[TOC]
## Twitter Zipkin
Twitter公司的Zipkin是Google的Dapper系统的开源实现,Zipkin严格按照Dapper论文实现,采用Scala编写,并且紧密集成到Twitter公司自己的分布式服务Finagle中,使得跟踪做到对应用透明。

## 完整的调用链
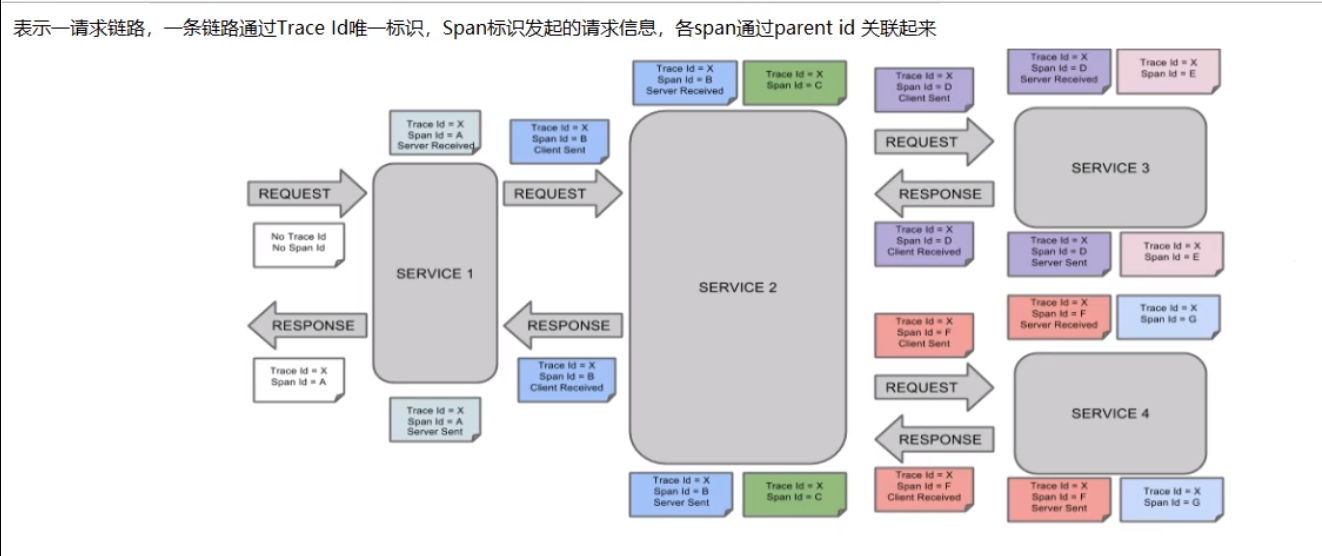
## 链路跟踪核心概念
* Span
基本工作单元,例如,发送 RPC 请求是一个新的 Span,发送 HTTP 请求是一个新的 Span,内部方法调用也是一个新的 Span。
* Trace
一次分布式调用的链路信息,每次调用链路信息都会在请求入口处生成一个 TraceId。
* Annotation
用于记录事件的信息。在 Annotation 中会有 CS、SR、SS、CR 这些信息,下面分别介绍下这些信息的作用。
* CS
也就是 Client Sent,客户端发起一个请求,这个 Annotation 表示 Span 的开始。
* SR
也就是 Server Received,服务器端获得请求并开始处理它,用 SR 的时间戳减去 CS 的时间戳会显示网络延迟时间。
* SS
也就是 Server Sent,在请求处理完成时将响应发送回客户端,用 SS 的间戳减去 SR 的时间戳会显示服务器端处理请求所需的时间。
* CR
也就是 Client Received,表示 Span 的结束,客户端已成功从服务器端收到响应,用 CR 的时间戳减去 CS 的时间戳就可以知道客户端从服务器接收响应所需的全部时间。
* MQ方式

* 启动工程

* es-server
* es-client

* 访问[http://127.0.0.1:9412/hello](http://127.0.0.1:9412/hello)后会通过kafka上报,通过es-server查看调用


* 消息持久化

* 手动埋点


* 埋点效果展现
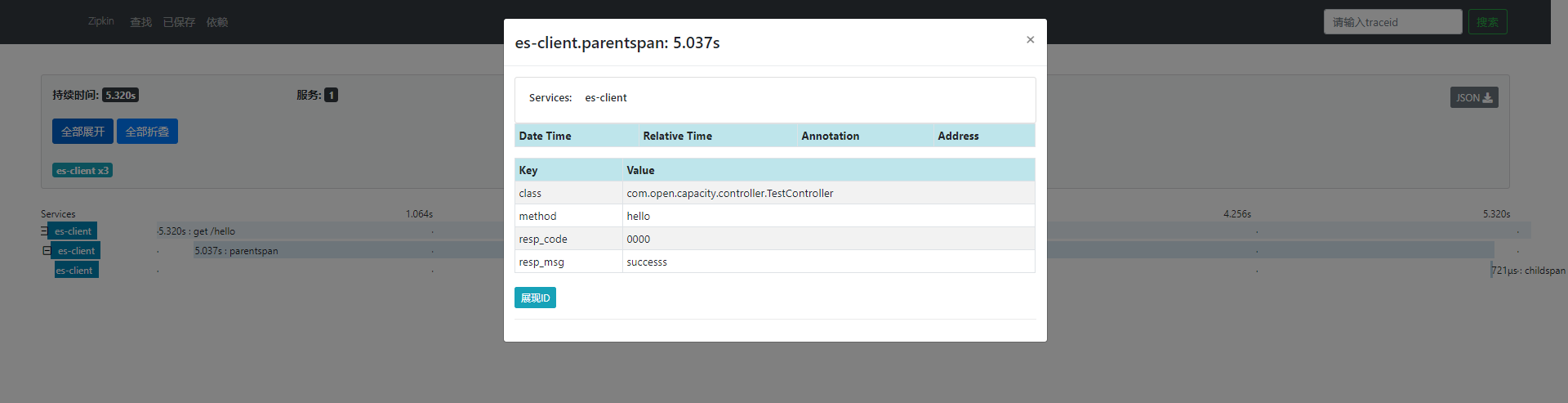
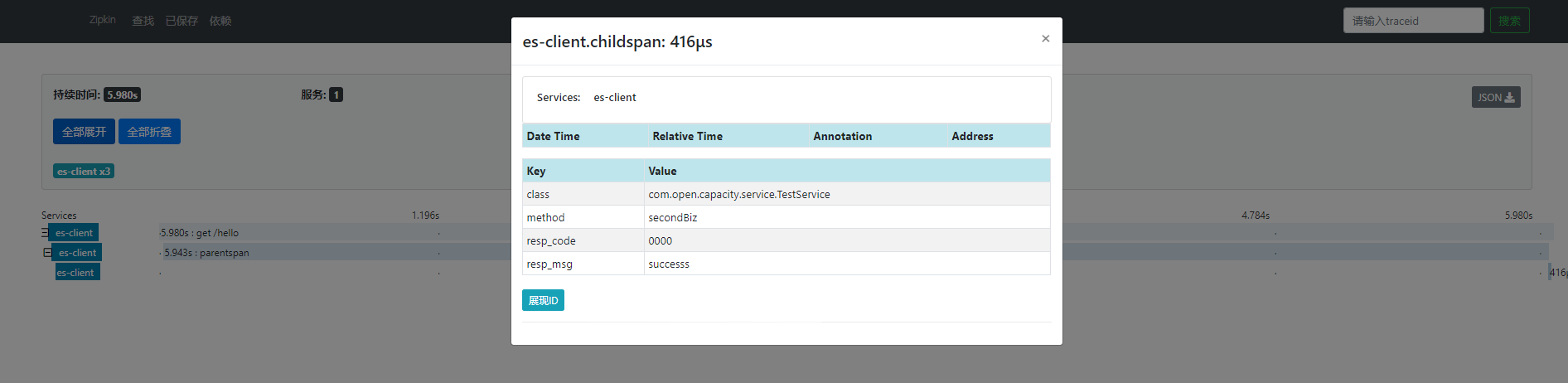
* es数据
## 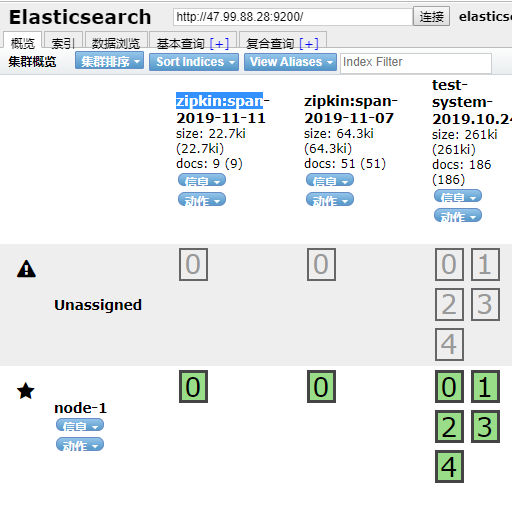
* zipkin数据清理
```
#!/bin/bash
# owen 2017
#调用链的数据只保留7天的
old_date=`date +%Y-%m-%d -d "7 days ago"`
curl -XDELETE "http://127.0.0.1:9200/zipkin:span-${old_date}"
```
## 使用 Brave 创建自定义 Span
从 2.X 版本开始,Spring Cloud Sleuth 全面使用 Brave 作为其底层的服务跟踪实现框架。原本在 1.X 版本中通过 Spring Cloud Sleuth 自带的 org.springframework.cloud.sleuth.Tracer 接口创建和管理自定义 Span 的方法将不再有效。因此,想要在访问链路中创建自定义的 Span,需要对 Brave 框架所提供的功能有足够的了解。
事实上,Brave 是 Java 版的 Zipkin 客户端,它将收集的跟踪信息,以 Span 的形式上报给 Zipkin 系统。我们首先来关注 Brave 中的 Span 类,该类的方法列表如下所示:

注意到 Span 是一个抽象类,在上面的方法列表中,我们也看到该类的几乎所有方法都是抽象方法,需要子类进行实现。在 Brave 中,该抽象类的子类就是 RealSpan。RealSpan 中的 start 方法如下所示:
```
@Override
public Span start(long timestamp) {
synchronized (state) {
state.startTimestamp(timestamp);
}
return this;
}
```
这里的 state 是一个可变的 MutableSpan,而上述 start 方法就是为这个 MutableSpan 设置了开始时间。可以想象,对应的 finish 方法也会为 MutableSpan 设置结束时间,如下所示:
```
@Override
public void finish(long timestamp) {
if (!pendingSpans.remove(context)) return;
synchronized (state) {
state.finishTimestamp(timestamp);
}
finishedSpanHandler.handle(context, state);
}
```
对于关闭 Span 的操作而言,上述方法还添加了一个 Handler 以便执行回调逻辑,这也是非常常见的一种实现技巧。我们接着来看另一个非常有用的 annotate 方法,如下所示:
```
@Override
public Span annotate(long timestamp, String value) {
if ("cs".equals(value)) {
synchronized (state) {
state.kind(Span.Kind.CLIENT);
state.startTimestamp(timestamp);
}
} else if ("sr".equals(value)) {
synchronized (state) {
state.kind(Span.Kind.SERVER);
state.startTimestamp(timestamp);
}
} else if ("cr".equals(value)) {
synchronized (state) {
state.kind(Span.Kind.CLIENT);
}
finish(timestamp);
} else if ("ss".equals(value)) {
synchronized (state) {
state.kind(Span.Kind.SERVER);
}
finish(timestamp);
} else {
synchronized (state) {
state.annotate(timestamp, value);
}
}
return this;
}
```
### Tracer
首先,我们来看如何通过 Tracer 创建一个新的根 Span,可以通过如下所示的 newTrace 方法进行实现:
```
public Span newTrace() {
return _toSpan(newRootContext());
}
```
这里用到了一个保存跟踪信息的 TraceContext 上下文对象,对于根 Span 而言,这个 TraceContext 就是全新的上下文,没有父 Span。而这里的 _toSpan 方法则最终构建了一个前面提到的 RealSpan 对象。
```
Span _toSpan(TraceContext decorated) {
if (isNoop(decorated)) return new NoopSpan(decorated);
PendingSpan pendingSpan = pendingSpans.getOrCreate(decorated, false);
return new RealSpan(decorated, pendingSpans, pendingSpan.state(), pendingSpan.clock(), finishedSpanHandler);
}
```
这里多了一个新建的对象叫 PendingSpan ,用于收集一条 Trace 上暂时被挂起的未完成的 Span。
一旦创建了根 Span,我们就可以在这个 Span 上执行 nextSpan 方法来添加新的 Span,如下所示:
```
public Span nextSpan() {
TraceContext parent = currentTraceContext.get();
return parent != null ? newChild(parent) : newTrace();
}
```
这里获取当前 TraceContext,如果该上下文不存在,就通过 newTrace 方法来创建一个新的根 Span;如果存在,则基于这个上下文并调用 newChild 方法来创建一个子 Span。newChild 方法也比较简单,如下所示:
```
public Span newChild(TraceContext parent) {
if (parent == null) throw new NullPointerException("parent == null");
return _toSpan(nextContext(parent));
}
```
当然,在很多场景下,我们首先需要获取当前的 Span,这时候就可以使用 Tracer 类所提供的 currentSpan 方法,如下所示:
```
public Span currentSpan() {
TraceContext currentContext = currentTraceContext.get();
return currentContext != null ? toSpan(currentContext) : null;
}
```
基于 Tracer 提供的这些常见方法,我们可以梳理在业务代码中添加一个自定义的 Span 模版方法,如下所示:
```
@Service
public class MyService {
@Autowired
private Tracer tracer;
public void perform() {
Span newSpan = tracer.nextSpan().name("spanName").start();
//ScopedSpan newSpan = tracer.startScopedSpan("spanName");
try {
//执行业务逻辑
}
finally{
newSpan.tag("key", "value");
newSpan.annotate("myannotation");
newSpan.finish();
}
}
}
```
在上述代码中,我们注入了一个 Tracer 对象,然后通过 nextSpan().name("findByDeviceCode").start() 方法创建并启动了一个“spanName”新的 Span。这是在业务代码中嵌入自定义 Span 的一种方法。另一种方法是使用注释行代码中的 ScopedSpan,ScopedSpan 代表包含一定操作延迟的 Span 对象,可以在操作不脱离当前进程时可以使用。当我们执行完各种业务逻辑之后,可以分别通过 tag 方法和 annotate 添加标签和定义事件,最后通过 finish 方法关闭 Span。这段模版代码可以直接引入到日常的开发过程中。
## zipkin中的 mq
老版本zpikin使用到了spring cloud stream
### Spring Cloud Stream
Spring Cloud 专门提供了一个 Spring Cloud Stream 框架来实现事件驱动架构,并完成与主流消息中间件的集成。同时,Spring Cloud Stream 背后也整合了 Spring 家族中的消息处理和消息总线方面的几个框架,可以说是 Spring Cloud 中整合程度最高的一个开发框架。
### Spring 家族中的消息处理机制
在了解了事件驱动架构以及消息中间件的基本概念之后,我们来看一下 Spring 中针对这些概念提供的技术解决方案。在 Spring 家族中,与消息处理机制相关的框架有三个。事实上, Spring Cloud Stream 是基于 Spring Integration 实现了消息发布和消费机制并提供了一层封装,很多关于消息发布和消费的概念和实现方法本质上都是依赖于 Spring Integration。而在 Spring Integration 的背后,则依赖于 Spring Messaging 组件来实现消息处理机制的基础设施。这三个框架之间的依赖关系如下图所示:
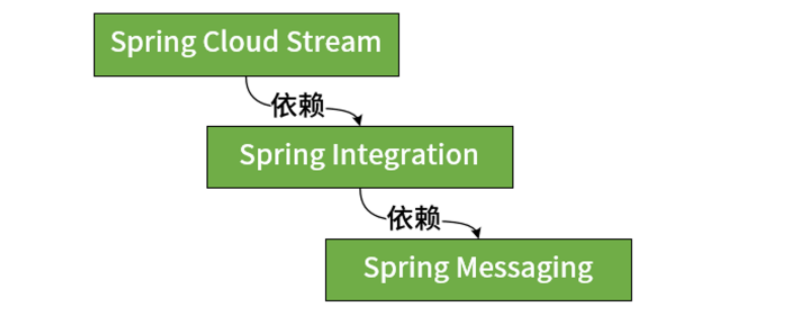
接下来的内容,我们先来对位于底层的 Spring Messaging 和 Spring Integration 框架做一些展开,方便你在使用 Spring Cloud Stream 时对其背后的实现原理有更好的理解。
Spring Messaging
Spring Messaging 是 Spring 框架中的一个底层模块,用于提供统一的消息编程模型。例如,消息这个数据单元在 Spring Messaging 中统一定义为如下所示的 Message 接口,包括一个消息头 Header 和一个消息体 Payload:
```
public interface Message<T> {
T getPayload();
MessageHeaders getHeaders();
}
```
而消息通道 MessageChannel 的定义也比较简单,我们可以调用 send() 方法将消息发送至该消息通道中,MessageChannel 接口定义如下所示:
复制代码
~~~
public interface MessageChannel {
long INDEFINITE_TIMEOUT = -1;
default boolean send(Message<?> message) {
return send(message, INDEFINITE_TIMEOUT);
}
boolean send(Message<?> message, long timeout);
}
~~~
消息通道的概念比较抽象,可以简单把它理解为是对队列的一种抽象。我们知道在消息传递系统中,队列的作用就是实现存储转发的媒介,消息发布者所生成的消息都将保存在队列中并由消息消费者进行消费。通道的名称对应的就是队列的名称,但是作为一种抽象和封装,各个消息传递系统所特有的队列概念并不会直接暴露在业务代码中,而是通过通道来对队列进行配置。
Spring Messaging 把通道抽象成如下所示的两种基本表现形式,即支持轮询的 PollableChannel 和实现发布-订阅模式的 SubscribableChannel,这两个通道都继承自具有消息发送功能的 MessageChannel:
```
public interface PollableChannel extends MessageChannel {
Message<?> receive();
Message<?> receive(long timeout);
}
public interface SubscribableChannel extends MessageChannel {
boolean subscribe(MessageHandler handler);
boolean unsubscribe(MessageHandler handler);
}
```
我们注意到对于 PollableChannel 而言才有 receive 的概念,代表这是通过轮询操作主动获取消息的过程。而 SubscribableChannel 则是通过注册回调函数 MessageHandler 来实现事件响应。MessageHandler 接口定义如下:
```
public interface MessageHandler {
void handleMessage(Message<?> message) throws MessagingException;
}
```
Spring Messaging 在基础消息模型之上还提供了很多方便在业务系统中使用消息传递机制的辅助功能,例如各种消息体内容转换器 MessageConverter 以及消息通道拦截器 ChannelInterceptor 等,这里不做展开,你可以参考官方文档做进一步了解。
### Spring Integration
Spring Integration 是对 Spring Messaging 的扩展,提供了对系统集成领域的经典著作《企业集成模式:设计构建及部署消息传递解决方案》中所描述的各种企业集成模式的支持,通常被认为是一种企业服务总线 ESB 框架。
在 Spring Messaging 的基础上,Spring Integration 还实现了其他几种有用的通道,包括支持阻塞式队列的 RendezvousChannel,该通道与带缓存的 QueueChannel 都属于点对点通道,但只有在前一个消息被消费之后才能发送下一个消息。PriorityChannel 即优先级队列,而 DirectChannel 是 Spring Integration 的默认通道,该通道的消息发送和接收过程处于同一线程中。另外还有 ExecutorChannel,使用基于多线程的 TaskExecutor 来异步消费通道中的消息。
Spring Integration 的设计目的是系统集成,因此内部提供了大量的集成化端点方便应用程序直接使用。当各个异构系统之间进行集成时,如何屏蔽各种技术体系所带来的差异性,Spring Integration 为我们提供了解决方案。通过通道之间的消息传递,在消息的入口和出口我们可以使用通道适配器和消息网关这两种典型的端点对消息进行同构化处理。Spring Integration 提供的常见集成端点包括 File、FTP、TCP/UDP、HTTP、JDBC、JMS、AMQP、JPA、Mail、MongoDB、Redis、RMI、Web Services 等。
### Spring Cloud Stream 基本架构
Spring Cloud Stream 对整个消息发布和消费过程做了高度抽象,并提供了一系列核心组件。我们先介绍通过 Spring Cloud Stream 构建消息传递机制的基本工作流程。区别于直接使用 RabbitMQ、Kafka 等消息中间件,Spring Cloud Stream 在消息生产者和消费者之间添加了一种桥梁机制,所有的消息都将通过 Spring Cloud Stream 进行发送和接收,如下图所示:
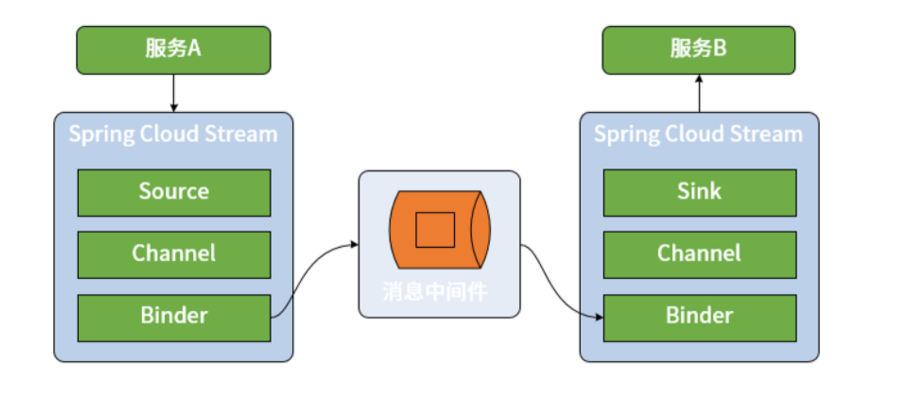
在上图中,我们不难看出 Spring Cloud Stream 具备四个核心组件,分别是 Binder、Channel、Source 和 Sink,其中 Binder 和 Channel 成对出现,而 Source 和 Sink 分别面向消息的发布者和消费者。
* Source 和 Sink
在 Spring Cloud Stream 中,Source 组件是真正生成消息的组件,相当于是一个输出(Output)组件。而 Sink 则是真正消费消息的组件,相当于是一个输入(Input)组件。根据我们对事件驱动架构的了解,对于同一个 Source 组件而言,不同的微服务可能会实现不同的 Sink 组件,分别根据自身需求进行业务上的处理。
在 Spring Cloud Stream 中,Source 组件使用一个普通的 POJO 对象来充当需要发布的消息,通过将该对象进行序列化(默认的序列化方式是 JSON)然后发布到 Channel 中。另一方面,Sink 组件监听 Channel 并等待消息的到来,一旦有可用消息,Sink 将该消息反序列化为一个 POJO 对象并用于处理业务逻辑。
* Channel
Channel 的概念比较容易理解,就是常见的通道,是对队列的一种抽象。根据前面
所讨论的结果,我们知道在消息传递系统中,队列的作用就是实现存储转发的媒介,消息生产者所生成的消息都将保存在队列中并由消息消费者进行消费。通道的名称对应的往往就是队列的名称。
* Binder
Spring Cloud Stream 中最重要的概念就是 Binder。所谓 Binder,顾名思义就是一种黏合剂,将业务服务与消息传递系统黏合在一起。通过 Binder,我们可以很方便地连接消息中间件,可以动态的改变消息的目标地址、发送方式而不需要了解其背后的各种消息中间件在实现上的差异。
### Spring Cloud Stream 集成 Spring 消息处理机制
结合上面中了解到的关于 Spring Messaging 和 Spring Integration 的相关概念,我们就不难理解 Spring Cloud Stream 中关于 Source 和 Sink 的定义。Source 和 Sink 都是接口,其中 Source 接口的定义如下:
```
import org.springframework.cloud.stream.annotation.Output;
import org.springframework.messaging.MessageChannel;
public interface Source {
String OUTPUT = "output";
@Output(Source.OUTPUT)
MessageChannel output();
}
```
注意到这里通过 MessageChannel 来发送消息,而 MessageChannel 类来自 Spring Messaging 组件。我们在 MessageChannel 上发现了一个 @Output 注解,该注解定义了一个输出通道。
类似的,Sink 接口定义如下:
```
import org.springframework.cloud.stream.annotation.Input;
import org.springframework.messaging.SubscribableChannel;
public interface Sink{
String INPUT = "input";
@Input(Sink.INPUT)
SubscribableChannel input();
}
```
同样,这里通过 Spring Messaging 中的 SubscribableChannel 来实现消息接收,而 @Input 注解定义了一个输入通道。
注意到 @Input 和 @Output 注解使用通道名称作为参数,如果没有名称,会使用带注解的方法名字作为参数,也就是默认情况下分别使用“input”和“output”作为通道名称。从这个角度讲,一个 Spring Cloud Stream 应用程序中的 Input 和 Output 通道数量和名称都是可以任意设置的,我们只需要在这些通道的定义上添加 @Input 和 @Output 注解即可。
Spring Cloud Stream 对 Spring Messaging 和 Spring Integration 提供了原生支持。在常规情况下,我们不需要使用这些框架中提供的API就能完成常见的开发需求。但如果确实有需要,我们也可以使用更为底层 API 直接操控消息发布和接收过程。
### Spring Cloud Stream 中的消息传递模型
Spring Cloud Stream 将消息发布和消费抽象成如下三个核心概念,并结合目前主流的一些消息中间件对这些概念提供了统一的实现方式。
* 发布-订阅模型
我们知道点对点模型和发布-订阅模型是传统消息传递系统的两大基本模型,其中点对点模型实际上可以被视为发布-订阅模型在订阅者数量为 1 时的一种特例。因此,在 Spring Cloud Stream 中,统一通过发布-订阅模型完成消息的发布和消费,如下所示:
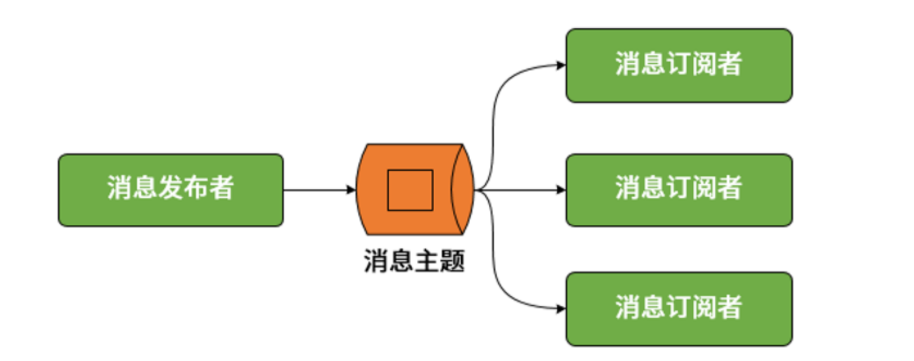
* 消费者组
设计消费者组(Consumer Group)的目的是应对集群环境下的多服务实例问题。显然,如果采用发布-订阅模式就会导致一个服务的不同实例都消费到了同一条消息。为了解决这个问题,Spring Cloud Stream 中提供了消费者组的概念。一旦使用了消费组,一条消息就只能被同一个组中的某一个服务实例所消费。消费者的基本结构如下图所示(其中虚线表示不会发生的消费场景):

* 消息分区
假如我们希望相同的消息都被同一个微服务实例来处理,但又有多个服务实例组成了负载均衡结构,那么通过上述的消费组概念仍然不能满足要求。针对这一场景,Spring Cloud Stream 又引入了消息分区(Partition)的概念。引入分区概念的意义在于,同一分区中的消息能够确保始终是由同一个消费者实例进行消费。尽管消息分区的应用场景并没有那么广泛,但如果想要达到类似的效果,Spring Cloud Stream 也为我们提供了一种简单的实现方案,消息分区的基本结构如下图所示:

### Binder 与消息中间件
Binder 组件本质上是一个中间层,负责与各种消息中间件的交互。目前,Spring Cloud Stream 中集成的消息中间件包括 RabbitMQ和Kafka。在具体介绍如何使用 Spring Cloud Stream 进行消息发布和消费之前,我们先来结合消息传递机制给出 Binder 对这两种不同消息中间件的整合方式。
* RabbitMQ
RabbitMQ 是 AMQP(Advanced Message Queuing Protocol,高级消息队列协议)协议的典型实现框架。在 RabbitMQ 中,核心概念是交换器(Exchange)。我们可以通过控制交换器与队列之间的路由规则来实现对消息的存储转发、点对点、发布-订阅等消息传递模型。在一个 RabbitMQ 中可能会存在多个队列,交换器如果想要把消息发送到具体某一个队列,就需要通过两者之间的绑定规则来设置路由信息。路由信息的设置是开发人员操控 RabbitMQ 的主要手段,而路由过程的执行依赖于消息头中的路由键(Routing Key)属性。交换器会检查路由键并结合路由算法来决定将消息路由到哪个队列中去。下图就是交换器与队列之间的路由关系图:

可以看到一条来自生产者的消息通过交换器中的路由算法可以发送给一个或多个队列,从而分别实现点对点和发布订阅功能。同时,我们基于上图也不难得出消费者组的实现方案。因为 RabbitMQ 里每个队列是被消费者竞争消费的,所以指定同一个组的消费者消费同一个队列就可以实现消费者组。
* Kafka
从架构上讲,在 Kafka 中,生产者使用推模式将消息发布到服务器,而消费者使用拉模式从服务器订阅消息。在 Kafka 中还使用到了 Zookeeper,其作用在于实现服务器与消费者之间的负载均衡,所以启动 Kafka 之前必须确保 Zookeeper 正常运行。同时,Kafka 也实现了消费者组机制,如下图所示:
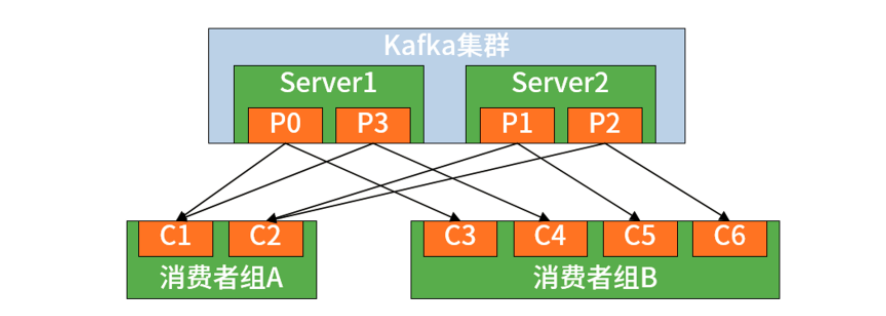
可以看到多个消费者构成了一种组结构,消息只能传输给某个组中的某一个消费者。也就是说,Kafka 中消息的消费具有显式的分布式特性,天生就内置了 Spring Cloud Stream 中的消费组概念。
Spring Cloud Stream 中的 Binder
通过前面的介绍,我们明确了 Binder 组件是 Spring Cloud Stream 与各种消息中间件进行集成的核心组件,而 Binder 组件的实现过程涉及一批核心类之间的相互协作。接下来,我们就对 Binder 相关的核心类做源码级的展开。
BindableProxyFactory
我们知道在发送和接收消息时,需要使用 @EnableBinding 注解,该注解的作用就是告诉 Spring Cloud Stream 将该应用程序绑定到消息中间件,从而实现两者之间的连接。我们来到 org.springframework.cloud.stream.binding 包下的 BindableProxyFactory 类。根据该类上的注释,BindableProxyFactory 是用于初始化由 @EnableBinding 注解所提供接口的工厂类,该类的定义如下所示:
```
public class BindableProxyFactory implements MethodInterceptor, FactoryBean<Object>, Bindable, InitializingBean
```
注意到 BindableProxyFactory 同时实现了 MethodInterceptor 接口和 Bindable 接口。其中前者是 AOP 中的方法拦截器,而后者是一个标明能够绑定 Input 和 Output 的接口。我们先来看 MethodInterceptor 中用于拦截的 invoke 方法,如下所示:
```
@Override
public synchronized Object invoke(MethodInvocation invocation) throws Throwable {
Method method = invocation.getMethod();
Object boundTarget = targetCache.get(method);
if (boundTarget != null) {
return boundTarget;
}
Input input = AnnotationUtils.findAnnotation(method, Input.class);
if (input != null) {
String name = BindingBeanDefinitionRegistryUtils.getBindingTargetName(input, method);
boundTarget = this.inputHolders.get(name).getBoundTarget();
targetCache.put(method, boundTarget);
return boundTarget;
}
else {
Output output = AnnotationUtils.findAnnotation(method, Output.class);
if (output != null) {
String name = BindingBeanDefinitionRegistryUtils.getBindingTargetName(output, method);
boundTarget = this.outputHolders.get(name).getBoundTarget();
targetCache.put(method, boundTarget);
return boundTarget;
}
}
return null;
}
```
这里的逻辑比较简单,可以看到 BindableProxyFactory 保存了一个缓存对象 targetCache。如果所调用方法已经存在于缓存中,则直接返回目标对象。反之,会根据 @Input 和 @Output 注解从 inputHolders 和 outputHolders 中获取对应的目标对象并放入缓存中。这里使用缓存的作用仅仅是为了加快每次方法调用的速度,而系统在初始化时通过重写 afterPropertiesSet 方法,已经将所有的目标对象都放置在 inputHolders 和 outputHolders 这两个集合中。至于这里提到的这个目标对象,暂时可以把它理解为就是一种 MessageChannel 对象,后面会对其进行展开。
然后我们来看 Bindable 接口的定义,如下所示:
```
public interface Bindable {
default Collection<Binding<Object>> createAndBindInputs(BindingService adapter) {
return Collections.<Binding<Object>>emptyList();
}
default void bindOutputs(BindingService adapter) {}
default void unbindInputs(BindingService adapter) {}
default void unbindOutputs(BindingService adapter) {}
default Set<String> getInputs() {
return Collections.emptySet();
}
default Set<String> getOutputs() {
return Collections.emptySet();
}
}
```
显然,这个接口提供了对 Input 和 Output 的绑定和解绑操作。在 BindableProxyFactory 中,对以上几个方法的实现过程基本都类似,我们随机挑选一个 bindOutputs 方法进行展开,如下所示:
```
@Override
public void bindOutputs(BindingService bindingService) {
for (Map.Entry<String, BoundTargetHolder> boundTargetHolderEntry : this.outputHolders.entrySet()) {
BoundTargetHolder boundTargetHolder = boundTargetHolderEntry.getValue();
String outputTargetName = boundTargetHolderEntry.getKey();
if (boundTargetHolderEntry.getValue().isBindable()) {
if (log.isDebugEnabled()) {
log.debug(String.format("Binding %s:%s:%s", this.namespace, this.type, outputTargetName));
}
bindingService.bindProducer(boundTargetHolder.getBoundTarget(), outputTargetName);
}
}
}
```
这里需要引入另一个重要的工具类 BindingService,该类提供了对 Input 和 Output 目标对象进行绑定的能力。但事实上,通过类上的注释可以看到,这也是一个外观类,它将底层的绑定动作委托给了 Binder。我们以绑定生产者的 bindProducer 方法为例展开讨论,该方法如下所示:
```
public <T> Binding<T> bindProducer(T output, String outputName) {
String bindingTarget = this.bindingServiceProperties
.getBindingDestination(outputName);
Binder<T, ?, ProducerProperties> binder = (Binder<T, ?, ProducerProperties>) getBinder(
outputName, output.getClass());
ProducerProperties producerProperties = this.bindingServiceProperties
.getProducerProperties(outputName);
if (binder instanceof ExtendedPropertiesBinder) {
Object extension = ((ExtendedPropertiesBinder) binder)
.getExtendedProducerProperties(outputName);
ExtendedProducerProperties extendedProducerProperties = new ExtendedProducerProperties<>(
extension);
BeanUtils.copyProperties(producerProperties, extendedProducerProperties);
producerProperties = extendedProducerProperties;
}
validate(producerProperties);
Binding<T> binding = doBindProducer(output, bindingTarget, binder, producerProperties);
this.producerBindings.put(outputName, binding);
return binding;
}
```
显然,这里的 doBindProducer 方法完成了真正的绑定操作,如下所示:
```
public <T> Binding<T> doBindProducer(T output, String bindingTarget, Binder<T, ?, ProducerProperties> binder,
ProducerProperties producerProperties) {
if (this.taskScheduler == null || this.bindingServiceProperties.getBindingRetryInterval() <= 0) {
return binder.bindProducer(bindingTarget, output, producerProperties);
}
else {
try {
return binder.bindProducer(bindingTarget, output, producerProperties);
}
catch (RuntimeException e) {
LateBinding<T> late = new LateBinding<T>();
rescheduleProducerBinding(output, bindingTarget, binder, producerProperties, late, e);
return late;
}
}
}
```
从这个方法中,我们终于看到了 Spring Cloud Stream 中最核心的概念 Binder,通过 Binder 的 bindProducer 方法完成了目标对象的绑定。
Binder
Binder 是一个接口,分别提供了绑定生产者和消费者的方法,如下所示:
```
public interface Binder<T, C extends ConsumerProperties, P extends ProducerProperties> {
Binding<T> bindConsumer(String name, String group, T inboundBindTarget, C consumerProperties);
Binding<T> bindProducer(String name, T outboundBindTarget, P producerProperties);
}
```
在介绍 Binder 接口的具体实现类之前,我们先来看一下如何获取一个 Binder,getBinder 方法如下所示。
```
protected <T> Binder<T, ?, ?> getBinder(String channelName, Class<T> bindableType) {
String binderConfigurationName = this.bindingServiceProperties.getBinder(channelName);
return binderFactory.getBinder(binderConfigurationName, bindableType);
```
显然,这里用到了个工厂模式。工厂类 BinderFactory 的定义如下所示:
```
public interface BinderFactory {
<T> Binder<T, ? extends ConsumerProperties, ? extends ProducerProperties> getBinder(String configurationName,
Class<? extends T> bindableType);
}
```
BinderFactory 只有一个方法,根据给定的配置名称 configurationName 和绑定类型 bindableType 获取 Binder 实例。而 BinderFactory 的实现类也只有一个,即 DefaultBinderFactory。在该实现类的 getBinder 方法中对配置信息进行了校验,并通过 getBinderInstance 获取真正的 Binder 实例。在 getBinderInstance 方法中,我们通过一系列基于 Spring 容器的步骤构建了一个上下文对象 ConfigurableApplicationContext,并通过该上下文对象获取实现了 Binder 接口的 Java bean,核心代码就是下面这句:
Binder<T, ?, ?> binder = binderProducingContext.getBean(Binder.class);
当然,对于 BinderFactory 而言,缓存也是需要的。在 DefaultBinderFactory 中存在一个 binderInstanceCache 变量,使用了一个 Map 来保存配置名称所对应的 Binder 对象。
AbstractMessageChannelBinder
既然我们已经能够获取 Binder 实例,接下去就来讨论 Binder 实例中对 bindConsumer 和 bindProducer 方法的实现过程。在 Spring Cloud Stream 中,Binder 接口的类层关系如下所示,注意到这里还展示了 spring-cloud-stream-binder-rabbit 代码工程中的 RabbitMessageChannelBinder 类,这个类在以下讲到 Spring Cloud Stream 与 RabbitMQ 进行集成时会具体展开:

Binder 接口类层结构图
Spring Cloud Stream 首先提供了一个 AbstractBinder,这是一个抽象类,提供的 bindConsumer 和 bindProducer 方法实现如下所示:
```
@Override
public final Binding<T> bindConsumer(String name, String group, T target, C properties) {
if (StringUtils.isEmpty(group)) {
Assert.isTrue(!properties.isPartitioned(), "A consumer group is required for a partitioned subscription");
}
return doBindConsumer(name, group, target, properties);
}
protected abstract Binding<T> doBindConsumer(String name, String group, T inputTarget, C properties);
@Override
public final Binding<T> bindProducer(String name, T outboundBindTarget, P properties) {
return doBindProducer(name, outboundBindTarget, properties);
}
protected abstract Binding<T> doBindProducer(String name, T outboundBindTarget, P properties);
```
可以看到,它对 Binder 接口中相关方法只是提供了空实现,并把具体实现过程通过 doBindConsumer 和 doBindProducer 抽象方法交由子类进行完成。显然,从设计模式上讲,AbstractBinder 应用了很典型的模板方法模式。
AbstractBinder 的子类是 AbstractMessageChannelBinder,它同样也是一个抽象类。我们来看它的 doBindProducer 方法,并对该方法中的核心语句进行提取和整理:
```
@Override
public final Binding<MessageChannel> doBindProducer(final String destination, MessageChannel outputChannel,
final P producerProperties) throws BinderException {
…
final MessageHandler producerMessageHandler;
final ProducerDestination producerDestination;
try {
producerDestination = this.provisioningProvider.provisionProducerDestination(destination,
producerProperties);
SubscribableChannel errorChannel = producerProperties.isErrorChannelEnabled()
? registerErrorInfrastructure(producerDestination) : null;
producerMessageHandler = createProducerMessageHandler(producerDestination, producerProperties,
errorChannel);
…
postProcessOutputChannel(outputChannel, producerProperties);
((SubscribableChannel) outputChannel).subscribe(
new SendingHandler(producerMessageHandler, HeaderMode.embeddedHeaders
.equals(producerProperties.getHeaderMode()), this.headersToEmbed,
producerProperties.isUseNativeEncoding()));
Binding<MessageChannel> binding = new DefaultBinding<MessageChannel>(destination, null, outputChannel,
producerMessageHandler instanceof Lifecycle ? (Lifecycle) producerMessageHandler : null) {
…
};
doPublishEvent(new BindingCreatedEvent(binding));
return binding;
}
```
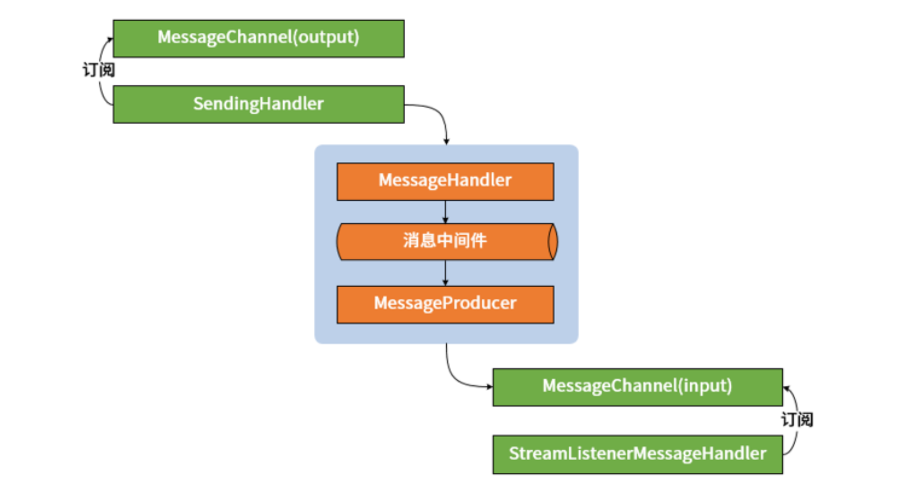
上述代码的核心逻辑在于,Source 里的 output 发送消息到 outputChannel 通道之后会被 SendingHandler 这个 MessageHandler 进行处理。从设计模式上讲,SendingHandler 是一个静态代理类,因此它又将这个处理过程委托给了由 createProducerMessageHandler 方法所创建的 producerMessageHandler,这点从 SendingHandler 的定义中可以得到验证,如下所示的 delegate 就是传入的 producerMessageHandler:
```
private final class SendingHandler extends AbstractMessageHandler implements Lifecycle {
private final MessageHandler delegate;
@Override
protected void handleMessageInternal(Message<?> message) throws Exception {
Message<?> messageToSend = (this.useNativeEncoding) ? message
: serializeAndEmbedHeadersIfApplicable(message);
this.delegate.handleMessage(messageToSend);
}
// 省略其他方法
}
```
请注意,同样作为一个模板方法类,AbstractMessageChannelBinder 具有三个抽象方法,即 createProducerMessageHandler、postProcessOutputChannel 和 afterUnbindProducer,这三个方法都需要由它的子类进行实现。也就是说,SendingHandler 所使用的 producerMessageHandler 需要由 AbstractMessageChannelBinder 子类负责进行创建。
需要注意的是,作为统一的数据模型,SendingHandler 以及 producerMessageHandler 中使用的都是 Spring Messaging 组件中的 Message 消息对象,而 createProducerMessageHandler 内部会把这个 Message 消息对象转换成对应中间件的消息数据格式并进行发送。
下面转到消息消费的场景,我们来看 AbstractMessageChannelBinder 的 doBindConsumer 方法。该方法的核心语句是创建一个消费者端点 ConsumerEndpoint,如下所示:
MessageProducer consumerEndpoint = createConsumerEndpoint(destination, group, properties);
consumerEndpoint.setOutputChannel(inputChannel);
这两行代码有两个注意点。首先,createConsumerEndpoint 是一个抽象方法,需要 AbstractMessageChannelBinder 的子类进行实现。与 createProducerMessageHandler 一样,createConsumerEndpoint 需要把中间件对应的消息数据结构转换成 Spring Messaging 中统一的 Message 消息对象。
然后,我们注意到这里的 consumerEndpoint 类型是 MessageProducer。MessageProducer 在 Spring Integration 中代表的是消息的生产者,它会把从第三方消息中间件中收到的消息转发到 inputChannel 所指定的通道中。基于 @StreamListener 注解,在 Spring Cloud Stream 中存在一个 StreamListenerMessageHandler 类,用于订阅 inputChannel 消息通道中传入的消息并进行消费。
作为总结,我们可以用如下所示的流程图来概括整个消息发送和消费流程:
## 同一通道根据消息内容分发不同的消费逻辑应用场景
有的时候,我们对于同一通道中的消息处理,会通过判断头信息或者消息内容来做一些差异化处理,比如:可能在消息头信息中带入消息版本号,然后通过if判断来执行不同的处理逻辑,其代码结构可能是这样的:
[https://blog.didispace.com/spring-cloud-starter-finchley-7-6/]()
- 前言
- 1.项目说明
- 2.项目更新日志
- 3.文档更新日志
- 01.快速开始
- 01.maven构建项目
- 02.环境安装
- 03.STS项目导入
- 03.IDEA项目导入
- 04.数据初始化
- 05.项目启动
- 06.付费文档说明
- 02.总体流程
- 1.oauth接口
- 2.架构设计图
- 3.微服务介绍
- 4.功能介绍
- 5.梳理流程
- 03.模块详解
- 01.老版本1.0.1分支模块讲解
- 01.db-core模块
- 02.api-commons模块
- 03.log-core模块
- 04.security-core模块
- 05.swagger-core模块
- 06.eureka-server模块
- 07.auth-server模块
- 08.auth-sso模块解析
- 09.user-center模块
- 10.api-gateway模块
- 11.file-center模块
- 12.log-center模块
- 13.batch-center模块
- 14.back-center模块
- 02.spring-boot-starter-web那点事
- 03.自定义db-spring-boot-starter
- 04.自定义log-spring-boot-starter
- 05.自定义redis-spring-boot-starter
- 06.自定义common-spring-boot-starter
- 07.自定义swagger-spring-boot-starter
- 08.自定义uaa-server-spring-boot-starter
- 09.自定义uaa-client-spring-boot-starter
- 10.自定义ribbon-spring-boot-starter
- 11.springboot启动原理
- 12.eureka-server模块
- 13.auth-server模块
- 14.user-center模块
- 15.api-gateway模块
- 16.file-center模块
- 17.log-center模块
- 18.back-center模块
- 19.auth-sso模块
- 20.admin-server模块
- 21.zipkin-center模块
- 22.job-center模块
- 23.batch-center
- 04.全新网关
- 01.基于spring cloud gateway的new-api-gateway
- 02.spring cloud gateway整合Spring Security Oauth
- 03.基于spring cloud gateway的redis动态路由
- 04.spring cloud gateway聚合swagger文档
- 05.技术详解
- 01.互联网系统设计原则
- 02.系统幂等性设计与实践
- 03.Oauth最简向导开发指南
- 04.oauth jdbc持久化策略
- 05.JWT token方式启用
- 06.token有效期的处理
- 07.@PreAuthorize注解分析
- 08.获取当前用户信息
- 09.认证授权白名单配置
- 10.OCP权限设计
- 11.服务安全流程
- 12.认证授权详解
- 13.验证码技术
- 14.短信验证码登录
- 15.动态数据源配置
- 16.分页插件使用
- 17.缓存击穿
- 18.分布式主键生成策略
- 19.分布式定时任务
- 20.分布式锁
- 21.网关多维度限流
- 22.跨域处理
- 23.容错限流
- 24.应用访问次数控制
- 25.统一业务异常处理
- 26.日志埋点
- 27.GPRC内部通信
- 28.服务间调用
- 29.ribbon负载均衡
- 30.微服务分布式跟踪
- 31.异步与线程传递变量
- 32.死信队列延时消息
- 33.单元测试用例
- 34.Greenwich.RELEASE升级
- 35.混沌工程质量保证
- 06.开发初探
- 1.开发技巧
- 2.crud例子
- 3.新建服务
- 4.区分前后台用户
- 07.分表分库
- 08.分布式事务
- 1.Seata介绍
- 2.Seata部署
- 09.shell部署
- 01.eureka-server
- 02.user-center
- 03.auth-server
- 04.api-gateway
- 05.file-center
- 06.log-center
- 07.back-center
- 08.编写shell脚本
- 09.集群shell部署
- 10.集群shell启动
- 11.部署阿里云问题
- 10.网关安全
- 1.openresty https保障服务安全
- 2.openresty WAF应用防火墙
- 3.openresty 高可用
- 11.docker配置
- 01.docker安装
- 02.Docker 开启远程API
- 03.采用docker方式打包到服务器
- 04.docker创建mysql
- 05.docker网络原理
- 06.docker实战
- 6.01.安装docker
- 6.02.管理镜像基本命令
- 6.03.容器管理
- 6.04容器数据持久化
- 6.05网络模式
- 6.06.Dockerfile
- 6.07.harbor部署
- 6.08.使用自定义镜像
- 12.统一监控中心
- 01.spring boot admin监控
- 02.Arthas诊断利器
- 03.nginx监控(filebeat+es+grafana)
- 04.Prometheus监控
- 05.redis监控(redis+prometheus+grafana)
- 06.mysql监控(mysqld_exporter+prometheus+grafana)
- 07.elasticsearch监控(elasticsearch-exporter+prometheus+grafana)
- 08.linux监控(node_exporter+prometheus+grafana)
- 09.micoservice监控
- 10.nacos监控
- 11.druid数据源监控
- 12.prometheus.yml
- 13.grafana告警
- 14.Alertmanager告警
- 15.监控微信告警
- 16.关于接口监控告警
- 17.prometheus-HA架构
- 18.总结
- 13.统一日志中心
- 01.统一日志中心建设意义
- 02.通过ELK收集mysql慢查询日志
- 03.通过elk收集微服务模块日志
- 04.通过elk收集nginx日志
- 05.统一日志中心性能优化
- 06.kibana安装部署
- 07.日志清理方案
- 08.日志性能测试指标
- 09.总结
- 14.数据查询平台
- 01.数据查询平台架构
- 02.mysql配置bin-log
- 03.单节点canal-server
- 04.canal-ha部署
- 05.canal-kafka部署
- 06.实时增量数据同步mysql
- 07.canal监控
- 08.clickhouse运维常见脚本
- 15.APM监控
- 1.Elastic APM
- 2.Skywalking
- 01.docker部署es
- 02.部署skywalking-server
- 03.部署skywalking-agent
- 16.压力测试
- 1.ocp.jmx
- 2.test.bat
- 3.压测脚本
- 4.压力报告
- 5.报告分析
- 6.压测平台
- 7.并发测试
- 8.wrk工具
- 9.nmon
- 10.jmh测试
- 17.SQL优化
- 1.oracle篇
- 01.基线测试
- 02.调优前奏
- 03.线上瓶颈定位
- 04.执行计划解读
- 05.高级SQL语句
- 06.SQL tuning
- 07.数据恢复
- 08.深入10053事件
- 09.深入10046事件
- 2.mysql篇
- 01.innodb存储引擎
- 02.BTree索引
- 03.执行计划
- 04.查询优化案例分析
- 05.为什么会走错索引
- 06.表连接优化问题
- 07.Connection连接参数
- 08.Centos7系统参数调优
- 09.mysql监控
- 10.高级SQL语句
- 11.常用维护脚本
- 12.percona-toolkit
- 18.redis高可用方案
- 1.免密登录
- 2.安装部署
- 3.配置文件
- 4.启动脚本
- 19.消息中间件搭建
- 19-01.rabbitmq集群搭建
- 01.rabbitmq01
- 02.rabbitmq02
- 03.rabbitmq03
- 04.镜像队列
- 05.haproxy搭建
- 06.keepalived
- 19-02.rocketmq搭建
- 19-03.kafka集群
- 20.mysql高可用方案
- 1.环境
- 2.mysql部署
- 3.Xtrabackup部署
- 4.Galera部署
- 5.galera for mysql 集群
- 6.haproxy+keepalived部署
- 21.es集群部署
- 22.生产实施优化
- 1.linux优化
- 2.jvm优化
- 3.feign优化
- 4.zuul性能优化
- 23.线上问题诊断
- 01.CPU性能评估工具
- 02.内存性能评估工具
- 03.IO性能评估工具
- 04.网络问题工具
- 05.综合诊断评估工具
- 06.案例诊断01
- 07.案例诊断02
- 08.案例诊断03
- 09.案例诊断04
- 10.远程debug
- 24.fiddler抓包实战
- 01.fiddler介绍
- 02.web端抓包
- 03.app抓包
- 25.疑难解答交流
- 01.有了auth/token获取token了为啥还要配置security的登录配置
- 02.权限数据存放在redis吗,代码在哪里啊
- 03.其他微服务和认证中心的关系
- 04.改包问题
- 05.use RequestContextListener or RequestContextFilter to expose the current request
- 06./oauth/token对应代码在哪里
- 07.验证码出不来
- 08./user/login
- 09.oauth无法自定义权限表达式
- 10.sleuth引发线程数过高问题
- 11.elk中使用7x版本问题
- 12.RedisCommandTimeoutException问题
- 13./oauth/token CPU过高
- 14.feign与权限标识符问题
- 15.动态路由RedisCommandInterruptedException: Command interrupted
- 26.学习资料
- 海量学习资料等你来拿
- 27.持续集成
- 01.git安装
- 02.代码仓库gitlab
- 03.代码仓库gogs
- 04.jdk&&maven
- 05.nexus安装
- 06.sonarqube
- 07.jenkins
- 28.Rancher部署
- 1.rancher-agent部署
- 2.rancher-server部署
- 3.ocp后端部署
- 4.演示前端部署
- 5.elk部署
- 6.docker私服搭建
- 7.rancher-server私服
- 8.rancher-agent docker私服
- 29.K8S部署OCP
- 01.准备OCP的构建环境和部署环境
- 02.部署顺序
- 03.在K8S上部署eureka-server
- 04.在K8S上部署mysql
- 05.在K8S上部署redis
- 06.在K8S上部署auth-server
- 07.在K8S上部署user-center
- 08.在K8S上部署api-gateway
- 09.在K8S上部署back-center
- 30.Spring Cloud Alibaba
- 01.统一的依赖管理
- 02.nacos-server
- 03.生产可用的Nacos集群
- 04.nacos配置中心
- 05.common.yaml
- 06.user-center
- 07.auth-server
- 08.api-gateway
- 09.log-center
- 10.file-center
- 11.back-center
- 12.sentinel-dashboard
- 12.01.sentinel流控规则
- 12.02.sentinel熔断降级规则
- 12.03.sentinel热点规则
- 12.04.sentinel系统规则
- 12.05.sentinel规则持久化
- 12.06.sentinel总结
- 13.sentinel整合openfeign
- 14.sentinel整合网关
- 1.sentinel整合zuul
- 2.sentinel整合scg
- 15.Dubbo与Nacos共存
- 31.Java源码剖析
- 01.基础数据类型和String
- 02.Arrays工具类
- 03.ArrayList源码分析
- 32.面试专题汇总
- 01.JVM专题汇总
- 02.多线程专题汇总
- 03.Spring专题汇总
- 04.springboot专题汇总
- 05.springcloud面试汇总
- 文档问题跟踪处理