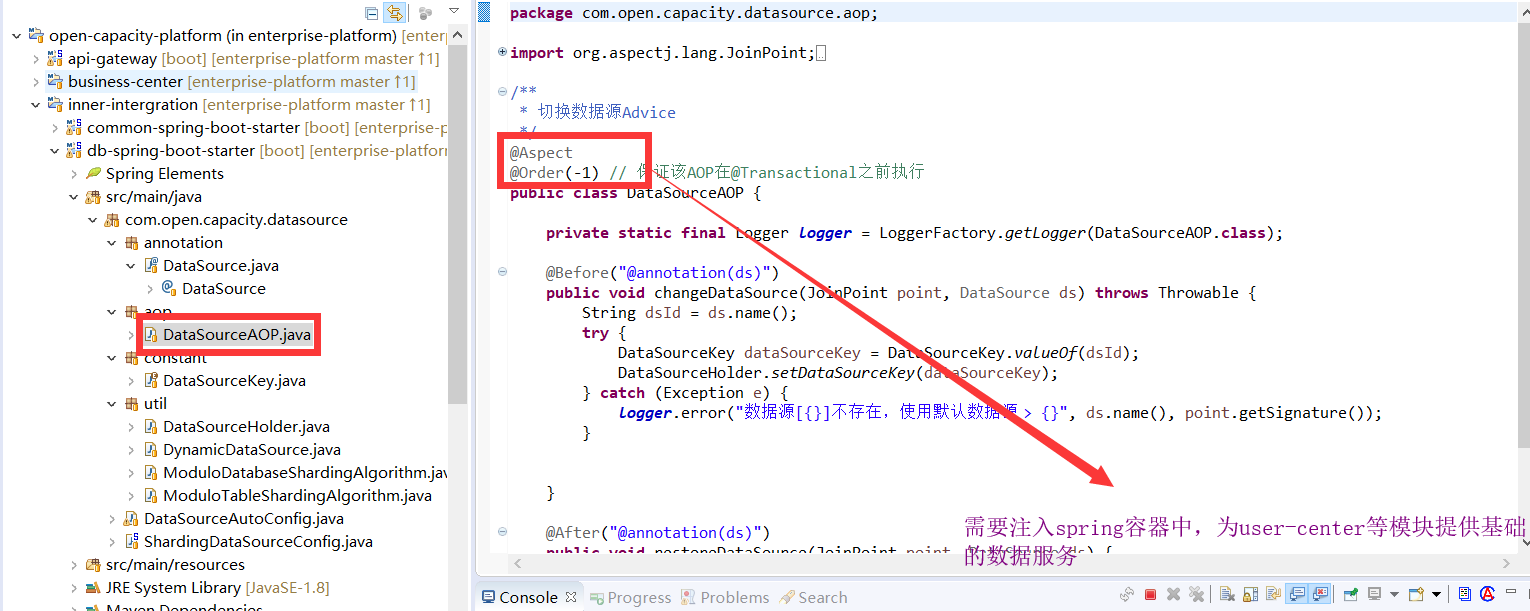
* 动态数据源定义core log
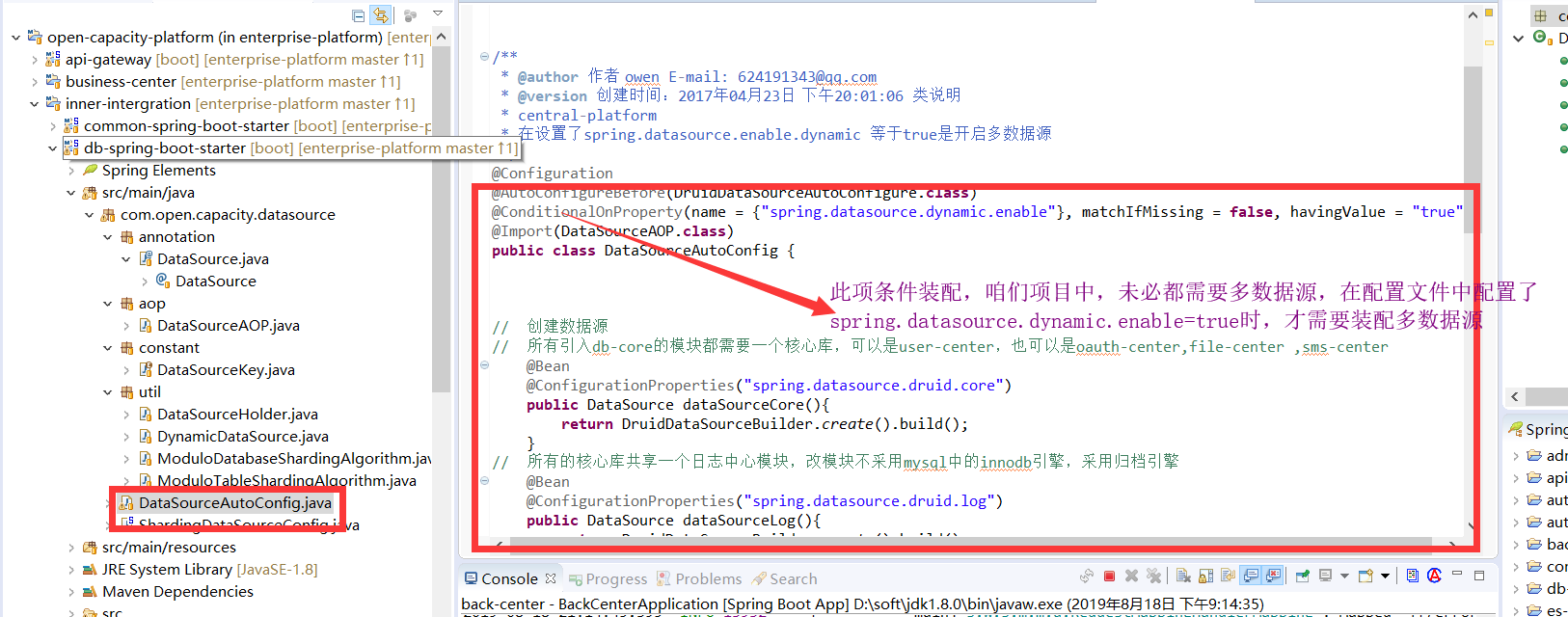
* 多数据源自动装配定义
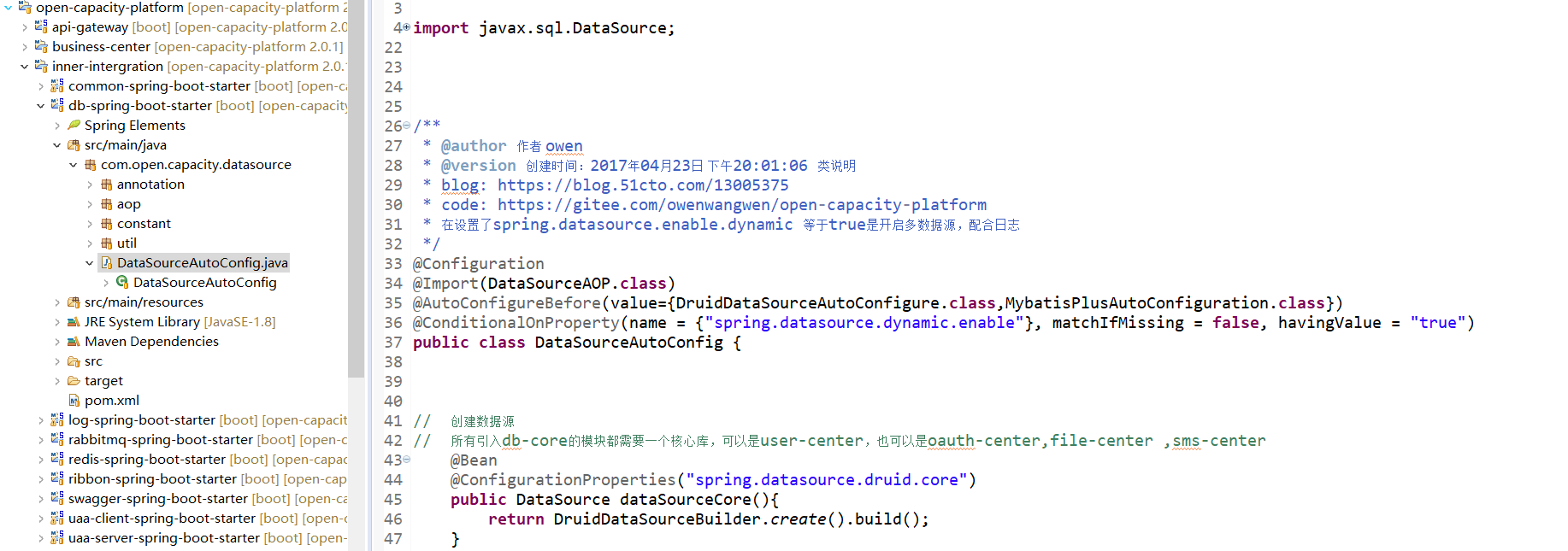
### druid配置
```
initial-size: 1
max-active: 20
min-idle: 1
# 配置获取连接等待超时的时间
max-wait: 60000
#打开PSCache,并且指定每个连接上PSCache的大小
pool-prepared-statements: true
max-pool-prepared-statement-per-connection-size: 20
validation-query: SELECT 'x'
test-on-borrow: false
test-on-return: false
test-while-idle: true
#配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
time-between-eviction-runs-millis: 60000
#配置一个连接在池中最小生存的时间,单位是毫秒
min-evictable-idle-time-millis: 300000
```
validationQuery和testWhileIdle这两个参数一起用,用来不间断检测是否有失效的链接,避免高并发的出现失效链接; 数据库连接池在初始化的时候会创建initialSize个连接,当有数据库操作时,会从池中取出一个连接。如果当前池中正在使用的连接数等于maxActive,则会等待一段时间,等待其他操作释放掉某一个连接,如果这个等待时间超过了maxWait,则会报错;如果当前正在使用的连接数没有达到maxActive,则判断当前是否空闲连接,如果有则直接使用空闲连接,如果没有则新建立一个连接。在连接使用完毕后,不是将其物理连接关闭,而是将其放入池中等待其他操作复用。 同时连接池内部有机制判断,如果当前的总的连接数少于miniIdle,则会建立新的空闲连接,以保证连接数得到miniIdle。如果当前连接池中某个连接在空闲了timeBetweenEvictionRunsMillis时间后仍然没有使用,则被物理性的关闭掉。有些数据库连接的时候有超时限制(mysql连接在8小时后断开),或者由于网络中断等原因,连接池的连接会出现失效的情况,这时候设置一个testWhileIdle参数为true,可以保证连接池内部定时检测连接的可用性,不可用的连接会被抛弃或者重建,最大情况的保证从连接池中得到的Connection对象是可用的。当然,为了保证绝对的可用性,你也可以使用testOnBorrow为true(即在获取Connection对象时检测其可用性),不过这样会影响性能。
### 动态数据源详解
* [15.动态数据源配置](18.%E5%8A%A8%E6%80%81%E6%95%B0%E6%8D%AE%E6%BA%90%E9%85%8D%E7%BD%AE.md)
## db-spring-boot-starter 如何使用
> user-center代码
* user-center pom文件使用

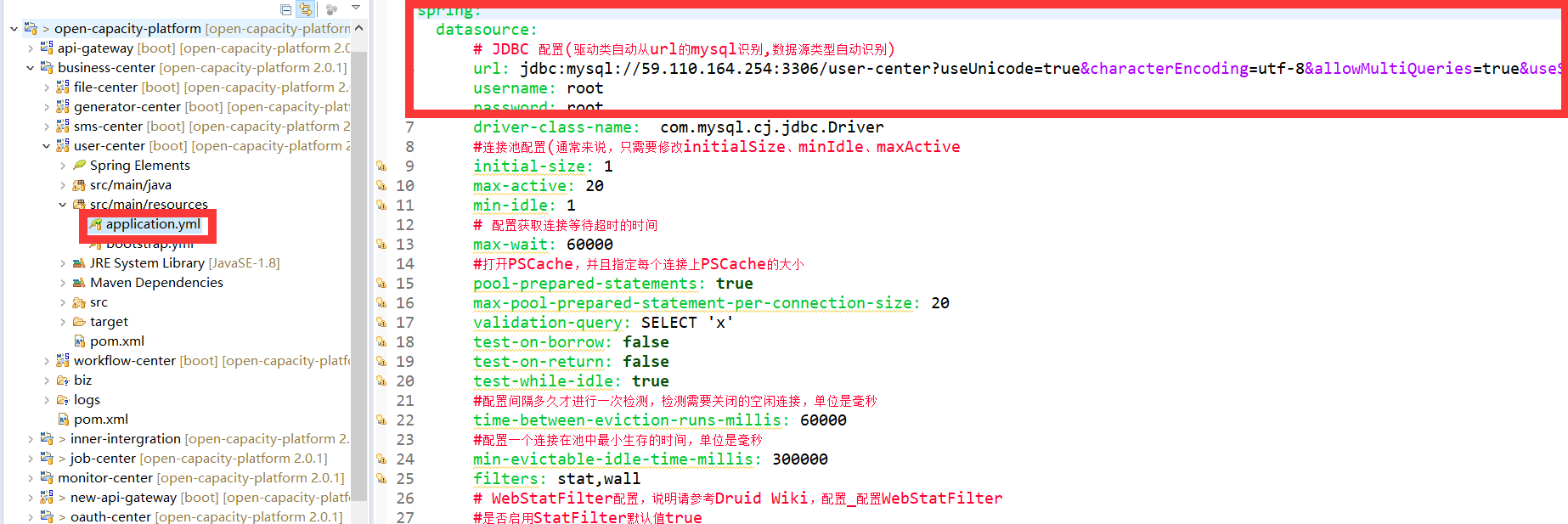
* user-center application.yml
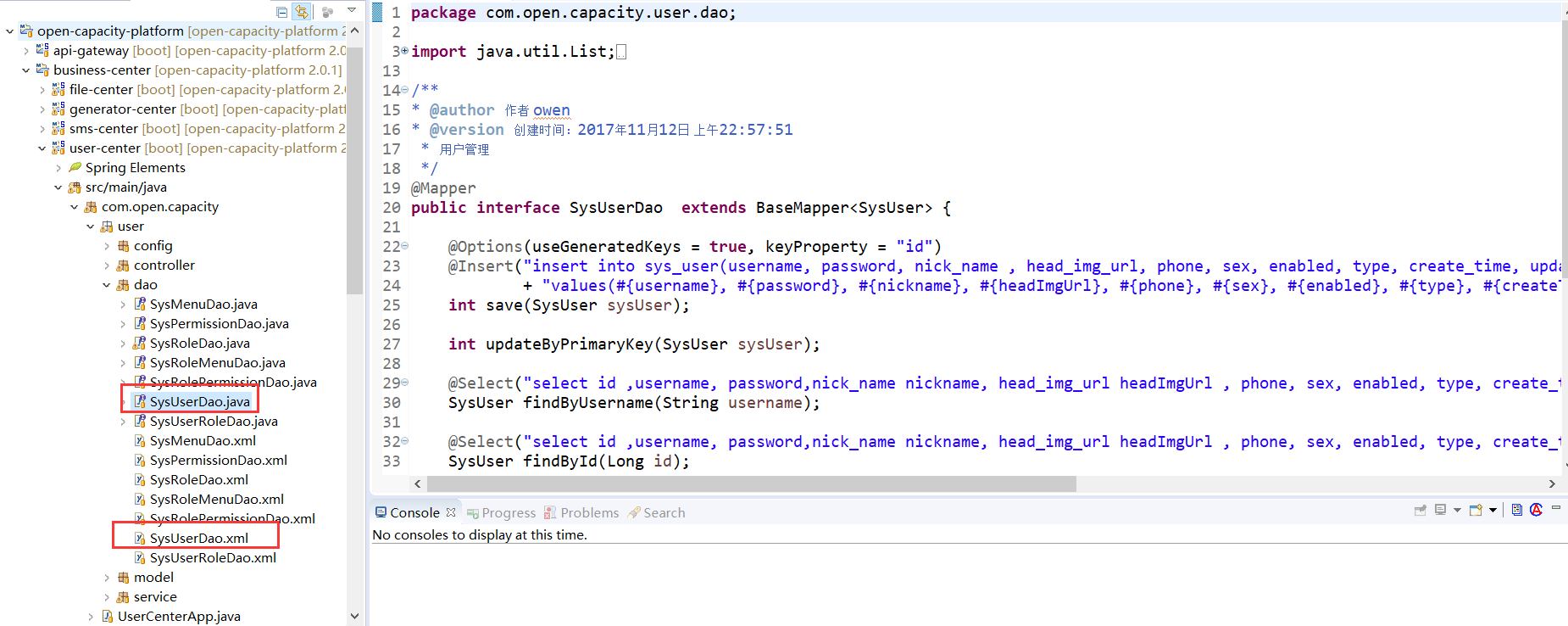
* 编写dao xml代码
## spring事务

spring事务抽象
* PlatformTransactionManager 事务管理接口,事务的开启,提交,回滚
* TransactionDefinition 事务的属性,传播属性等
* TransactionStatus 事务的运行状态
```
@Test
// select @@GLOBAL.tx_isolation ,@@tx_isolation
@Transactional( propagation = Propagation.REQUIRED ,isolation=Isolation.DEFAULT)
public void testSaveException2() {
Map dmo = Maps.newHashMap();
dmo.put("id", 3);
dmo.put("name", "3");
testDao.save(dmo);
Throwables.throwIfUnchecked(new RuntimeException("模拟业务出错"));
}
@Test
public void testSaveException3() {
DefaultTransactionDefinition definition = new DefaultTransactionDefinition();
definition.setPropagationBehavior(TransactionDefinition.PROPAGATION_REQUIRED);
TransactionStatus status = txManager.getTransaction(definition) ;
try{
Map dmo = Maps.newHashMap();
dmo.put("id", 5);
dmo.put("name", "5");
testDao.save(dmo);
Throwables.throwIfUnchecked(new RuntimeException("模拟业务出错"));
txManager.commit(status);
}catch (Exception e) {
txManager.rollback(status);
}
}
```
### aop与传播机制问题
### @Transactional try catch 后手动回退事务
```
TransactionAspectSupport.currentTransactionStatus().setRollbackOnly()
```
### transactionTemplate 异常后回退事务
```
transactionTemplate.setPropagationBehavior(TransactionDefinition.PROPAGATION\_RE QUIRED);
transactionTemplate.execute(item->{
try {
compareService.insert2();
} catch (Exception e) {
item.setRollbackOnly();
}
return Boolean.FALSE;
});
return "hello" ;
}
```
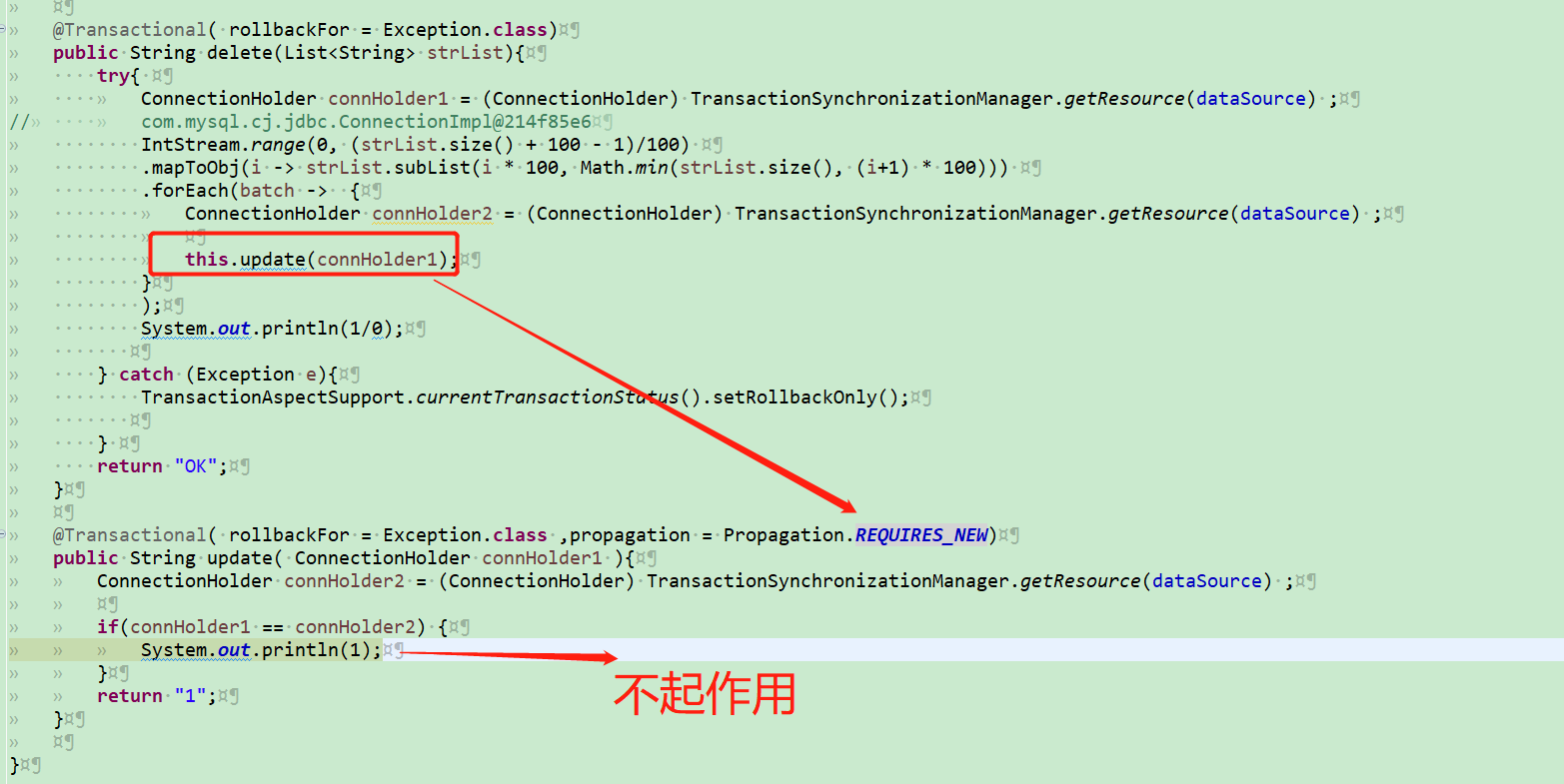
### 多线程与事务
```
@Transactional( rollbackFor = Exception.class)
public String delete(List<String> strList){
try{
ConnectionHolder connHolder1 = (ConnectionHolder) TransactionSynchronizationManager.getResource(dataSource) ;
// com.mysql.cj.jdbc.ConnectionImpl@214f85e6
IntStream.range(0, (strList.size() + 100 - 1)/100)
.mapToObj(i -> strList.subList(i * 100, Math.min(strList.size(), (i+1) * 100))).parallel()
.forEach(batch -> {
ConnectionHolder connHolder2 = (ConnectionHolder) TransactionSynchronizationManager.getResource(dataSource) ;
if(connHolder1 == connHolder2) {
System.out.println(1);
}
tableMapper.update("1");
}
);
System.out.println(1/0);
} catch (Exception e){
TransactionAspectSupport.currentTransactionStatus().setRollbackOnly();
}
return "OK";
}
```
### CompletableFuture.runAsync 与事务问题
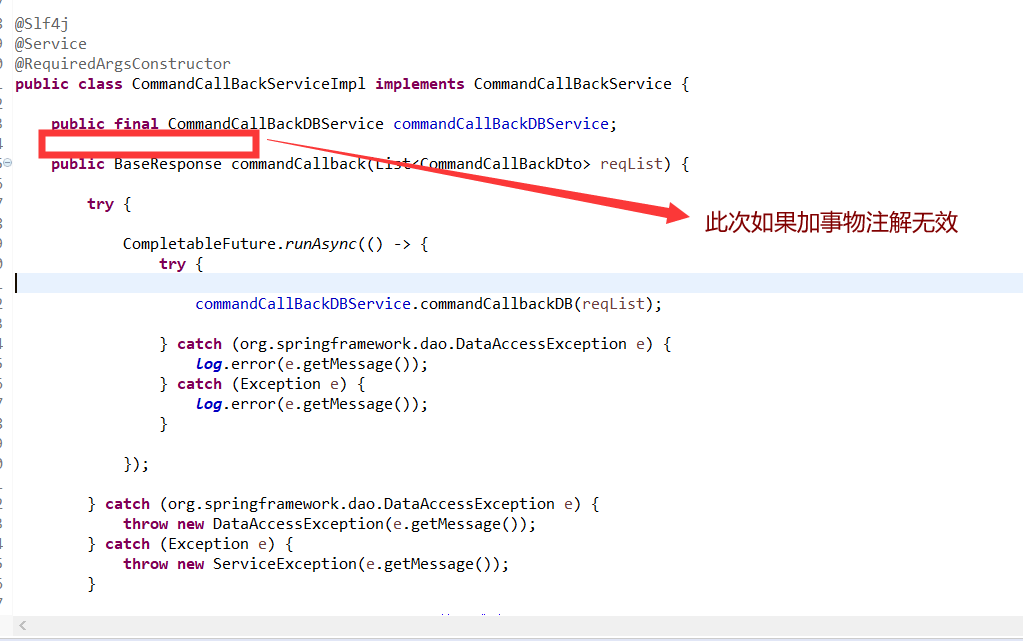
需要下沉到另外一个类
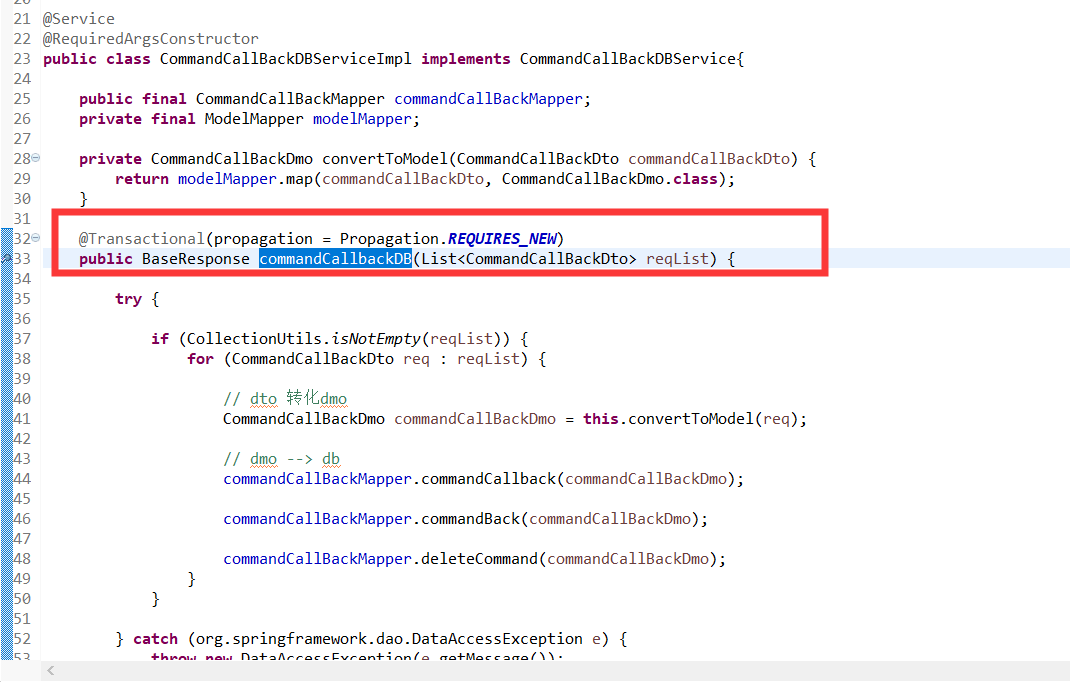
### 源码解析
~~~
public static Connection doGetConnection(DataSource dataSource) throws SQLException {
Assert.notNull(dataSource, "No DataSource specified");
//TransactionSynchronizationManager重点!!!有没有很熟悉的感觉??
//还记得我们前面Spring事务源码的分析吗?@Transaction会创建Connection,并放入ThreadLocal中
//这里从ThreadLocal中获取ConnectionHolder
ConnectionHolder conHolder = (ConnectionHolder)TransactionSynchronizationManager.getResource(dataSource);
if (conHolder == null || !conHolder.hasConnection() && !conHolder.isSynchronizedWithTransaction()) {
logger.debug("Fetching JDBC Connection from DataSource");
//如果没有使用@Transaction,那调用Mapper接口方法时,也是通过Spring的方法获取Connection
Connection con = fetchConnection(dataSource);
if (TransactionSynchronizationManager.isSynchronizationActive()) {
logger.debug("Registering transaction synchronization for JDBC Connection");
ConnectionHolder holderToUse = conHolder;
if (conHolder == null) {
holderToUse = new ConnectionHolder(con);
} else {
conHolder.setConnection(con);
}
holderToUse.requested();
TransactionSynchronizationManager.registerSynchronization(new DataSourceUtils.ConnectionSynchronization(holderToUse, dataSource));
holderToUse.setSynchronizedWithTransaction(true);
if (holderToUse != conHolder) {
//将获取到的ConnectionHolder放入ThreadLocal中,那么当前线程调用下一个接口,下一个接口使用了Spring事务,那Spring事务也可以直接取到Mybatis创建的Connection
//通过ThreadLocal保证了同一线程中Spring事务使用的Connection和Mapper代理类使用的Connection是同一个
TransactionSynchronizationManager.bindResource(dataSource, holderToUse);
}
}
return con;
} else {
conHolder.requested();
if (!conHolder.hasConnection()) {
logger.debug("Fetching resumed JDBC Connection from DataSource");
conHolder.setConnection(fetchConnection(dataSource));
}
//所以如果我们业务代码使用了@Transaction注解,在Spring中就已经通过dataSource创建了一个Connection并放入ThreadLocal中
//那么当Mapper代理对象调用方法时,通过SqlSession的SpringManagedTransaction获取连接时,就直接获取到了当前线程中Spring事务创建的Connection并返回
return conHolder.getConnection();
}
}
我们看到直接从ThreadLocal中取出来的conn,而spring自己的事务也是操作的这个ThreadLocal中的conn来进行事务的开启和回滚,由此我们知道了在同一线程中Spring事务中的Connection和Mybaits中Mapper代理对象中操作数据库的Connection是同一个,当取出来的conn为空时候,调用org.springframework.jdbc.datasource.DataSourceUtils#fetchConnection获取,然后把从数据源取出来的连接返回
private static Connection fetchConnection(DataSource dataSource) throws SQLException {
//从数据源取出来conn
Connection con = dataSource.getConnection();
if (con == null) {
throw new IllegalStateException("DataSource returned null from getConnection(): " + dataSource);
}
return con;
}
~~~
## mybatis-plus 介绍
* MyBatis 是一款优秀的持久层框架,其目的是想当做互联网的篱笆墙,围绕着数据库提供持久化服务的一个框架,支持自定义 SQL、存储过程及高级映射。
* MyBatis 免除了几乎所有的 JDBC 代码以及设置参数和获取结果集的工作,还可以通过简单的 XML 或注解来配置和映射原始类型、接口和 Java POJO(Plain Ordinary Java Object,普通 Java 对象)为数据库中的记录。
* [MyBatis-Plus](https://github.com/baomidou/mybatis-plus)(简称 MP)是一个[MyBatis](http://www.mybatis.org/mybatis-3/)的增强工具,在 MyBatis 的基础上只做增强不做改变,为简化开发、提高效率而生。
### 使用mybatis编写Dao

## db-spring-boot-starter自动装配原理解析
咱们想想,在不同项目中,咱们的项目是如何装配这些对象的吗?下面咱们需要揭密。
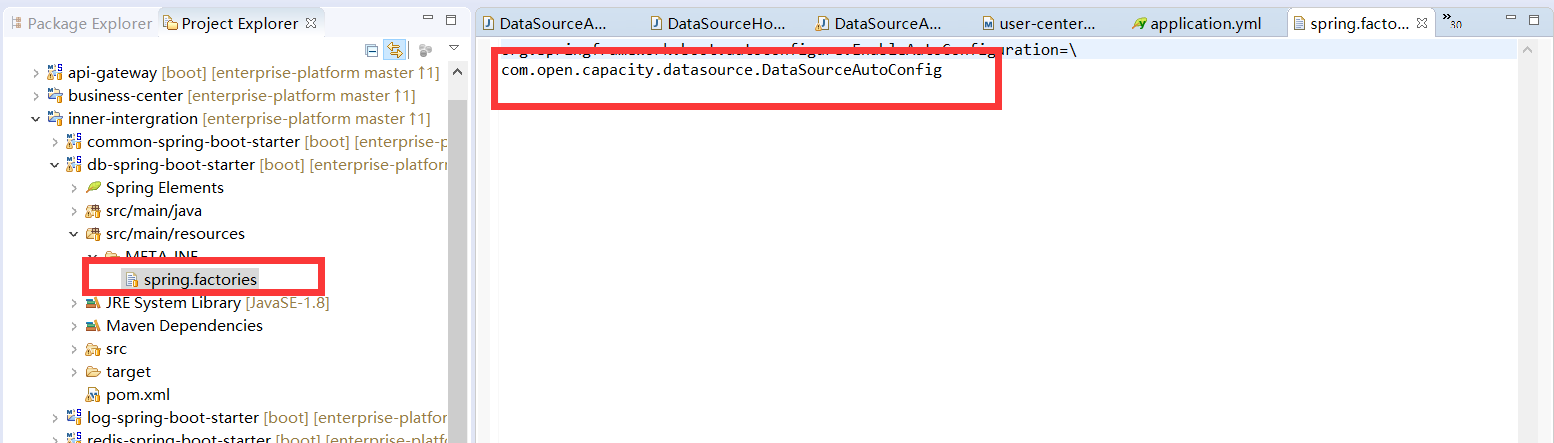
* db-spring-boot-starter 中定义了spring.factories文件
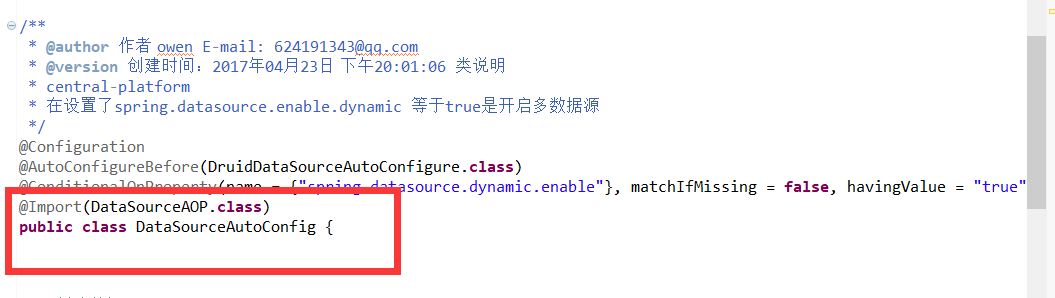
* DataSourceAutoConfig 中@Import(DataSourceAOP.class)
那么这些文件是如何完成加载到spring容器的呢?
此时,咱们必须回到user-center,阅读源码
* @SpringBootApplication
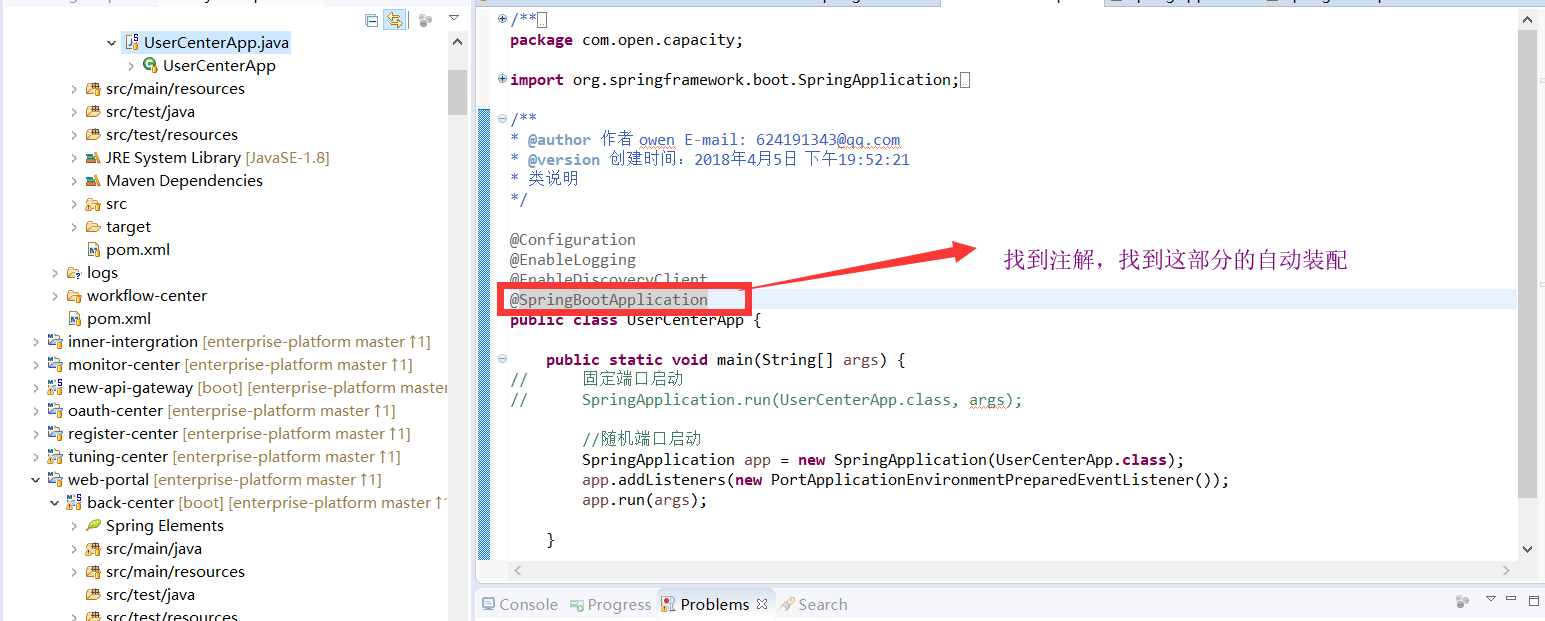
* @EnableAutoConfiguration
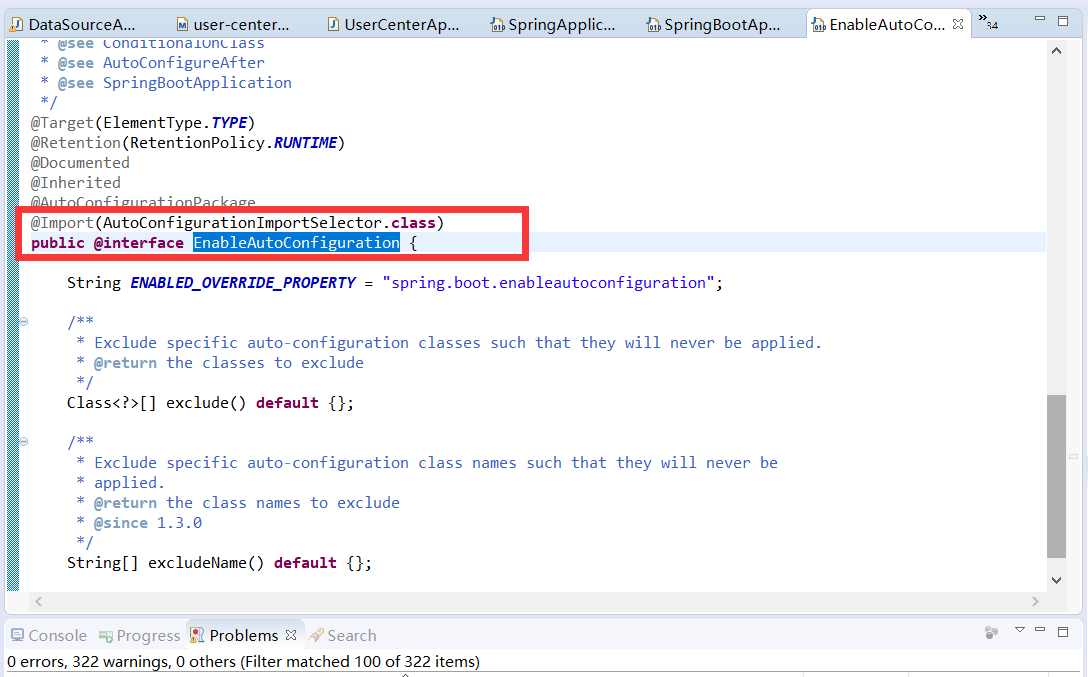
* AutoConfigurationImportSelector
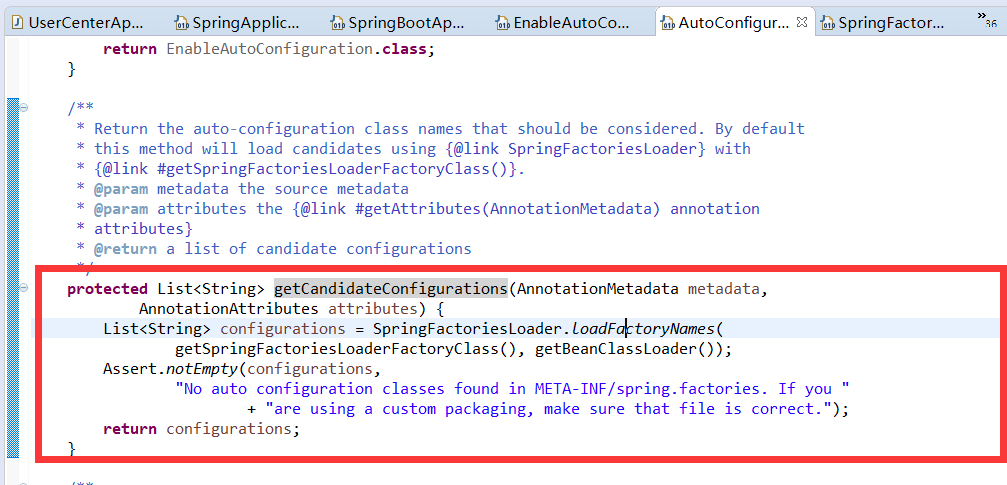
阅读到这里,我们了解到,user-center在启动时,由于@SpringBootApplication是复合注解,包含@EnableAutoConfiguration,这个类中@import了核心处理类AutoConfigurationImportSelector,这个类的核心就是将classpath中搜索所有META-INF/spring.factories配置文件,并且将其中org.springframework.boot.autoconfigure.EnableAutoConfiguration key对应的配置项加载到spring容器
## SPI机制的使用
```
SPI的全名为Service Provider Interface,简单的总结下java spi机制的思想。我们系统里抽象的各个模块,往往有很多不同的实现方案,比如日志模块的方案,xml解析模块、jdbc模块的方案等。面向的对象的设计里,我们一般推荐模块之间基于接口编程,模块之间不对实现类进行硬编码。一旦代码里涉及具体的实现类,就违反了可拔插的原则,如果需要替换一种实现,就需要修改代码。为了实现在模块装配的时候能不在程序里动态指明,这就需要一种服务发现机制。 java spi就是提供这样的一个机制:为某个接口寻找服务实现的机制
```
### JDK SPI 在 JDBC 中的应用
JDK 中只定义了一个 java.sql.Driver 接口,具体的实现是由不同数据库厂商来提供的。这里以 MySQL 提供的 JDBC 实现包为例进行分析。
在 mysql-connector-java-*.jar 包中的 META-INF/services 目录下,有一个 java.sql.Driver 文件中只有一行内容,如下所示:
```
com.mysql.cj.jdbc.Driver
```
在使用 mysql-connector-java-*.jar 包连接 MySQL 数据库的时候,我们会用到如下语句创建数据库连接:
```
String url = "jdbc:mysql://59.110.164.254:3306/user-center?useUnicode=true&characterEncoding=utf-8&allowMultiQueries=true&useSSL=false ";
Connection conn = DriverManager.getConnection(url, username, pwd);
```
DriverManager 是 JDK 提供的数据库驱动管理器,其中的代码片段,如下所示:
```
static {
loadInitialDrivers();
println("JDBC DriverManager initialized");
}
```
在调用 getConnection() 方法的时候,DriverManager 类会被 Java 虚拟机加载、解析并触发 static 代码块的执行,在 loadInitialDrivers() 方法中通过 JDK SPI 扫描 Classpath 下 java.sql.Driver 接口实现类并实例化,核心实现如下所示:
```
private static void loadInitialDrivers() {
String drivers = System.getProperty("jdbc.drivers")
// 使用 JDK SPI机制加载所有 java.sql.Driver实现类
ServiceLoader<Driver> loadedDrivers =
ServiceLoader.load(Driver.class);
Iterator<Driver> driversIterator = loadedDrivers.iterator();
while(driversIterator.hasNext()) {
driversIterator.next();
}
String[] driversList = drivers.split(":");
for (String aDriver : driversList) { // 初始化Driver实现类
Class.forName(aDriver, true,
ClassLoader.getSystemClassLoader());
}
}
```
在 MySQL 提供的 com.mysql.cj.jdbc.Driver 实现类中,同样有一段 static 静态代码块,这段代码会创建一个 com.mysql.cj.jdbc.Driver 对象并注册到 DriverManager.registeredDrivers 集合中( CopyOnWriteArrayList 类型),如下所示:
```
static {
java.sql.DriverManager.registerDriver(new Driver());
}
```
在 getConnection() 方法中,DriverManager 从该 registeredDrivers 集合中获取对应的 Driver 对象创建 Connection,核心实现如下所示:
```
private static Connection getConnection(String url, java.util.Properties info, Class<?> caller) throws SQLException {
// 省略 try/catch代码块以及权限处理逻辑
for(DriverInfo aDriver : registeredDrivers) {
Connection con = aDriver.driver.connect(url, info);
return con;
}
}
```
### SpringBoot中的类SPI扩展机制
在springboot的自动装配过程中,最终会加载META-INF/spring.factories文件,而加载的过程是由SpringFactoriesLoader加载的。从CLASSPATH下的每个Jar包中搜寻所有META-INF/spring.factories配置文件,然后将解析properties文件,找到指定名称的配置后返回。需要注意的是,其实这里不仅仅是会去ClassPath路径下查找,会扫描所有路径下的Jar包,只不过这个文件只会在Classpath下的jar包中。
## Guava
Guava 还提供了很多实用工具,如 Lists、Maps、Sets,接下来我们分别来看下这些常用工具的使用和原理。
* List<泛型> list = Lists.newArrayList();
* Map<String,String> hashMap = Maps.newHashMap();
这种写法其实就是一种简单的工厂模式
```
// 可以预估 list 的大小为 20
List<String> list = Lists.newArrayListWithCapacity(20);
List<String> list = Lists.newArrayListWithExpectedSize(20);
Map<String,String> hashMap = Maps.newHashMap();
Map<String,String> linkedHashMap = Maps.newLinkedHashMap();
Map<String,String> withExpectedSizeHashMap = Maps.newHashMapWithExpectedSize(20);
```
Guava 还提供了提供了一些异常处理的静态方法
```
Throwables.throwIfUnchecked(new RuntimeException("模拟业务出错"));
```
## 总结回顾
db-spring-boot-starter构建原理
* 1.ImportSelector 该接口的方法的返回值都会被纳入到spring容器管理中
* 2.SpringFactoriesLoader 该类可以从classpath中搜索所有META-INF/spring.factories配置文件,并读取配置
db-spring-boot-starter如何使用
* 1.使用mybatis构建dao文件
* 2.配置数据源
* 3.配置xml路径
- 前言
- 1.项目说明
- 2.项目更新日志
- 3.文档更新日志
- 01.快速开始
- 01.maven构建项目
- 02.环境安装
- 03.STS项目导入
- 03.IDEA项目导入
- 04.数据初始化
- 05.项目启动
- 06.付费文档说明
- 02.总体流程
- 1.oauth接口
- 2.架构设计图
- 3.微服务介绍
- 4.功能介绍
- 5.梳理流程
- 03.模块详解
- 01.老版本1.0.1分支模块讲解
- 01.db-core模块
- 02.api-commons模块
- 03.log-core模块
- 04.security-core模块
- 05.swagger-core模块
- 06.eureka-server模块
- 07.auth-server模块
- 08.auth-sso模块解析
- 09.user-center模块
- 10.api-gateway模块
- 11.file-center模块
- 12.log-center模块
- 13.batch-center模块
- 14.back-center模块
- 02.spring-boot-starter-web那点事
- 03.自定义db-spring-boot-starter
- 04.自定义log-spring-boot-starter
- 05.自定义redis-spring-boot-starter
- 06.自定义common-spring-boot-starter
- 07.自定义swagger-spring-boot-starter
- 08.自定义uaa-server-spring-boot-starter
- 09.自定义uaa-client-spring-boot-starter
- 10.自定义ribbon-spring-boot-starter
- 11.springboot启动原理
- 12.eureka-server模块
- 13.auth-server模块
- 14.user-center模块
- 15.api-gateway模块
- 16.file-center模块
- 17.log-center模块
- 18.back-center模块
- 19.auth-sso模块
- 20.admin-server模块
- 21.zipkin-center模块
- 22.job-center模块
- 23.batch-center
- 04.全新网关
- 01.基于spring cloud gateway的new-api-gateway
- 02.spring cloud gateway整合Spring Security Oauth
- 03.基于spring cloud gateway的redis动态路由
- 04.spring cloud gateway聚合swagger文档
- 05.技术详解
- 01.互联网系统设计原则
- 02.系统幂等性设计与实践
- 03.Oauth最简向导开发指南
- 04.oauth jdbc持久化策略
- 05.JWT token方式启用
- 06.token有效期的处理
- 07.@PreAuthorize注解分析
- 08.获取当前用户信息
- 09.认证授权白名单配置
- 10.OCP权限设计
- 11.服务安全流程
- 12.认证授权详解
- 13.验证码技术
- 14.短信验证码登录
- 15.动态数据源配置
- 16.分页插件使用
- 17.缓存击穿
- 18.分布式主键生成策略
- 19.分布式定时任务
- 20.分布式锁
- 21.网关多维度限流
- 22.跨域处理
- 23.容错限流
- 24.应用访问次数控制
- 25.统一业务异常处理
- 26.日志埋点
- 27.GPRC内部通信
- 28.服务间调用
- 29.ribbon负载均衡
- 30.微服务分布式跟踪
- 31.异步与线程传递变量
- 32.死信队列延时消息
- 33.单元测试用例
- 34.Greenwich.RELEASE升级
- 35.混沌工程质量保证
- 06.开发初探
- 1.开发技巧
- 2.crud例子
- 3.新建服务
- 4.区分前后台用户
- 07.分表分库
- 08.分布式事务
- 1.Seata介绍
- 2.Seata部署
- 09.shell部署
- 01.eureka-server
- 02.user-center
- 03.auth-server
- 04.api-gateway
- 05.file-center
- 06.log-center
- 07.back-center
- 08.编写shell脚本
- 09.集群shell部署
- 10.集群shell启动
- 11.部署阿里云问题
- 10.网关安全
- 1.openresty https保障服务安全
- 2.openresty WAF应用防火墙
- 3.openresty 高可用
- 11.docker配置
- 01.docker安装
- 02.Docker 开启远程API
- 03.采用docker方式打包到服务器
- 04.docker创建mysql
- 05.docker网络原理
- 06.docker实战
- 6.01.安装docker
- 6.02.管理镜像基本命令
- 6.03.容器管理
- 6.04容器数据持久化
- 6.05网络模式
- 6.06.Dockerfile
- 6.07.harbor部署
- 6.08.使用自定义镜像
- 12.统一监控中心
- 01.spring boot admin监控
- 02.Arthas诊断利器
- 03.nginx监控(filebeat+es+grafana)
- 04.Prometheus监控
- 05.redis监控(redis+prometheus+grafana)
- 06.mysql监控(mysqld_exporter+prometheus+grafana)
- 07.elasticsearch监控(elasticsearch-exporter+prometheus+grafana)
- 08.linux监控(node_exporter+prometheus+grafana)
- 09.micoservice监控
- 10.nacos监控
- 11.druid数据源监控
- 12.prometheus.yml
- 13.grafana告警
- 14.Alertmanager告警
- 15.监控微信告警
- 16.关于接口监控告警
- 17.prometheus-HA架构
- 18.总结
- 13.统一日志中心
- 01.统一日志中心建设意义
- 02.通过ELK收集mysql慢查询日志
- 03.通过elk收集微服务模块日志
- 04.通过elk收集nginx日志
- 05.统一日志中心性能优化
- 06.kibana安装部署
- 07.日志清理方案
- 08.日志性能测试指标
- 09.总结
- 14.数据查询平台
- 01.数据查询平台架构
- 02.mysql配置bin-log
- 03.单节点canal-server
- 04.canal-ha部署
- 05.canal-kafka部署
- 06.实时增量数据同步mysql
- 07.canal监控
- 08.clickhouse运维常见脚本
- 15.APM监控
- 1.Elastic APM
- 2.Skywalking
- 01.docker部署es
- 02.部署skywalking-server
- 03.部署skywalking-agent
- 16.压力测试
- 1.ocp.jmx
- 2.test.bat
- 3.压测脚本
- 4.压力报告
- 5.报告分析
- 6.压测平台
- 7.并发测试
- 8.wrk工具
- 9.nmon
- 10.jmh测试
- 17.SQL优化
- 1.oracle篇
- 01.基线测试
- 02.调优前奏
- 03.线上瓶颈定位
- 04.执行计划解读
- 05.高级SQL语句
- 06.SQL tuning
- 07.数据恢复
- 08.深入10053事件
- 09.深入10046事件
- 2.mysql篇
- 01.innodb存储引擎
- 02.BTree索引
- 03.执行计划
- 04.查询优化案例分析
- 05.为什么会走错索引
- 06.表连接优化问题
- 07.Connection连接参数
- 08.Centos7系统参数调优
- 09.mysql监控
- 10.高级SQL语句
- 11.常用维护脚本
- 12.percona-toolkit
- 18.redis高可用方案
- 1.免密登录
- 2.安装部署
- 3.配置文件
- 4.启动脚本
- 19.消息中间件搭建
- 19-01.rabbitmq集群搭建
- 01.rabbitmq01
- 02.rabbitmq02
- 03.rabbitmq03
- 04.镜像队列
- 05.haproxy搭建
- 06.keepalived
- 19-02.rocketmq搭建
- 19-03.kafka集群
- 20.mysql高可用方案
- 1.环境
- 2.mysql部署
- 3.Xtrabackup部署
- 4.Galera部署
- 5.galera for mysql 集群
- 6.haproxy+keepalived部署
- 21.es集群部署
- 22.生产实施优化
- 1.linux优化
- 2.jvm优化
- 3.feign优化
- 4.zuul性能优化
- 23.线上问题诊断
- 01.CPU性能评估工具
- 02.内存性能评估工具
- 03.IO性能评估工具
- 04.网络问题工具
- 05.综合诊断评估工具
- 06.案例诊断01
- 07.案例诊断02
- 08.案例诊断03
- 09.案例诊断04
- 10.远程debug
- 24.fiddler抓包实战
- 01.fiddler介绍
- 02.web端抓包
- 03.app抓包
- 25.疑难解答交流
- 01.有了auth/token获取token了为啥还要配置security的登录配置
- 02.权限数据存放在redis吗,代码在哪里啊
- 03.其他微服务和认证中心的关系
- 04.改包问题
- 05.use RequestContextListener or RequestContextFilter to expose the current request
- 06./oauth/token对应代码在哪里
- 07.验证码出不来
- 08./user/login
- 09.oauth无法自定义权限表达式
- 10.sleuth引发线程数过高问题
- 11.elk中使用7x版本问题
- 12.RedisCommandTimeoutException问题
- 13./oauth/token CPU过高
- 14.feign与权限标识符问题
- 15.动态路由RedisCommandInterruptedException: Command interrupted
- 26.学习资料
- 海量学习资料等你来拿
- 27.持续集成
- 01.git安装
- 02.代码仓库gitlab
- 03.代码仓库gogs
- 04.jdk&&maven
- 05.nexus安装
- 06.sonarqube
- 07.jenkins
- 28.Rancher部署
- 1.rancher-agent部署
- 2.rancher-server部署
- 3.ocp后端部署
- 4.演示前端部署
- 5.elk部署
- 6.docker私服搭建
- 7.rancher-server私服
- 8.rancher-agent docker私服
- 29.K8S部署OCP
- 01.准备OCP的构建环境和部署环境
- 02.部署顺序
- 03.在K8S上部署eureka-server
- 04.在K8S上部署mysql
- 05.在K8S上部署redis
- 06.在K8S上部署auth-server
- 07.在K8S上部署user-center
- 08.在K8S上部署api-gateway
- 09.在K8S上部署back-center
- 30.Spring Cloud Alibaba
- 01.统一的依赖管理
- 02.nacos-server
- 03.生产可用的Nacos集群
- 04.nacos配置中心
- 05.common.yaml
- 06.user-center
- 07.auth-server
- 08.api-gateway
- 09.log-center
- 10.file-center
- 11.back-center
- 12.sentinel-dashboard
- 12.01.sentinel流控规则
- 12.02.sentinel熔断降级规则
- 12.03.sentinel热点规则
- 12.04.sentinel系统规则
- 12.05.sentinel规则持久化
- 12.06.sentinel总结
- 13.sentinel整合openfeign
- 14.sentinel整合网关
- 1.sentinel整合zuul
- 2.sentinel整合scg
- 15.Dubbo与Nacos共存
- 31.Java源码剖析
- 01.基础数据类型和String
- 02.Arrays工具类
- 03.ArrayList源码分析
- 32.面试专题汇总
- 01.JVM专题汇总
- 02.多线程专题汇总
- 03.Spring专题汇总
- 04.springboot专题汇总
- 05.springcloud面试汇总
- 文档问题跟踪处理