
[TOC]
*****
**PANDAS的功能**
* 能够很好的处理missing value(NaN)
* 可以对二维甚至高维的数据对象进行插入和删除
* 支持将其它python数据结构简单快捷的转变为DataFrame
* 支持分组计算group by
* 支出数据重塑与数据透视表
* 支持智能的基于标签的切片,索引选取等数据操作
* 支持多个数据集的组合操作:join与merge
* 支持从多个渠道读取文本数据
* 支持时间序列time-series操作
* 支持可视化数据
## 1.1. 文件读取
在之前的I/O章节中给我们学习了使用open函数来打开文件,read函数用来读取数据。 但是读取进来的数据都是str的格式,非常不方便我们进行分析。 pandas提供了read_csv函数可以将文件按照固定的格式进行读取,函数能够自动解析数据类型,添加列名与索引等很多功能,能够以结构化的dataframe形式存储数据。
一些注意点:
1. 不要尝试去读取excel文件,最好使用通用的csv或者txt格式
2. 注意编码问题,使用encoding参数
3. 注意处理报错行
**如果要处理excel文件,用另存为变为csv文件,不推荐使用excel格式**
```
import pandas as pd
import numpy as np
print(pandas.__version__) # 检查版本,如果太低请在终端使用 conda update pandas 命令进行升级
#版本号
0.24.2
```
**读文件**
~~~python
pd.read_csv
pd.read_excel
~~~
```
会显示该方法的解释文档
?pd.read_csv
#\t是分隔符,比如一行数据有10列,每列之间用横向制表符分割
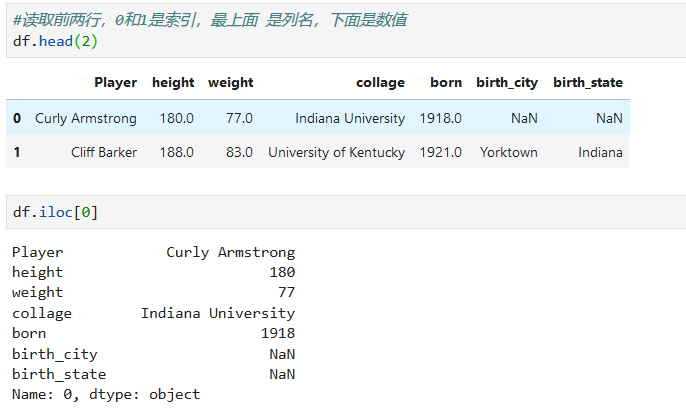
df = pd.read_csv("C:\\Users\\ddupl\\Desktop\\python数据管理\\NBAPlayers.txt",sep = '\t')
```
```
#读取xlsx文件中第一张sheet
movie = pd.read_excel("movie.xlsx",sheetname = 0 ) #不推荐
#显示前三行数据
movie.head(3)
#根据索引显示第一行数据
df.iloc[0]
```
**写文件**
~~~python
df.to_csv(path_or_buf=None, sep=',', na_rep='', float_format=None, columns=None, header=True, index=True, index_label=None, mode='w', encoding=None, compression=None, quoting=None, quotechar='"', line_terminator='\n', chunksize=None, tupleize_cols=None, date_format=None, doublequote=True, escapechar=None, decimal='.')
~~~
```
#将读取数据写入csv文件中,数据间的分隔符是横向制表符,index=true表示显示索引列
df.to_csv("movie_1.csv",sep = '\t',index = True)
```
- 第五节 Pandas数据管理
- 1.1 文件读取
- 1.2 DataFrame 与 Series
- 1.3 常用操作
- 1.4 Missing value
- 1.5 文本数据
- 1.6 分类数据
- 第六节 pandas数据分析
- 2.1 索引选取
- 2.2. 分组计算
- 2.3. 表联结
- 2.4. 数据透视与重塑(pivot table and reshape)
- 2.5 官方小结图片
- 第七节 NUMPY科学计算
- 第八节 python可视化
- 第九节 统计学
- 01 单变量
- 02 双变量
- 03 数值方法
- 第十节 概率
- 01 概率
- 02 离散概率分布
- 03 连续概率分布
- 第一节 抽样与抽样分布
- 01抽样
- 02 点估计
- 03 抽样分布
- 04 抽样分布的性质
- 第十三节 区间估计
- 01总体均值的区间估计:𝝈已知
- 02总体均值的区间估计:𝝈未知
- 03总体容量的确定
- 04 总体比率