[TOC]
# **注册中心**
## 什么是服务治理
服务治理可以说是微服务架构中最为核心和基础的模块,它主要用来实现各个微服务实例的自动化注册与发现。
## 为什么需要服务治理模块
在最初构建微服务系统的时候可能服务并不多,我们可以通过做一些静态配置来完成服务调用,此时看着一切都还正常。随着项目逐渐接近尾声,维护人员需要维护的服务越来越多,越来越复杂,最终形成大量的配置文件,维护将会变得越来越困难。此时,微服务应用实例自动化管理框架变得至关重要。
## 服务治理框架需要完成什么任务
● 服务注册:在服务治理框架中,通常都会构建一个注册中心,每个服务单元向注册中心登记自己提供的服务,将主机与端口号、版本号、通信协议等一些附加信息告知注册中心,注册中心按服务名分类组织服务清单。
● 服务发现:我们的所有服务都已经注册到注册中心,并且在注册中心是按照服务名分类,并且由注册中心维护者服务的具体位置。所以调用方需要调用某个服务时,需要先和注册中心咨询,注册中心会返回被调用方服务的所有具体位置,调用方在根据某种轮询策略选择一个具体位置进行服务调用。
## Netflix eureka
>Eureka是Netflix开发的服务发现框架,本身是一个基于REST的服务,主要用于定位运行在AWS域中的中间层服务,以达到负载均衡和中间层服务故障转移的目的。SpringCloud将它集成在其子项目spring-cloud-netflix中,以实现SpringCloud的服务发现功能。

## Eureka服务端
>Eureka服务端,我们也称为服务注册中心,他同其他服务注册中心一样,支持高可用配置。它依托于强一致性提供良好的服务实例可用性,可以应对多种不同的故障场景。 如果Eureka以集群方式部署,当集群中有分片出现故障时,那么Eureka就转入自我保护模式。它允许在分片故障期间继续提供服务的发现和注册,当故障分片恢复运行时,集群中的其他分片会把它们的状态再次同步回来。
## Eureka客户端
>Eureka客户端,主要处理服务的注册与发现。客户端服务通过注解和参数配置的方式,嵌入在客户端应用程序的代码中,在应用程序运行时,Eureka客户端向注册中心注册自身提供的服务并周期性地发送心跳来更新它的服务租约。同时,他也能从服务端查询当前注册的服务信息并把它们缓存到本地并周期性地刷新服务状态。
## 注册中心原理

# 注册中心代码详解
## 配置文件
```
eureka:
server:
shouldUseReadOnlyResponseCache: true #eureka是CAP理论种基于AP策略,为了保证强一致性关闭此切换CP 默认不关闭 false关闭
enable-self-preservation: false #关闭服务器自我保护,客户端心跳检测15分钟内错误达到80%服务会保护,导致别人还认为是好用的服务
eviction-interval-timer-in-ms: 60000 #清理间隔(单位毫秒,默认是60\*1000)5秒将客户端剔除的服务在服务注册列表中剔除#
response-cache-update-interval-ms: 3000 ##eureka server刷新readCacheMap的时间,注意,client读取的是readCacheMap,这个时间决定了多久会把readWriteCacheMap的缓存更新到readCacheMap上 #eureka server刷新readCacheMap的时间,注意,client读取的是readCacheMap,这个时间决定了多久会把readWriteCacheMap的缓存更新到readCacheMap上默认30s
response-cache-auto-expiration-in-seconds: 180 ##eureka server缓存readWriteCacheMap失效时间,这个只有在这个时间过去后缓存才会失效,失效前不会更新,过期后从registry重新读取注册服务信息,registry是一个ConcurrentHashMap。
client:
register-with-eureka: true #false:不作为一个客户端注册到注册中心
fetch-registry: false #为true时,可以启动,但报异常:Cannot execute request on any known server
instance-info-replication-interval-seconds: 10
service-url:
defaultZone: [http://127.0.0.1:1111/eureka](http://127.0.0.1:1111/eureka)
instance:
prefer-ip-address: true
instance-id: ${spring.application.name}:${spring.cloud.client.ip-address}:${spring.application.instance\_id:${server.port}}
lease-renewal-interval-in-seconds: 30 ## 续约更新时间间隔(默认30秒)
lease-expiration-duration-in-seconds: 90 # 续约到期时间(默认90秒)
ribbon:
ServerListRefreshInterval: 1000
```
## 核心代码@EnableEurekaServer注解
```
/**
* @author 作者 owen E-mail: 624191343@qq.com
* @version 创建时间:2017年11月28日 下午22:50:29
* 类说明
* eureka高可用三台机器
*/
@EnableEurekaServer
@SpringBootApplication
//@EnableHystrixDashboard
//@EnableTurbine
public class EurekaServerApp {
public static void main(String[] args) {
// 1本地启动采用此方法加载profiles文件
// ConfigurableApplicationContext context = new SpringApplicationBuilder(EurekaServerApp.class).
// profiles("slave0").run(args);
SpringApplication.run(EurekaServerApp.class, args);
// 2服务器采用此方法 java -jar --spring.profiles.active=slave3;
// SpringApplication.run(EurekaServerApp.class, args);
}
}
```
## eureka 服务源码解析
* LeaseManager
```
public interface LeaseManager<T> {
void register(T r, int leaseDuration, boolean isReplication);
boolean cancel(String appName, String id, boolean isReplication);
boolean renew(String appName, String id, boolean isReplication);
void evict();
}
```
**LeaseManager**做的事情就是 Eureka 注册中心模型中的**服务注册、服务续约、服务取消**和**服务剔除等**核心操作,关注于对服务注册过程的管理。
* LookupService
```
public interface LookupService<T> {
Application getApplication(String appName);
Applications getApplications();
List<InstanceInfo> getInstancesById(String id);
InstanceInfo getNextServerFromEureka(String virtualHostname, boolean secure);
}
```
**LookupService**关注于对应用程序与服务实例的管理,
InstanceRegistry 接口继承了即LeaseManager 接口和 LookupService 接口,其子对象类图关系:
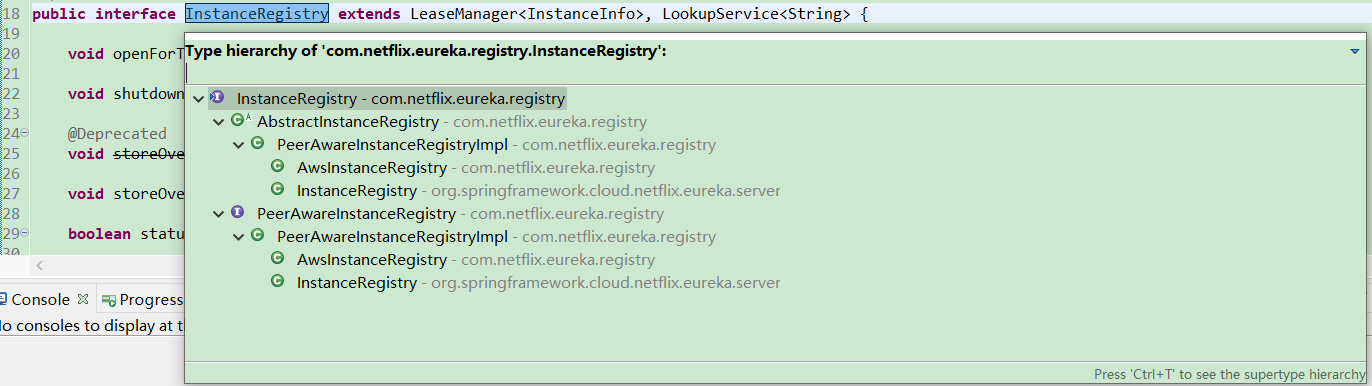
AbstractInstanceRegistry中有eureka 用于保存注册信息的数据结构。
```
private final ConcurrentHashMap<String, Map<String, Lease<InstanceInfo>>> registry = new ConcurrentHashMap<String, Map<String, Lease<InstanceInfo>>>();
```
它是一个双层的 HashMap,采用的是 JDK 中线程安全的 ConcurrentHashMap。其中第一层的 ConcurrentHashMap 的 Key 为 spring.application.name,也就是服务名,Value 为一个 ConcurrentHashMap;而第二层的 ConcurrentHashMap 的 Key 为 instanceId,也就是服务的唯一实例 ID,Value 为 Lease 对象。Eureka 采用 Lease(租约)这个词来表示对服务注册信息的抽象,Lease 对象保存了服务实例信息以及一些实例服务注册相关的时间,如注册时间 registrationTimestamp、最新的续约时间 lastUpdateTimestamp 等。
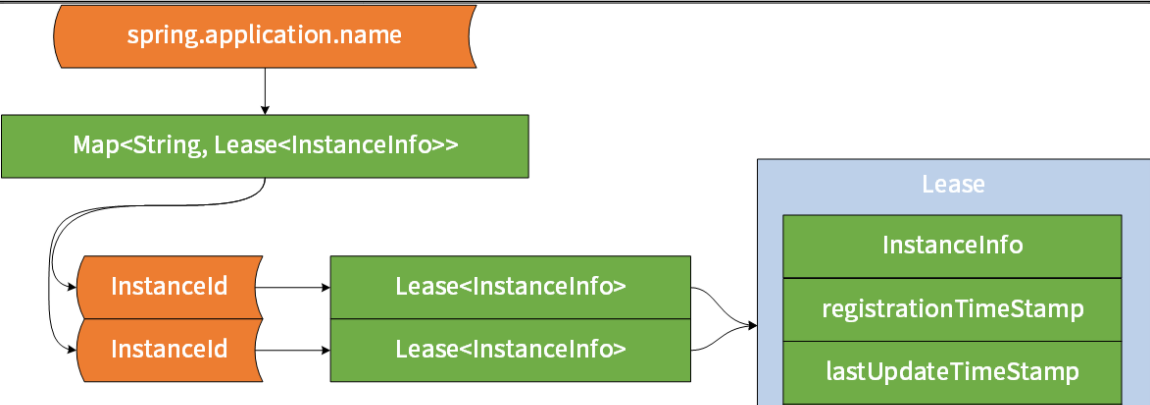
AbstractInstanceRegistry主要有如下方法:

## 注册代码解析
```
public void register(InstanceInfo registrant, int leaseDuration, boolean isReplication) {
try {
//从已存储的 registry 获取一个服务定义
Map<String, Lease<InstanceInfo>> gMap = registry.get(registrant.getAppName());
REGISTER.increment(isReplication);
if (gMap == null) {
//初始化一个 Map<String, Lease<InstanceInfo>> ,并放入 registry 中
}
//根据当前注册的 ID 找到对应的 Lease
Lease<InstanceInfo> existingLease = gMap.get(registrant.getId());
if (existingLease != null && (existingLease.getHolder() != null)) {
//如果 Lease 能找到,根据当前节点的最新更新时间和注册节点的最新更新时间比较
//如果前者的时间晚于后者的时间,那么注册实例就以已存在的实例为准
} else {
//如果找不到,代表是一个新注册,则更新其每分钟期望的续约数量及其阈值
}
//创建一个新 Lease 并放入 Map 中
Lease<InstanceInfo> lease = new Lease<InstanceInfo>(registrant, leaseDuration);
gMap.put(registrant.getId(), lease);
//处理服务的 InstanceStatus
registrant.setActionType(ActionType.ADDED);
//更新服务最新更新时间
registrant.setLastUpdatedTimestamp();
//刷选缓存
invalidateCache(registrant.getAppName(), registrant.getVIPAddress(), registrant.getSecureVipAddress());
}
}
```
## eureka客户端基本原理
对于 Eureka 而言,微服务的提供者和消费者都是它的客户端,其中服务提供者关注服务注册、服务续约和服务下线等功能,而服务消费者关注于服务信息的获取。同时,对于服务消费者而言,为了提高服务获取的性能以及在注册中心不可用的情况下继续使用服务,一般都还会具有缓存机制。
在 Netflix Eureka 中,专门提供了一个客户端包,并抽象了一个客户端接口 EurekaClient。EurekaClient 接口继承自 LookupService 接口,这个 LookupService 接口实际上也是我们上一课时中所介绍的 InstanceRegistry 接口的父接口。EurekaClient 在 LookupService 接口的基础上提供了一系列扩展方法,这些扩展方法并不是重点,我们还是更应该关注于它的类层机构,如下所示:

可以看到 EurekaClient 接口有个实现类 DiscoveryClient(位于 com.netflix.discovery 包中),该类包含了服务提供者和服务消费者的核心处理逻辑,同时提供了我们在介绍 Eureka 服务器端基本原理时所介绍的 register、renew 等方法。DiscoveryClient 类的实现非常复杂,我们重点关注它构造方法中的这行代码:
```
// finally, init the schedule tasks (e.g. cluster resolvers, heartbeat, instanceInfo replicator, fetch
initScheduledTasks();
```
通过分析该方法中的代码,我们看到系统在这里初始化了一批调度任务,具体包含缓存刷新 cacheRefresh、心跳 heartbeat、服务实例复制 InstanceInfoReplicator 等,其中缓存刷新面向服务消费者,而心跳和服务实例复制面向服务提供者。接下来我们将分别从这两个 Eureka 客户端组件出发讨论服务注册和发现的客户端操作。
## 服务提供者操作源码解析
服务提供者关注**服务注册、服务续约和服务下线**等功能,它可以使用 Eureka 服务器提供的 RESTful API 完成上述操作。因为篇幅关系,这里同样以服务注册为例给出服务提供者的操作流程。
在 DiscoveryClient 类中,服务注册操作由register 方法完成,如下所示。为了简单起见,我们对代码进行了裁剪,省略了日志相关等非核心代码:
```
boolean register() throws Throwable {
EurekaHttpResponse<Void> httpResponse;
try {
httpResponse = eurekaTransport.registrationClient.register(instanceInfo);
} catch (Exception e) {
throw e;
}
return httpResponse.getStatusCode() == 204;
}
```
上述 register 方法会在 InstanceInfoReplicator 类的 run 方法中进行执行。从操作流程上讲,上述代码的逻辑非常简单,即服务提供者先将自己注册到 Eureka 服务器中,然后根据返回的结果确定操作是否成功。显然,这里的重点代码是eurekaTransport.registrationClient.register(),DiscoveryClient 通过这行代码发起了远程请求。
首先我们来看 EurekaTransport 类,这是 DiscoveryClient 类中的一个内部类,定义了 registrationClient 变量用于实现服务注册。registrationClient 的类型是 EurekaHttpClient 接口,该接口的定义如下:
```
public interface EurekaHttpClient {
EurekaHttpResponse<Void> register(InstanceInfo info);
EurekaHttpResponse<Void> cancel(String appName, String id);
EurekaHttpResponse<InstanceInfo> sendHeartBeat(String appName, String id, InstanceInfo info, InstanceStatus overriddenStatus);
EurekaHttpResponse<Void> statusUpdate(String appName, String id, InstanceStatus newStatus, InstanceInfo info);
EurekaHttpResponse<Void> deleteStatusOverride(String appName, String id, InstanceInfo info);
EurekaHttpResponse<Applications> getApplications(String... regions);
EurekaHttpResponse<Applications> getDelta(String... regions);
EurekaHttpResponse<Applications> getVip(String vipAddress, String... regions);
EurekaHttpResponse<Applications> getSecureVip(String secureVipAddress, String... regions);
EurekaHttpResponse<Application> getApplication(String appName);
EurekaHttpResponse<InstanceInfo> getInstance(String appName, String id);
EurekaHttpResponse<InstanceInfo> getInstance(String id);
void shutdown();
}
```
可以看到这个 EurekaHttpClient 接口定义了 Eureka 服务器的一些底层 REST API,包括 register、cancel、sendHeartBeat、statusUpdate、getApplications 等。在 Eureka 中,关于如何实现客户端与服务器端的远程通信,从工作原理上讲只是一个 RESTful 风格的 HTTP 请求,但在具体设计和实现上可以说是非常考究,因此类层结构上也比较复杂。我们先来看 EurekaHttpClient 接口的一个实现类 EurekaHttpClientDecorator,从命名上看它是一个装饰器(Decorator),如下所示:
```
public abstract class EurekaHttpClientDecorator implements EurekaHttpClient {
public enum RequestType {
Register,
Cancel,
SendHeartBeat,
StatusUpdate,
DeleteStatusOverride,
GetApplications
…
}
public interface RequestExecutor<R> {
EurekaHttpResponse<R> execute(EurekaHttpClient delegate);
RequestType getRequestType();
}
protected abstract <R> EurekaHttpResponse<R> execute(RequestExecutor<R> requestExecutor);
@Override
public EurekaHttpResponse<Void> register(final InstanceInfo info) {
return execute(new RequestExecutor<Void>() {
@Override
public EurekaHttpResponse<Void> execute(EurekaHttpClient delegate) {
return delegate.register(info);
}
@Override
public RequestType getRequestType() {
return RequestType.Register;
}
});
}
//省略其他方法实现
}
```
可以看到 EurekaHttpClientDecorator 通过定义一个抽象方法 execute(RequestExecutor requestExecutor) 来包装 EurekaHttpClient,这种包装是代理机制的一种表现形式。
然后我们再来看如何构建一个 EurekaHttpClient,Eureka 也专门提供了 EurekaHttpClientFactory 类来负责构建具体的 EurekaHttpClient。显然,这是工厂模式的一种典型应用。EurekaHttpClientFactory 接口定义如下:
```
public interface EurekaHttpClientFactory {
EurekaHttpClient newClient();
void shutdown();
}
```
Eureka 中存在一批 EurekaHttpClientFactory 的实现类,包括 RetryableEurekaHttpClient 和 MetricsCollectingEurekaHttpClient 等,这些类都在com.netflix.discovery.shared.transport.decorator 包下。同时,在 com.netflix.discovery.shared.transport 包下,还存在一个 EurekaHttpClients 工具类,能够创建通过 RedirectingEurekaHttpClient、RetryableEurekaHttpClient、SessionedEurekaHttpClient 包装之后的 EurekaHttpClient。如下所示:
```
new EurekaHttpClientFactory() {
@Override
public EurekaHttpClient newClient() {
return new SessionedEurekaHttpClient(
name,
RetryableEurekaHttpClient.createFactory(
name,
transportConfig,
clusterResolver,
RedirectingEurekaHttpClient.createFactory(transportClientFactory),
ServerStatusEvaluators.legacyEvaluator()),
transportConfig.getSessionedClientReconnectIntervalSeconds() * 1000
);
}
};
```
这是 EurekaHttpClient 创建过程中的一条分支,即通过包装器对请求过程进行层层封装和代理。而在执行远程请求时,Eureka 同样提供了另一套体系来完成真正的远程调用,原始的 EurekaHttpClient 通过 TransportClientFactory 进行创建。TransportClientFactory 接口定义如下:
```
public interface TransportClientFactory {
EurekaHttpClient newClient(EurekaEndpoint serviceUrl);
void shutdown();
}
```
TransportClientFactory 同样存在一批实现类,其中有些是实名类,有些是匿名类。以实名的实现类 JerseyEurekaHttpClientFactory 为例,它位于 com.netflix.discovery.shared.transport.jersey 包下,通过 EurekaJerseyClient 获取 Jersey 客户端,而 EurekaJerseyClient 又会使用 ApacheHttpClient4 对象,从而完成 REST 调用。
作为总结,这里也给你分享一个 Eureka 在设计和实现上的技巧,也就是所谓的高阶(High Level)API和低阶(Low Level)API,如下图所示:
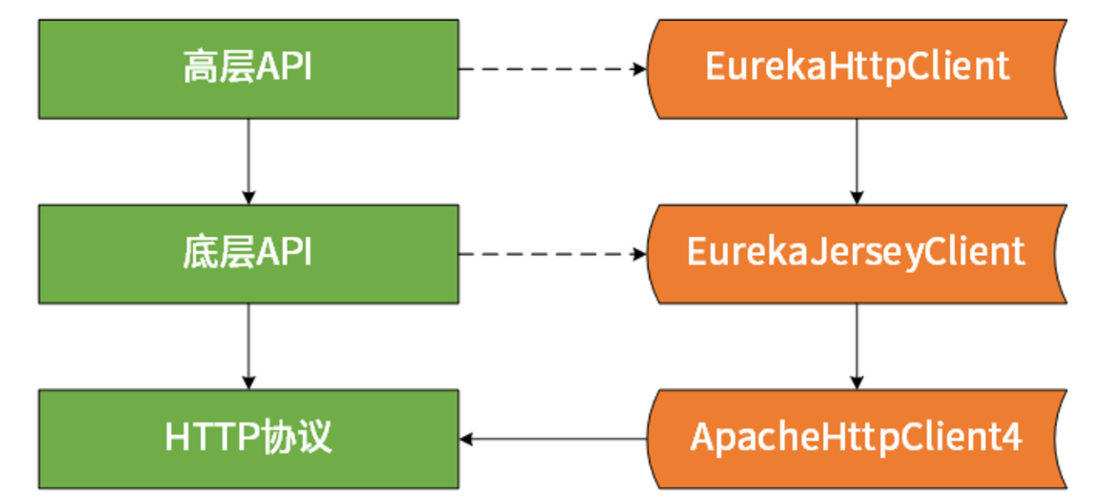
针对高阶 API,主要是通过装饰器模式进行一系列包装,从而创建目标 EurekaHttpClient。而关于低阶 API 的话,主要是 HTTP 远程调用的实现,Netflix 提供的是基于 Jersey 的版本,而 Spring Cloud 则提供了基于 RestTemplate 的版本。
## 服务消费者操作源码解析
我们在介绍注册中心模型时,服务消费者可以配备缓存机制以加速服务路由。对于 Eureka 而言,作为客户端组件的 DiscoveryClient 同样具备这种缓存功能。
Eureka 客户端通过定时任务完成缓存刷新操作,我们已经在前面的内容中提到 DiscoveryClient 中的 initScheduledTasks 方法用于初始化各种调度任务,对于缓存刷选而言,调度器的初始化过程如下所示:
```
if (clientConfig.shouldFetchRegistry()) {
int registryFetchIntervalSeconds = clientConfig.getRegistryFetchIntervalSeconds();
int expBackOffBound = clientConfig.getCacheRefreshExecutorExponentialBackOffBound();
scheduler.schedule(
new TimedSupervisorTask(
"cacheRefresh",
scheduler,
cacheRefreshExecutor,
registryFetchIntervalSeconds,
TimeUnit.SECONDS,
expBackOffBound,
new CacheRefreshThread()
),
registryFetchIntervalSeconds, TimeUnit.SECONDS);
}
```
这里启动了一个调度任务并通过 CacheRefreshThread 线程完成具体操作。CacheRefreshThread 线程定义如下:
```
class CacheRefreshThread implements Runnable {
public void run() {
refreshRegistry();
}
}
```
对于服务消费者而言,最重要的操作就是**获取服务注册信息**。在这里的 refreshRegistry 方法中,我们发现在进行一系列的校验之后,最终调用了 fetchRegistry 方法以完成注册信息的更新,该方法代码如下。为了简单起见,我们对代码进行了部分裁剪,只保留主流程:
```
private boolean fetchRegistry(boolean forceFullRegistryFetch) {
try {
// 获取应用
Applications applications = getApplications();
if (…) //如果满足全量拉取条件
{
// 全量拉取服务实例数据
getAndStoreFullRegistry();
} else {
// 增量拉取服务实例数据
getAndUpdateDelta(applications);
}
// 重新计算和设置一致性hashcode
applications.setAppsHashCode(applications.getReconcileHashCode());
}
// 刷新本地缓存
onCacheRefreshed();
// 更新远程服务实例运行状态
updateInstanceRemoteStatus();
return true;
}
```
这里的几个带注释的方法都非常有用,因为 getAndStoreFullRegistry 的逻辑相对比较简单,我们将重点介绍 getAndUpdateDelta 方法,以便学习在 Eureka 中如何实现增量数据更新的设计技巧。裁剪之后的 getAndUpdateDelta 方法代码如下所示:
```
private void getAndUpdateDelta(Applications applications) throws Throwable {
long currentUpdateGeneration = fetchRegistryGeneration.get();
Applications delta = null;
//通过 eurekaTransport.queryClient 获取增量信息
EurekaHttpResponse<Applications> httpResponse = eurekaTransport.queryClient.getDelta(remoteRegionsRef.get());
if (httpResponse.getStatusCode() == Status.OK.getStatusCode()) {
delta = httpResponse.getEntity();
}
if (delta == null) {
//如果增量信息为空,就直接发起一次全量更新
getAndStoreFullRegistry();
} else if (fetchRegistryGeneration.compareAndSet(currentUpdateGeneration, currentUpdateGeneration + 1)) {//通过CAS来确保请求的线程安全性
String reconcileHashCode = "";
if (fetchRegistryUpdateLock.tryLock()) {
try {
//比对从服务器端返回的增量数据和本地数据,合并两者的差异数据
updateDelta(delta);
//用合并了增量数据之后的本地数据来生成一致性 hashcode
reconcileHashCode = getReconcileHashCode(applications);
} finally {
fetchRegistryUpdateLock.unlock();
}
} else {
}
//比较本地数据中的 hashcode 和来自服务器端的 hashcode
if (!reconcileHashCode.equals(delta.getAppsHashCode()) || clientConfig.shouldLogDeltaDiff()) {
//如果 hashcode 不一致,就触发远程调用进行全量更新
reconcileAndLogDifference(delta, reconcileHashCode);
}
} else {
}
}
```
回顾 Eureka 服务器端基本原理,我们知道 Eureka 服务器端会保存一个服务注册列表的缓存。Eureka 官方文档中提到这个数据保留时间是三分钟,而 Eureka 客户端的定时调度机制会每隔 30 秒刷选本地缓存。原则上,只要 Eureka 客户端不停地获取服务器端的更新数据,就能保证自己的数据和 Eureka 服务器端的保持一致。但如果客户端在 3 分钟之内没有获取更新数据,就会导致自身与服务器端的数据不一致,这是这种更新机制所必须要考虑的问题,也是我们自己在设计类似场景时的一个注意点。
针对上述问题,Eureka 采用了一致性 HashCode 方法来进行解决。Eureka 服务器端每次返回的增量数据中都会带有一个一致性 HashCode,这个 HashCode 会与 Eureka 客户端用本地服务列表数据算出的一致性 HashCode 进行比对,如果两者不一致就证明增量更新出了问题,这时候就需要执行一次全量更新。
# 注册中心集群
Eureka-Server 之间会将注册信息复制到集群中的 Eureka Server 的所有节点中,可以在任意一个 Eureka-Server 的实例上进行注册,也可以在任意一个实例上进行读取。

可以为每个实例创建一个配置文件,通过 spring.profiles.active 的方式激活,这样就不用创建多个 Eureka Server 的项目了,Eureka-Server 本质上没有任何区别,只是配置内容不一样而已。

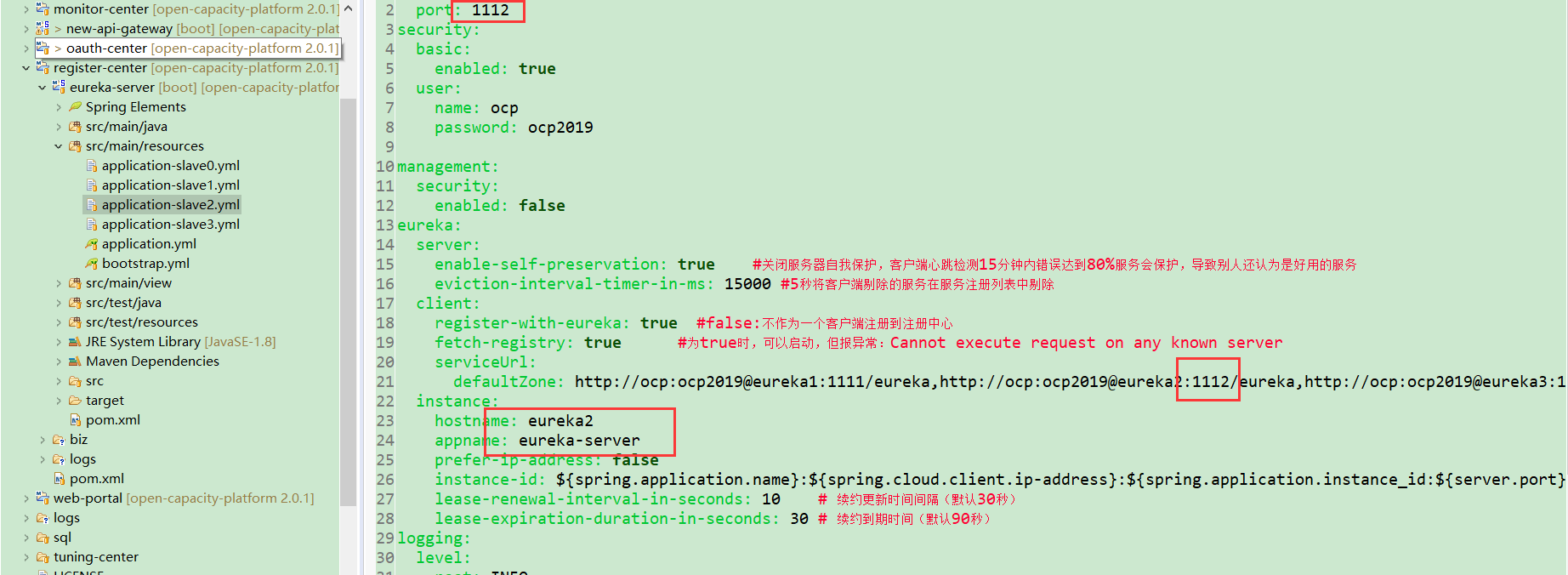

注意hostname需要配置hosts文件

### 启动集群


### 查看集群
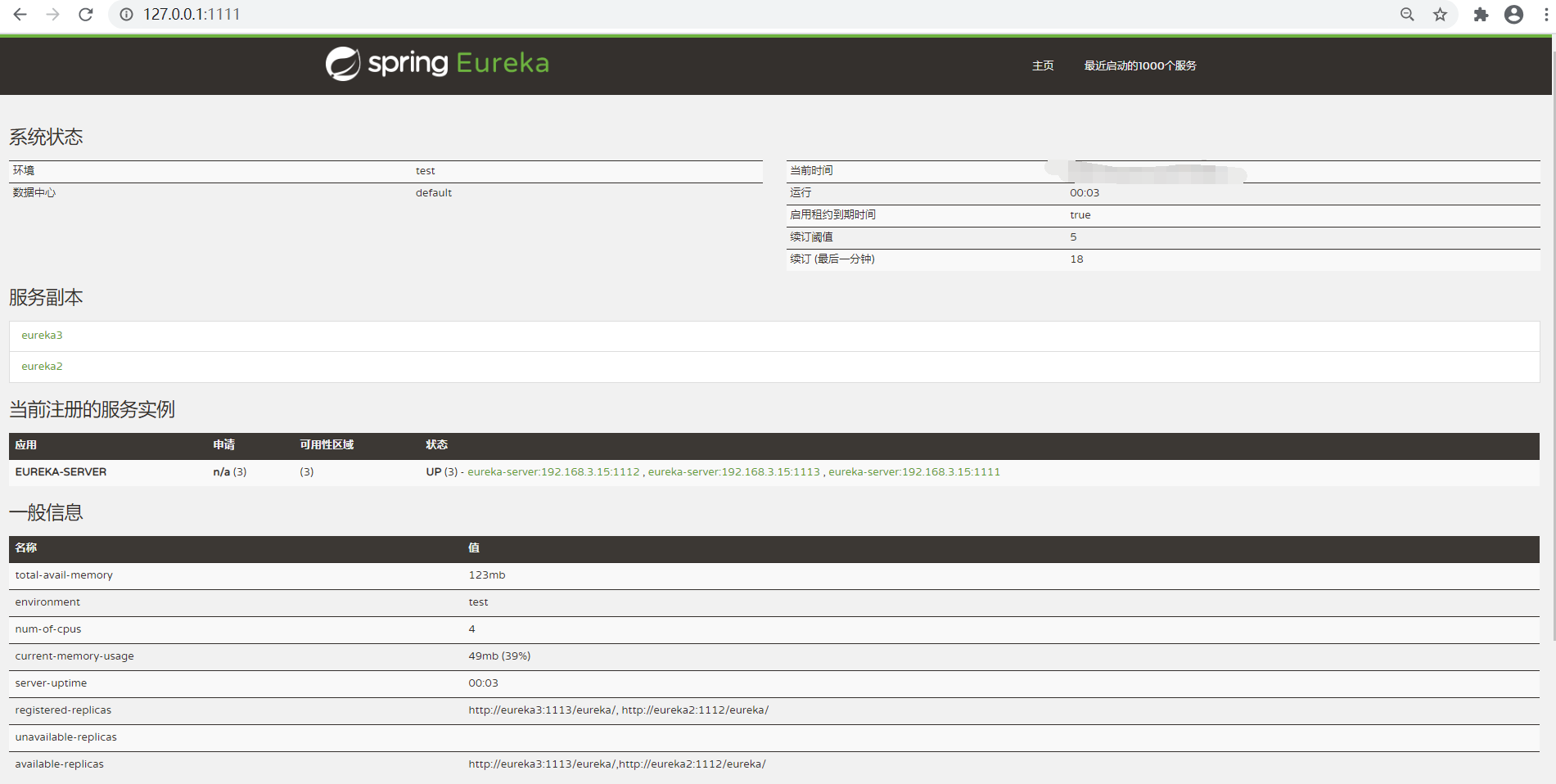
### 高可用源码解析
Eureka 的高可用部署方式被称为**Peer Awareness 模式**。对应的,我们在**InstanceRegistry 的类层**结构中也已经看到了它的一个扩展接口**PeerAwareInstanceRegistry**以及该接口的实现类 PeerAwareInstanceRegistryImpl。
我们还是围绕服务注册这个场景展开讨论,在**PeerAwareInstanceRegistryImpl**中同样存在一个 register 方法,如下所示:
```
@Override
public void register(final InstanceInfo info, final boolean isReplication) {
int leaseDuration = Lease.DEFAULT_DURATION_IN_SECS;
if (info.getLeaseInfo() != null && info.getLeaseInfo().getDurationInSecs() > 0) {
leaseDuration = info.getLeaseInfo().getDurationInSecs();
}
super.register(info, leaseDuration, isReplication);
replicateToPeers(Action.Register, info.getAppName(), info.getId(), info, null, isReplication);
}
```
我们在这里看到了一个非常重要的**replicateToPeers 方法**,该方法作就是用来实现服务器节点之间的状态同步。**replicateToPeers 方法的核心代码**如下所示:
```
for (final PeerEurekaNode node : peerEurekaNodes.getPeerEurekaNodes()) {
//如何该 URL 代表主机自身,则不用进行注册
if (peerEurekaNodes.isThisMyUrl(node.getServiceUrl())) {
continue;
}
replicateInstanceActionsToPeers(action, appName, id, info, newStatus, node);
}
```
为了理解这个操作,我们首先需要理解 Eureka 中的集群模式,这部分代码位于 com.netflix.eureka.cluster 包中,其中包含了代表节点的 PeerEurekaNode 和 PeerEurekaNodes 类,以及用于节点之间数据传递的 HttpReplicationClient 接口。而 replicateInstanceActionsToPeers 方法中则根据不同的 Action 来调用 PeerEurekaNode 的不同方法。例如,如果是 StatusUpdate Action,则会调动 PeerEurekaNode的statusUpdate 方法,而该方法又会执行如下代码;
```
replicationClient.statusUpdate(appName, id, newStatus, info);
```
这句代码完成了 PeerEurekaNode 之间的通信,而 replicationClient 是 HttpReplicationClient 接口的实例,该接口定义如下:
```
public interface HttpReplicationClient extends EurekaHttpClient {
EurekaHttpResponse<Void> statusUpdate(String asgName, ASGStatus newStatus);
EurekaHttpResponse<ReplicationListResponse> submitBatchUpdates(ReplicationList replicationList);
}
```
HttpReplicationClient 接口继承自 EurekaHttpClient 接口,而 EurekaHttpClient 接口属于 Eureka 客户端组件,我们会在下一课时介绍 Eureka 客户端基本原理时进行详细介绍。在这里,我们只需要明白 Eureka 提供了 JerseyReplicationClient(位于 com.netflix.eureka.transport 包下)这一基于 Jersey 框架实现的HttpReplicationClient。以 statusUpdate 方法为例,它的实现过程如下:
```
@Override
public EurekaHttpResponse<Void> statusUpdate(String asgName, ASGStatus newStatus) {
ClientResponse response = null;
try {
String urlPath = "asg/" + asgName + "/status";
response = jerseyApacheClient.resource(serviceUrl)
.path(urlPath)
.queryParam("value", newStatus.name())
.header(PeerEurekaNode.HEADER_REPLICATION, "true")
.put(ClientResponse.class);
return EurekaHttpResponse.status(response.getStatus());
} finally {
if (response != null) {
response.close();
}
}
}
```
# OCP服务治理

## eureka重要源码
com.netflix.eureka.resources.ServerInfoResource
com.netflix.eureka.resources.ApplicationsResource
com.netflix.eureka.resources.InstancesResource
com.netflix.eureka.resources.InstanceResource
com.netflix.eureka.resources.StatusResource
### ApplicationResource分析
```
http://127.0.0.1:1111/eureka/apps/<APPID>
```
该地址代表的就是一个普通的 HTTP GET 请求。Eureka 中所有对服务器端的访问都是通过**RESTful 风格**的**资源(Resource)**进行获取,ApplicationResource 类(位于com.netflix.eureka.resources 包中)提供了根据应用获取注册信息的入口。我们来看该类的 getApplication 方法,核心代码如下所示:
```
Key cacheKey = new Key(
Key.EntityType.Application,appName,
keyType,
CurrentRequestVersion.get(),
EurekaAccept.fromString(eurekaAccept)
);
String payLoad = responseCache.get(cacheKey);
if (payLoad != null) {
logger.debug("Found: {}", appName);
return Response.ok(payLoad).build();
} else {
logger.debug("Not Found: {}", appName);
return Response.status(Status.NOT_FOUND).build();
}
```
可以看到这里是构建了一个**cacheKey**,并直接调用了 responseCache.get(cacheKey) 方法来返回一个字符串并构建响应。从命名上看,不难想象这里使用了缓存机制。我们来看 ResponseCache 的定义,如下所示,其中最核心的就是这里的 get 方法:
```
public interface ResponseCache {
void invalidate(String appName, @Nullable String vipAddress, @Nullable String secureVipAddress);
AtomicLong getVersionDelta();
AtomicLong getVersionDeltaWithRegions();
String get(Key key);
byte[] getGZIP(Key key);
}
```
从类层关系上看,ResponseCache 只有一个**实现类 ResponseCacheImpl**,我们来看它的 get 方法,发现该方法使用了如下处理策略:
```
Value getValue(final Key key, boolean useReadOnlyCache) {
Value payload = null;
try {
if (useReadOnlyCache) {
final Value currentPayload = readOnlyCacheMap.get(key);
if (currentPayload != null) {
payload = currentPayload;
} else {
payload = readWriteCacheMap.get(key);
readOnlyCacheMap.put(key, payload);
}
} else {
payload = readWriteCacheMap.get(key);
}
} catch (Throwable t) {
logger.error("Cannot get value for key : {}", key, t);
}
return payload;
}
```
可以看到上述代码中有两个缓存,一个是**readOnlyCacheMap**,一个是**readWriteCacheMap**。其中 readOnlyCacheMap 就是一个 JDK 中的 ConcurrentMap,而 readWriteCacheMap 使用的则是 Google Guava Cache 库中的 LoadingCache 类型。在创建 LoadingCache过程中,缓存数据的来源是调用 generatePayload 方法来生成。而在这个 generatePayload 方法中,就会调用前面介绍的 AbstractInstanceRegistry 中的 getApplications 方法获取应用信息并放到缓存中。这样我们就实现了把注册信息与缓存信息进行关联。
这里有一个设计和实现上的技巧。把缓存设计为一个只读的 readOnlyCacheMap 以及一个可读写的 readWriteCacheMap,可以更好地分离职责。但因为两个缓存中保存的实际上是同一份数据,所以,我们在不断更新 readWriteCacheMap 时,也需要确保 readOnlyCacheMap 中的数据得到同步。为此 ResponseCacheImpl 提供了一个定时任务 CacheUpdateTask,如下所示:
```
private TimerTask getCacheUpdateTask() {
return new TimerTask() {
@Override
public void run() {
for (Key key : readOnlyCacheMap.keySet()) {
try {
CurrentRequestVersion.set(key.getVersion());
Value cacheValue = readWriteCacheMap.get(key);
Value currentCacheValue = readOnlyCacheMap.get(key);
if (cacheValue != currentCacheValue) {
readOnlyCacheMap.put(key, cacheValue);
}
} catch (Throwable th) {
}
}
}
};
}
```
## 服务治理API
* 获取服务列表

* 获取某个服务的实例列表

* 服务下线


* 服务上线

> 通过以上,我们了解到了一个服务治理概念,如何服务上下线,如何服务查询,以后的章节将讲解如何构建一个微服务治理平台呢?微服务治理平台都有哪些功能

## 小结
通过以上eureka的学习,我们可以总结如下:
> * 注册中心的实现主要涉及几个问题:注册中心需要提供哪些接口,该如何部署;如何存储服务信息;如何监控服务提供者节点的存活;如果服务提供者节点有变化如何通知服务消费者,以及如何控制注册中心的访问权限。
> * 注册中心必须提供以下最基本的API,例如:
服务注册接口:服务提供者通过调用服务注册接口来完成服务注册。
心跳汇报接口:服务提供者通过调用心跳汇报接口完成节点存活状态上报。
服务查询接口:查询注册中心当前注册了哪些服务信息。
服务变更查询接口:服务消费者通过调用服务变更查询接口,获取最新的可用服务节点列表。
服务修改接口:修改注册中心中某一服务的信息。
## 服务发现负载均衡
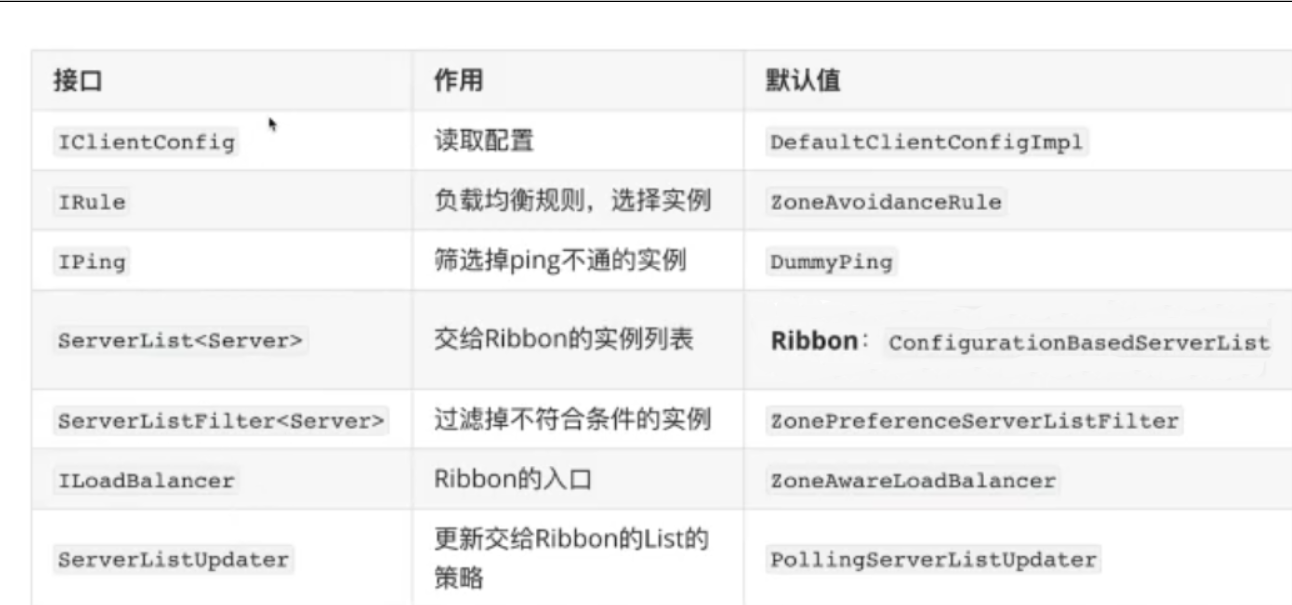
## 负载均衡主要组件
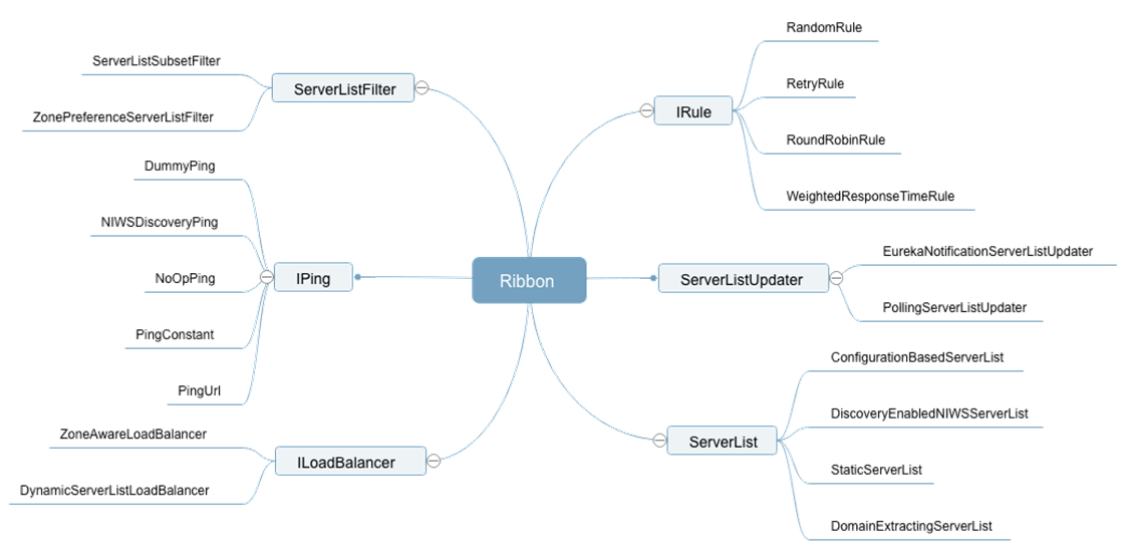
| 组件 | 作用 |
| --- | --- |
| ILoadBalancer | 定义一系列的操作接口,比如选择服务实例 |
| IRule| 算法策略,内置算法策略来为服务实例的选择提供服务|
| ServerList| 负责服务实例信息的获取,可以获取配置文件中的,也可以从注册中心获取|
| ServerListFilter| 过滤掉某些不想要的服务实例信息|
| ServerListUpdater| 更新本地缓存的服务实例信息|
| IPing| 对已有的服务实例进行可用性检查,保证选择的服务都是可用的|
## 指定负载均衡算法

## 负载均衡器通过Eureka获取动态后端服务列表

Netflix源码解析之Ribbon:负载均衡器通过Eureka获取动态后端服务列表 - 为程序员服务
Ribbon是一种客户端的负载均衡,本质上是跑在服务消费者的进程里。服务消费者要访问服务时,通过ribbon向一个服务注册的列表查询,然后以配置的负载均衡策略选择一个后端服务发起请求。
LB的定义的两个主要方法,分别是后端服务相关的调用:
~~~
public void addServers(List<Server> newServers);
public List<Server> getServerList(boolean availableOnly);
~~~
在netflix中这个服务注册列表其实就是eureka服务端集中管理的注册服务列表。获取这个列表应该就是是通过eureka的client来完成的。
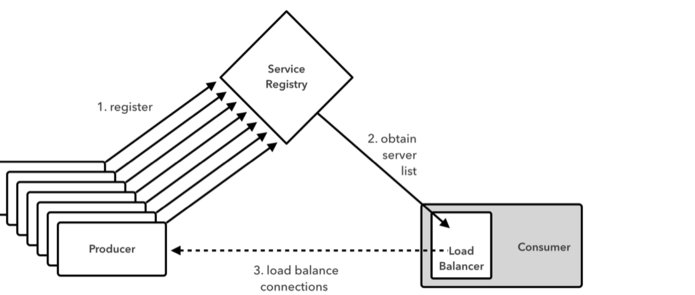
Netflix源码解析之Ribbon:负载均衡器通过Eureka获取动态后端服务列表 - 为程序员服务
也就是ribbon中应该在某个地方集成了eureka client来维护服务列表。这里尝试追踪细这个过程,确认下猜想。
[ribbon的实现](http://juke.outofmemory.cn/entry/253610) 的继承图上可以看到除了介绍的基本实现LoadBalancer外,还有DynamicServerListLoadBalancer的实现,可以动态的加载后端服务列表。正如名所示,可以动态的加载后端的服务列表。
DynamicServerListLoadBalancer中使用一个ServerListRefreshExecutorThread任务线程定期的更新后端服务列表。
~~~
class ServerListRefreshExecutorThread implements Runnable {
public void run() {
updateListOfServers();
}
}
public void updateListOfServers() {
servers = serverListImpl.getUpdatedListOfServers();
updateAllServerList(servers);
}
~~~
其实是通过com.netflix.loadbalancer.ServerList.getUpdatedListOfServers() 方法加载后端服务列表。ServerList这个接口正是用来获取加载后端服务列表。
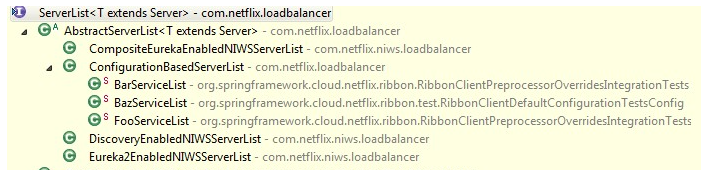
Netflix源码解析之Ribbon:负载均衡器通过Eureka获取动态后端服务列表 - 为程序员服务
看到ConfigurationBasedServerList是从配置中(可以是通过Archaius这样的集中配置)加载的。 而DiscoveryEnabledNIWSServerList这个实现中包含DiscoveryEnabled猜想应该就是服务发现框架里的服务吧。看进去果然是通过eureka client 从eureka server获取服务列表进而在ribbon中可以动态的加载。 从声明
~~~
public class DiscoveryEnabledNIWSServerList extends AbstractServerList<DiscoveryEnabledServer>{
~~~
能看到管理的服务不是一般的服务,是DiscoveryEnabledServer的服务。观察List com.netflix.niws.loadbalancer.DiscoveryEnabledNIWSServerList.obtainServersViaDiscovery() 的实现可以了解整个过程。
~~~
private List<DiscoveryEnabledServer> obtainServersViaDiscovery() {
List<DiscoveryEnabledServer> serverList = new ArrayList<DiscoveryEnabledServer>();
DiscoveryClient discoveryClient = DiscoveryManager.getInstance().getDiscoveryClient();
if (vipAddresses!=null){
for (String vipAddress : vipAddresses.split(“,”)) {
// if targetRegion is null, it will be interpreted as the same region of client
List<InstanceInfo> listOfinstanceInfo = discoveryClient.getInstancesByVipAddress(vipAddress, isSecure, targetRegion);
for (InstanceInfo ii : listOfinstanceInfo) {
if (ii.getStatus().equals(InstanceStatus.UP)) {
DiscoveryEnabledServer des = new DiscoveryEnabledServer(ii, isSecure, shouldUseIpAddr);
des.setZone(DiscoveryClient.getZone(ii));
serverList.add(des);
}
}
return serverList;
}
~~~
可以看到就是通过一个com.netflix.discovery.EurekaClient作为一个句柄来获取eureka中注册的服务列表。获取活的服务,并根据instanceInfo 构造成ribbon需要的DiscoveryEnabledServer并加到服务列表中。
## 项目pom依赖关系

## springcloud f版本以后差异
左侧2.0.x版本 右侧1.5.9版本差异



## 常见问题

### 服务感知慢的原因
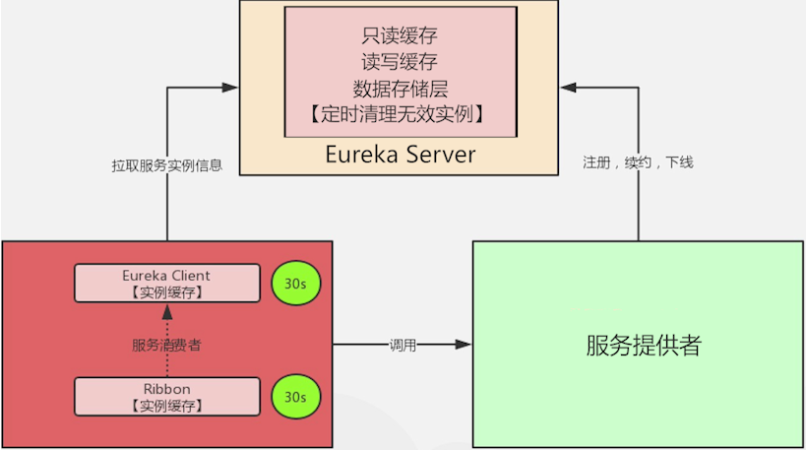
Eureka 服务感知慢的原因主要有两个,一部分是因为服务缓存导致的,另一部分是因为客户端缓存导致的。
* 服务端缓存
服务注册到注册中心后,服务实例信息是存储在注册表中的,也就是内存中。但 Eureka 为了提高响应速度,在内部做了优化,加入了两层的缓存结构,将 Client 需要的实例信息,直接缓存起来,获取的时候直接从缓存中拿数据然后响应给 Client。
第一层缓存是 readOnlyCacheMap,readOnlyCacheMap 是采用 ConcurrentHashMap
来存储数据的,主要负责定时与 readWriteCacheMap 进行数据同步,默认同步时间为 30 秒一次。
第二层缓存是 readWriteCacheMap,readWriteCacheMap 采用 Guava 来实现缓存。 缓存过期时间默认为 180 秒,当服务下线、过期、注册、状态变更等操作都会清除此缓存中的数据。
Client 获取服务实例数据时,会先从一级缓存中获取,如果一级缓存中不存在,再从二级缓存中获取,如果二级缓存也不存在,会触发缓存的加载,从存储层拉取数据到缓存中,然后再返回给 Client。Eureka 之所以设计二级缓存机制,也是为了提高 Eureka Server 的响应速度,缺点是缓存会导致 Client 获取不到最新的服务实例信息,然后导致无法快速发现新的服务和已下线的服务。了解了服务端的实现后,想要解决这个问题就变得很简单了,我们可以缩短只读缓存的更新时间(eureka.server.response-cache-update-interval-ms)让服务发现变得更加及时,或者直接将只读缓存关闭(eureka.server.use-read-only-response-cache=false),直接将只读缓存关闭适合服务量小的场景。Eureka Server 中会有定时任务去检测失效的服务,将服务实例信息从注册表中移除,也可以将这个失效检测的时间缩短,这样服务下线后就能够及时从注册表中清除。
2. 客户端缓存
客户端缓存主要分为两块内容,一块是 Eureka Client 缓存,一块是 Ribbon 缓存。
* Eureka Client 缓存
Eureka Client 负责跟 Eureka Server 进行交互,在 Eureka Client 中的com.netflix.discovery.DiscoveryClient.initScheduledTasks() 方法中,初始化了一个 CacheRefreshThread 定时任务专门用来拉取 Eureka Server 的实例信息到本地。
所以我们需要缩短这个定时拉取服务信息的时间间隔(eureka.client.registryFetchIntervalSeconds)来快速发现新的服务。
* Ribbon 缓存
Ribbon 会从 Eureka Client 中获取服务信息,ServerListUpdater 是 Ribbon 中负责服务实例更新的组件,默认的实现是 PollingServerListUpdater,通过线程定时去更新实例信息。定时刷新的时间间隔默认是 30 秒,当服务停止或者上线后,这边最快也需要 30 秒才能将实例信息更新成最新的。我们可以将这个时间调短一点,比如 3 秒。刷新间隔的参数是通过 getRefreshIntervalMs 方法来获取的,方法中的逻辑也是从 Ribbon 的配置中进行取值的。将这些服务端缓存和客户端缓存的时间全部缩短后,跟默认的配置时间相比,快了很多。我们通过调整参数的方式来尽量加快服务发现的速度。
## 总结
注册中心可以说是实现服务化的关键,因为服务化之后,服务提供者和服务消费者不在同一个进程中运行,实现了解耦,这就需要一个纽带去连接服务提供者和服务消费者,而注册中心就正好承担了这一角色。此外,服务提供者可以任意伸缩即增加节点或者减少节点,通过服务健康状态检测,注册中心可以保持最新的服务节点信息,并将变化通知给订阅服务的服务消费者。注册中心一般采用分布式集群部署,来保证高可用性。
- 前言
- 1.项目说明
- 2.项目更新日志
- 3.文档更新日志
- 01.快速开始
- 01.maven构建项目
- 02.环境安装
- 03.STS项目导入
- 03.IDEA项目导入
- 04.数据初始化
- 05.项目启动
- 06.付费文档说明
- 02.总体流程
- 1.oauth接口
- 2.架构设计图
- 3.微服务介绍
- 4.功能介绍
- 5.梳理流程
- 03.模块详解
- 01.老版本1.0.1分支模块讲解
- 01.db-core模块
- 02.api-commons模块
- 03.log-core模块
- 04.security-core模块
- 05.swagger-core模块
- 06.eureka-server模块
- 07.auth-server模块
- 08.auth-sso模块解析
- 09.user-center模块
- 10.api-gateway模块
- 11.file-center模块
- 12.log-center模块
- 13.batch-center模块
- 14.back-center模块
- 02.spring-boot-starter-web那点事
- 03.自定义db-spring-boot-starter
- 04.自定义log-spring-boot-starter
- 05.自定义redis-spring-boot-starter
- 06.自定义common-spring-boot-starter
- 07.自定义swagger-spring-boot-starter
- 08.自定义uaa-server-spring-boot-starter
- 09.自定义uaa-client-spring-boot-starter
- 10.自定义ribbon-spring-boot-starter
- 11.springboot启动原理
- 12.eureka-server模块
- 13.auth-server模块
- 14.user-center模块
- 15.api-gateway模块
- 16.file-center模块
- 17.log-center模块
- 18.back-center模块
- 19.auth-sso模块
- 20.admin-server模块
- 21.zipkin-center模块
- 22.job-center模块
- 23.batch-center
- 04.全新网关
- 01.基于spring cloud gateway的new-api-gateway
- 02.spring cloud gateway整合Spring Security Oauth
- 03.基于spring cloud gateway的redis动态路由
- 04.spring cloud gateway聚合swagger文档
- 05.技术详解
- 01.互联网系统设计原则
- 02.系统幂等性设计与实践
- 03.Oauth最简向导开发指南
- 04.oauth jdbc持久化策略
- 05.JWT token方式启用
- 06.token有效期的处理
- 07.@PreAuthorize注解分析
- 08.获取当前用户信息
- 09.认证授权白名单配置
- 10.OCP权限设计
- 11.服务安全流程
- 12.认证授权详解
- 13.验证码技术
- 14.短信验证码登录
- 15.动态数据源配置
- 16.分页插件使用
- 17.缓存击穿
- 18.分布式主键生成策略
- 19.分布式定时任务
- 20.分布式锁
- 21.网关多维度限流
- 22.跨域处理
- 23.容错限流
- 24.应用访问次数控制
- 25.统一业务异常处理
- 26.日志埋点
- 27.GPRC内部通信
- 28.服务间调用
- 29.ribbon负载均衡
- 30.微服务分布式跟踪
- 31.异步与线程传递变量
- 32.死信队列延时消息
- 33.单元测试用例
- 34.Greenwich.RELEASE升级
- 35.混沌工程质量保证
- 06.开发初探
- 1.开发技巧
- 2.crud例子
- 3.新建服务
- 4.区分前后台用户
- 07.分表分库
- 08.分布式事务
- 1.Seata介绍
- 2.Seata部署
- 09.shell部署
- 01.eureka-server
- 02.user-center
- 03.auth-server
- 04.api-gateway
- 05.file-center
- 06.log-center
- 07.back-center
- 08.编写shell脚本
- 09.集群shell部署
- 10.集群shell启动
- 11.部署阿里云问题
- 10.网关安全
- 1.openresty https保障服务安全
- 2.openresty WAF应用防火墙
- 3.openresty 高可用
- 11.docker配置
- 01.docker安装
- 02.Docker 开启远程API
- 03.采用docker方式打包到服务器
- 04.docker创建mysql
- 05.docker网络原理
- 06.docker实战
- 6.01.安装docker
- 6.02.管理镜像基本命令
- 6.03.容器管理
- 6.04容器数据持久化
- 6.05网络模式
- 6.06.Dockerfile
- 6.07.harbor部署
- 6.08.使用自定义镜像
- 12.统一监控中心
- 01.spring boot admin监控
- 02.Arthas诊断利器
- 03.nginx监控(filebeat+es+grafana)
- 04.Prometheus监控
- 05.redis监控(redis+prometheus+grafana)
- 06.mysql监控(mysqld_exporter+prometheus+grafana)
- 07.elasticsearch监控(elasticsearch-exporter+prometheus+grafana)
- 08.linux监控(node_exporter+prometheus+grafana)
- 09.micoservice监控
- 10.nacos监控
- 11.druid数据源监控
- 12.prometheus.yml
- 13.grafana告警
- 14.Alertmanager告警
- 15.监控微信告警
- 16.关于接口监控告警
- 17.prometheus-HA架构
- 18.总结
- 13.统一日志中心
- 01.统一日志中心建设意义
- 02.通过ELK收集mysql慢查询日志
- 03.通过elk收集微服务模块日志
- 04.通过elk收集nginx日志
- 05.统一日志中心性能优化
- 06.kibana安装部署
- 07.日志清理方案
- 08.日志性能测试指标
- 09.总结
- 14.数据查询平台
- 01.数据查询平台架构
- 02.mysql配置bin-log
- 03.单节点canal-server
- 04.canal-ha部署
- 05.canal-kafka部署
- 06.实时增量数据同步mysql
- 07.canal监控
- 08.clickhouse运维常见脚本
- 15.APM监控
- 1.Elastic APM
- 2.Skywalking
- 01.docker部署es
- 02.部署skywalking-server
- 03.部署skywalking-agent
- 16.压力测试
- 1.ocp.jmx
- 2.test.bat
- 3.压测脚本
- 4.压力报告
- 5.报告分析
- 6.压测平台
- 7.并发测试
- 8.wrk工具
- 9.nmon
- 10.jmh测试
- 17.SQL优化
- 1.oracle篇
- 01.基线测试
- 02.调优前奏
- 03.线上瓶颈定位
- 04.执行计划解读
- 05.高级SQL语句
- 06.SQL tuning
- 07.数据恢复
- 08.深入10053事件
- 09.深入10046事件
- 2.mysql篇
- 01.innodb存储引擎
- 02.BTree索引
- 03.执行计划
- 04.查询优化案例分析
- 05.为什么会走错索引
- 06.表连接优化问题
- 07.Connection连接参数
- 08.Centos7系统参数调优
- 09.mysql监控
- 10.高级SQL语句
- 11.常用维护脚本
- 12.percona-toolkit
- 18.redis高可用方案
- 1.免密登录
- 2.安装部署
- 3.配置文件
- 4.启动脚本
- 19.消息中间件搭建
- 19-01.rabbitmq集群搭建
- 01.rabbitmq01
- 02.rabbitmq02
- 03.rabbitmq03
- 04.镜像队列
- 05.haproxy搭建
- 06.keepalived
- 19-02.rocketmq搭建
- 19-03.kafka集群
- 20.mysql高可用方案
- 1.环境
- 2.mysql部署
- 3.Xtrabackup部署
- 4.Galera部署
- 5.galera for mysql 集群
- 6.haproxy+keepalived部署
- 21.es集群部署
- 22.生产实施优化
- 1.linux优化
- 2.jvm优化
- 3.feign优化
- 4.zuul性能优化
- 23.线上问题诊断
- 01.CPU性能评估工具
- 02.内存性能评估工具
- 03.IO性能评估工具
- 04.网络问题工具
- 05.综合诊断评估工具
- 06.案例诊断01
- 07.案例诊断02
- 08.案例诊断03
- 09.案例诊断04
- 10.远程debug
- 24.fiddler抓包实战
- 01.fiddler介绍
- 02.web端抓包
- 03.app抓包
- 25.疑难解答交流
- 01.有了auth/token获取token了为啥还要配置security的登录配置
- 02.权限数据存放在redis吗,代码在哪里啊
- 03.其他微服务和认证中心的关系
- 04.改包问题
- 05.use RequestContextListener or RequestContextFilter to expose the current request
- 06./oauth/token对应代码在哪里
- 07.验证码出不来
- 08./user/login
- 09.oauth无法自定义权限表达式
- 10.sleuth引发线程数过高问题
- 11.elk中使用7x版本问题
- 12.RedisCommandTimeoutException问题
- 13./oauth/token CPU过高
- 14.feign与权限标识符问题
- 15.动态路由RedisCommandInterruptedException: Command interrupted
- 26.学习资料
- 海量学习资料等你来拿
- 27.持续集成
- 01.git安装
- 02.代码仓库gitlab
- 03.代码仓库gogs
- 04.jdk&&maven
- 05.nexus安装
- 06.sonarqube
- 07.jenkins
- 28.Rancher部署
- 1.rancher-agent部署
- 2.rancher-server部署
- 3.ocp后端部署
- 4.演示前端部署
- 5.elk部署
- 6.docker私服搭建
- 7.rancher-server私服
- 8.rancher-agent docker私服
- 29.K8S部署OCP
- 01.准备OCP的构建环境和部署环境
- 02.部署顺序
- 03.在K8S上部署eureka-server
- 04.在K8S上部署mysql
- 05.在K8S上部署redis
- 06.在K8S上部署auth-server
- 07.在K8S上部署user-center
- 08.在K8S上部署api-gateway
- 09.在K8S上部署back-center
- 30.Spring Cloud Alibaba
- 01.统一的依赖管理
- 02.nacos-server
- 03.生产可用的Nacos集群
- 04.nacos配置中心
- 05.common.yaml
- 06.user-center
- 07.auth-server
- 08.api-gateway
- 09.log-center
- 10.file-center
- 11.back-center
- 12.sentinel-dashboard
- 12.01.sentinel流控规则
- 12.02.sentinel熔断降级规则
- 12.03.sentinel热点规则
- 12.04.sentinel系统规则
- 12.05.sentinel规则持久化
- 12.06.sentinel总结
- 13.sentinel整合openfeign
- 14.sentinel整合网关
- 1.sentinel整合zuul
- 2.sentinel整合scg
- 15.Dubbo与Nacos共存
- 31.Java源码剖析
- 01.基础数据类型和String
- 02.Arrays工具类
- 03.ArrayList源码分析
- 32.面试专题汇总
- 01.JVM专题汇总
- 02.多线程专题汇总
- 03.Spring专题汇总
- 04.springboot专题汇总
- 05.springcloud面试汇总
- 文档问题跟踪处理