
# 细分:使用 Docker,ECS 和 Terraform 重建基础架构
> 原文: [http://highscalability.com/blog/2015/10/19/segment-rebuilding-our-infrastructure-with-docker-ecs-and-te.html](http://highscalability.com/blog/2015/10/19/segment-rebuilding-our-infrastructure-with-docker-ecs-and-te.html)
*这是[段](https://www.linkedin.com/in/calvinfo)的 CTO /联合创始人 [Calvin French-Owen](https://www.linkedin.com/in/calvinfo) 的来宾[重新发布](https://segment.com/blog/rebuilding-our-infrastructure/)。*
在 Segment 成立之初,我们的基础设施遭到了相当大的破坏。 我们通过 AWS UI 设置了实例,拥有未使用的 AMI 的墓地,并且通过三种不同的方式实现了配置。
随着业务开始腾飞,我们扩大了 eng 团队的规模和体系结构的复杂性。 但是,只有少数知道神秘奥秘的人才能从事生产工作。 我们一直在逐步改进流程,但是我们需要对基础架构进行更深入的检查,以保持快速发展。
所以几个月前,我们坐下来问自己:*“如果今天设计基础架构设置会是什么样?”*
在 10 周的过程中,我们完全重新设计了基础架构。 我们几乎淘汰了每个实例和旧配置,将服务移至可在 Docker 容器中运行,并切换到使用新的 AWS 账户。
我们花了很多时间思考如何制作可审核,简单易用的生产设置,同时仍具有扩展和增长的灵活性。
这是我们的解决方案。
## 单独的 AWS 账户
我们没有使用区域或标签来分隔不同的暂存和生产实例,而是切换了完全独立的 AWS 帐户。 我们需要确保我们的配置脚本不会影响我们当前正在运行的服务,并且使用新帐户意味着我们一开始就有空白。
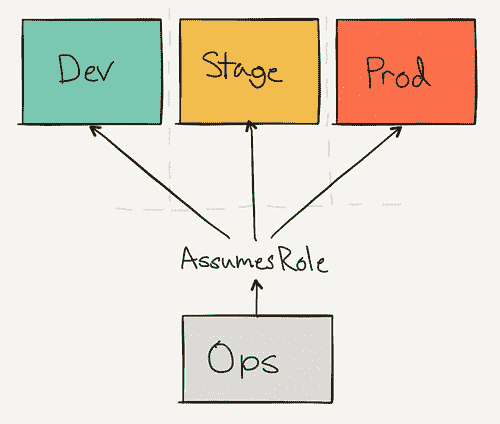
`ops`帐户用作跳转点和集中登录。 组织中的每个人都可以拥有一个 IAM 帐户。
其他环境具有一组 IAM 角色,可以在它们之间进行切换。 这意味着我们的管理员帐户只有一个登录点,并且只有一个位置可以限制访问。
例如,爱丽丝可能可以访问所有三个环境,但是鲍勃只能访问开发人员(因为他删除了生产负载平衡器)。 但是它们都通过`ops`帐户输入。
无需复杂的 IAM 设置来限制访问,我们可以轻松地按环境锁定用户并按*角色将其分组。* 通过界面使用每个帐户就像切换当前活动角色一样简单。
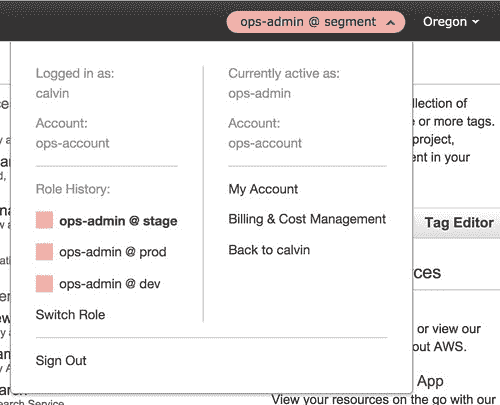
不必担心暂存盒可能不安全或会更改生产数据库,我们免费获得*真正隔离*。 无需额外配置。
能够共享配置代码的另一个好处是,我们的登台环境实际上可以反映产品。 配置上的唯一区别是实例的大小和容器的数量。
最后,我们还启用了各个帐户的合并结算。 我们使用相同的发票支付每月帐单,并查看按环境划分的费用的详细分类。
## Docker 和 ECS
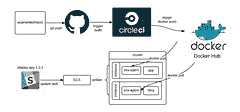
设置好帐户后,就可以设计服务的实际运行方式了。 为此,我们转向了 [Docker](https://docker.com/) 和 [EC2 容器服务(ECS)](https://aws.amazon.com/ecs/)。
截至今天,我们现在在 Docker 容器中运行我们的大多数服务,包括我们的 API 和数据管道。 容器每秒接收数千个请求,每月处理 500 亿个事件。
Docker 最大的单一好处是在一定程度上使团队能够从头开始构建服务。 我们不再需要复杂的配置脚本或 AMI,只需将生产集群交给一个映像即可运行。 不再有状态的实例,我们保证在 staging 和 prod 上运行相同的代码。
在将我们的服务配置为在容器中运行之后,我们选择了 ECS 作为调度程序。
总体而言,ECS 负责在生产中实际运行我们的容器。 它负责调度服务,将它们放置在单独的主机上,并在连接到 ELB 时重新加载零停机时间。 它甚至可以跨可用区进行调度,以提高可用性。 如果某个容器死亡,ECS 将确保将其重新安排在该群集中的新实例上。
切换到 ECS 大大简化了服务的运行,而无需担心新贵作业或预配实例。 就像添加一个 [Dockerfile](https://gist.github.com/calvinfo/c9ffb5c28133be525c62) ,设置任务定义并将其与集群关联一样简单。
在我们的设置中,Docker 映像是由 CI 构建的,然后被推送到 Docker Hub。 服务启动时,它将从 Docker Hub 中拉出映像,然后 ECS 在机器之间调度它。

我们会根据服务集群的关注程度和负载情况对其进行分组(例如,针对 API,CDN,App 等的不同集群)。 具有单独的群集意味着我们可以获得更好的可见性,并且可以决定为每个实例使用不同的实例类型(因为 ECS 没有实例相似性的概念)。
每个服务都有一个特定的任务定义,该任务定义指示要运行哪个版本的容器,要运行多少个实例以及要选择哪个集群。
在运行期间,服务向 ELB 进行自身注册,并使用运行状况检查来确认容器实际上已准备就绪。 我们在 ELB 上指向本地 Route53 条目,以便服务可以相互通信,并仅通过 DNS 进行引用。
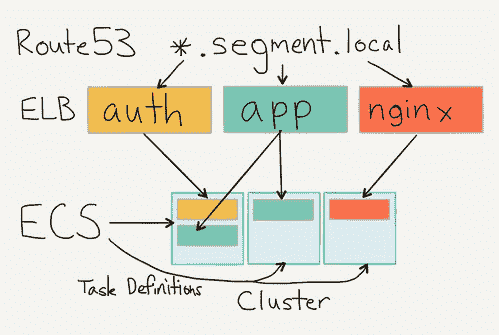
设置很好,因为我们不需要任何服务发现。 本地 DNS 为我们完成所有簿记工作。
ECS 运行所有服务,我们从 ELB 获得免费的 cloudwatch 指标。 这比在启动时向中央机构注册服务要简单得多。 最好的部分是我们不必自己处理国家冲突。
## 使用 Terraform 进行模板化
Docker 和 ECS 描述了如何运行我们的每个服务的地方, [Terraform](https://terraform.io/) 是将它们结合在一起的粘合剂。 从高层次上讲,它是一组配置脚本,用于创建和更新我们的基础架构。 您可以将其视为类固醇上的 Cloudformation 版本,但这并不能使您感到惊讶。
除了运行一组用于维护状态的服务器外,还有一组描述集群的脚本。 配置在本地运行(并在将来通过 CI 运行)并致力于 git,因此我们可以连续记录生产基础架构的实际状况。
这是用于设置堡垒节点的 Terraform 模块的示例。 它创建了所有安全组,实例和 AMI,因此我们能够轻松地为将来的环境设置新的跳转点。
```
// Use the Ubuntu AMI
module "ami" {
source = "github.com/terraform-community-modules/tf_aws_ubuntu_ami/ebs"
region = "us-west-2"
distribution = "trusty"
instance_type = "${var.instance_type}"
}
// Set up a security group to the bastion
resource "aws_security_group" "bastion" {
name = "bastion"
description = "Allows ssh from the world"
vpc_id = "${var.vpc_id}"
ingress {
from_port = 22
to_port = 22
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
}
egress {
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = ["0.0.0.0/0"]
}
tags {
Name = "bastion"
}
}
// Add our instance description
resource "aws_instance" "bastion" {
ami = "${module.ami.ami_id}"
source_dest_check = false
instance_type = "${var.instance_type}"
subnet_id = "${var.subnet_id}"
key_name = "${var.key_name}"
security_groups = ["${aws_security_group.bastion.id}"]
tags {
Name = "bastion-01"
Environment = "${var.environment}"
}
}
// Setup our elastic ip
resource "aws_eip" "bastion" {
instance = "${aws_instance.bastion.id}"
vpc = true
}
```
我们在阶段和产品中使用相同的模块来设置我们的个人堡垒。 我们唯一需要切换的是 IAM 密钥,我们已经准备就绪。
进行更改也很轻松。 Terraform 不会总是拆除整个基础架构,而会在可能的地方进行更新。
当我们想将 ELB 耗尽超时更改为 60 秒时,只需执行简单的查找/替换操作即可,然后是`terraform apply`。 而且,两分钟后,我们对所有 ELB 进行了完全更改的生产设置。
它具有可复制性,可审核性和自我记录性。 这里没有黑匣子。
我们将所有配置都放在了`infrastructure`中央存储库中,因此很容易发现如何设置给定的服务。
不过,我们还没有达到圣杯。 我们希望转换更多的 Terraform 配置以利用模块,以便可以合并单个文件并减少共享样板的数量。
一路上,我们在`.tfstate`周围发现了一些陷阱,因为 Terraform 始终首先从现有基础架构中读取数据,并抱怨状态是否不同步。 我们最终只是将我们的`.tfstate`提交给了仓库,并在进行了任何更改之后将其推送了,但是我们正在研究 [Atlas](https://atlas.hashicorp.com/) 或通过 CI 来解决该问题。
## 移至 Datadog
至此,我们有了基础架构,配置和隔离。 最后剩下的是度量和监视,以跟踪生产中正在运行的所有内容。
在我们的新环境中,我们已将所有指标和监视切换到 [Datadog](https://datadog.com/) ,这是出色的。

我们一直对 Datadog 的 UI,API 以及与 AWS 的完全集成感到非常满意,但是要充分利用该工具,需要进行一些关键的设置。
我们要做的第一件事是与 AWS 和 Cloudtrail 集成。 它提供了 10,000 英尺的视图,可了解我们在每个环境中发生的情况。 由于我们正在与 ECS 集成,因此 Datadog feed 会在每次任务定义更新时进行更新,因此最终会免费获得部署通知。 惊人地搜索提要很容易,并且可以轻松地追溯到上一次部署或重新安排服务的时间。
接下来,我们确保将 Datadog-agent 作为容器添加到基本 AMI( [datadog / docker-dd-agent](https://hub.docker.com/r/datadog/docker-dd-agent/) )。 它不仅从主机(CPU,内存等)收集指标,而且还充当我们 statsd 指标的接收器。 我们的每项服务都会收集有关查询,延迟和错误的自定义指标,以便我们可以在 Datadog 中进行浏览并发出警报。 我们的 go 工具包(即将开源)将自动在代码行中收集 [`pprof`](https://golang.org/pkg/net/http/pprof/) 的输出并将其发送,因此我们可以监视内存和 goroutine。
更酷的是,代理可以可视化环境中主机之间的实例利用率,因此我们可以对可能存在问题的实例或群集进行高层概述:
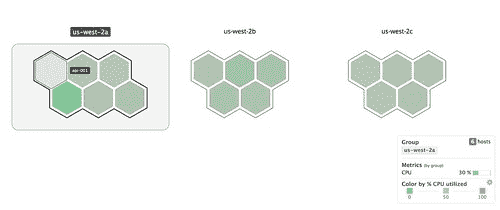
此外,我的队友文斯(Vince)为 Datadog 创建了 [Terraform 提供程序,因此我们可以完全针对*实际生产配置*编写警报脚本。 我们的警报将被记录,并与产品中正在运行的警报保持同步。](https://github.com/segmentio/terraform-datadog)
```
resource "datadog_monitor_metric" "app.internal_errors" {
name = "App Internal Errors"
message = "App Internal Error Alerts"
metric = "app.5xx"
time_aggr = "avg"
time_window = "last_5m"
space_aggr = "avg"
operator = ">"
warning {
threshold = 10
notify = "@slack-team-infra"
}
critical {
threshold = 50
notify = "@slack-team-infra @pagerduty"
}
}
```
按照惯例,我们指定两个警报级别:`warning`和`critical`。 `warning`可以让当前在线的任何人知道某些东西看起来可疑,应在任何潜在问题发生之前就将其触发。 `critical`警报是为严重的系统故障而“半夜醒来”的问题保留的。
更重要的是,一旦我们过渡到 Terraform 模块并将 Datadog 提供程序添加到我们的服务描述中,那么所有服务最终都会获得*免费*的警报。 数据将直接由我们的内部工具包和 Cloudwatch 指标提供动力。
## 让好时光泊坞窗运行
一旦我们将所有这些组件准备就绪,就可以开始进行转换了。
我们首先在新的生产环境和旧的生产环境之间建立了 [VPC 对等连接](http://docs.aws.amazon.com/AmazonVPC/latest/UserGuide/vpc-peering.html)-允许我们对数据库进行集群并在两者之间进行复制。
接下来,我们对新环境中的 ELB 进行了预热,以确保它们可以处理负载。 亚马逊不会提供自动调整大小的 ELB,因此我们不得不要求他们提前对其进行调整(或缓慢调整规模)以应对增加的负载。
从那里开始,只需要使用加权的 Route53 路由将流量从旧环境稳定地增加到我们的新环境,并不断监视一切都看起来不错。
如今,我们的 API 蓬勃发展,每秒处理数千个请求,并且完全在 Docker 容器内运行。
但是我们还没有完成。 我们仍在微调我们的服务创建,并减少样板,以便团队中的任何人都可以通过适当的监视和警报轻松构建服务。 而且,由于服务不再与实例相关联,因此我们希望围绕容器的使用改进工具。
我们还计划关注这一领域的有前途的技术。 [Convox](https://convox.com/) 团队正在围绕 AWS 基础架构构建出色的工具。 [Kubernetes](http://kubernetes.io/) ,[中层](https://mesosphere.com/), [Nomad](https://nomadproject.io/) 和 [Fleet](https://github.com/coreos/fleet) 看起来像是不可思议的调度程序,尽管我们喜欢 ECS 的简单性和集成性。 看到它们如何被淘汰将是令人兴奋的,我们将继续关注它们以了解我们可以采用什么。
在所有这些业务流程变更之后,我们比以往任何时候都更加坚信将基础架构外包给 AWS。 他们通过将许多核心服务产品化而改变了游戏规则,同时保持了极具竞争力的价格。 它正在创建一种新型的初创公司,可以高效而廉价地生产产品,同时减少维护时间。 而且我们看好将在其生态系统之上构建的工具。
Datadog 链接已断开,它显示 SSL 错误。 正确的网址是 https://www.datadoghq.com/
我们是一家初创公司,我们正在尝试从头开始设置 evyrthing。 感谢您的帖子。
- LiveJournal 体系结构
- mixi.jp 体系结构
- 友谊建筑
- FeedBurner 体系结构
- GoogleTalk 架构
- ThemBid 架构
- 使用 Amazon 服务以 100 美元的价格构建无限可扩展的基础架构
- TypePad 建筑
- 维基媒体架构
- Joost 网络架构
- 亚马逊建筑
- Fotolog 扩展成功的秘诀
- 普恩斯的教训-早期
- 论文:Wikipedia 的站点内部,配置,代码示例和管理问题
- 扩大早期创业规模
- Feedblendr 架构-使用 EC2 进行扩展
- Slashdot Architecture-互联网的老人如何学会扩展
- Flickr 架构
- Tailrank 架构-了解如何在整个徽标范围内跟踪模因
- Ruby on Rails 如何在 550k 网页浏览中幸存
- Mailinator 架构
- Rackspace 现在如何使用 MapReduce 和 Hadoop 查询 TB 的数据
- Yandex 架构
- YouTube 架构
- Skype 计划 PostgreSQL 扩展到 10 亿用户
- 易趣建筑
- FaceStat 的祸根与智慧赢得了胜利
- Flickr 的联合会:每天进行数十亿次查询
- EVE 在线架构
- Notify.me 体系结构-同步性
- Google 架构
- 第二人生架构-网格
- MySpace 体系结构
- 扩展 Digg 和其他 Web 应用程序
- Digg 建筑
- 在 Amazon EC2 中部署大规模基础架构的六个经验教训
- Wolfram | Alpha 建筑
- 为什么 Facebook,Digg 和 Twitter 很难扩展?
- 全球范围扩展的 10 个 eBay 秘密
- BuddyPoke 如何使用 Google App Engine 在 Facebook 上扩展
- 《 FarmVille》如何扩展以每月收获 7500 万玩家
- Twitter 计划分析 1000 亿条推文
- MySpace 如何与 100 万个并发用户一起测试其实时站点
- FarmVille 如何扩展-后续
- Justin.tv 的实时视频广播架构
- 策略:缓存 404 在服务器时间上节省了洋葱 66%
- Poppen.de 建筑
- MocoSpace Architecture-一个月有 30 亿个移动页面浏览量
- Sify.com 体系结构-每秒 3900 个请求的门户
- 每月将 Reddit 打造为 2.7 亿页面浏览量时汲取的 7 个教训
- Playfish 的社交游戏架构-每月有 5000 万用户并且不断增长
- 扩展 BBC iPlayer 的 6 种策略
- Facebook 的新实时消息系统:HBase 每月可存储 135 亿条消息
- Pinboard.in Architecture-付费玩以保持系统小巧
- BankSimple 迷你架构-使用下一代工具链
- Riak 的 Bitcask-用于快速键/值数据的日志结构哈希表
- Mollom 体系结构-每秒以 100 个请求杀死超过 3.73 亿个垃圾邮件
- Wordnik-MongoDB 和 Scala 上每天有 1000 万个 API 请求
- Node.js 成为堆栈的一部分了吗? SimpleGeo 说是的。
- 堆栈溢出体系结构更新-现在每月有 9500 万页面浏览量
- Medialets 体系结构-击败艰巨的移动设备数据
- Facebook 的新实时分析系统:HBase 每天处理 200 亿个事件
- Microsoft Stack 是否杀死了 MySpace?
- Viddler Architecture-每天嵌入 700 万个和 1500 Req / Sec 高峰
- Facebook:用于扩展数十亿条消息的示例规范架构
- Evernote Architecture-每天有 900 万用户和 1.5 亿个请求
- TripAdvisor 的短
- TripAdvisor 架构-4,000 万访客,200M 动态页面浏览,30TB 数据
- ATMCash 利用虚拟化实现安全性-不变性和还原
- Google+是使用您也可以使用的工具构建的:闭包,Java Servlet,JavaScript,BigTable,Colossus,快速周转
- 新的文物建筑-每天收集 20 亿多个指标
- Peecho Architecture-鞋带上的可扩展性
- 标记式架构-扩展到 1 亿用户,1000 台服务器和 50 亿个页面视图
- 论文:Akamai 网络-70 个国家/地区的 61,000 台服务器,1,000 个网络
- 策略:在 S3 或 GitHub 上运行可扩展,可用且廉价的静态站点
- Pud 是反堆栈-Windows,CFML,Dropbox,Xeround,JungleDisk,ELB
- 用于扩展 Turntable.fm 和 Labmeeting 的数百万用户的 17 种技术
- StackExchange 体系结构更新-平稳运行,Amazon 4x 更昂贵
- DataSift 体系结构:每秒进行 120,000 条推文的实时数据挖掘
- Instagram 架构:1400 万用户,1 TB 的照片,数百个实例,数十种技术
- PlentyOfFish 更新-每月 60 亿次浏览量和 320 亿张图片
- Etsy Saga:从筒仓到开心到一个月的浏览量达到数十亿
- 数据范围项目-6PB 存储,500GBytes / sec 顺序 IO,20M IOPS,130TFlops
- 99designs 的设计-数以千万计的综合浏览量
- Tumblr Architecture-150 亿页面浏览量一个月,比 Twitter 更难扩展
- Berkeley DB 体系结构-NoSQL 很酷之前的 NoSQL
- Pixable Architecture-每天对 2000 万张照片进行爬网,分析和排名
- LinkedIn:使用 Databus 创建低延迟更改数据捕获系统
- 在 30 分钟内进行 7 年的 YouTube 可扩展性课程
- YouPorn-每天定位 2 亿次观看
- Instagram 架构更新:Instagram 有何新功能?
- 搜索技术剖析:blekko 的 NoSQL 数据库
- Pinterest 体系结构更新-1800 万访问者,增长 10 倍,拥有 12 名员工,410 TB 数据
- 搜索技术剖析:使用组合器爬行
- iDoneThis-从头开始扩展基于电子邮件的应用程序
- StubHub 体系结构:全球最大的票务市场背后的惊人复杂性
- FictionPress:在网络上发布 600 万本小说
- Cinchcast 体系结构-每天产生 1,500 小时的音频
- 棱柱架构-使用社交网络上的机器学习来弄清您应该在网络上阅读的内容
- 棱镜更新:基于文档和用户的机器学习
- Zoosk-实时通信背后的工程
- WordPress.com 使用 NGINX 服务 70,000 req / sec 和超过 15 Gbit / sec 的流量
- 史诗般的 TripAdvisor 更新:为什么不在云上运行? 盛大的实验
- UltraDNS 如何处理数十万个区域和数千万条记录
- 更简单,更便宜,更快:Playtomic 从.NET 迁移到 Node 和 Heroku
- Spanner-关于程序员使用 NoSQL 规模的 SQL 语义构建应用程序
- BigData 使用 Erlang,C 和 Lisp 对抗移动数据海啸
- 分析数十亿笔信用卡交易并在云中提供低延迟的见解
- MongoDB 和 GridFS 用于内部和内部数据中心数据复制
- 每天处理 1 亿个像素-少量竞争会导致大规模问题
- DuckDuckGo 体系结构-每天进行 100 万次深度搜索并不断增长
- SongPop 在 GAE 上可扩展至 100 万活跃用户,表明 PaaS 未通过
- Iron.io 从 Ruby 迁移到 Go:减少了 28 台服务器并避免了巨大的 Clusterf ** ks
- 可汗学院支票簿每月在 GAE 上扩展至 600 万用户
- 在破坏之前先检查自己-鳄梨的建筑演进的 5 个早期阶段
- 缩放 Pinterest-两年内每月从 0 到十亿的页面浏览量
- Facebook 的网络秘密
- 神话:埃里克·布鲁尔(Eric Brewer)谈银行为什么不是碱-可用性就是收入
- 一千万个并发连接的秘密-内核是问题,而不是解决方案
- GOV.UK-不是你父亲的书库
- 缩放邮箱-在 6 周内从 0 到 100 万用户,每天 1 亿条消息
- 在 Yelp 上利用云计算-每月访问量为 1.02 亿,评论量为 3900 万
- 每台服务器将 PHP 扩展到 30,000 个并发用户的 5 条 Rockin'Tips
- Twitter 的架构用于在 5 秒内处理 1.5 亿活跃用户,300K QPS,22 MB / S Firehose 以及发送推文
- Salesforce Architecture-他们每天如何处理 13 亿笔交易
- 扩大流量的设计决策
- ESPN 的架构规模-每秒以 100,000 Duh Nuh Nuhs 运行
- 如何制作无限可扩展的关系数据库管理系统(RDBMS)
- Bazaarvoice 的架构每月发展到 500M 唯一用户
- HipChat 如何使用 ElasticSearch 和 Redis 存储和索引数十亿条消息
- NYTimes 架构:无头,无主控,无单点故障
- 接下来的大型声音如何使用 Hadoop 数据版本控制系统跟踪万亿首歌曲的播放,喜欢和更多内容
- Google 如何备份 Internet 和数十亿字节的其他数据
- 从 HackerEarth 用 Apache 扩展 Python 和 Django 的 13 个简单技巧
- AOL.com 体系结构如何发展到 99.999%的可用性,每天 800 万的访问者和每秒 200,000 个请求
- Facebook 以 190 亿美元的价格收购了 WhatsApp 体系结构
- 使用 AWS,Scala,Akka,Play,MongoDB 和 Elasticsearch 构建社交音乐服务
- 大,小,热还是冷-条带,Tapad,Etsy 和 Square 的健壮数据管道示例
- WhatsApp 如何每秒吸引近 5 亿用户,11,000 内核和 7,000 万条消息
- Disqus 如何以每秒 165K 的消息和小于 0.2 秒的延迟进行实时处理
- 关于 Disqus 的更新:它仍然是实时的,但是 Go 摧毁了 Python
- 关于 Wayback 机器如何在银河系中存储比明星更多的页面的简短说明
- 在 PagerDuty 迁移到 EC2 中的 XtraDB 群集
- 扩展世界杯-Gambify 如何与 2 人组成的团队一起运行大型移动投注应用程序
- 一点点:建立一个可处理每月 60 亿次点击的分布式系统的经验教训
- StackOverflow 更新:一个月有 5.6 亿次网页浏览,25 台服务器,而这一切都与性能有关
- Tumblr:哈希处理每秒 23,000 个博客请求的方式
- 使用 HAProxy,PHP,Redis 和 MySQL 处理 10 亿个请求的简便方法来构建成长型启动架构
- MixRadio 体系结构-兼顾各种服务
- Twitter 如何使用 Redis 进行扩展-105TB RAM,39MM QPS,10,000 多个实例
- 正确处理事情:通过即时重放查看集中式系统与分散式系统
- Instagram 提高了其应用程序的性能。 这是如何做。
- Clay.io 如何使用 AWS,Docker,HAProxy 和 Lots 建立其 10 倍架构
- 英雄联盟如何将聊天扩大到 7000 万玩家-需要很多小兵。
- Wix 的 Nifty Architecture 技巧-大规模构建发布平台
- Aeron:我们真的需要另一个消息传递系统吗?
- 机器:惠普基于忆阻器的新型数据中心规模计算机-一切仍在变化
- AWS 的惊人规模及其对云的未来意味着什么
- Vinted 体系结构:每天部署数百次,以保持繁忙的门户稳定
- 将 Kim Kardashian 扩展到 1 亿个页面
- HappyPancake:建立简单可扩展基金会的回顾
- 阿尔及利亚分布式搜索网络的体系结构
- AppLovin:通过每天处理 300 亿个请求向全球移动消费者进行营销
- Swiftype 如何以及为何从 EC2 迁移到真实硬件
- 我们如何扩展 VividCortex 的后端系统
- Appknox 架构-从 AWS 切换到 Google Cloud
- 阿尔及利亚通往全球 API 的愤怒之路
- 阿尔及利亚通往全球 API 步骤的愤怒之路第 2 部分
- 为社交产品设计后端
- 阿尔及利亚通往全球 API 第 3 部分的愤怒之路
- Google 如何创造只有他们才能创造的惊人的数据中心网络
- Autodesk 如何在 Mesos 上实施可扩展事件
- 构建全球分布式,关键任务应用程序:Trenches 部分的经验教训 1
- 构建全球分布式,关键任务应用程序:Trenches 第 2 部分的经验教训
- 需要物联网吗? 这是美国一家主要公用事业公司从 550 万米以上收集电力数据的方式
- Uber 如何扩展其实时市场平台
- 优步变得非常规:使用司机电话作为备份数据中心
- 在不到五分钟的时间里,Facebook 如何告诉您的朋友您在灾难中很安全
- Zappos 的网站与 Amazon 集成后冻结了两年
- 为在现代时代构建可扩展的有状态服务提供依据
- 细分:使用 Docker,ECS 和 Terraform 重建基础架构
- 十年 IT 失败的五个教训
- Shopify 如何扩展以处理来自 Kanye West 和 Superbowl 的 Flash 销售
- 整个 Netflix 堆栈的 360 度视图
- Wistia 如何每小时处理数百万个请求并处理丰富的视频分析
- Google 和 eBay 关于构建微服务生态系统的深刻教训
- 无服务器启动-服务器崩溃!
- 在 Amazon AWS 上扩展至 1100 万以上用户的入门指南
- 为 David Guetta 建立无限可扩展的在线录制活动
- Tinder:最大的推荐引擎之一如何决定您接下来会看到谁?
- 如何使用微服务建立财产管理系统集成
- Egnyte 体系结构:构建和扩展多 PB 分布式系统的经验教训
- Zapier 如何自动化数十亿个工作流自动化任务的旅程
- Jeff Dean 在 Google 进行大规模深度学习
- 如今 Etsy 的架构是什么样的?
- 我们如何在 Mail.Ru Cloud 中实现视频播放器
- Twitter 如何每秒处理 3,000 张图像
- 每天可处理数百万个请求的图像优化技术
- Facebook 如何向 80 万同时观看者直播
- Google 如何针对行星级基础设施进行行星级工程设计?
- 为 Mail.Ru Group 的电子邮件服务实施反垃圾邮件的猫捉老鼠的故事,以及 Tarantool 与此相关的内容
- The Dollar Shave Club Architecture Unilever 以 10 亿美元的价格被收购
- Uber 如何使用 Mesos 和 Cassandra 跨多个数据中心每秒管理一百万个写入
- 从将 Uber 扩展到 2000 名工程师,1000 个服务和 8000 个 Git 存储库获得的经验教训
- QuickBooks 平台
- 美国大选期间城市飞艇如何扩展到 25 亿个通知
- Probot 的体系结构-我的 Slack 和 Messenger Bot 用于回答问题
- AdStage 从 Heroku 迁移到 AWS
- 为何将 Morningstar 迁移到云端:降低 97%的成本
- ButterCMS 体系结构:关键任务 API 每月可处理数百万个请求
- Netflix:按下 Play 会发生什么?
- ipdata 如何以每月 150 美元的价格为来自 10 个无限扩展的全球端点的 2500 万个 API 调用提供服务
- 每天为 1000 亿个事件赋予意义-Teads 的 Analytics(分析)管道
- Auth0 体系结构:在多个云提供商和地区中运行
- 从裸机到 Kubernetes
- Egnyte Architecture:构建和扩展多 PB 内容平台的经验教训
- 缩放原理
- TripleLift 如何建立 Adtech 数据管道每天处理数十亿个事件
- Tinder:最大的推荐引擎之一如何决定您接下来会看到谁?
- 如何使用微服务建立财产管理系统集成
- Egnyte 体系结构:构建和扩展多 PB 分布式系统的经验教训
- Zapier 如何自动化数十亿个工作流自动化任务的旅程
- Jeff Dean 在 Google 进行大规模深度学习
- 如今 Etsy 的架构是什么样的?
- 我们如何在 Mail.Ru Cloud 中实现视频播放器
- Twitter 如何每秒处理 3,000 张图像
- 每天可处理数百万个请求的图像优化技术
- Facebook 如何向 80 万同时观看者直播
- Google 如何针对行星级基础设施进行行星级工程设计?
- 为 Mail.Ru Group 的电子邮件服务实施反垃圾邮件的猫捉老鼠的故事,以及 Tarantool 与此相关的内容
- The Dollar Shave Club Architecture Unilever 以 10 亿美元的价格被收购
- Uber 如何使用 Mesos 和 Cassandra 跨多个数据中心每秒管理一百万个写入
- 从将 Uber 扩展到 2000 名工程师,1000 个服务和 8000 个 Git 存储库获得的经验教训
- QuickBooks 平台
- 美国大选期间城市飞艇如何扩展到 25 亿条通知
- Probot 的体系结构-我的 Slack 和 Messenger Bot 用于回答问题
- AdStage 从 Heroku 迁移到 AWS
- 为何将 Morningstar 迁移到云端:降低 97%的成本
- ButterCMS 体系结构:关键任务 API 每月可处理数百万个请求
- Netflix:按下 Play 会发生什么?
- ipdata 如何以每月 150 美元的价格为来自 10 个无限扩展的全球端点的 2500 万个 API 调用提供服务
- 每天为 1000 亿个事件赋予意义-Teads 的 Analytics(分析)管道
- Auth0 体系结构:在多个云提供商和地区中运行
- 从裸机到 Kubernetes
- Egnyte Architecture:构建和扩展多 PB 内容平台的经验教训