
# Jeff Dean 在 Google 进行大规模深度学习
> 原文: [http://highscalability.com/blog/2016/3/16/jeff-dean-on-large-scale-deep-learning-at-google.html](http://highscalability.com/blog/2016/3/16/jeff-dean-on-large-scale-deep-learning-at-google.html)
<iframe allowfullscreen="" frameborder="0" height="225" src="https://www.youtube.com/embed/QSaZGT4-6EY?rel=0" width="400"></iframe>
*If you can’t understand what’s in information then it’s going to be very difficult to organize it.*
此引用来自 [Jeff Dean](http://research.google.com/pubs/jeff.html) ,现为 Google 系统基础架构小组的向导,研究员,研究员。 摘自他最近的演讲: [智能计算机系统的大规模深度学习](https://www.youtube.com/watch?v=QSaZGT4-6EY) 。
自 [AlphaGo 诉 Lee Se-dol](https://gogameguru.com/tag/deepmind-alphago-lee-sedol/) 以来, [John Henry](https://en.wikipedia.org/wiki/John_Henry_(folklore)) 的现代版本 与 的致命一击 [像蒸汽锤一样,已经笼罩了整个世界,人们普遍对 AI 感到恐惧](https://www.youtube.com/watch?v=j3LVFdWBHVM) [[ 启示录](http://thenextweb.com/insider/2014/03/08/ai-could-kill-all-meet-man-takes-risk-seriously/) ,这似乎是掩盖 Jeff 演讲的绝佳时机。 而且,如果您认为 AlphaGo 现在很好,请等到 beta 达到。
Jeff 当然是指 Google 臭名昭著的 [座右铭](https://www.google.com/about/company/) : *整理世界各地的信息并将其广泛地传播 可访问且有用的* 。
从历史上看,我们可能会将“组织”与收集,清理,存储,建立索引,报告和搜索数据相关联。 早期 Google 掌握的所有东西。 完成这项任务后,Google 便迎接了下一个挑战。
现在 **的组织意味着对** 的理解。
我的演讲重点:
* **实际的神经网络由数亿个参数**组成。 Google 的技能在于如何在大型有趣的数据集上构建并快速训练这些庞大的模型,将其应用于实际问题,*和*然后将模型快速部署到各种不同平台(电话)中的生产环境中 ,传感器,云等)。
* 神经网络在 90 年代没有兴起的原因是**缺乏计算能力,也缺少大型有趣的数据集**。 您可以在 Google 上看到 Google 对算法自然的热爱,再加上庞大的基础架构和不断扩大的数据集,如何为 AI 掀起**完美的 AI 风暴。**
* Google 与其他公司之间的关键区别在于,当他们在 2011 年启动 Google Brain 项目时, **并未将他们的研究留在象牙塔** 。 项目团队与 Android,Gmail 和照片等其他团队密切合作,以实际改善这些属性并解决难题。 对于每个公司来说,这都是难得的,也是一个很好的教训。 **通过与您的员工合作进行研究** 。
* 这个想法很有效:他们了解到他们可以采用一整套子系统,其中一些子系统可以通过机器学习,并且 **替换为更通用的端到端 终端机器学习资料** 。 通常,当您有很多复杂的子系统时,通常会有很多复杂的代码将它们缝合在一起。 如果您可以用数据和非常简单的算法替换所有内容,那就太好了。
* **机器学习只会变得更好,更快。** 。 杰夫的一句话:机器学习社区的发展确实非常快。 人们发表了一篇论文,并且在一周之内,全世界许多研究小组下载了该论文,阅读,进行了剖析,对其进行了理解,对其进行了一些扩展,并在 [上发布了自己的扩展。 arXiv.org](http://arxiv.org/) 。 它与计算机科学的许多其他部分不同,在其他方面,人们将提交论文,六个月后,一个会议将决定是否接受该论文,然后在三个月后的会议中发表。 到那时已经一年了。 将时间从一年缩短到一周,真是太神奇了。
* **可以魔术方式组合技术** 。 翻译团队使用计算机视觉编写了可识别取景器中文本的应用程序。 它翻译文本,然后将翻译后的文本叠加在图像本身上。 另一个示例是编写图像标题。 它将图像识别与序列到序列神经网络相结合。 您只能想象将来所有这些模块化组件将如何组合在一起。
* **具有令人印象深刻的功能的模型在智能手机** 上足够小。 为了使技术消失,情报必须走到最前沿。 它不能依赖于连接到远程云大脑的网络脐带。 由于 TensorFlow 模型可以在手机上运行,因此这可能是可能的。
* 如果您不考虑如何使用深度神经网络来解决数据理解问题, **几乎可以肯定是** 。 这条线直接来自谈话,但是在您使用深层神经网络解决了棘手的问题之后,观察到棘手的问题后,事实就很清楚了。
Jeff 总是进行精彩的演讲,而这一演讲也不例外。 它简单,有趣,深入并且相对容易理解。 如果您想了解深度学习知识,或者只是想了解 Google 在做什么,那么必须要看的是 。
谈话内容不多。 它已经包装好了。 因此,我不确定本文将为您带来多少价值。 因此,如果您只想观看视频,我会理解的。
与 Google 对话一样,您会感到我们只被邀请到 Willy Wonka 的巧克力工厂的大厅里。 我们面前是一扇锁着的门,我们没有被邀请进来。那扇门之外的东西一定充满了奇迹。 但是,就连威利旺卡(Willy Wonka)的大厅也很有趣。
因此,让我们了解杰夫对未来的看法……这很令人着迷...
## 理解意味着什么?
* 当向人们展示街道场景时,他们可以毫无问题地从场景中挑选文字,了解到一家商店出售纪念品,一家商店的价格确实很低,等等。 直到最近,计算机还无法从图像中提取此信息。

* 如果您真的想从图像中了解物理世界,则计算机需要能够挑选出有趣的信息,阅读并理解它们。
* 小型移动设备在当今和将来都主导着计算机交互。 这些设备需要不同类型的接口。 您需要真正能够理解并产生语音。
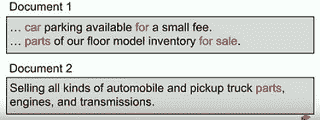
* 进行查询:[待售汽车零件]。 旧的 Google 会匹配第一个结果,因为关键字匹配,但是比较好的匹配是第二个文档。 真正了解查询的含义是深层次而不是肤浅的单词层次,这是构建良好的搜索和语言理解产品所需要的。
## Google 的深度神经网络简史
* [Google Brain 项目](https://en.wikipedia.org/wiki/Google_Brain) 从 2011 年开始,致力于真正推动神经网络技术的发展。
* 神经网络已经存在很长时间了。 它们在 60 年代和 70 年代发明,并在 80 年代末和 90 年代初流行,但它们逐渐消失了。 两个问题:1)缺乏训练大型模型所需的计算能力,这意味着无法将神经网络应用于较大的有趣数据集上的较大问题。 2)缺少大量有趣的数据集。
* 仅与 Google 的几个产品组合作。 随着时间的流逝,随着小组发布的好消息或解决了以前无法解决的问题的消息,周围的人流连忘返,更多的团队会去帮助他们解决问题。
* 一些使用深度学习技术的产品/领域:Android,Apps,药物发现,Gmail,图像理解,地图,自然语言,照片,机器人技术,语音翻译等。
* **深度学习可以应用在如此多样化的项目**中的原因是,它们**涉及到适用于不同领域的同一组构建模块**:语音,文本,搜索查询,图像, 视频,标签,实体,单词,音频功能。 您可以输入一种信息,确定要使用的信息,一起收集表示要计算的功能的训练数据集,然后就可以使用了。
* 这些模型运作良好,因为 **您以非常原始的数据形式输入** ,您无需手工设计很多有趣的功能, 该模型的强大功能在于它能够通过观察大量示例来自动确定数据集的有趣之处。
* 您可以学习通用表示法,可能跨域学习。 例如,“汽车”的含义可能与汽车的图像相同。
* 他们已经知道他们可以采用一整套子系统,其中一些子系统可能是机器学习的,因此**替换为更通用的端到端机器学习文章**。 通常,当您有很多复杂的子系统时,通常会有很多复杂的代码将它们缝合在一起。 如果您可以用数据和非常简单的算法替换所有内容,那就太好了。
## 什么是深度神经网络?
* [神经网络](https://en.wikipedia.org/wiki/Artificial_neural_network) 从数据中学到了非常复杂的功能。 来自一个空间的输入将转换为另一个空间的输出。
* 此功能与 x 2 不同,它是一个非常复杂的功能。 例如,当您输入原始像素(例如猫)时,输出将是对象类别。
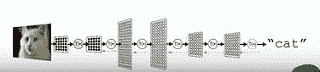
* 深度学习中的“ **深度**”是指神经网络中的**层数。**
* 深度的一个不错的特性是该系统由简单且可训练的数学函数 的 **集合组成。**
* 深度神经网络与许多机器学习风格兼容。
* 例如,您有一个输入,即猫的图片,而输出中有人将该图像标记为猫,则称为 [监督学习](https://en.wikipedia.org/wiki/Supervised_learning) 。 您可以为系统提供许多受监管的示例,并且您将学习近似于与在受监管的示例中观察到的功能相似的函数。
* 您也可以进行 [无监督训练](https://en.wikipedia.org/wiki/Unsupervised_learning) ,其中仅显示图像,不知道图像中包含什么。 然后,系统可以学习掌握在许多图像中出现的模式。 因此,即使您不知道该怎么称呼图像,它也可以识别出其中所有带有猫的图像都具有共同点。
* 还与 [强化学习](https://en.wikipedia.org/wiki/Reinforcement_learning) 等更奇特的技术兼容,这是一种非常重要的技术,已被用作一种 AlphaGo。
## 什么是深度学习?
* 神经网络模型**宽松地基于我们认为大脑的行为**。 这不是神经元真正工作原理的详细模拟。 这是神经元的简单抽象版本。 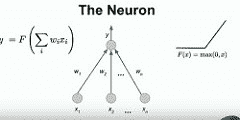
* 神经元有很多输入。 真实的神经元可以将不同的强度与不同的输入相关联。 人工神经网络尝试学习所有这些边上的权重,这些权重是与不同输入相关的优势。
* 真实的神经元会结合其输入和强度,并决定触发或不触发,即尖峰。
* 人工神经元不仅发出尖峰,还发出实数值。 这些神经元计算的功能是其输入的加权总和乘以通过某些非线性函数施加的权重。
* 通常,当今使用的非线性函数是 [整流线性单元](https://en.wikipedia.org/wiki/Rectifier_(neural_networks)) (最大值(0,x))。 在 90 年代,许多非线性函数是 [更平滑的](https://www.quora.com/What-is-special-about-rectifier-neural-units-used-in-NN-learning) S 型或正弦函数。 它具有不错的特性,即当神经元不触发时提供真实的零,而接近零的值可以在优化系统时为您提供帮助。
* 例如,如果神经元作为权重为-0.21、0.3 和 0.7 的三个输入 X1,X1,X3,则计算将为:y = max(0,-.0.21 * x1 + 0.3 * x2 + 0.7 * x3)。
* 在确定图像是猫还是狗时,图像将经过一系列图层放置。 一些神经元会根据其输入而激发或不激发。

* 最低层的神经元将看着小块像素。 较高级别的神经元将查看下面的神经元的输出,并决定是否触发。
* 该模型将逐步向上移动,例如说它是一只猫。 在这种情况下哪个是错的,那是一条狗(尽管我也以为是猫,还是在篮中的狗?)。
* 这是一个错误决策的信号会反馈到系统中,然后该信号将对模型的其余部分进行调整,以使下次查看图像时输出看起来像狗一样。
* 这就是神经网络的**目标,** **对整个模型中所有边缘**的权重进行很小的调整 **,以使您更有可能正确理解示例 。 您可以在所有示例中进行汇总,以便正确地使用大多数示例。**
* 学习算法非常简单。 未完成时:
* 选择一个随机训练示例“(输入,标签)”。 例如,带有所需输出“ cat”的猫图片。
* 在“输入”上运行神经网络,并查看其产生的结果。
* 调整边缘的权重以使输出更接近“标签”
* 如何调整边缘的权重以使输出更接近标签?
* [反向传播](http://mattmazur.com/2015/03/17/a-step-by-step-backpropagation-example/) 。 以下是推荐的解释: [计算图上的演算:反向传播](http://colah.github.io/posts/2015-08-Backprop/) 。
* 微积分的 [链规则](https://www.khanacademy.org/math/differential-calculus/taking-derivatives/chain-rule/v/chain-rule-introduction) 用于确定当选择的是猫而不是狗时,在神经网络的顶部,您了解如何调整 最顶层的权重使其更可能说狗。

* 您需要使用权重朝箭头方向前进,以使其更有可能说狗。 不要迈出大步,因为它是复杂的不平坦表面。 采取非常小的步骤,使其更有可能在下一次遇到狗。 通过多次迭代并查看示例,结果更有可能成为狗。
* 通过链式规则,您可以了解较低层的参数更改将如何影响输出。 这意味着网络中的 **变化可以通过** 一直回荡到输入,从而使整个模型适应并更有可能说狗。
* 真正的神经网络是 **,它由数亿个参数组成** ,因此您要在亿维空间中进行调整,并尝试了解其影响 网络的输出。
## 神经网络的一些不错的特性
* **神经网络可以应用于许多不同类型的问题** (只要您有很多有趣的数据需要理解)。
* 文字:英语和其他语言的单词数以万亿计。 有很多对齐的文本,在一个句子的层次上有一种语言的翻译版本和另一种语言的翻译版本。
* 视觉数据:数十亿个图像和视频。
* 音频:每天数万小时的语音。
* 用户活动:有许多不同的应用程序在生成数据。 例如来自搜索引擎的查询或在电子邮件中标记垃圾邮件的人。 您可以学习许多活动并构建智能系统。
* 知识图:数十亿标记的关系三倍。
* **如果向它们投入更多数据,并使模型更大,则结果往往会更好** 。
* 如果您在问题上投入了更多数据而又没有使模型更大,则可以通过学习有关数据集的更显而易见的事实来饱和模型的容量。
* **通过增加模型的大小,它不仅可以记住明显的事物**,而且可以记住可能仅在数据集中的一小部分示例中出现的细微模式。
* 通过在更多数据上构建更大的模型 **,需要进行更多的计算** 。 Google 一直在努力研究如何扩展计算量以解决这些问题,从而训练更大的模型。
## 深度学习对 Google 有何重大影响?
### 语音识别
* 这是 Google Brain 团队与之合作部署神经网络的第一批团队之一。 他们帮助他们部署了基于神经网络的新声学模型,而不是他们所使用的 [隐藏马尔可夫模型](https://en.wikipedia.org/wiki/Hidden_Markov_model) 。
* 声学模型的问题是要从语音的 150 毫秒转到预测在 10 毫秒的中间发出什么声音。 例如,是 ba 还是 ka 声音? 然后,您将获得这些预测的完整序列,然后将它们与语言模型结合在一起,以了解用户的意见。
* 他们的初始模型 **将字识别错误减少了 30%** ,这确实是一个大问题。 从那时起,语音团队一直在研究更复杂的模型和高级网络,以进一步降低错误率。 现在,当您在电话里讲话时,语音识别比三五年前要好得多。
### ImageNet 挑战
* 大约 6 年前,发布了 [ImageNet](http://image-net.org/) 数据集。 当时大约有 100 万张图像,是计算机视觉的最大数据集之一。 这个庞大的数据集的发布推动了计算机视觉领域的发展。
* 将图像放置在大约 1000 个不同类别中,每个类别大约放置 1000 张图像。
* 有上千种不同的豹子,小型摩托车等图片。
* 一个复杂的因素是并非所有标签都正确。
* 目标是推广到新型图像。 您可以说是豹子还是樱桃,换个新图片?
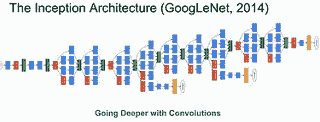
* 在使用神经网络进行挑战之前,错误率约为 26%。 2014 年,Google 以 6.66% 的 错误率赢得了挑战。 2015 年,错误率降至 3.46%。
* 这是一个庞大而深入的模型。 每个盒子都像整个神经元层一样在进行卷积运算。 这是本文: [随着卷积的发展而深入](http://www.cs.unc.edu/~wliu/papers/GoogLeNet.pdf) 。
* 人类 Andrej Karpathy 接受了挑战,错误率为 5.1%。 您可以在以下位置了解他的经验: [我在 ImageNet 上与 ConvNet 竞争所学到的东西。](http://karpathy.github.io/2014/09/02/what-i-learned-from-competing-against-a-convnet-on-imagenet/)
#### 神经网络模型擅长什么?
* 该模型在 **方面表现出色,在**方面有很好的区分。 例如,计算机擅长区分狗的品种,而人类则不如。 当人们看到一朵花并说是一朵花时,计算机可以分辨出它是“芙蓉”还是“大丽花”。
* 这些模型**擅长于概括**。 例如,看起来不相似的不同种类的餐食仍将正确地标记为“餐食”。
* 当计算机出错时,错误对于原因是明智的。 例如,sl 看起来很像蛇。
### Google 相册搜索
* 能够查看像素并了解图像中的内容是一种强大的功能。
* Google 相册小组实现了无需标记即可搜索照片的功能。 您可以找到雕像,yoda,图纸,水等的图片,而无需为图片加标签。
### 街景图像
* 在街景图像中,您希望能够阅读所有文字。 这是更精细的视觉任务。
* 您需要首先能够找到图像中的文本。 经过训练的模型可以从本质上预测像素的热图,其中像素包含文本,而像素不包含文本。 训练数据是围绕文本片段绘制的多边形。
* 因为训练数据包含不同的字符集,所以以多种语言查找文本没有问题。 它适用于大字体和小字体; 靠近摄像机的单词和远离摄像机的单词; 用不同的颜色。
* 这是一种相对容易训练的模型。 这是一个卷积网络,它会尝试预测每个像素是否包含文本。
### 在 Google 搜索排名中的 RankBrain
* [RankBrain](http://searchengineland.com/faq-all-about-the-new-google-rankbrain-algorithm-234440) 于 2015 年推出。它是第三重要的搜索排名信号(100 秒)。 有关更多信息,请访问: [Google 将其获利的 Web 搜索移交给 AI 机器](http://www.bloomberg.com/news/articles/2015-10-26/google-turning-its-lucrative-web-search-over-to-ai-machines) 。
* 搜索排名有所不同,因为您希望能够理解该模型,并且希望了解其做出某些决定的原因。
* 这是搜索排名小组在使用神经网络进行搜索排名时的不安。 当系统出错时,他们想了解为什么这样做。
* 创建了调试工具,并在模型中建立了足够的可理解性,以克服该反对意见。
* 通常,您不想手动调整参数。 您试图了解模型为什么要进行这种预测,并弄清楚该模型是否与训练数据有关,是否与问题不匹配? 您可以训练一种数据分布,然后应用到另一种数据分布。 通过搜索查询的分布,您每天的变化都会有所变化。 由于事件的发生,变化总是在发生。 您必须了解自己的分布是否稳定,例如语音识别,人们发出的声音变化不大。 查询和文档内容经常更改,因此您必须确保模型是最新的。 一般而言,我们需要做得更好的工作构建工具,以了解这些神经网络内部发生的事情,找出导致预测的原因。
### 序列到序列模型
* 可以将世界上的许多问题构想为将一个序列映射到另一个序列。 Google 的 Sutskever,Vinyals 和 Le 撰写了有关该主题的突破性论文: [序列到神经网络的序列学习](http://papers.nips.cc/paper/5346-sequence-to-sequence-learning-with-neural-networks.pdf) 。
* 他们特别关注语言翻译,以及将英语翻译成法语的问题。 翻译实际上只是将英语单词序列映射到法语单词序列。
* 神经网络非常擅长学习非常复杂的功能,因此该模型将学习将英语映射到法语句子的功能。
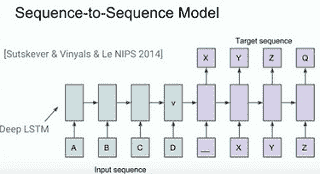
* 用 EOS(句子结尾)信号一次输入一种语言的句子。 当看到一个 EOS 以另一种语言开始产生相应的句子时,模型被训练。 训练数据是指意义相同的语言句子对。 它只是试图对该功能建模。
* 在每个步骤中,它都会在您词汇表中的所有词汇表项上发出概率分布。 在推论时,您需要做一点搜索而不是训练。 如果您必须最大化每个单词的概率,则不一定要获得最可能的句子。 对联合概率进行搜索,直到找到最大可能的句子。
* 该系统在公共翻译任务上达到了最新水平。 大多数其他翻译系统都是针对问题子集的一堆手工编码或机器学习的模型,而不是完整的端到端学习系统。
* 该模型引起了人们的广泛关注,因为很多问题都可以映射到这种逐序列方法。
#### 智能回复
* [智能回复](http://googleresearch.blogspot.com/2015/11/computer-respond-to-this-email.html) 是如何在产品中使用逐个序列的示例。 在电话上,您希望能够快速响应电子邮件,并且打字很麻烦。
* 他们与 Gmail 团队合作开发了一个系统来预测邮件的可能回复。
* 第一步是训练一个小模型,以预测消息是否是可以简短回复的消息。 如果是这样,则会激活一个更大,计算量更大的模型,该模型将消息作为顺序输入,并尝试预测响应字的顺序。
* 例如,在一封询问感恩节邀请的电子邮件中,三种预计的回复是: 我们会去的; 抱歉,我们无法做到。
* 使用智能回复可以在收件箱应用中生成令人惊讶的回复数量。
#### 图片字幕
* 生成图像标题时,您要尝试在给定图像像素的情况下使人可能为该图像写上的标题。
* 取得已开发的图像模型和已开发的序列到序列模型,并将它们插入在一起。 图像模型用作输入。 不用一次查看一个英语句子,而是查看图像的像素。
* 经过训练可以产生字幕。 训练数据集具有由五个不同的人书写的带有五个不同标题的图像。 共写了大约 700,000 个句子,大约 100,000 至 200,000 张图像。
* 关于电脑上写道的一个抱着玩具熊的婴儿的照片:关闭一个抱着毛绒玩具的孩子; 一个婴儿在玩具熊旁边睡着了。
* 它没有人的理解水平。 错误的结果可能很有趣。
### 组合视觉+翻译
* 可以组合技术。 翻译团队使用计算机视觉编写了可识别取景器中文本的应用程序。 它翻译文本,然后将翻译后的文本叠加在图像本身上(看起来非常令人印象深刻,大约为 37:29)。
* 这些模型足够小,可以在设备 上运行**和** **!**
## 周转时间及其对研究的影响
* 每天训练一张 GPU 卡需要 6 个星期。
* Google 真的很希望能够快速完成研究。 这个想法是要快速训练模型,了解哪些方法行之有效,哪些行之有效,并找出下一组要运行的实验。
* 模型应在数小时之内(而不是数天或数周)可训练。 它使每个进行此类研究的人都更有效率。
## 如何快速训练大型模型
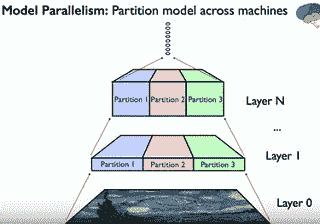
### 模型并行
* 神经网络具有许多固有的并行性。
* 在计算它们时,所有不同的单个神经元大多彼此独立,尤其是当您具有局部感受野时,其中一个神经元仅接受来自其下方少数神经元的输入。
* 可以在不同的 GPU 卡上的不同计算机上划分工作。 只有跨越边界的数据才需要通信。
### 数据并行
* 您要优化的模型的参数集不应位于集中服务中的一台计算机中,因此您可以拥有许多不同的模型副本,这些副本将协作以优化参数。
* 在训练过程中读取不同的随机数据(示例)。 每个副本都将获取模型中的当前参数集,读取一些有关梯度应为多少的数据,找出要对参数进行哪些调整,然后将调整发送回集中的参数服务器集 。 参数服务器将对参数进行调整。 并重复该过程。
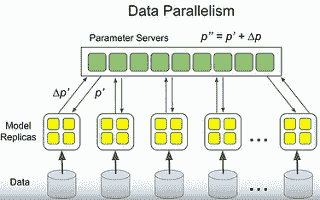
* 这可以跨许多副本完成。 有时,他们在 500 台不同的机器上使用 500 个模型的副本,以便快速优化参数并处理大量数据。
* 该过程可以是 **异步** ,其中每个料仓都在其自己的循环中,获取参数,计算梯度并将其发送回去,而无需任何控制或同步 其他的。 不利的一面是,当梯度返回时,参数可能已从计算时移开。 事实证明,对于实际上多达 50 到 100 个副本的多种模型而言,这是可以的。
* 该进程可以 **同步** 。 一个控制器控制所有副本。 两者似乎都起作用并且具有不同的优点和缺点(未列出)。
演讲的下一部分是关于 TensorFlow 的,我不会在这里讨论。 这篇文章已经太长了。
## Q & A
* **如果您不是 Google 这样的大公司,并且无法访问大数据集,该怎么办?** 从运作良好的模型开始,该模型在公共数据集上经过训练。 公共数据集通常可用。 然后对更适合您的问题的数据进行培训。 从相似且可公开获得的数据集开始时,您可能只需要为特定问题加上标签的 1,000 或 10,000 个示例。 ImageNet 是此过程工作的一个很好的例子。
* **作为工程师,您最大的错误是什么?** 不在 BigTable 中放置分布式事务。 如果要更新多个行,则必须滚动自己的事务协议。 不会输入它是因为它会使系统设计变得复杂。 回想起来,许多团队都希望拥有这种能力,并以不同程度的成功建立自己的团队。 我们应该在核心系统中实现事务。 它在内部也将是有用的。 Spanner 通过添加事务来解决此问题。
## 相关文章
* [关于 HackerNews](https://news.ycombinator.com/item?id=11298308)
* Ryan Adams 的 [AlphaGo](http://deepmind.com/alpha-go.html) 的真棒麻瓜可获得的技术解释 [机器学习音乐视频](http://www.thetalkingmachines.com/blog/) [Talking Machines](http://www.thetalkingmachines.com/) 播客的 集。
* [TensorFlow](https://www.tensorflow.org/)
* [为什么机器学习课程的注册人数激增](http://blogs.nvidia.com/blog/2016/02/24/enrollment-in-machine-learning/)
* [使用深度卷积神经网络](http://arxiv.org/abs/1412.6564) 进行移动评估
* [捍卫强大的 AI:语法](http://disagreeableme.blogspot.com/2012/11/in-defence-of-strong-ai-semantics-from.html) 的语义
* [中文会议室参数](http://plato.stanford.edu/entries/chinese-room/)
* [Google:将计算机上的多个工作负荷相乘以提高机器利用率并节省资金](http://highscalability.com/blog/2013/11/13/google-multiplex-multiple-works-loads-on-computers-to-increa.html)
* [Google On Latency Tolerant Systems:由不可预测的部分组成可预测的整体](http://highscalability.com/blog/2012/6/18/google-on-latency-tolerant-systems-making-a-predictable-whol.html)
* [Google DeepMind:它是什么,它如何工作,您应该被吓到吗?](http://www.techworld.com/personal-tech/google-deepmind-what-is-it-how-it-works-should-you-be-scared-3615354/)
* [重塑 Google 帝国的人工大脑内部](http://www.wired.com/2014/07/google_brain/)
* [神经网络揭秘](http://lumiverse.io/series/neural-networks-demystified)
* [神经网络黑客指南](http://karpathy.github.io/neuralnets/)
* [神经网络和深度学习](http://neuralnetworksanddeeplearning.com/)
* [神经网络(常规)](http://colah.github.io/)
* [stephencwelch /神经网络解密](https://github.com/stephencwelch/Neural-Networks-Demystified)
* [加州大学伯克利分校深度学习主题课程](https://github.com/joanbruna/stat212b)
* [机器学习:2014-2015](https://www.cs.ox.ac.uk/people/nando.defreitas/machinelearning/)
* [通过深度强化学习玩 Atari](https://www.cs.toronto.edu/~vmnih/docs/dqn.pdf)
* [通过深度强化学习](https://storage.googleapis.com/deepmind-data/assets/papers/DeepMindNature14236Paper.pdf) 进行人为控制
您提到了 arxiv.org,但却错过了 [gitxiv.com](http://gitxiv.com) ,这是机器学习中“真正非常快的”开发周期的下一个演变。 在 Gitxiv 上,您可以在 arxiv.org 上找到某些论文的实现。 这是您希望随论文提供的源代码。 大多数实现是由第三方完成的,但越来越多的是高质量的。
人类如何更好地以最适合 AI(例如 BrainRank 或其他深度神经网络)消费和理解的形式来构造文本?
“从历史上看,我们可能会将'组织'与收集,清理,存储,建立索引,报告和搜索数据联系在一起。所有 Google 早期掌握的东西。完成这一任务后,Google 便迎接了下一个挑战。
现在组织意味着理解。”
我还没有看过杰夫·迪恩(Jeff Dean)的演讲-但有趣的是,几天前我在 Twitter 上发布了完全相同的内容:
“ IMO Google 的长期目标不仅是“组织世界的信息”,还在于使用#AI 来“理解”它:
https://twitter.com/arunshroff/status/709072187773349889
要点:约翰·亨利的故事是我小时候最喜欢的故事之一。
尽管这场比赛对他来说是致命的,但他还是*击败了*蒸汽锤。 因此,我不确定您想以此类推论来说明什么。
总体而言,自工业革命以来,我们就发生了人机冲突,这表明发生了棘轮事件。 永远无法退回的齿轮转动。 约翰·亨利(John Henry)是其中一员。 AlphaGo 不是,但是它来了。
约翰·亨利死了。 那不是赢。 充其量是物理上的胜利。 他悲惨的胜利并没有阻止接下来发生的一切。 机器置换人的肌肉。
好文章。 小重点。 Alpha Go 没有使用强化学习,这很重要。 强化学习是专为单人问题设计的,它在游戏等两人模型中的使用远非直截了当。 最大的问题是,如果自己一个人去,您将探索哪个领域。 因此,Alpha Go 使用(深度)学习来确定要探索的动作,如何评估情况以及何时停止评估,但是总体算法是一种博弈。 重要的是,学习不能解决所有问题,并且有明显的盲点。 其中之一就是结构很多的问题,例如是否有对手试图击败您。 还有其他情况。
- LiveJournal 体系结构
- mixi.jp 体系结构
- 友谊建筑
- FeedBurner 体系结构
- GoogleTalk 架构
- ThemBid 架构
- 使用 Amazon 服务以 100 美元的价格构建无限可扩展的基础架构
- TypePad 建筑
- 维基媒体架构
- Joost 网络架构
- 亚马逊建筑
- Fotolog 扩展成功的秘诀
- 普恩斯的教训-早期
- 论文:Wikipedia 的站点内部,配置,代码示例和管理问题
- 扩大早期创业规模
- Feedblendr 架构-使用 EC2 进行扩展
- Slashdot Architecture-互联网的老人如何学会扩展
- Flickr 架构
- Tailrank 架构-了解如何在整个徽标范围内跟踪模因
- Ruby on Rails 如何在 550k 网页浏览中幸存
- Mailinator 架构
- Rackspace 现在如何使用 MapReduce 和 Hadoop 查询 TB 的数据
- Yandex 架构
- YouTube 架构
- Skype 计划 PostgreSQL 扩展到 10 亿用户
- 易趣建筑
- FaceStat 的祸根与智慧赢得了胜利
- Flickr 的联合会:每天进行数十亿次查询
- EVE 在线架构
- Notify.me 体系结构-同步性
- Google 架构
- 第二人生架构-网格
- MySpace 体系结构
- 扩展 Digg 和其他 Web 应用程序
- Digg 建筑
- 在 Amazon EC2 中部署大规模基础架构的六个经验教训
- Wolfram | Alpha 建筑
- 为什么 Facebook,Digg 和 Twitter 很难扩展?
- 全球范围扩展的 10 个 eBay 秘密
- BuddyPoke 如何使用 Google App Engine 在 Facebook 上扩展
- 《 FarmVille》如何扩展以每月收获 7500 万玩家
- Twitter 计划分析 1000 亿条推文
- MySpace 如何与 100 万个并发用户一起测试其实时站点
- FarmVille 如何扩展-后续
- Justin.tv 的实时视频广播架构
- 策略:缓存 404 在服务器时间上节省了洋葱 66%
- Poppen.de 建筑
- MocoSpace Architecture-一个月有 30 亿个移动页面浏览量
- Sify.com 体系结构-每秒 3900 个请求的门户
- 每月将 Reddit 打造为 2.7 亿页面浏览量时汲取的 7 个教训
- Playfish 的社交游戏架构-每月有 5000 万用户并且不断增长
- 扩展 BBC iPlayer 的 6 种策略
- Facebook 的新实时消息系统:HBase 每月可存储 135 亿条消息
- Pinboard.in Architecture-付费玩以保持系统小巧
- BankSimple 迷你架构-使用下一代工具链
- Riak 的 Bitcask-用于快速键/值数据的日志结构哈希表
- Mollom 体系结构-每秒以 100 个请求杀死超过 3.73 亿个垃圾邮件
- Wordnik-MongoDB 和 Scala 上每天有 1000 万个 API 请求
- Node.js 成为堆栈的一部分了吗? SimpleGeo 说是的。
- 堆栈溢出体系结构更新-现在每月有 9500 万页面浏览量
- Medialets 体系结构-击败艰巨的移动设备数据
- Facebook 的新实时分析系统:HBase 每天处理 200 亿个事件
- Microsoft Stack 是否杀死了 MySpace?
- Viddler Architecture-每天嵌入 700 万个和 1500 Req / Sec 高峰
- Facebook:用于扩展数十亿条消息的示例规范架构
- Evernote Architecture-每天有 900 万用户和 1.5 亿个请求
- TripAdvisor 的短
- TripAdvisor 架构-4,000 万访客,200M 动态页面浏览,30TB 数据
- ATMCash 利用虚拟化实现安全性-不变性和还原
- Google+是使用您也可以使用的工具构建的:闭包,Java Servlet,JavaScript,BigTable,Colossus,快速周转
- 新的文物建筑-每天收集 20 亿多个指标
- Peecho Architecture-鞋带上的可扩展性
- 标记式架构-扩展到 1 亿用户,1000 台服务器和 50 亿个页面视图
- 论文:Akamai 网络-70 个国家/地区的 61,000 台服务器,1,000 个网络
- 策略:在 S3 或 GitHub 上运行可扩展,可用且廉价的静态站点
- Pud 是反堆栈-Windows,CFML,Dropbox,Xeround,JungleDisk,ELB
- 用于扩展 Turntable.fm 和 Labmeeting 的数百万用户的 17 种技术
- StackExchange 体系结构更新-平稳运行,Amazon 4x 更昂贵
- DataSift 体系结构:每秒进行 120,000 条推文的实时数据挖掘
- Instagram 架构:1400 万用户,1 TB 的照片,数百个实例,数十种技术
- PlentyOfFish 更新-每月 60 亿次浏览量和 320 亿张图片
- Etsy Saga:从筒仓到开心到一个月的浏览量达到数十亿
- 数据范围项目-6PB 存储,500GBytes / sec 顺序 IO,20M IOPS,130TFlops
- 99designs 的设计-数以千万计的综合浏览量
- Tumblr Architecture-150 亿页面浏览量一个月,比 Twitter 更难扩展
- Berkeley DB 体系结构-NoSQL 很酷之前的 NoSQL
- Pixable Architecture-每天对 2000 万张照片进行爬网,分析和排名
- LinkedIn:使用 Databus 创建低延迟更改数据捕获系统
- 在 30 分钟内进行 7 年的 YouTube 可扩展性课程
- YouPorn-每天定位 2 亿次观看
- Instagram 架构更新:Instagram 有何新功能?
- 搜索技术剖析:blekko 的 NoSQL 数据库
- Pinterest 体系结构更新-1800 万访问者,增长 10 倍,拥有 12 名员工,410 TB 数据
- 搜索技术剖析:使用组合器爬行
- iDoneThis-从头开始扩展基于电子邮件的应用程序
- StubHub 体系结构:全球最大的票务市场背后的惊人复杂性
- FictionPress:在网络上发布 600 万本小说
- Cinchcast 体系结构-每天产生 1,500 小时的音频
- 棱柱架构-使用社交网络上的机器学习来弄清您应该在网络上阅读的内容
- 棱镜更新:基于文档和用户的机器学习
- Zoosk-实时通信背后的工程
- WordPress.com 使用 NGINX 服务 70,000 req / sec 和超过 15 Gbit / sec 的流量
- 史诗般的 TripAdvisor 更新:为什么不在云上运行? 盛大的实验
- UltraDNS 如何处理数十万个区域和数千万条记录
- 更简单,更便宜,更快:Playtomic 从.NET 迁移到 Node 和 Heroku
- Spanner-关于程序员使用 NoSQL 规模的 SQL 语义构建应用程序
- BigData 使用 Erlang,C 和 Lisp 对抗移动数据海啸
- 分析数十亿笔信用卡交易并在云中提供低延迟的见解
- MongoDB 和 GridFS 用于内部和内部数据中心数据复制
- 每天处理 1 亿个像素-少量竞争会导致大规模问题
- DuckDuckGo 体系结构-每天进行 100 万次深度搜索并不断增长
- SongPop 在 GAE 上可扩展至 100 万活跃用户,表明 PaaS 未通过
- Iron.io 从 Ruby 迁移到 Go:减少了 28 台服务器并避免了巨大的 Clusterf ** ks
- 可汗学院支票簿每月在 GAE 上扩展至 600 万用户
- 在破坏之前先检查自己-鳄梨的建筑演进的 5 个早期阶段
- 缩放 Pinterest-两年内每月从 0 到十亿的页面浏览量
- Facebook 的网络秘密
- 神话:埃里克·布鲁尔(Eric Brewer)谈银行为什么不是碱-可用性就是收入
- 一千万个并发连接的秘密-内核是问题,而不是解决方案
- GOV.UK-不是你父亲的书库
- 缩放邮箱-在 6 周内从 0 到 100 万用户,每天 1 亿条消息
- 在 Yelp 上利用云计算-每月访问量为 1.02 亿,评论量为 3900 万
- 每台服务器将 PHP 扩展到 30,000 个并发用户的 5 条 Rockin'Tips
- Twitter 的架构用于在 5 秒内处理 1.5 亿活跃用户,300K QPS,22 MB / S Firehose 以及发送推文
- Salesforce Architecture-他们每天如何处理 13 亿笔交易
- 扩大流量的设计决策
- ESPN 的架构规模-每秒以 100,000 Duh Nuh Nuhs 运行
- 如何制作无限可扩展的关系数据库管理系统(RDBMS)
- Bazaarvoice 的架构每月发展到 500M 唯一用户
- HipChat 如何使用 ElasticSearch 和 Redis 存储和索引数十亿条消息
- NYTimes 架构:无头,无主控,无单点故障
- 接下来的大型声音如何使用 Hadoop 数据版本控制系统跟踪万亿首歌曲的播放,喜欢和更多内容
- Google 如何备份 Internet 和数十亿字节的其他数据
- 从 HackerEarth 用 Apache 扩展 Python 和 Django 的 13 个简单技巧
- AOL.com 体系结构如何发展到 99.999%的可用性,每天 800 万的访问者和每秒 200,000 个请求
- Facebook 以 190 亿美元的价格收购了 WhatsApp 体系结构
- 使用 AWS,Scala,Akka,Play,MongoDB 和 Elasticsearch 构建社交音乐服务
- 大,小,热还是冷-条带,Tapad,Etsy 和 Square 的健壮数据管道示例
- WhatsApp 如何每秒吸引近 5 亿用户,11,000 内核和 7,000 万条消息
- Disqus 如何以每秒 165K 的消息和小于 0.2 秒的延迟进行实时处理
- 关于 Disqus 的更新:它仍然是实时的,但是 Go 摧毁了 Python
- 关于 Wayback 机器如何在银河系中存储比明星更多的页面的简短说明
- 在 PagerDuty 迁移到 EC2 中的 XtraDB 群集
- 扩展世界杯-Gambify 如何与 2 人组成的团队一起运行大型移动投注应用程序
- 一点点:建立一个可处理每月 60 亿次点击的分布式系统的经验教训
- StackOverflow 更新:一个月有 5.6 亿次网页浏览,25 台服务器,而这一切都与性能有关
- Tumblr:哈希处理每秒 23,000 个博客请求的方式
- 使用 HAProxy,PHP,Redis 和 MySQL 处理 10 亿个请求的简便方法来构建成长型启动架构
- MixRadio 体系结构-兼顾各种服务
- Twitter 如何使用 Redis 进行扩展-105TB RAM,39MM QPS,10,000 多个实例
- 正确处理事情:通过即时重放查看集中式系统与分散式系统
- Instagram 提高了其应用程序的性能。 这是如何做。
- Clay.io 如何使用 AWS,Docker,HAProxy 和 Lots 建立其 10 倍架构
- 英雄联盟如何将聊天扩大到 7000 万玩家-需要很多小兵。
- Wix 的 Nifty Architecture 技巧-大规模构建发布平台
- Aeron:我们真的需要另一个消息传递系统吗?
- 机器:惠普基于忆阻器的新型数据中心规模计算机-一切仍在变化
- AWS 的惊人规模及其对云的未来意味着什么
- Vinted 体系结构:每天部署数百次,以保持繁忙的门户稳定
- 将 Kim Kardashian 扩展到 1 亿个页面
- HappyPancake:建立简单可扩展基金会的回顾
- 阿尔及利亚分布式搜索网络的体系结构
- AppLovin:通过每天处理 300 亿个请求向全球移动消费者进行营销
- Swiftype 如何以及为何从 EC2 迁移到真实硬件
- 我们如何扩展 VividCortex 的后端系统
- Appknox 架构-从 AWS 切换到 Google Cloud
- 阿尔及利亚通往全球 API 的愤怒之路
- 阿尔及利亚通往全球 API 步骤的愤怒之路第 2 部分
- 为社交产品设计后端
- 阿尔及利亚通往全球 API 第 3 部分的愤怒之路
- Google 如何创造只有他们才能创造的惊人的数据中心网络
- Autodesk 如何在 Mesos 上实施可扩展事件
- 构建全球分布式,关键任务应用程序:Trenches 部分的经验教训 1
- 构建全球分布式,关键任务应用程序:Trenches 第 2 部分的经验教训
- 需要物联网吗? 这是美国一家主要公用事业公司从 550 万米以上收集电力数据的方式
- Uber 如何扩展其实时市场平台
- 优步变得非常规:使用司机电话作为备份数据中心
- 在不到五分钟的时间里,Facebook 如何告诉您的朋友您在灾难中很安全
- Zappos 的网站与 Amazon 集成后冻结了两年
- 为在现代时代构建可扩展的有状态服务提供依据
- 细分:使用 Docker,ECS 和 Terraform 重建基础架构
- 十年 IT 失败的五个教训
- Shopify 如何扩展以处理来自 Kanye West 和 Superbowl 的 Flash 销售
- 整个 Netflix 堆栈的 360 度视图
- Wistia 如何每小时处理数百万个请求并处理丰富的视频分析
- Google 和 eBay 关于构建微服务生态系统的深刻教训
- 无服务器启动-服务器崩溃!
- 在 Amazon AWS 上扩展至 1100 万以上用户的入门指南
- 为 David Guetta 建立无限可扩展的在线录制活动
- Tinder:最大的推荐引擎之一如何决定您接下来会看到谁?
- 如何使用微服务建立财产管理系统集成
- Egnyte 体系结构:构建和扩展多 PB 分布式系统的经验教训
- Zapier 如何自动化数十亿个工作流自动化任务的旅程
- Jeff Dean 在 Google 进行大规模深度学习
- 如今 Etsy 的架构是什么样的?
- 我们如何在 Mail.Ru Cloud 中实现视频播放器
- Twitter 如何每秒处理 3,000 张图像
- 每天可处理数百万个请求的图像优化技术
- Facebook 如何向 80 万同时观看者直播
- Google 如何针对行星级基础设施进行行星级工程设计?
- 为 Mail.Ru Group 的电子邮件服务实施反垃圾邮件的猫捉老鼠的故事,以及 Tarantool 与此相关的内容
- The Dollar Shave Club Architecture Unilever 以 10 亿美元的价格被收购
- Uber 如何使用 Mesos 和 Cassandra 跨多个数据中心每秒管理一百万个写入
- 从将 Uber 扩展到 2000 名工程师,1000 个服务和 8000 个 Git 存储库获得的经验教训
- QuickBooks 平台
- 美国大选期间城市飞艇如何扩展到 25 亿个通知
- Probot 的体系结构-我的 Slack 和 Messenger Bot 用于回答问题
- AdStage 从 Heroku 迁移到 AWS
- 为何将 Morningstar 迁移到云端:降低 97%的成本
- ButterCMS 体系结构:关键任务 API 每月可处理数百万个请求
- Netflix:按下 Play 会发生什么?
- ipdata 如何以每月 150 美元的价格为来自 10 个无限扩展的全球端点的 2500 万个 API 调用提供服务
- 每天为 1000 亿个事件赋予意义-Teads 的 Analytics(分析)管道
- Auth0 体系结构:在多个云提供商和地区中运行
- 从裸机到 Kubernetes
- Egnyte Architecture:构建和扩展多 PB 内容平台的经验教训
- 缩放原理
- TripleLift 如何建立 Adtech 数据管道每天处理数十亿个事件
- Tinder:最大的推荐引擎之一如何决定您接下来会看到谁?
- 如何使用微服务建立财产管理系统集成
- Egnyte 体系结构:构建和扩展多 PB 分布式系统的经验教训
- Zapier 如何自动化数十亿个工作流自动化任务的旅程
- Jeff Dean 在 Google 进行大规模深度学习
- 如今 Etsy 的架构是什么样的?
- 我们如何在 Mail.Ru Cloud 中实现视频播放器
- Twitter 如何每秒处理 3,000 张图像
- 每天可处理数百万个请求的图像优化技术
- Facebook 如何向 80 万同时观看者直播
- Google 如何针对行星级基础设施进行行星级工程设计?
- 为 Mail.Ru Group 的电子邮件服务实施反垃圾邮件的猫捉老鼠的故事,以及 Tarantool 与此相关的内容
- The Dollar Shave Club Architecture Unilever 以 10 亿美元的价格被收购
- Uber 如何使用 Mesos 和 Cassandra 跨多个数据中心每秒管理一百万个写入
- 从将 Uber 扩展到 2000 名工程师,1000 个服务和 8000 个 Git 存储库获得的经验教训
- QuickBooks 平台
- 美国大选期间城市飞艇如何扩展到 25 亿条通知
- Probot 的体系结构-我的 Slack 和 Messenger Bot 用于回答问题
- AdStage 从 Heroku 迁移到 AWS
- 为何将 Morningstar 迁移到云端:降低 97%的成本
- ButterCMS 体系结构:关键任务 API 每月可处理数百万个请求
- Netflix:按下 Play 会发生什么?
- ipdata 如何以每月 150 美元的价格为来自 10 个无限扩展的全球端点的 2500 万个 API 调用提供服务
- 每天为 1000 亿个事件赋予意义-Teads 的 Analytics(分析)管道
- Auth0 体系结构:在多个云提供商和地区中运行
- 从裸机到 Kubernetes
- Egnyte Architecture:构建和扩展多 PB 内容平台的经验教训